文本挖掘与机器学习跟踪扫描动态快报(2020.03)
实时跟踪、关注文本挖掘与机器学习领域最新研究动态
研究动态
如何在Python中使用NLP:实用的分步示例
在本文中,我们将介绍有关确实职位发布的分步NLP应用程序。
Preparation:收集数据
我们从8个不同的城市抓取了提供给“数据科学家”的职位。抓取后,我们将数据下载到每个城市的单独文件中。
此分析中包括的8个城市是波士顿,芝加哥,洛杉矶,蒙特利尔,纽约,旧金山,多伦多和温哥华。变量是job_title,company,location和job_description。
我们将从这些数据中总结出雇主所需的技能和最低学历。
步骤#1:加载和清理数据
首先,我们将8个城市的数据文件加载并合并到Python中。

我们将删除具有相同job_title,job_description和城市功能的重复行(职位发布)。

现在我们有了一个包含5个要素和2,681行的数据集。

步骤#2:形成关键字列表
在搜索职位描述之前,我们需要代表工具/技能/学位的关键字列表。
对于此处的分析,我们使用一种简单的方法——基于我们的判断和职位发布的内容来形成列表。如果任务比此复杂,则可以改用更高级的方法。
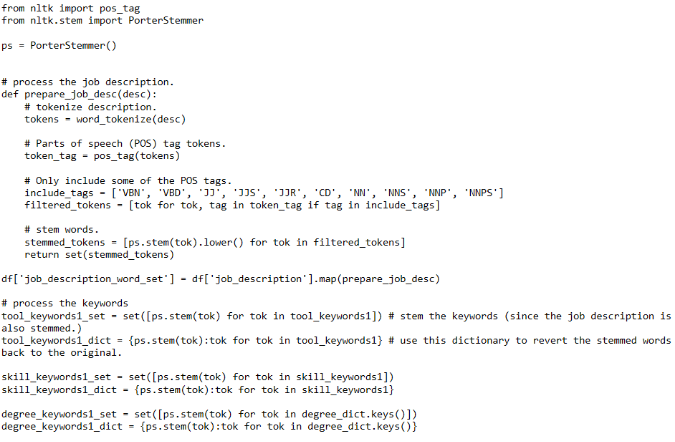
对于工具关键字,我们首先根据数据科学知识提出一个列表。我们知道,数据科学家常用的工具包括Python,R,Hadoop,Spark等。我们在该领域拥有丰富的知识。因此,这份最初的清单很不错,可以涵盖职位发布中提到的许多工具。
然后,我们查看随机的职位发布信息并添加列表中尚未列出的工具。通常,这些新关键字会提醒我们自己添加其他相关工具。
完成此过程后,我们将获得一个关键字列表,其中涵盖了职位发布中提到的绝大多数工具。
接下来,我们将关键字分为一个单字列表和一个多字列表。我们需要以不同的方式将这两个关键字列表与职位描述进行匹配。
通过简单的字符串匹配,多词关键字通常是唯一的,并且在职位描述中易于识别。
本文中的单词关键字(例如“c”)是指C编程语言。 但是“c”也是一个常见的字母,在很多词中都使用过,包括“can”,“clustering”。我们需要进一步处理它们(通过tokenization),使其仅在职位描述中有单个字母“c”时才匹配。
以下是我们使用Python编码的工具的关键字列表。

通过与工具类似的过程,我们可以获得技能关键字列表。

对于教育水平,我们使用不同的方法。
因为我们正在寻找最低要求的教育水平,所以我们需要一个数值对教育程度进行排名。例如,我们用1表示“学士”或“本科”,用2表示“硕士”或“研究生”,依此类推。
这样,我们就可以从1到4的数字对学位进行排名。数字越高,受教育程度越高。

步骤#3:使用NLP技术简化职位描述
在这一步中,我们将简化职位描述文本。使文本更容易被计算机程序理解; 因此能够更有效地将文本与关键字列表匹配。
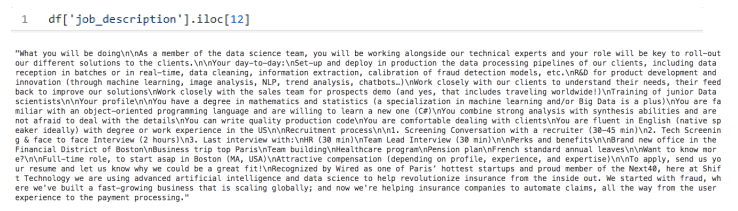
我们的数据集中的job_description功能如下所示。
Tokenizing the Job Descriptions
Tokenization是将文本字符串解析为不同部分(tokens)的过程。这是重要的一步的,它可以使计算机程序可以更好地理解标记化的文本。
我们必须将Job Descriptions的文本字符串显式拆分为带有分隔符(例如,空格(“”))的不同tokens(words)。我们使用word_tokenize函数来处理此任务。

在此过程之后,Job Descriptions文本字符串将如下划分为tokens(words)。 计算机可以更轻松地读取和处理这些tokens。
例如,单字关键字“c”只能与tokens(words)“c”匹配,而不能与其他单词“can”或“clustering”匹配。

