文本挖掘与机器学习跟踪扫描动态快报(2021.09)
实时跟踪、关注文本挖掘与机器学习领域最新研究动态
深度观察
Spacial Transformer网络
Max Jaderberg等人引入的Spacial Transformer模块是一种常用的方法,可以增强模型对空间变换(如平移、缩放、旋转、裁剪以及非刚性变形)的空间不变性。它们可以插入到现有的卷积架构中:要么紧跟输入,要么在更深的层中。它们通过自适应地将输入转换为规范的预期姿态来实现空间不变性,从而获得更好的分类性能。“自适应”一词表示,根据输入本身,为每个样本生成适当的转换。Spacial Transformer网络可以使用标准反向传播进行端到端的训练。
职责分离
在反向映射中,我们遍历输出图像,一次一个像素,对于每个位置,我们执行两个操作:
- 1.使用逆变换𝑇-1{…}来计算输入图像中的相应位置。
- 2.使用双线性插值对像素值进行采样。
在实现反向映射时,首先计算所有输出像素的对应位置(并可能存储它们),然后应用双线性插值是有益的。这种方法的主要好处是,我们现在得到了两个单独负责的组件:网格生成器和采样器。网格生成器的唯一任务是执行逆变换,采样器的唯一任务是执行双线性插值。此外,分离极大地促进了反向传播。
网格生成器
网格生成器在输出/目标图像的规则网格上迭代,并使用逆变换𝑇-1{…}计算输入/源图像中相应的(通常为非整数)样本位置:
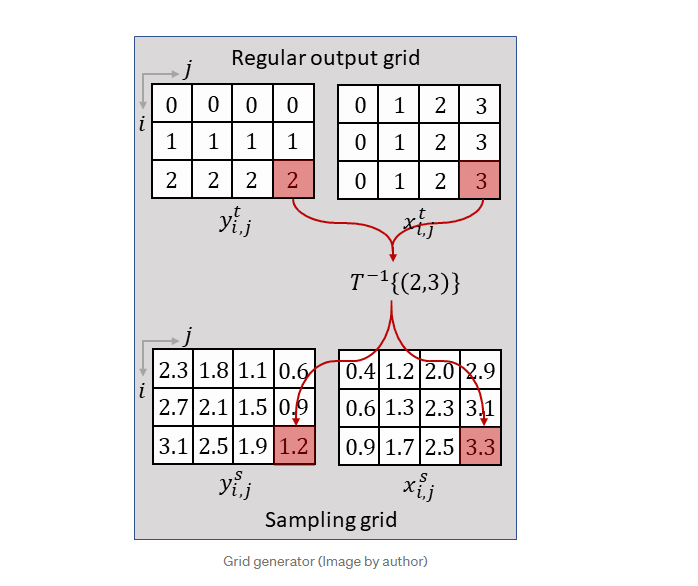
上标𝑡和𝑠取自原始论文,分别表示“目标图像”和“源图像”。采样网格的行和列索引表示为𝑖和𝑗。另请注意,在原始论文中,常规网格上的逆变换𝑇-1{…}表示为𝒯𝜃(𝐺)。
在上图中,为了清晰起见,坐标是以顺序方式计算的,而网格生成器的实际实现将尝试并行转换尽可能多的点,以提高计算效率。网格生成器的输出是所谓的采样网格,它是一组点,输入地图将在其中采样以产生空间变换的输出:
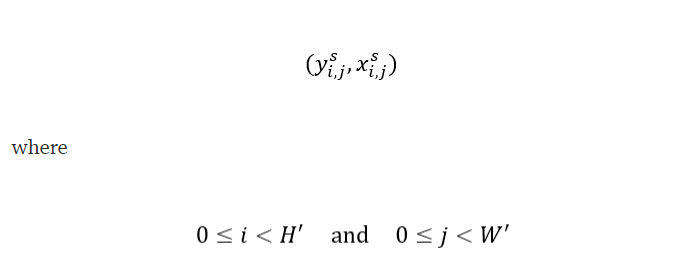
请注意,采样网格的大小决定了目标图像的大小。
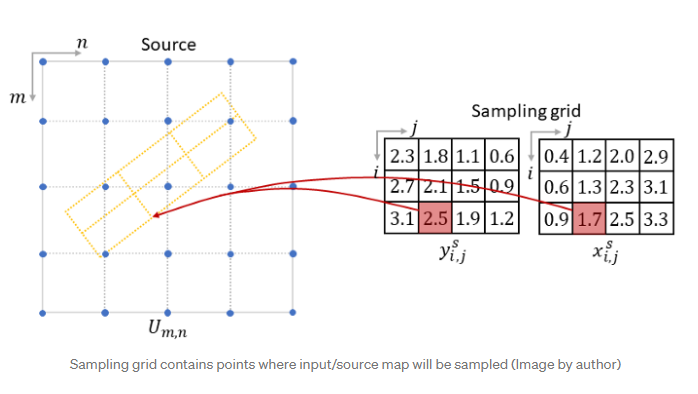
采样网格
关于采样网格的最后一件重要事情是,其高度和宽度不一定需要与输入图像的高度和宽度相同。
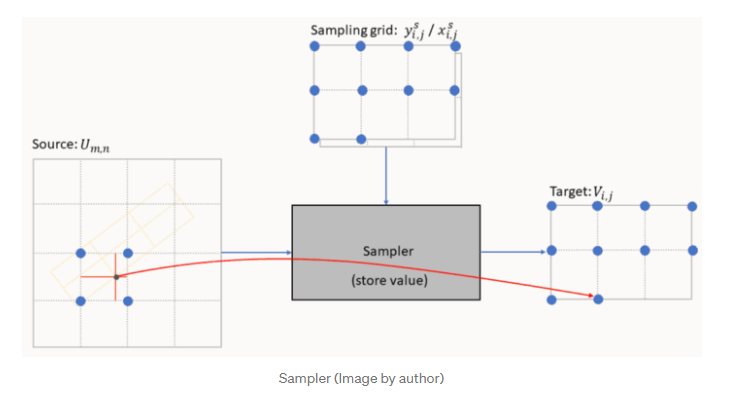
像素值的提取包括三个操作:
- 1.找到四个相邻点(左上、右上、左下和右下)
- 2.对于每个相邻点计算其相应的权重
- 3.取加权平均以产生输出
所有操作都总结在以下等式中。
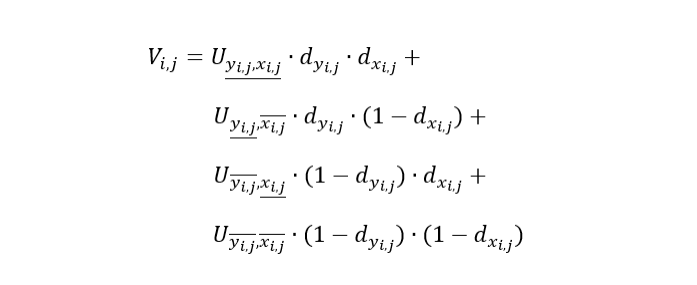
