文本挖掘与机器学习跟踪扫描动态快报(2021.02)
实时跟踪、关注文本挖掘与机器学习领域最新研究动态
深度观察
模型搜索:一个寻找最佳ML模型的开源平台
神经网络(NN)的成功往往取决于它对各种任务的泛化能力。然而,设计能够很好地泛化的NN是一个挑战,因为研究界对神经网络如何泛化的理解目前还有些有限。对于一个给定的问题,合适的神经网络是什么样的?它应该有多深?应该使用哪种类型的层?LSTMs是否足够,还是Transformer层更好?或者是两者的结合?合并或蒸馏会提升性能吗?当考虑到机器学习(ML)领域时,这些棘手的问题变得更具挑战性,因为这些领域可能存在比其他领域更好的直觉和更深的理解。
近年来,出现了AutoML算法,帮助研究人员自动找到合适的神经网络,而不需要人工实验。像神经架构搜索(NAS)这样的技术,使用强化学习(RL)、进化算法和组合搜索等算法,从给定的搜索空间中构建出一个神经网络。在适当的设置下,这些技术已经证明它们能够提供比人工设计的同类产品更好的结果。但更多的时候,这些算法是重计算的,在收敛之前需要训练成千上万的模型。此外,它们探索的搜索空间是特定领域的,并且包含了大量的人类先验知识,而这些知识并不能很好地跨领域转移。举个例子,在图像分类中,传统的NAS搜索两个好的构建块(卷积和下采样块),它按照传统的惯例进行排列以创建完整的网络。
为了克服这些缺点,并将AutoML解决方案的使用范围扩展到更广泛的研究社区,我们很高兴地宣布Model Search的开源发布,这是一个帮助研究人员高效、自动开发最佳ML模型的平台。Model Search不专注于特定领域,而是领域不可知、灵活,能够找到最适合给定数据集和问题的合适架构,同时最大限度地减少编码时间、精力和计算资源。它建立在Tensorflow上,既可以在单机上运行,也可以在分布式环境中运行。
概述
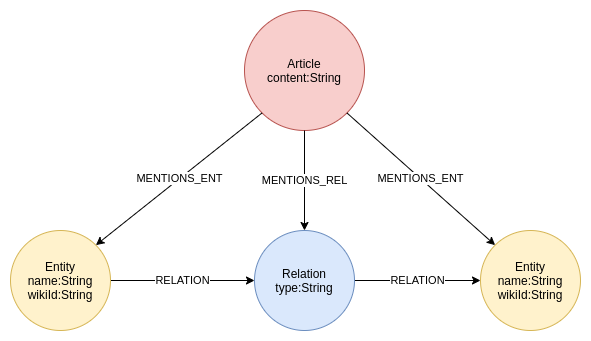
Model Search系统由多个训练器、一个搜索算法、一个转移学习算法和一个数据库组成,用于存储各种评价模型。该系统以自适应但异步的方式运行各种ML模型(不同架构和训练技术)的训练和评估实验。虽然每个训练者都独立进行实验,但所有训练者都会分享从实验中获得的知识。在每个周期开始时,搜索算法会查找所有已完成的试验,并使用波束搜索来决定下一步要尝试什么。然后,它在迄今为止发现的最佳架构之一上进行变异,并将得到的模型分配回训练器。
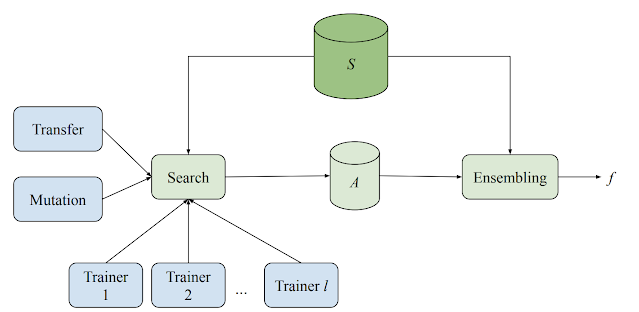
Model Search示意图,说明分布式搜索和集合。每个训练器独立运行,训练和评估一个给定的模型。结果与搜索算法共享,并将其存储起来。然后,搜索算法在其中一个最佳架构上进行变异,然后将新模型送回训练器进行下一次迭代。S是训练和验证实例的集合,A是训练和搜索过程中使用的所有候选模型。