下面我们将Tokenization与接下来的几个步骤结合在一起。
Parts of Speech(POS)标记Job Descriptions
Job Descriptions描述通常很长。 我们希望保留有助于分析的信息,同时过滤掉其他信息。我们使用POS标记实现此目的。
POS标记是一种NLP方法,用于标记单词是否为名词,形容词,动词等。维基百科对此进行了很好的解释:
POS标记是基于其定义和上下文在文本(语料库)中将单词标记为与之对应的说话时的特定部分(即其与短语,句子,段落或单词中相邻单词的关系)的过程。通常将这种简化形式教给学龄儿童,将单词识别为名词,动词,形容词,副词等。
将这种算法应用到关键字列表中,可以找到与我们分析相关的标签。
接下来,我们用POS标记工具关键字列表作为演示。

字母的不同组合代表标签。例如,NN代表名词和单数单词,例如“python”,JJ代表形容词,例如“big”。表示的完整列表如下。

如我们所见,标记器并不完美。例如,“sql”被标记为“JJ”(形容词)。 但这仍然足以帮助我们过滤有用的单词。
我们将所有关键字的标签列表用作Job Descriptions的过滤器。我们仅保留Job Descriptions中具有这些相同关键字标签的单词。例如,我们将职位描述中的单词保留为“NN”和“JJ”标签。通过这样做,我们从职位描述中过滤掉了对我们的分析没有帮助的,诸如“the”,“then”之类的单词。
在此阶段,我们已经简化了tokenized的Job Descriptions。
步骤#4:关键字和Job Descriptions的最终处理
在此步骤中,我们将进一步处理关键字列表和Job Descriptions。
Stemming the Words(词干)
词干是将变型(或有时衍生)的词减少为词干,基词或词根形式(通常是书面词形式)的过程。
词干处理允许计算机程序识别相同词干的词,尽管它们的外观不同。这样,只要词干相同,我们就可以匹配它们。例如,单词“models”,“modeling”都具有“model”的相同词干。
我们同时列出关键字列表和简化的Job Descriptions。
Lowercasing the Words(小写)
最后,我们通过小写将所有单词标准化。 由于关键字列表以小写形式构建,因此我们仅将Job Descriptions描述小写。
以下过程中使用了Python代码如下。
现在仅保留与我们的分析相关的Job Descriptions中的tokens(words)。 最终Job Descriptions的示例如下。


最后,我们准备好进行关键字匹配!
步骤#5:匹配关键字和Job Descriptions
为了查看Job Descriptions中是否提到了特定的关键字,我们将关键字列表和最终精简的Job Descriptions进行匹配。
Tools/Skills
在最初,我们构建了两种类型的关键字列表——单字列表和多字列表。对于单字关键字,我们通过设置交集函数将每个关键字与职位描述进行匹配。对于多字关键字,我们检查它们是否是职位描述的子字符串
Education
对于教育水平,我们使用与工具/技能相同的方法来匹配关键字。但是,我们只跟踪最低水平。
例如,当职位描述中同时存在关键字“学士”和“硕士”时,学士学位是该职位所需的最低学历。
以下是具有更多详细信息的Python代码。

步骤#6:结果可视化
我们用条形图总结结果。
对于工具/技能/教育水平的每个特定关键字,我们计算与之匹配的职位描述的数量。我们还计算了他们在所有职位描述中的百分比。
对于工具和技能列表,我们仅列出前50名最受欢迎的工具和技能。对于教育水平,我们根据所需的最低水平对其进行汇总。
详细的Python代码如下。
热门工具需求

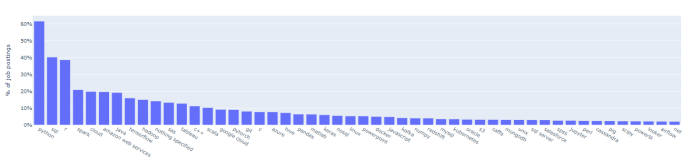
面向数据科学家的50大工具
热门技能需求
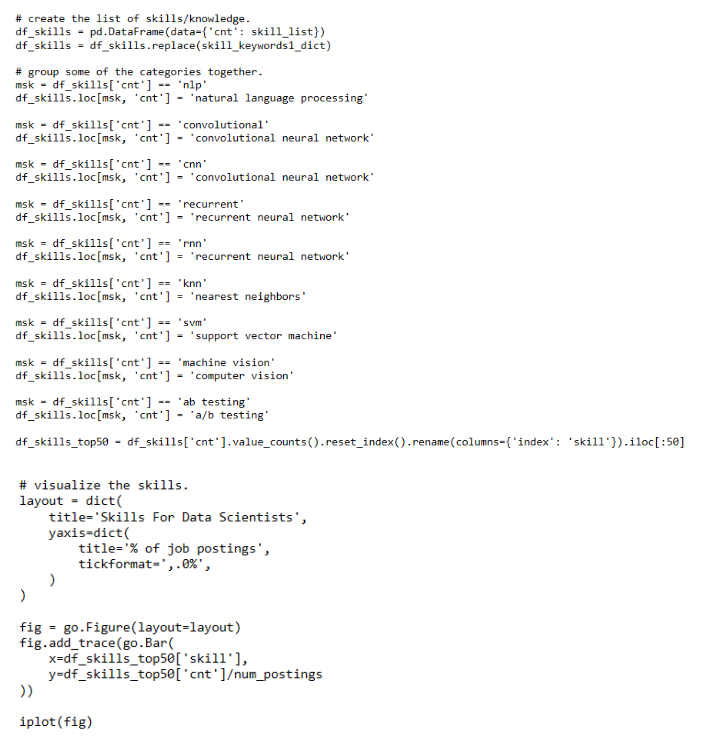
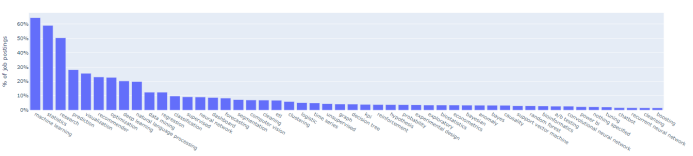
数据科学家最需要的前50个技能
最低学历要求