其中𝑑𝑥表示从采样点到右单元格边框的水平距离,以及𝑑𝑦到顶部单元格边框的垂直距离。
在网格生成器中,每个输出像素的计算完全独立于任何其他输出像素。因此,采样器的实现将通过并行提取尽可能多的点来加速该过程。
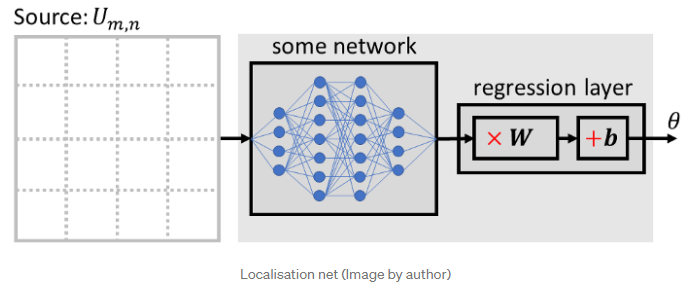
定位网
定位网络的任务是找到逆变换𝑇-1{…}的参数𝜃,它将输入特征图置于规范姿态,从而简化后续层的识别。定位网络可以采用任何形式,如完全连接网络或卷积网络,但应包括最终回归层以产生转换参数𝜃:
𝜃的大小可以根据参数化的变换而变化,例如,对于仿射变换𝜃 是6维的:
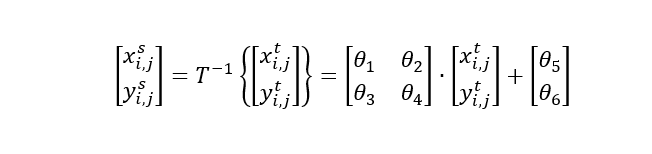
仿射变换功能非常强大,包含平移、缩放、旋转和剪切等特殊情况。然而,对于许多任务,简单的转换可能就足够了,例如,仅使用2个参数实现纯转换:
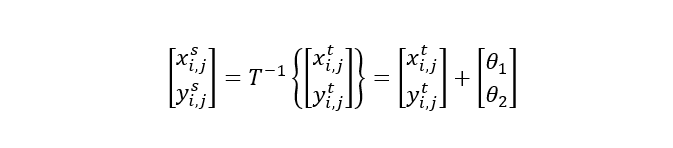
网格生成器和采样器都是无参数操作,即它们没有任何可训练的参数。在这方面,它们与最大池化层相当。因此,Spacial Transformer模块的脑力来自定位网络,定位网络必须学会检测输入特征地图的姿态(如方向、比例等),以便产生适当的变换。
完整模块
最后,让我们看看Spacial Transformer模块的单个构建块是如何相互作用的。输入特征映射𝑈 首先传递给定位网络,该网络回归适当的转换参数𝜃。然后,网格生成器使用变换参数𝜃 生成采样网格,这是一组点,输入特征图应在其中采样。最后,采样器获取输入特征图和采样网格,并使用双线性插值等方法输出变换后的特征图。定位网络分别预测每个输入的转换参数。以这种方式,Spacial Transformer模块成为自适应组件,其行为取决于输入。
多渠道
到目前为止,我们已经在单通道C=1的输入上演示了Spacial Transformer模块的原理,例如灰度图像。然而,Spacial Transformer模块通常在更深的层中使用,并在特征图上操作,特征图通常有多个通道𝐶 > 1。即使在紧接着输入使用时,Spacial Transformer模块也可能面对具有多个通道的输入,例如具有3个通道的RGB图像。
扩展很简单:对于多通道输入,映射对输入的每个通道都是相同的,因此每个通道都以相同的方式进行转换。这样我们可以保持通道之间的空间一致性。值得注意的是,Spacial Transformer模块不会更改通道数𝐶, 在输入和输出特征映射中保持不变。
(张梦婷编译,周子喻校对)
研究动态
IBM利用强化学习在文本和知识库生成方面实现SOTA性能