该系统从一组预定义的块构建神经网络模型,每个块代表一个已知的微架构,如LSTM、ResNet或Transformer层。通过使用预先存在的架构组件块,Model Search能够利用NAS跨领域研究的现有最佳知识。这种方法也更有效率,因为它探索的是结构,而不是其更基本和更详细的组件,因此减少了搜索空间的规模。
因为Model Search框架是建立在Tensorflow上的,所以块可以实现任何以张量为输入的函数。例如,想象一下,人们想引入一个新的搜索空间,用精选的微架构构建。该框架将把新定义的区块纳入搜索过程中,这样算法就可以从提供的组件中构建最佳的神经网络。所提供的块甚至可以是完全定义的神经网络,这些神经网络已经知道对感兴趣的问题有效。在这种情况下,Model Search可以被配置为简单地作为一个强大的集合机。Model Search中实现的搜索算法是自适应的、贪婪的和增量的,这使得它们比RL算法收敛得更快。然而,它们确实模仿了RL算法的"探索与利用"性质,将搜索一个好的候选者(探索步骤)和通过合集发现的好的候选者(利用步骤)来提高准确性。主搜索算法在对架构或训练技术进行随机变化(如使架构更深入)后,自适应地修改前k个表现好的实验之一(其中k可以由用户指定)。
为了进一步提高效率和准确性,在各种内部实验之间实现了转移学习。Model Search通过两种方式来实现--通过知识提炼或权重共享。知识提炼允许人们通过添加一个损失项来提高候选者的准确率,该损失项除了与地面真相相匹配外,还与高性能模型的预测相匹配。另一方面,权重共享则是通过复制之前训练过的模型中合适的权重,并随机初始化剩余的模型,从之前训练过的候选模型中引导出网络中的部分参数(应用变异后)。这样可以加快训练速度,从而有机会发现更多(和更好)的架构。
实验结果
Model Search以最少的迭代改进了生产模型。在最近的一篇论文中,我们通过发现一个用于关键词发现和语言识别的模型,展示了Model Search在语音领域的能力。在不到200次的迭代中,所得到的模型比专家设计的内部最先进的生产模型在准确度上略有提高,使用的可训练参数减少了约13万个(184K个参数比315K个参数)。
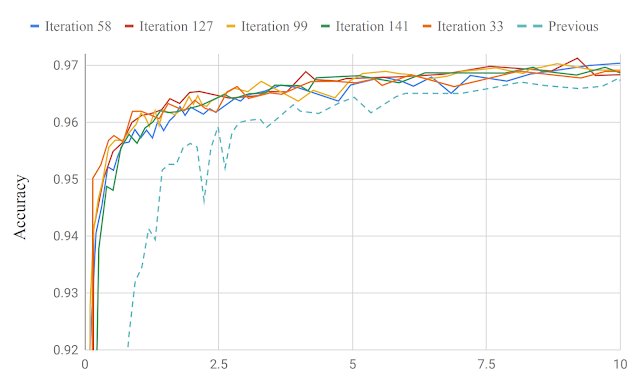
在我们的系统中,模型给定迭代的准确率与之前的生产模型相比,在关键词点选方面,可以在链接的论文中找到类似的语言识别图。