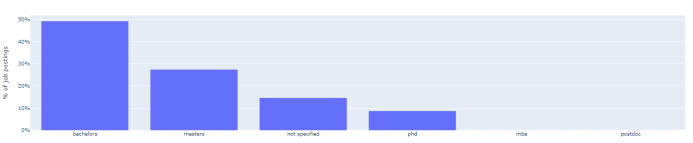
数据科学家的最低教育水平
(李朝安编译,王宇飞校对)
用代码理解数学符号
对于任何有兴趣从事机器学习和数据科学的事业或研究的人来说,总有一天他们会超越python库,跟随好奇进入这一切背后的数学世界。通常,这将带你进入一个大量公开的论文集,详细说明其工作原理。你对核心数学的理解越深入,就越有可能灵光一现地创造出一种新方法。在你遇到类似以下内容之前,第一篇文章上的所有内容似乎都还不错:
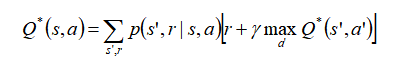
对于那些学了多年数学或在机器学习的数学水平上工作过的人来说,这样的方程可以解析为代码。但是对于许多其他人来说,这看起来像象形文字。事实是,古代数学领袖似乎选择了最有趣的外观符号来描述相当直观的方法。结果是:方程和变量看起来比实际复杂得多。
我发现代码不仅可以用于编写程序,还可以用于解释复杂性的全球通用语言。当我学习所有数据科学背后的数学时,我总是发现获得对数学的普遍理解的最佳方法是编写代码段来描述方程式。最终,这些符号几乎可以被理解为一篇典型论文中的文本。在本文中,我希望与大家分享一些用代码描述数学的例子!
求和与乘积
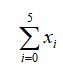
求和符号是迭代数学中最有用、最常用的符号之一。尽管其设计复杂,但实现相当简单,也非常有用。

如上所示,此符号代表的所有内容都是从顶部的数字开始的for循环,在顶部的数字范围内。在底部设置的变量将成为索引变量,并且每个循环的所有结果都将添加到总值中。较不常见的是,可以使用以下方法:
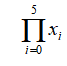
通常称为乘积运算符,该符号以相同的方式起作用,但不是将每个结果相加,而是将它们相乘。

阶乘
阶乘是“!”,几乎所有计算器上都存在。对许多人来说,这可能更明显一些,但是仍然值得编写一些代码以了解其原理。
5!将表示为:

条件表达式
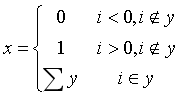
条件括号用于根据一组条件转移方程的流程。对于编码人员,这只是常见的“if”语句。以上条件可以表示为:

如上所示,括号中每一行的正确表示法指定了每条路径应执行的操作。我也将多余的“包含”符号添加到每个条件中,以增加更多的见解。如上所示,我们检查了i值是否在y列表中。认识到确实如此,我们返回了数组的总和。如果i值不在数组中,我们将基于该值返回0或1。
点乘和笛卡尔矩阵乘法
最后,我想快速介绍一下数据科学家通常使用的喜欢的语言库(矩阵乘法)完成的操作。最容易理解的形式是逐点运算。简写为:
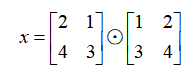
注意,第一个要求是每个矩阵必须具有相同的形状(即# rows= & #Columns=).代码如下:

最后,让我们看一下机器学习中最常用的典型矩阵乘法过程。用复杂的术语来说,此运算将找到每个主要行与每个次要列的点积。这样做的主要要求是:假设[#rows,#columns]→矩阵ixj要求#columns(i)== #rows(j)→最终产物的形状为[#rows(i), #columns(j)]
这可能看起来有些令人困惑,我最好的建议是查看一些很好的可视化效果。