知识库可用于存储复杂的结构化和非结构化信息,是捕获具有复杂关系的现实世界信息的强大工具。从自由格式文本自动生成知识库和从知识库生成具有语义意义的文本是机器学习中至关重要且具有挑战性的研究领域。
在新论文ReGen: Reinforcement Learning for Text and Knowledge Base Generation Using Pretrained Language Models中,IBM 研究团队提出了 ReGen,这是一种双向生成文本和图的方法,它利用强化学习将文本到图(T2G)和图到文本(G2T)生成任务的性能提升到更高的水平。

该团队将他们的主要贡献总结为:
- 1. 建议对G2T和T2G任务使用基于RL的序列训练——特别是SCST。 这是首次提出基于RL的训练用于文本和图的双向生成。
- 2. 证明我们的方法提供了比WebNLG 2020+挑战报告的最佳系统更好的性能。
- 3.为T2G和G2T任务提供基于SCST的训练的彻底调查,包括最佳奖励组合。
- 4.从TEKGEN句子三元组对构建主语和关系-宾语边界,并展示我们的方法在T2G和G2T任务中的性能。
- 5. 针对T2G和G2T任务调整大规模TEKGEN语料库(Agarwal等人,2021年),并确认基于SCST的微调方法相对于CE训练基线的优势。

受到序列生成任务可以重新构建以便模型在给定词汇表中选择最佳单词的想法的启发,该团队将Seq2Seq生成重新构建到RL框架中。简而言之,代理将定义一个策略,在生成过程中选择每个单词。通过这种方式,该模型被用作自己的批评者,从而实现自我批判序列训练 (SCST)。
该团队使用T5 PLM–t5-large(770M参数)和t5-base(220M参数)进行评估实验。这些模型经过微调,要么专门用于T2G (MT)或G2T (MG)任务,要么适应两个生成方向(MT+G)。
该团队在WebNLG 2020挑战赛中报告了WebNLG+ 2020 (v3.0)数据集的结果,其中包括两项任务:RDF-to-text生成 (G2T) 和text-to-RDF 语义解析(T2G)。他们还使用TEKGEN数据集来测试他们提出的系统的稳健性,使用 BLEU、BLEU_NLTK、METEOR和chrF++作为评估指标。
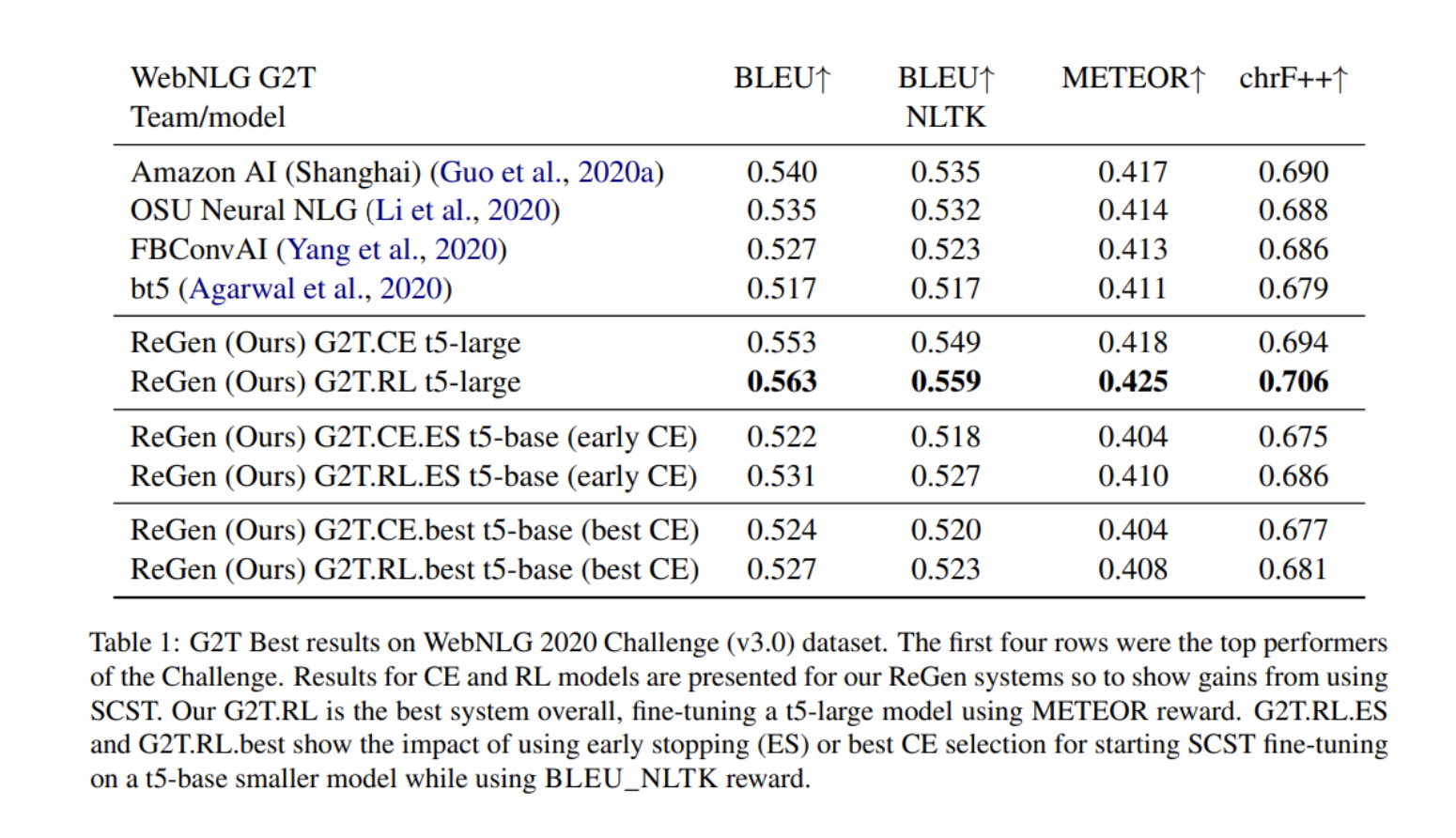
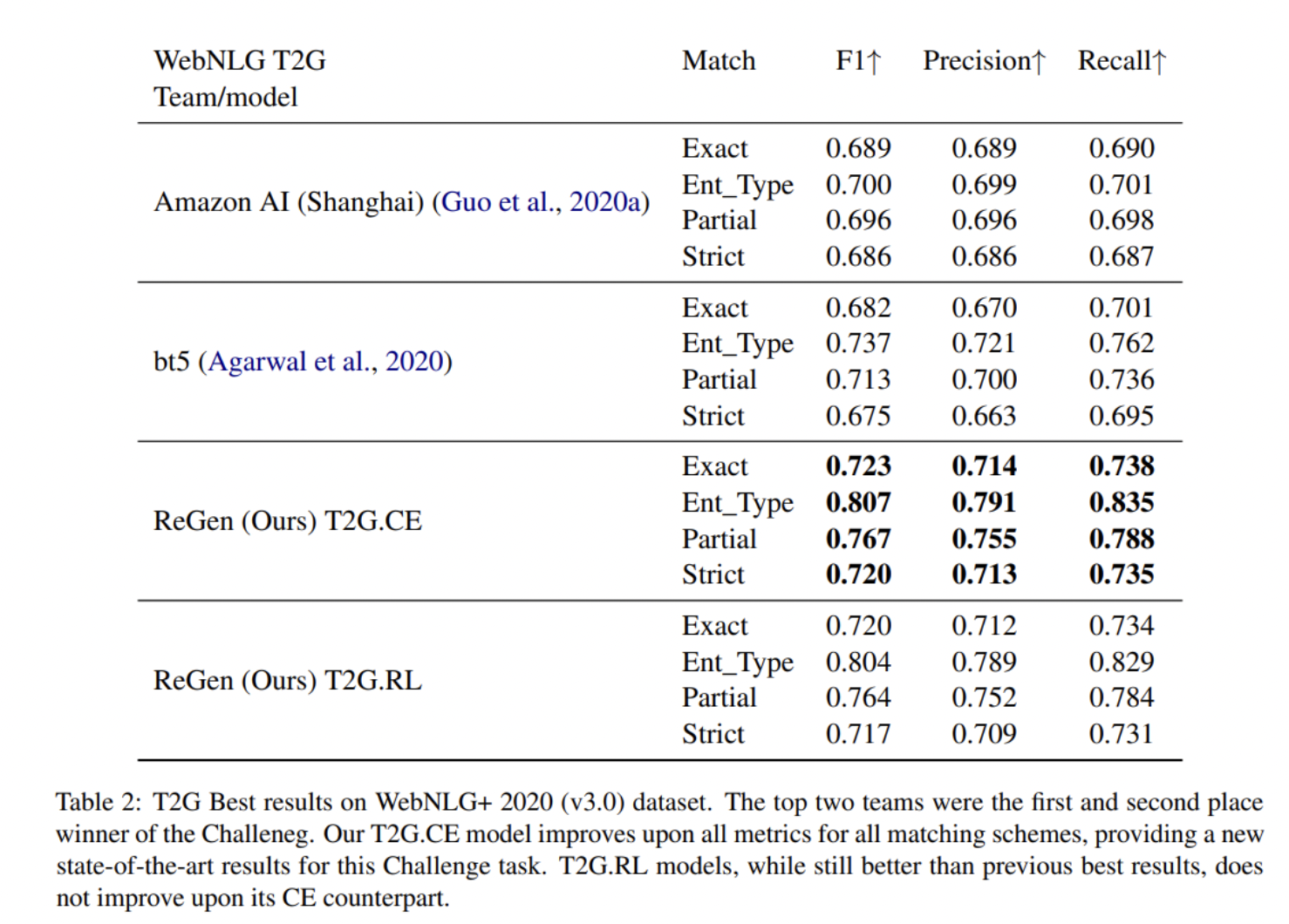
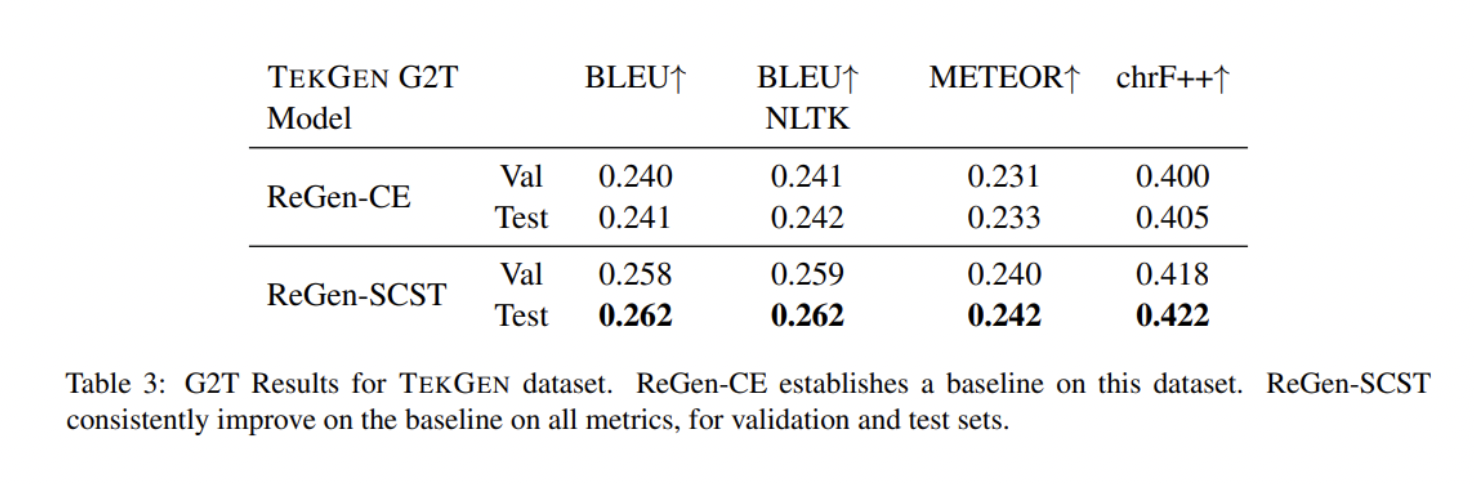
结果表明,通过SCST使用RL有利于WebNLG+ 2020和TEKGEN数据集上的图形和文本生成,显著改善了先前发布的结果,在WebNLG+ 2020的文本到图和图到文本生成任务中实现了最先进的性能。