这只是几个示例,但是对这种简单代码的理解可以使任何程序员承担起初不祥的数学世界。当然,这些方法都可以合并以提高效率,并且通常具有易于使用的库方法。用简单的代码编写这些代码的目的是查看以真实操作的形式写出它们时的意义。
(张梦婷编译,王宇飞校对)
通过数据回传加速神经网络训练
2019年10月,澳大利亚墨尔本的一名亚马逊员工在骑自行车的路上撞上了一个人。当她向那个人保证她会帮忙时,她意识到他是聋哑人,不知道他在说什么。
如果有辅助技术来促进双方的沟通,这种尴尬局面本可以避免。事件发生后,亚马逊网络服务(Amazon Web Services)东南亚技术主管Santanu Dutt领导的一个团队开始工作。
在10天左右的时间里,Dutt的团队建立了一个用手语训练机器学习模型。通过使用从相机上拍摄的手势语手势的图像,该模型可以识别手势并将其转换为文本。该模型还可以将口语转换成文本,供聋哑人阅读。
Dutt说,随着机器学习服务和应用程序接口(API)的出现和开放,该模型还可以定制为将语音转换为手语——尽管他还没有看到这种需求。但仍有需要改进的地方:由于训练是在白色背景下用手势进行的,因此在实际使用中,目前形式的模型的效果将受到限制。
Dutt团队展示这一点的时间有限,但他们希望能拿出一些东西来展示,用于实验目的。企业可以使用Amazon SageMaker等工具,用更多的图像和视频来编辑和训练模型,以识别更大范围的环境。这也将有助于提高模型的准确率。事实上,拥有的数据越多,模型就越精确。开发人员可以设置置信水平,并拒绝低于某一准确水平的结果。
Dutt表示,AWS的公共部门团队已经与澳大利亚的非营利组织进行了合作,以利用机器学习模型来进行概念验证,以抵销使用AWS服务进行训练和部署该模型的成本。
(张梦婷编译,王宇飞校对)
开源BiT:探索计算机视觉的大规模预训练
现代深层神经网络总是渴望得到更多的标记数据——目前最先进的CNNs需要在诸如OpenImages或Places这样的数据集上进行训练,这些数据集包含超过1百万个标记图像。事实上,收集如此庞大规模的数据是困难的。而缓和计算机视觉任务中标记数据不足问题一种常见方法是使用经过通用数据(如ImageNet)预训练的模型。其思想是,在通用数据上学习到的视觉特性可以重新用于感兴趣的任务。尽管这种预训练在实践中相当有效,但它仍然缺乏快速掌握新概念并在不同背景下理解新概念的能力。类似于BERT和T5在语言领域的进步,我们认为大规模的预训练可以提高计算机视觉模型的性能。
在“Big Transfer(BiT):一般视觉表征学习”中,我们设计了一种方法,可以使用超出实际标准规模的图像数据集(ILSVRC-2012)进行有效的一般特征预训练。在训练数据规模很大的情况下,适当选择规范化层和缩放体系结构容量是极为重要的。
苹果和谷歌将在五月中旬引入一对iOS和Android的API,并确保这些卫生部门的应用程序能够实现它们。在此阶段,用户仍必须下载应用程序才能参与联系人跟踪,这可能会限制采用率。但是在API完成后的几个月内,两家公司将致力于在基础操作系统中构建跟踪功能,使此功能作为每个使用iOS或Android手机的人都可以立即使用的选项。
- 预训练
- 迁移学习
- 使用ObjectNet进行评估
首先研究的是数据集大小和模型容量之间的关系。利用经典的ResNet架构,在ILSVRC-2012(1.28M)、ImageNet-21K(14M)和JFT(300M)这三个数据集上,分别训练了从标准的50层深的“R50x1”,到4倍宽、152层深的“R152x4”的变体。一项主要的观察结果是,若想在更大的数据集上获得更好的训练效果,就需要增加模型容量。
研究发现训练时间至关重要。如果在较大的数据集上进行预训练而不调整计算预算和训练时间,那么性能可能会变得更差。然而,通过使时间表适应新的数据集,改进可能会很显着。
此外,用群规范化(GN, group normalization)代替批规范化(BN, batch normalization)也是有利于大规模训练的。首先,BN的状态(神经激活的均值和方差)需要在预训练和迁移之间进行调整,而GN是无状态的,因此避开了这一困难。第二,BN使用批处理级别的统计数据,大型模型不可避免地出现小设备(small per-device)批处理量,BN就会变得不可靠。由于GN不计算批处理级别的统计数据,因此它也回避了这个问题。
遵循BERT在语言领域建立的方法,我们针对来自各种“下游”任务的数据(可能带有很少的标记数据)微调了预训练的BiT模型。由于预先训练的模型已经对视觉世界有了很好的理解,所以这个简单的策略非常有效。微调涉及大量超参数,例如学习率、权重衰减等。研究人员提出了一种启发式的方法来选择这些超参数,称之为“BiT-HyperRule”。该方法仅基于高层次的数据集特征,例如图像分辨率和标记实例的数量。
当用很少的例子将BiT转移到任务时,随着同时增加用于预训练的通用数据量和体系结构容量时,生成的模型适应新数据的能力显著提高。
为了验证这个结果是否具有普遍性,研究人员在VTAB-1k上进行了实验。VTAB-1k是由19个不同任务组成的任务套件,每个任务只有1000个标记示例。BiT-L模型(在JFT-300M上进行预训练)迁移到这些任务上后,获得了76.3%的总得分,比此前的SOTA方法提高了5.8%。

另外,BiT-L在标准CV基准Oxford Pets、Flowers、CIFAR上的结果也表明,这种大规模预训练和简单迁移的策略在数据量适中的情况下也是有效的。在MSCOCO-2017检测任务中使用BiT作为RetinaNet的骨干,发现即使对于这样一个结构化的输出任务,使用大规模的预训练也有相当大的帮助。
为了进一步评估BiT的鲁棒性,研究人员还在基于真实照片的ObjectNet数据集上对模型进行验证。BiT-L模型的top-5精度刷新记录,达到80%,比此前的SOTA方法提高将近25%,这使得数据和架构规模的好处更加明显。