在他们未来的工作中,研究人员计划开发一种SCST变体,它可以更好地利用图的独特结构——要么通过执行更合理的图依赖采样,要么通过研究更适合图内容和结构整合的替代奖励方案。
(张梦婷编译,周子喻校对)
无限内存Transformer:在不增加计算负担的情况下处理任意长上下文
阅读小说时,人们自然会记住相关的情节信息,即使它出现在许多章节之前。 尽管今天基于Transformer的语言模型在自然语言处理方面取得了令人瞩目的进步,但它们在这方面却举步维艰,因为建模长期记忆所需的计算量随文本长度成二次方增长,最终将超过模型的有限内存容量。
为了克服这一限制,来自Instituto de Telecomunicações、DeepMind、系统与机器人研究所、Instituto Superior Técnico 和 Unbabel的研究团队提出了“∞-former”——一种配备无限长期记忆(LTM)的Transformer模型,使其能够处理任意长的上下文。
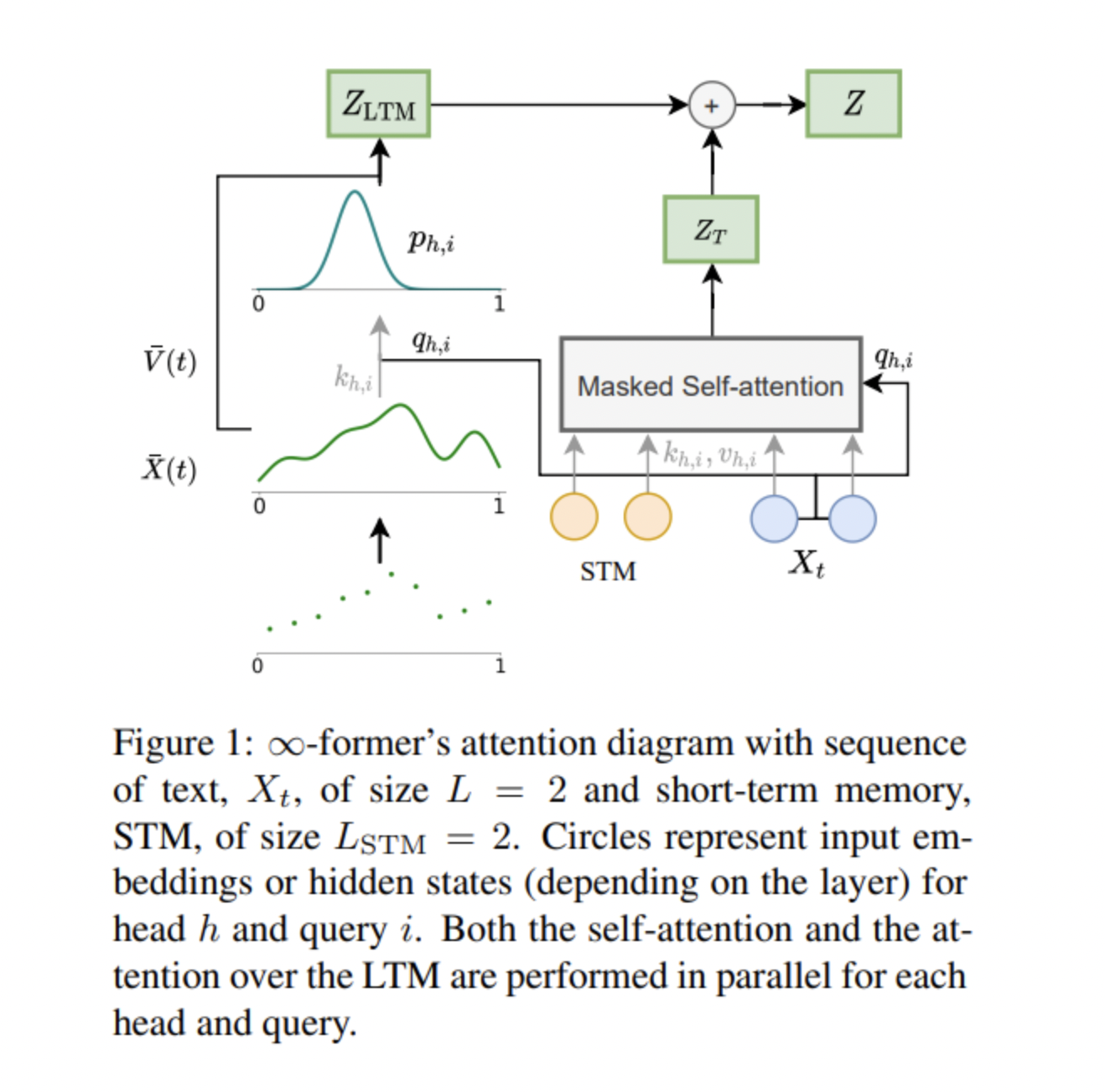
该团队将他们的研究贡献总结为:
- 1.提出∞-former,其中我们用连续的长期记忆扩展了Transformer模型。 由于注意力计算复杂度与上下文长度无关,∞-former能够对长上下文进行建模。
- 2.提出一个过程,允许模型在内存中保留无界上下文。
- 3.引入粘性记忆,这是一个强制执行 LTM 中重要信息持久性的过程。
- 4.在考虑越来越长的序列的合成任务和语言建模中,通过从头开始训练模型。微调预训练的语言模型,进行经验比较。这些实验显示了使用无限内存的好处。
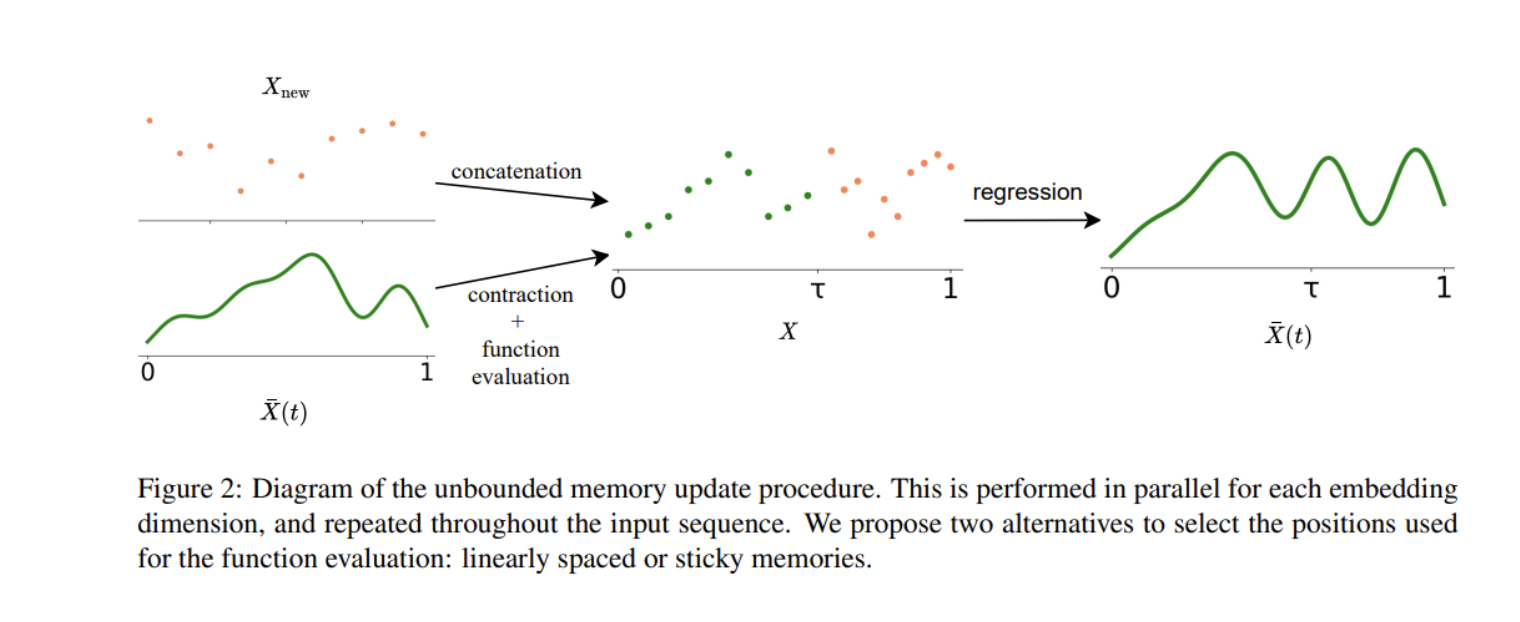
该团队使用连续LTM扩展了普通的Transformer,使他们提出的 ∞-former能够访问远程上下文。新方法采用连续空间注意框架来处理LTM信号,其中关键矩阵的大小取决于基函数的数量,而不是所关注的上下文的长度。因此,模型的计算复杂度与上下文长度无关,使其能够处理任意长的上下文,而不会增加内存需求或计算负担。
为了评估他们提出的方法,研究人员使用Transformer-XL和压缩Transformer作为基线,对合成任务和语言建模任务进行了大量的实验。
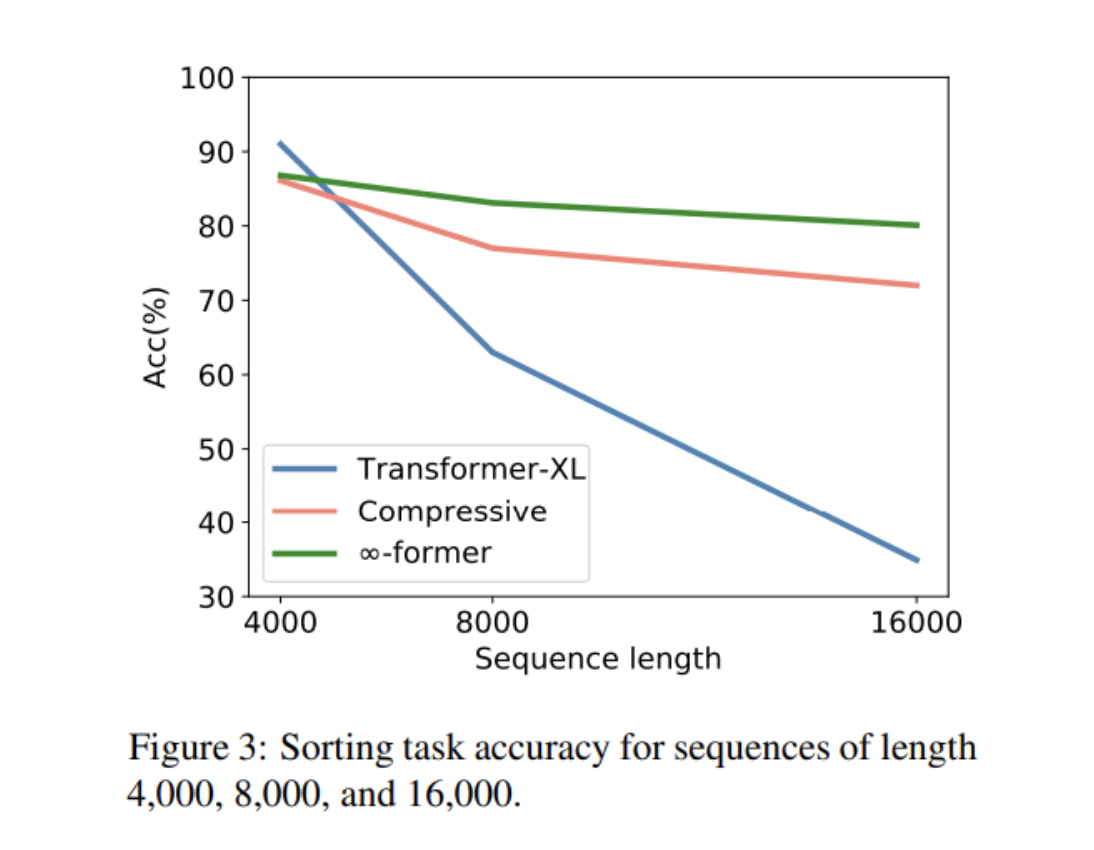
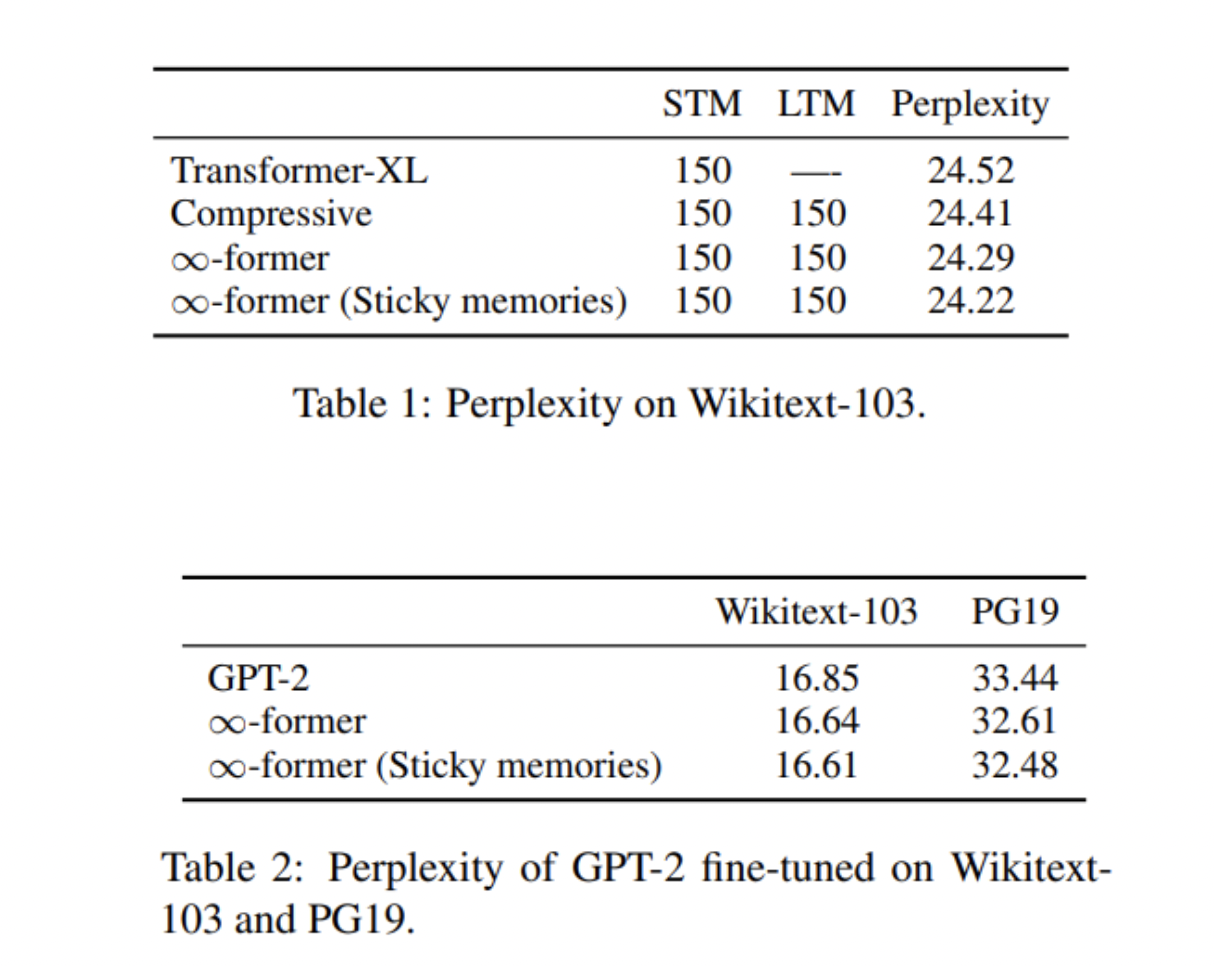
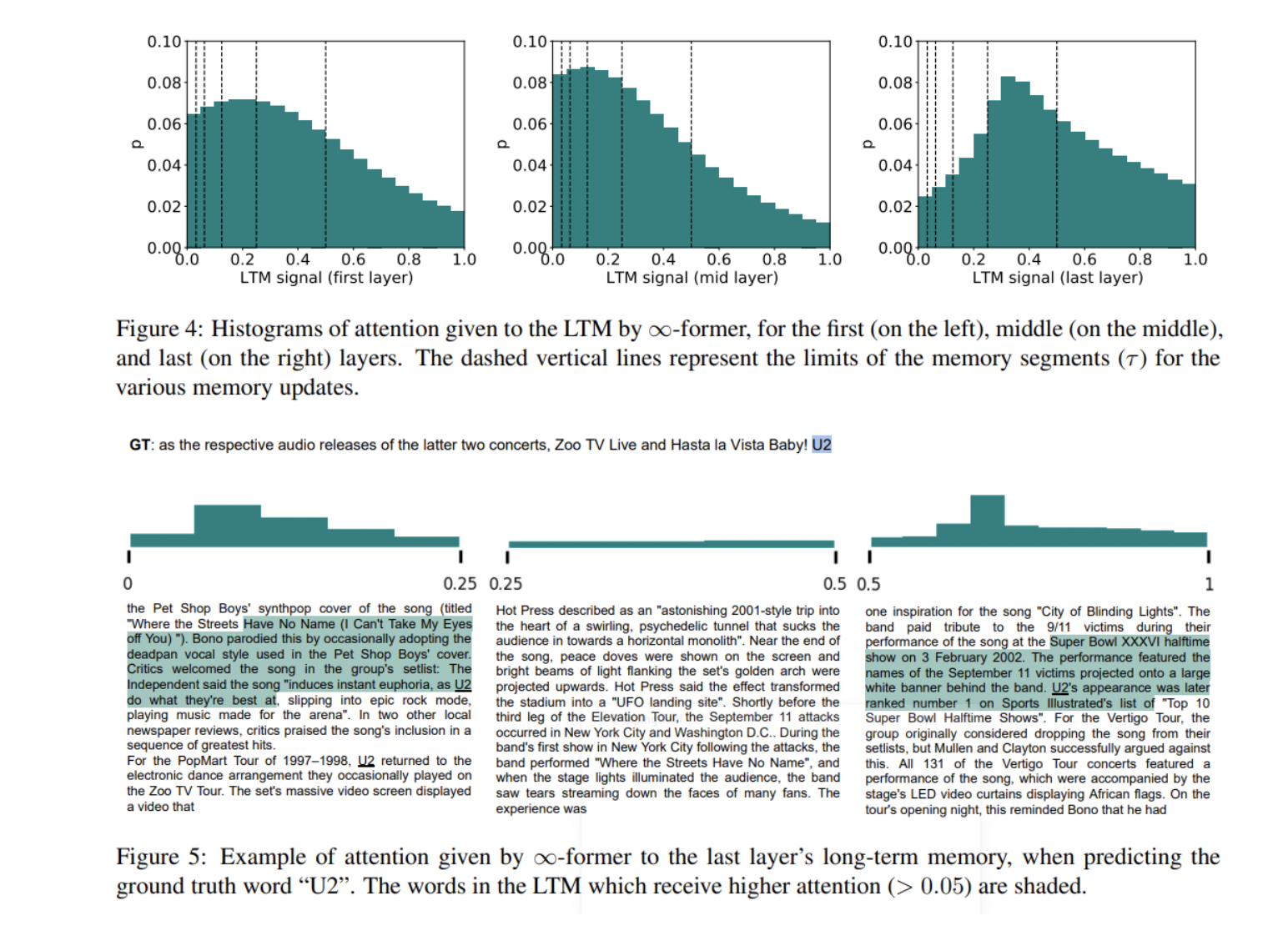