(张梦婷编译,王宇飞校对)
BERTLang帮助研究人员在BERT模型之间进行选择
由Jacob Devin领导的Google团队于2018年推出了强大的BERT语言模型,在自然语言处理领域(NLP)取得了许多突破。基于行业领先搜索性能建立品牌的谷歌表示,BERT甚至大大改善了对搜索查询的理解。
Google还发布了一个多语言语言模型mBERT,它是在104种语言的语料库上训练的,可以作为通用语言模型使用。尽管NLP研究社区从使用特定语言训练的BERT模型中看到了令人印象深刻的性能,但mBERT与这些特定于语言的BERT模型之间还没有明确的比较。为了从架构、任务和领域的角度评估每个模型的优势,来自Bocconi大学的一个研究团队准备了一个在线概述,介绍特定语言的BERT模型和mBERT之间的共性和差异。
目前,GitHub大约有5000个项目库提到了“BERT”。对于研究人员而言,决定哪种特定语言的模型最适合他们的需求是一个可以影响整个研究项目的选择。在特定语言上训练并在特定数据域和任务上测试的模型通常从诸如维基百科、新闻、立法和行政测试、翻译的电影字幕等来源获取其训练数据。常见的NLP任务包括命名实体识别、自然语言推理、释义识别,为了理解不同的模型和任务以及它们之间的相互关系,博科尼大学的研究团队启动了“BertLang”网站。
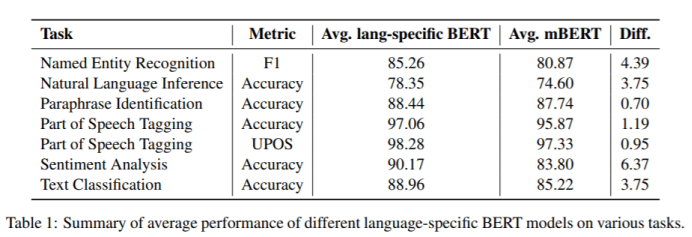
该团队表示,确定哪些mBERT或特定于语言的模型在特定任务中表现最佳,对于NLP的进度非常重要,而且还可能影响计算资源的使用。他们在18种语言的29个任务中测试了30种经过预训练的特定于语言的BERT模型,获得了177种不同的性能结果。
在所有29项任务中,特定语言的BERT模型得分均高于mBERT。交叉检查不同语言特定的BERT模型在不同任务上的平均性能提供了更多的见解。例如,研究人员观察到,与mBERT相比,专门用于低资源语言(如蒙古语)的模型显示出最高的改进。该论文表明,这是因为特定语言的BERT模型的开发人员很可能是维基百科以外的适当开发资源的来源和使用方面的专家。
(张梦婷编译,王宇飞校对)
通过数据回传加速神经网络训练
2019年10月,澳大利亚墨尔本的一名亚马逊员工在骑自行车的路上撞上了一个人。当她向那个人保证她会帮忙时,她意识到他是聋哑人,不知道他在说什么。
如果有辅助技术来促进双方的沟通,这种尴尬局面本可以避免。事件发生后,亚马逊网络服务(Amazon Web Services)东南亚技术主管Santanu Dutt领导的一个团队开始工作。
在10天左右的时间里,Dutt的团队建立了一个用手语训练机器学习模型。通过使用从相机上拍摄的手势语手势的图像,该模型可以识别手势并将其转换为文本。该模型还可以将口语转换成文本,供聋哑人阅读。
Dutt说,随着机器学习服务和应用程序接口(API)的出现和开放,该模型还可以定制为将语音转换为手语——尽管他还没有看到这种需求。但仍有需要改进的地方:由于训练是在白色背景下用手势进行的,因此在实际使用中,目前形式的模型的效果将受到限制。
Dutt团队展示这一点的时间有限,但他们希望能拿出一些东西来展示,用于实验目的。企业可以使用Amazon SageMaker等工具,用更多的图像和视频来编辑和训练模型,以识别更大范围的环境。这也将有助于提高模型的准确率。事实上,拥有的数据越多,模型就越精确。开发人员可以设置置信水平,并拒绝低于某一准确水平的结果。
Dutt表示,AWS的公共部门团队已经与澳大利亚的非营利组织进行了合作,以利用机器学习模型来进行概念验证,以抵销使用AWS服务进行训练和部署该模型的成本。
(张梦婷编译,王宇飞校对)
阿里巴巴的新AI系统可以在几秒钟内检测出新型冠状病毒,准确率达96%
Alibabas New AI System Can Detect Coronavirus in Seconds with 96 Accuracy
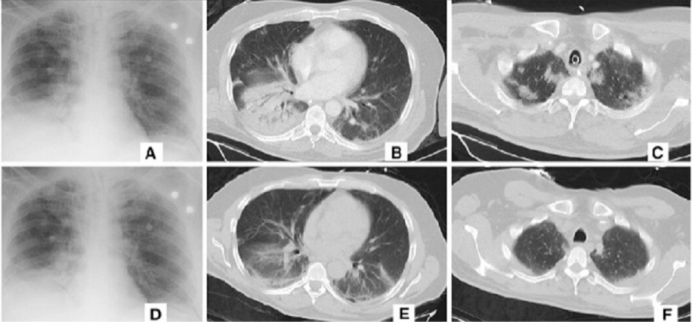
近日,阿里巴巴开发了一种用于诊断COVID-19(新性冠状病毒)的AI系统。
阿里巴巴就像把亚马逊,微软,一家视频游戏公司以及一个全国性的医疗保健网络,全部融合为一个的巨头公司,每个分支机构都获得了该公司世界一流的AI部门的解决方案。
根据Asian Review的报道,阿里巴巴声称其新系统可以从患者胸部CT扫描中检测是否有新性冠状病毒的存在,对病毒性肺炎病例的预测准确率为96%。AI只需20秒钟即可做出判断。根据这篇报道,人类通常需要大约15分钟才能诊断出疾病,因为这项工作需要评估多达300张图像。
该系统接受了5,000例确诊的冠状病毒病例图像和数据的训练,并且已经在中国各地的医院进行了测试。 根据Asian Review的报道,目前至少有100家医疗机构采用了阿里巴巴的AI。
但这并不是目前唯一能够检测新型冠状病毒的系统。阿里巴巴的竞争对手——医疗保健机构,平安,最近发布了一个听起来很相似的系统。该公司智能城市部门联合总裁兼首席战略官Geoff Kau发表声明说:“自推出以来,智能图像读取系统已为1500多家医疗机构提供服务。超过5,000名患者免费获得了智能图像读取服务。该系统可在约15秒内生成智能分析结果,准确率超过90%。”
解决方案越多越好。至少可以帮助不堪重负的医生提供更好的诊断,从而让人类更快地战胜病毒。
(李朝安编译,王宇飞校对)
项目工具
专家评选的15种最常用的机器学习工具
如果以正确的方式使用机器学习,则它是一项惊人的技术。建造一个在很大程度上表现得像人的机器将是多么迷人。精通机器学习工具将使你能够处理数据,训练模型,发现新方法并创建自己的算法。
机器学习带有大量ML工具,平台和软件。此外,ML技术也在不断发展。从一堆机器学习工具中,您需要选择其中任何一种以获得专业知识。本文列出了专家们广泛使用的前15种机器学习工具。
1.Knime
Knime是一个基于GUI的开源机器学习工具。关于Knime最好的一点是,它不需要任何编程知识,仍然可以利用Knime提供的设施。它通常用于与数据相关的任务,例如,数据操作、数据挖掘等。