在合成任务实验中,Transformer-XL在内存长度较短的情况下取得了比压缩Transformer和∞-former稍好的性能,但随着序列长度的增加,其准确性迅速下降。压缩Transformer和∞-former的精度同时保持相对稳定。在语言建模实验中,∞-former略胜于压缩Transformer。
研究人员还注意到∞-former通过帮助模型专注于相关记忆来减少预训练模型(如GPT-2)中的困惑。
总体而言,该研究表明提出的∞-former可以扩展到长序列,同时保持高精度,并证明了无界长期记忆无论是在从头开始模型训练还是在预训练语言模型的微调中的多功能性和好处。
(张梦婷编译,赵海喻校对)
Google的零标签语言学习取得了与监督学习相媲美的结果
Google's Zero-Label Language Learning Achieves Results Competitive With Supervised Learning
虽然当代深度学习模型继续在广泛的任务中取得出色的成果,但这些模型对数据有着巨大的需求。大规模预训练语言模型(例如Open AI的GPT-3)的出现有助于减少自然语言处理中对特定任务标记数据的需求,因为模型学习到的上下文表示可以使用相对较小的训练数据集,对特定的下游任务进行微调。这些强大的大型语言模型最近还展示了它们通过小样本推理未见的NLP任务生成答案的能力。
在这一发展的推动下,一项新的谷歌人工智能研究探索了NLP中的零标签学习(仅使用合成数据进行训练),提出了无监督数据生成 (Unsupervised data Generation,UDG),这是一种新颖的训练数据创建程序,旨在在没有人工标注的情况下合成高质量的训练数据。

NLP 任务的少显示推理背后的机制是利用大型语言模型,根据手动制作的输入提示来推断正确的标签,该输入提示包括任务描述和一些样本输入标签对。 最近对大规模GPT-3模型的研究表明,通过使用有限的特定任务数据和无梯度更新,小样本推理可以获得与传统微调方法相当的性能。
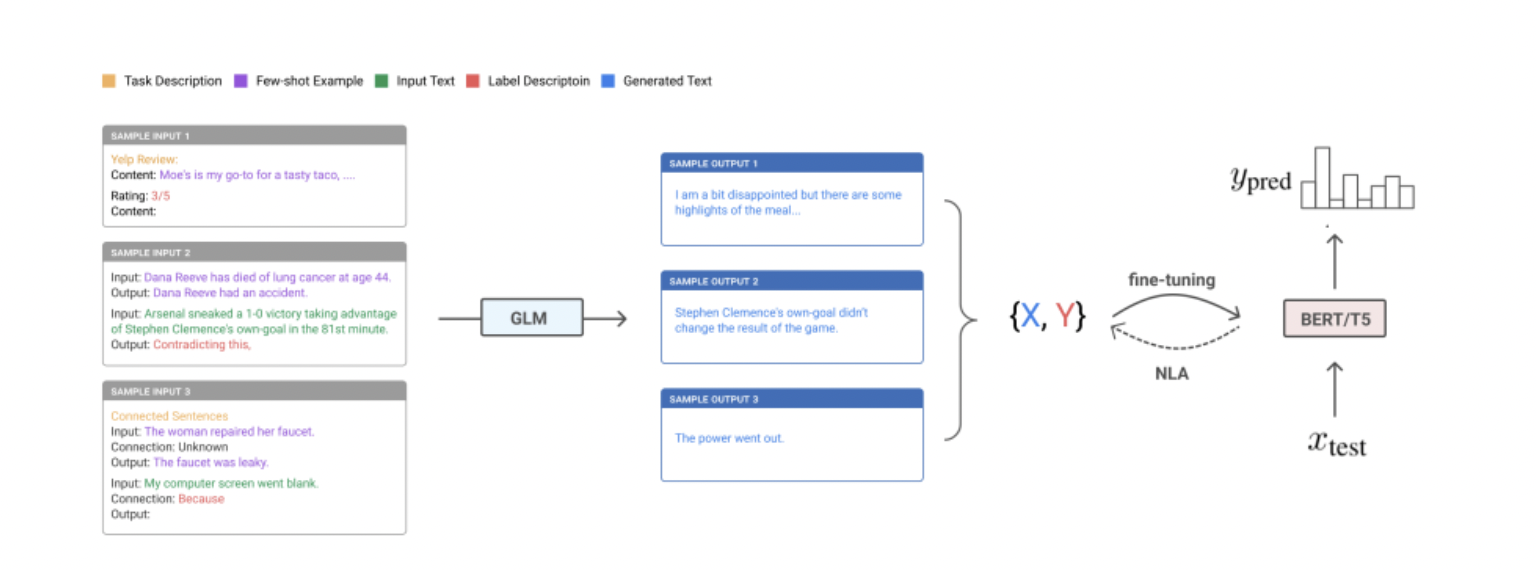
然而,在许多 NLP 任务上,使用大型语言模型的少样本推理方法的性能仍然落后于最先进的微调模型。研究人员认为,一个可能的原因是语言模型从未被明确训练来直接进行推理。因此,他们建议利用模型来执行少样本生成——而不是预测输出标签,而是让它们生成输入,目的是制定更可能自然存在于训练语料库中的输入提示。
与小样本推理不同,所提出的UDG框架只需要无监督的小样本示例——换句话说,它实际上是一个零标签学习设置。与现有的合成数据生成方法不同,它也不需要对生成模型进行微调,只使用无监督数据。
为了测试他们方法的性能,研究人员进行了文本分类和复杂的语言理解任务实验。
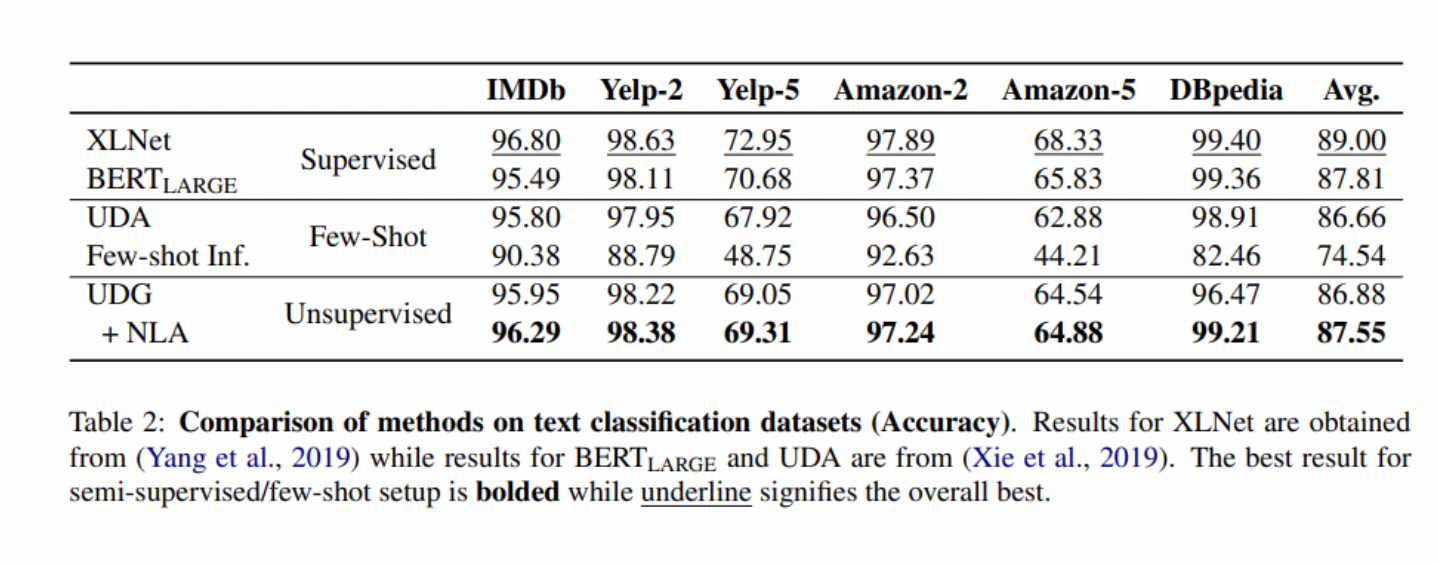