此外,它通过创建不同的工作流来处理数据,然后执行它们。它附带的存储库充满了不同的节点。这些节点随后被带入Knime门户。最后,创建并执行一个节点工作流。
2.Accord.net
Accord.net是一个计算机器学习框架。它带有图像和音频包。这些软件包有助于训练模型和创建交互式应用程序。例如,试听,计算机视觉等。
由于工具名中包含.net,因此该框架的基础库是C#语言。Accord库在测试和处理音频文件中非常有用。
3.Scikit-Learn
Scikit Learn是一个开源的机器学习软件包。它是一个用于多种用途的统一平台。它有助于进行回归、聚类、分类、降维和预处理。Scikit Learn构建在三个主要Python库之上,即NumPy、Matplotlib和SciPy。除此之外,它还将帮助您测试和训练模型。
4.TensorFlow
TensorFlow是一个开源框架,适用于大规模和数值ML。它是机器学习和神经网络模型的混合体。而且,它也是Python的好朋友。
TensorFlow最突出的特点是,它同时运行在CPU和GPU上。自然语言处理、图像分类可以通过该工具实现。
5.Weka
Weka也是开源软件。大家可以通过图形用户界面访问它。该软件非常人性化,广泛应用于研究和教学中。除此之外,Weka还允许您访问其他机器学习工具。例如,R、Scikit learn等。
6.Pytorch
Pythorch是一个深度学习框架。它使用起来既快又灵活。这是因为Pytorch对GPU的命令良好。它是机器学习中最重要的工具之一,因为它被用于ML最重要的方面,包括建立深度神经网络和张量计算。
Pytorch完全基于Python。除此之外,它是NumPy的最佳选择。
7.RapidMiner
RapidMiner对于非程序员来说是个好消息。它是一个数据科学平台,具有非常出色的界面。RapidMiner是独立于平台的,因为它在跨平台操作系统上工作。借助该工具,人们可以使用自己的数据以及测试自己的模型。它的界面非常友人性化。您只需要拖放即可。这也是为什么它对非程序员也有益的主要原因。
8.Google Clound AutoML
Google Cloud AutoML的目标是使所有人都能使用人工智能。Google Cloud AutoML所做的是,它提供了针对用户的预训练模型,以创建各种服务。例如,文本识别,语音识别等。
Google Cloud AutoML在公司中非常受欢迎。由于公司希望将人工智能应用于行业的各个领域,但由于市场上缺少熟练的AI人才,因此它们一直面临着困难。
9.Jupyter Notebook
Jupyter Notebook是最广泛使用的机器学习工具之一。 这是一个处理非常迅速的高效电子平台。此外,它支持三种语言,即Julia,R和Python。
因此,Jupyter的名称是由这三种编程语言的组合形成的。Jupyter Notebook允许用户以笔记本的形式存储和共享实时代码。也可以通过GUI访问它。例如,winpython navigator,anaconda navigator等。
10.Apache Mahout
Mahout由Apache启动,Apache是基于Hadoop的开源平台。它通常用于机器学习和数据挖掘。Mahout使诸如回归,分类和聚类之类的技术成为可能。除此之外,它还利用了基于数学的函数,如向量等。
11.Azure machine learning studio
Azure machine learning studio由Microsoft启动。就像Google的Cloud AutoML一样,这是微软为用户提供机器学习服务的产品。Azure machine learning studio是形成模块和数据集连接的非常简单的方法。
除此之外,Azure还旨在为用户提供AI功能。与TensorFlow一样,它也可以在CPU和GPU上运行。
12.MLLIB
与Mahout一样,MLLIB也是Apache Spark的产品。它用于回归、特征提取、分类、滤波等,也称为Spark MLLIB。MLLIB的速度和效率都非常好。
13.Orange3
Orange3是一种数据挖掘软件,它是Orange软件的最新版本。Orange3协助进行预处理,数据可视化以及其他与数据相关的工作。大家可以通过Anaconda Navigator访问Orange3。它在Python编程中确实非常有帮助。除此之外,它的用户界面也非常不错。
14.IBM Watson
IBM Watson是IBM为使用Watson而提供的web界面。Watson是基于自然语言处理的人机交互问答系统,被广泛应用于自动学习、信息提取等领域。
IBM Watson通常用于研究和测试目的。其目的是为用户提供人性化的体验。
15.Pylearn2
Pylearn2是建立在Theano之上的机器学习库。因此,它们之间有许多相似的功能。除此之外,它还可以执行数学计算。Pylearn2也能够在CPU和GPU上运行。在进入Pylearn2之前,您必须熟悉Theano。
结论
这些是一些最流行和广泛使用的机器学习工具。所有这些都表明了机器学习的先进性。所有这些工具都使用不同的编程语言并在其上运行。例如,其中一些运行在Python上,一些运行在C ++上,而另一些运行在Java上。
(张梦婷编译,王宇飞校对)
Python的小技巧
I Thought I Was Mastering Python until I Discovered These Tricks
在本文中,我将介绍我的十大技巧,以帮助您快速有效地使用Python进行编码。
1.可读性很重要
首先,请遵循一些编程约定,使程序易于阅读。编程约定是经验丰富的程序员在编写其代码时遵循的约定。除了忽略约定外,没有其他方法可以更快地表明您是“新手”。其中一些约定特定于Python。其他则由所有语言使用。
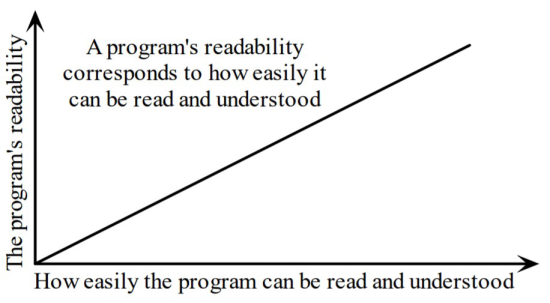
从本质上讲,可读性是一种特性,它指定另一个人可以多么容易地理解您代码的某些部分(而不是你自己)。
举例来说,我不习惯用垂直对齐方式来写,也不习惯打开定界符来对齐函数的参数。