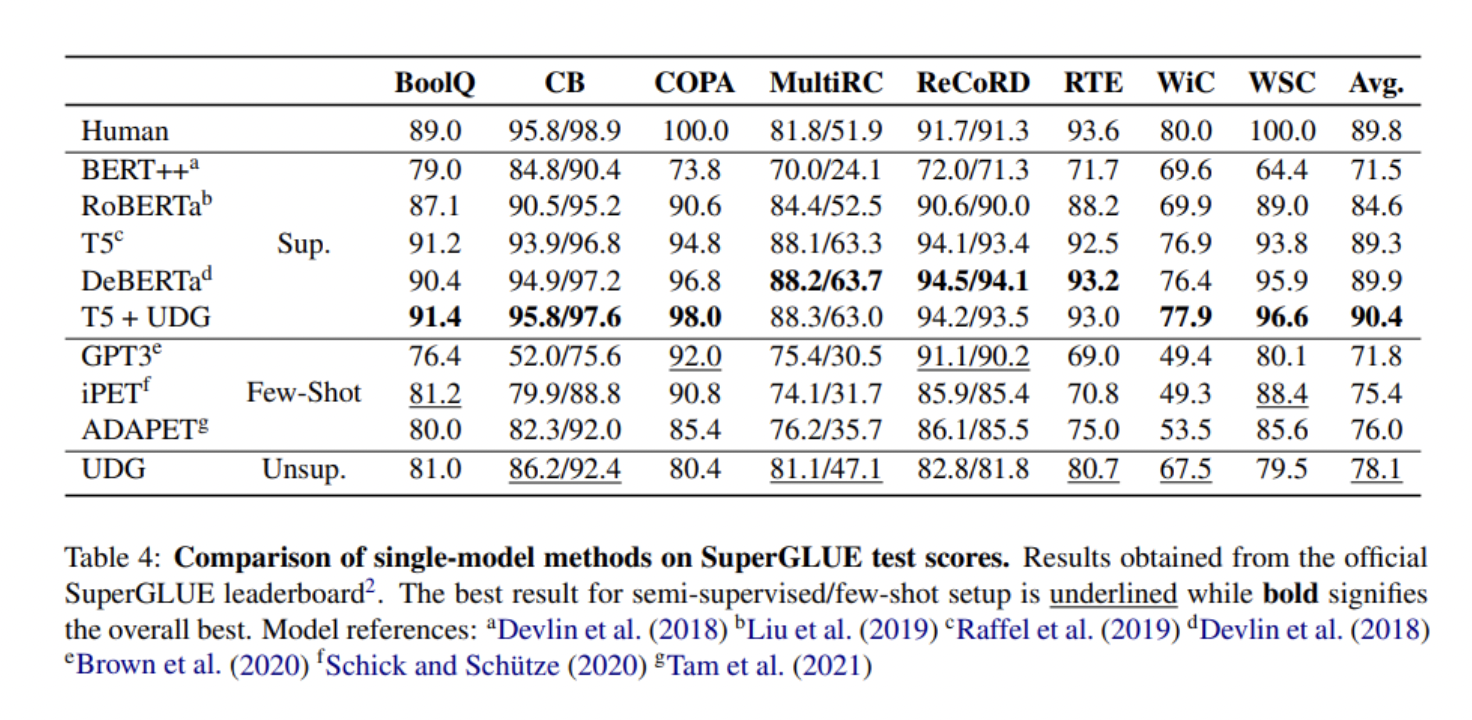
与在人类标记数据上训练的强基线模型相比,所提出的UDG取得了更好或可比的结果,并且在与标记数据结合时也被证明是一种高效的数据增强方法,在 SuperGLUE基准上实现SOTA性能。
总而言之,这项工作表明自然语言处理模型可以在没有任何人工标注标签的情况下获得较好的结果,为未来自然语言处理的迁移学习研究开辟了新方向。
(张梦婷编译,周子喻校对)
NYU和UNC揭示了Transformer在微调后的学习表现变化
NYU & UNC Reveal How Transformers' Learned Representations Change After Fine-Tuning
从哲学角度来看,还原论是世界上最自然的概念:通过理解其部分可以理解一个整体。当涉及到认知科学时,这个想法可以通过构成性原则来体现:人类根据感官观察推断结构和关系,并将这些信息与现有的知识结合起来,指导将较简单的意义构成复杂的整体。
对像BERT这样的预训练语言模型进行微调已经成为一种行之有效的方法,可以使这种基于Transformer的大型语言模型有效地转移到下游的自然语言理解任务中。然而,人工智能研究人员对微调如何改变神经网络的了解有限。
在论文Fine-Tuned Transformers Show Clusters of Similar Representations Across Layers中,来自NYU和UNC的一个研究小组使用中心核对齐(CKA)来衡量跨网络层表示的相似性并探索微调如何改变 Transformer的学习表征。

CKA 是比较学习过的表示的理想方法,因为它对比较表示的正交变换和各向同性缩放都是不变的。使用CKA,研究人员能够比较同一模型甚至不同模型各层之间表示的相似性。
该团队考虑了三种常用的语言编码模型:RoBERTa、ALBERT和ELECTRA;并对包括GLUE基准、BoolQ、Yelp Review极性分类以及HellaSwag和 CosmosQA多项选择任务在内的任务进行了实验。
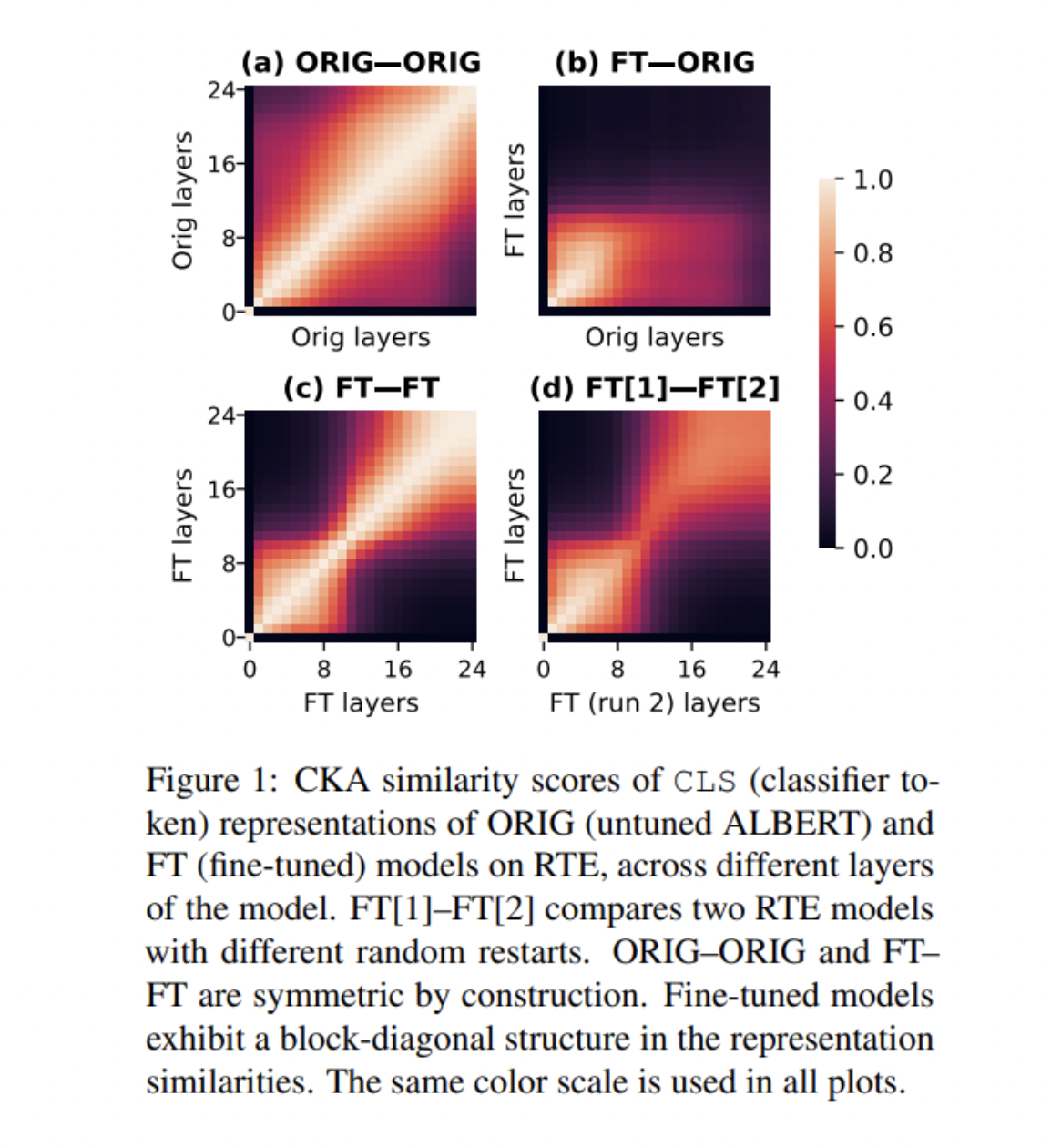
CKA相似性分数通过四种比较格式呈现,使用ALBERT在RTE上进行微调。 ORIG-ORIG格式显示了在RTE输入上未调优ALBERT模型层之间表示的相似性,而FT-ORIG在Y轴上显示了任务调整模型的层,在X轴上显示了未调整模型的层。FT-FT格式同时比较了单个微调模型中的层,FT[1]-FT[2]格式比较了两次随机重启的微调ALBERT模型。

团队的实验结果表明,表示相似性的块对角线结构几乎出现在每个 RoBERTa和ALBERT模型中。后面层的显著相似性表明,这些层中的许多层可能对手头的任务没有显著贡献。 该团队进一步观察到,任务调整后的RoBERTa 和ALBERT模型的后面层通常可以在不牺牲任务性能的情况下被丢弃,从而验证后面的层确实具有相似的表示。
然而,在ELECTRA模型中,后来层的表示通常被认为是高度不同的。研究人员表示,这可能是由用于ELECTRA模型所使用的不同预训练任务造成的,但要充分了解这些差异还需要进一步研究。
总体而言,该研究为关于Transformer学习表示如何通过微调而变化提供了新见解,揭示了任务调整后的RoBERTa和ALBERT模型的表示相似模式,其中早期层表示和后期层表示形成两个不同的蔟,具有高蔟间相似性和低蔟间相似性。
(张梦婷编译,赵海喻校对)
项目工具
基于BERTopic的动态主题建模
BERTopic是一种主题建模技术,它利用BERT嵌入和c-TF-IDF创建密集的集群,允许轻松解释主题,同时在主题描述中保留重要词语。BERTopic的两大优势是其开箱即用性和新颖的交互式可视化方法。对模型学习的主题有一个全面的了解,可以让我们对模型的质量和语料库中封装的最显著的主题有一个内部感知。
安装

如果您预计您的项目将使用BERTopic软件包附带的可视化选项,请按如下方式安装:

构建基本的BERT主题模型
要在Python中创建BERTopic对象并转到有趣的东西(动态主题建模),我们只需要预处理的文档列表。使用pd.read_csv()加载数据后,我们可以编写一些lambda apply函数来预处理文本数据:
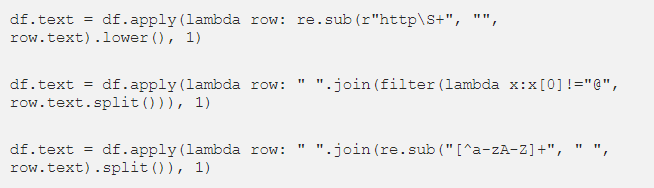
如果已经清理过,我们可以准备两个变量。最关键的变量显然是我们的文档列表,我们称之为标题。其次,我们需要一个与每个文档对应的日期列表,以便我们能够深入了解主题是如何随时间而变化的。


我们可以根据分配给每个主题的主题数量提取最大的十个主题,还可以预览主题的基于关键字的“名称”,如前所述:

注意,在上面的数据框架中,topic-1表示由异常文档组成的主题,这些文档通常被忽略,因为术语在整个语料库中具有相对较高的流行性,因此对任何内聚主题或主题的特异性较低。
我们还可以查看构成特定感兴趣主题的术语:

交互式可视化
这项技术最重要的一点是能够可视化我们的主题模型,让我们充分了解我们的数据,而无需调查原始文本本身。BERTopic有自己的intertopic距离图实现,其中包括一个悬停工具提示,显示指定给特定主题的文档数量以及该主题中最常见的前5个术语。生成以下可视化所需的代码行非常简单:

(张梦婷编译,赵海喻校对)
近期论文
Enriching and Controlling Global Semantics for Text Summarization