查看《Style Guide for Python Code》中的其他示例,并确定最适合的示例。我们经常做的一件事情是重新阅读我们以前看过或写过的程序,这就是为什么我们接触可读程序对学习编程很重要的原因。
2.避免无用的条件
通常,如果if&elif&…&else条件过长是需要重构的代码的标志,这些条件使您的代码冗长而又难以解释。有时它们很容易被替换,例如,我曾经做过以下事情:

这真是愚蠢!该函数返回一个布尔值,那么为什么还要使用if块呢? 正确的做法是:

在Hackerrank挑战中,您将获得一个年份,并且必须编写一个函数来检查年份是否闰年。在公历中,必须使用三个标准来标识闰年:
- 可以被4整除的年份是闰年,除非:
- 可以被100整除的年份是,不是闰年,除非:
- 可以被400整除的年份是闰年。
因此,在此挑战中,不要用if&else,只需执行以下操作即可:

3.充分使用空白
- 切勿混用制表符和空格。
- 函数之间的隔开一行。
- 类之间的隔开两行。
- 在术语,列表,元组,参数列表中的参数“,”之后添加空格。在术语的“:”之后添加空格而不是之前。
- 在赋值和比较周围放置空格(列表中的参数除外)。
- 在左/右括号或参数列表之前没有空格。

4.文档字符串和注释
- 即使您觉得函数很明显,也要解释该函数的目的,因为它不一定对另一个后来的人显而易见。
- 描述预期的参数,返回的值和引发的异常。
- 如果该方法与单个调用者紧密耦合,请提及调用函数。
文档字符串=如何使用代码
注释=为什么(合理)以及代码如何工作
文档字符串需要解释:

编写好的文档字符串和注释是您的责任,因此请始终使它们保持最新!进行更改时,请确保注释和文档字符串与代码一致。
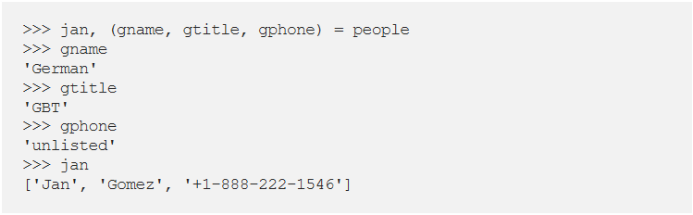
5.变量和赋值
用其他编程语言:

在Python中,最好在一行代码中使用分配:

您可能早已见过它,但是您知道它是如何运行的吗?
逗号是构建元组的语法。
在右侧创建一个元组(元组包装)。
元组是左侧的目标(元组解包)。
其他例子:

在结构化数据循环中很有用(上面的变量user已保留):

也可以采取相反的方式,只需确保左右具有相同的结构即可:
6.列表串联和联接
让我们从字符串列表开始:

我们希望将这些链连接在一起以创建一条长链。特别是当子字符串的数量很大时,请避免这样做:

这样非常慢。它占用大量内存和性能。总和将累加,存储,然后继续进行每个中间步骤。
相反,请执行以下操作:

join()方法可一次完成整个副本。当您仅处理几个字符串时,它没有什么区别。但是养成以最佳方式构建链的习惯,因为当然处理成百上千的字符串时,它确实会有所作为。
这里是一些使用join()方法的技术。 如果要使用空格作为分隔符:

或逗号和空格:

为了使语法正确,我们希望除最后一个值(我们更喜欢使用“or”)之外的每个值之间都使用逗号。拆分列表的语法将完成其余工作。[:-1]返回除最后一个值外的所有内容,我们可以将其与逗号连接。

7.测试True条件
就布尔值而言,利用Python既优雅又快捷:

8.尽可能使用枚举
枚举函数获取一个列表并返回对(索引,项目):

必须使用列表来显示结果,因为枚举是一种惰性函数,仅在需要时才一次生成一个项目(一对)。for循环需要这种机制。打印不会取得结果,但必须拥有要显示的整个消息。因此,在使用打印之前,我们会自动将生成器转换为列表。因此,使用下面的循环会更好:

带枚举的版本比其他两个版本更短,更简单。以枚举函数返回迭代器的为例(生成器是一种迭代器)
9.列表理解
for和if的传统使用方式:

使用列表表示:

listcomp清晰直接。您可以有多个for循环,并且条件可以在同一个listcomp中,但不能超过两个或三个,或者条件复杂,建议您使用通常的for循环。
例如,从0到9的正方形列表:

上一个列表中的奇数列表:

另一个例子:

10.表达式生成器
让我们对小于100的数字平方求和:

我们还可以使用sum函数,通过建立正确的序列来为我们更快地完成工作。

生成器表达式类似于列表,除了它们的计算是懒惰的。Listcomps一次计算整个结果,然后将其存储在列表中。需要计算时时,生成器表达式一次只计算一个值。当序列很长,并且生成的列表只是中间步骤而不是最终结果时,这将会很有用。
例如,如果我们必须对数十亿个整数的平方求和,我们如果通过列表达将到内存的饱和,但是生成器表达式不会有任何问题。 好吧,虽然需要一段时间!

语法上的差异是listcomp带有方括号,而生成器表达式则没有。生成器表达式有时需要圆括号,因此您应始终使用它们。
简而言之:
- 当预期结果是列表时,使用列表。
- 当列表只是中间结果时,请使用生成器表达式。
(李朝安编译,王宇飞校对)
近期论文
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
2020.3.1 by Victor SANH Lysandre DEBUT Julien CHAUMOND Thomas WOLF
研究背景
在过去的两年中,自然语言处理中的转移学习方法兴起,大规模的预训练语言模型已成为许多NLP任务中的基本工具。尽管这些模型可以带来显着的改进,但它们通常具有数亿个参数,并且当前对预训练模型的研究表明,训练更大的模型仍然可以提高下游任务的性能。但是,这些模型不断增长的计算和内存需求可能会阻碍它们被广泛采用。
目的
对BERT使用知识蒸馏,从而得到更轻、更快的预训练模型,并且可以在许多下游任务上达到类似的性能。
做法
学生模型具有与BERT相同的体系结构,但层数减少了一半,并且删除了token type embedding和pooler。文章从BERT中的两层中选取一层来初始化学生模型。模型使用了三个损失函数:蒸馏损失、掩盖语言建模(MLM)损失、余弦嵌入损失。
结果
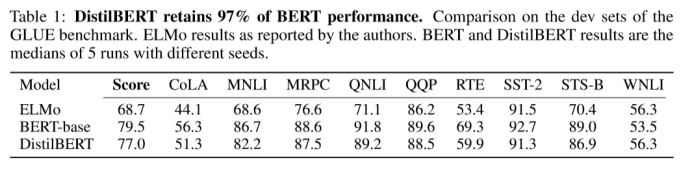
文章根据通用语言理解评估(GLUE)基准评估DistilBERT的语言理解和泛化能力,该数据库由9个数据集组成。在这9项任务中,DistilBERT始终处于ELMo基线水平上或与之持平。DistilBERT与BERT相比也很出色,它保留了BERT 97%的性能,而参数却减少了40%。
(王宇飞编译,张梦婷校对)