摘要
最近,基于Transformer的模型已经被证明在生成式自动文摘任务中是有效的,它可以创建流畅和信息丰富的摘要。然而,这些模型仍然存在短期依赖问题,导致它们生成的摘要忽略了文档的关键点。在本文中,我们试图通过引入一个神经主题模型来解决这个问题,该模型具有规范化流的能力来捕获文档的全局语义,然后将其集成到摘要模型中。此外,为了避免全局语义对上下文化表示的压倒性影响,我们引入了一种机制来控制提供给文本生成模块的全局语义的数量。我们的方法在五种常见的文本摘要数据集(即CNN/DailyMail、XSum、Reddit TIFU、arXiv和PubMed)上的表现优于目前最先进的摘要模型。
主要贡献
论文的贡献可以总结如下:
- 1.我们提出了一种新颖的架构,它在执行生成式摘要时考虑了全局语义。
- 2.我们引入了一种神经主题模型,该模型具有规范化流程以丰富全局语义和上下文门控机制,以更好地控制全局语义对隐藏表示的影响。
- 我们在五个基准数据集(即 CNN/DailyMail、XSum、Reddit TIFU、PubMed 和 arXiv)上进行了大量实验并优于其它最先进的摘要模型,同时生成有利于人类判断的摘要,并生成人类可解释的主题。
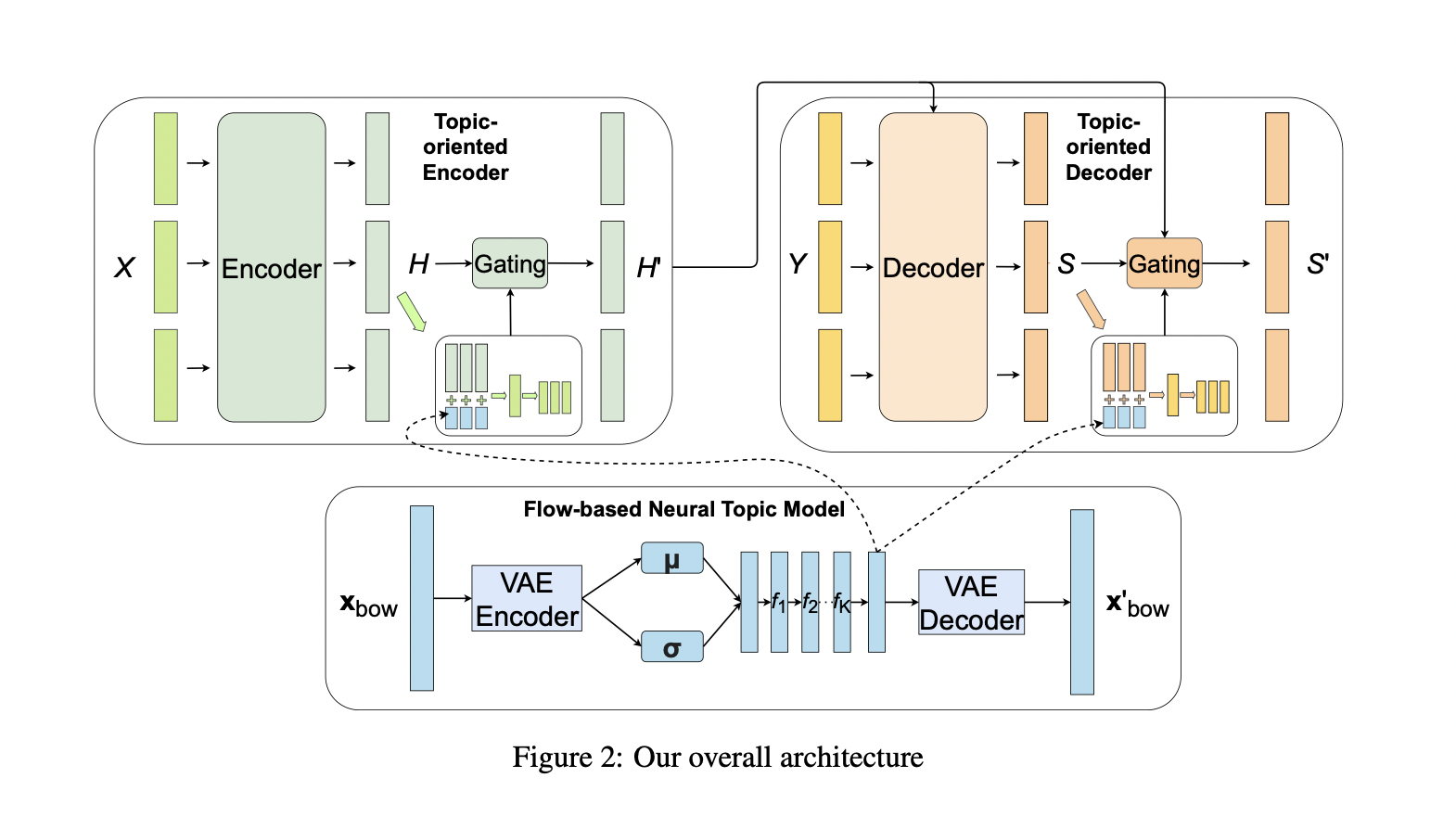
整体架构上图所示。它包括一个面向主题的编码器(topic-oriented encoder)、一个面向主题的解码器(topic-oriented decoder)和一个基于流的神经主题模型(flow-based neural topic model)。
实验

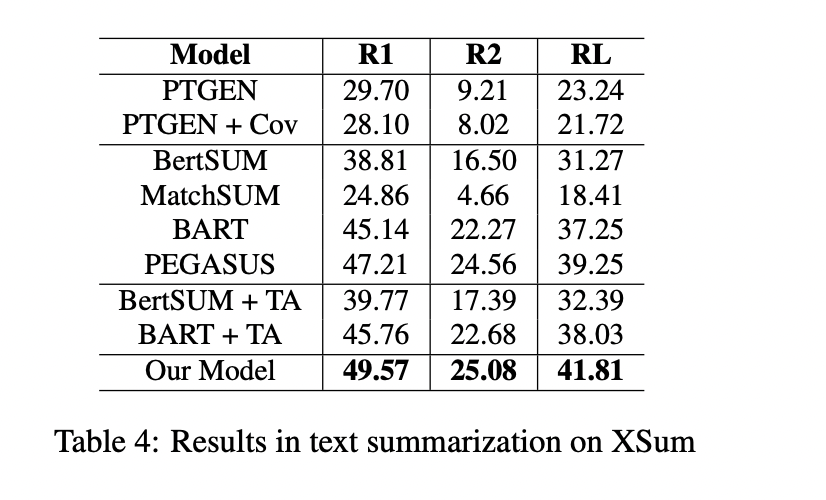
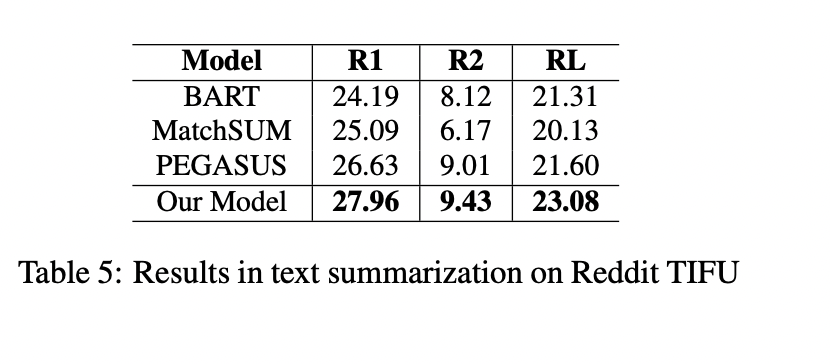
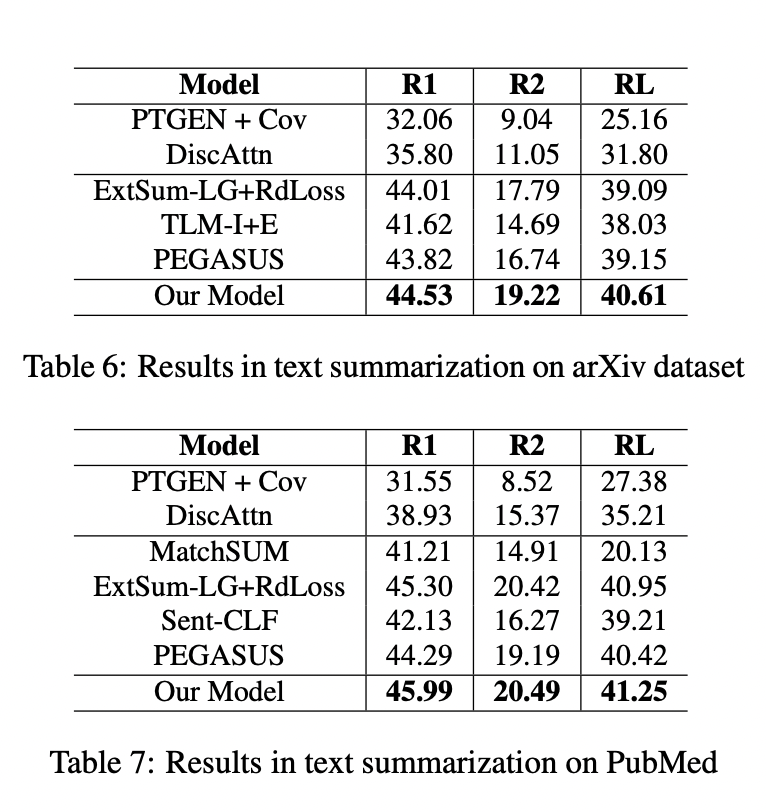
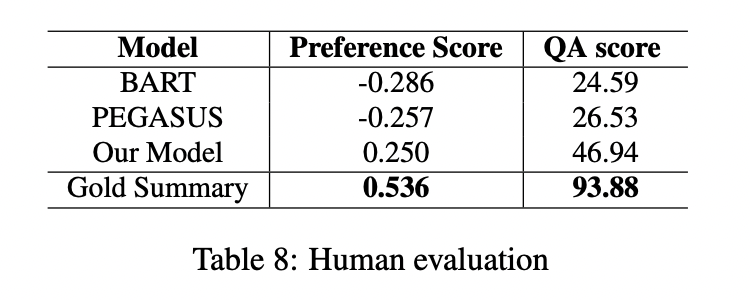
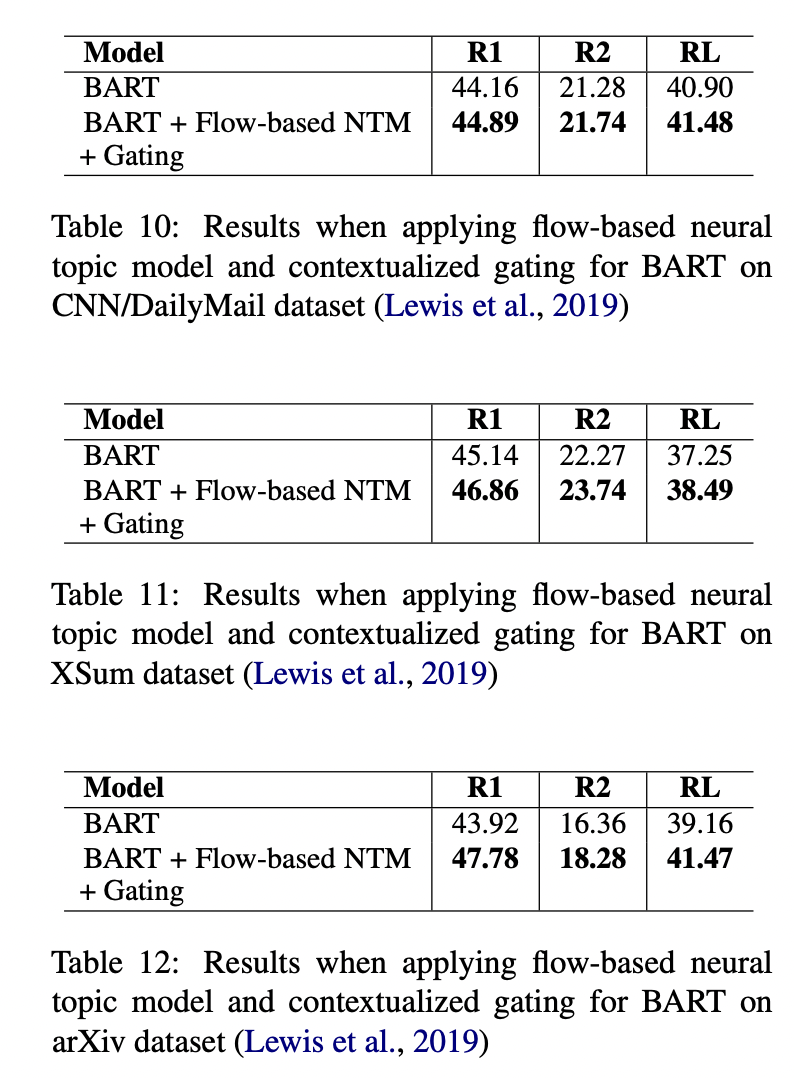
(张梦婷编译)
近期会议
NLPCC 2021:Natural Language Processing and Chinese Computing
Oct 12 - Oct 17 Chennai, India
NLPCC是一个领先的国际会议,专门研究自然语言处理(NLP)和中文计算(CC)领域。NLPCC在CCF推荐的CS会议列表中。它是学术界、工业界和政府的研究人员和实践者分享他们的想法、研究成果和经验,并促进他们在该领域的研究和技术创新的主要论坛。
(张梦婷)