我们还应用Model Search在大量探索的CIFAR-10成像数据集上寻找适合图像分类的架构。使用一组已知的卷积块,包括卷积、resnet块(即两个卷积和一个跳过连接)、NAS-A单元、全连接层等,我们观察到,我们能够在209次试验中迅速达到91.83的基准精度(即只探索了209个模型)。相比之下,之前表现最好的NasNet算法(RL)在5807次试验中达到了同样的阈值精度,PNAS(RL+Progressive)则是1160次。
结论
我们希望模型搜索代码能够为研究人员提供一个灵活的、与领域无关的ML模型发现框架。通过建立在给定领域的先前知识基础上,我们相信,当提供一个由标准构件组成的搜索空间时,这个框架足够强大,可以在研究良好的问题上建立具有最先进性能的模型。
(周子喻编译,张梦婷校对)
研究动态
新的迁移学习方法总结了现代语言中的历史文本
New Transfer Learning Approach Summarizes Historical Texts in Modern Language
许多ML研究引入了将古代文本破译成现代语言的系统,这些系统已被证明对历史、考古学和数字人文学者有用。现在,谢菲尔德大学、北京航空航天大学和开放大学知识媒体研究所的研究人员提出了一种迁移学习方法,可以在语义层面自动处理历史文本,生成现代语言摘要。该方法优于标准的跨语言基准的任务。

历史文本摘要是一种独特的跨语言摘要形式。然而,由于历史和现代语料库的限制以及词汇、拼写、意义和语法的发展,传统的跨语言摘要的发展受到了阻碍。针对这些挑战,研究人员开发了一种基于迁移学习的方法。
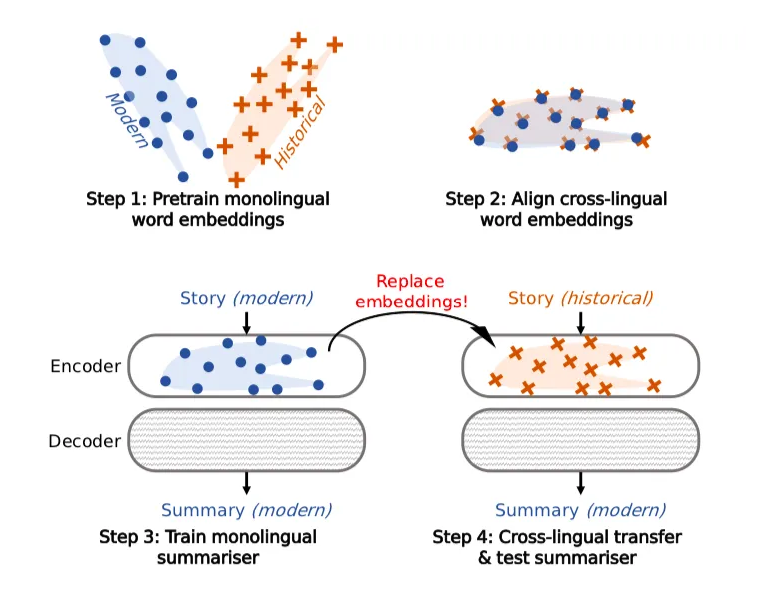
该模型是针对德语和汉语建立的,每种语言都有丰富的文本传承和可访问的(单语)训练资源。德语和汉语也分别代表字母和表意字符书写系统,这将有助于该方法在其他语言上的应用。
研究人员解释说,他们提出的历史文本摘要模型基于2019年的论文Survey of Cross-lingual Word Embedding Models中介绍的跨语言迁移学习框架,即使没有跨语言(从历史到现代)的监督或数据,也可以被独自创建。

由于这是第一次对历史文本摘要进行此类研究,因此没有类似的模型性能比较方法。研究人员指出,此类摘要大多是新闻、编年史、日记和回忆录等叙事文本所需要的,因此在该领域人类专家的帮助下,构建了一个德文和中文历史新闻摘要语料库,称为HISTSUMM。
该团队采用了两种最先进的baseline进行标准的跨语言摘要,并使用标准的ROUGE度量标准对信息性、简洁性、流利性和及时性进行了广泛的自动和人工评估。结果表明,所提出的模型相当或略优于德语的baseline方法,而汉语的模型则大幅度优于德语的baseline方法。研究人员说,新模型也为这一领域的未来研究提供了一个基准。
(张梦婷编译,赵海喻校对)
GEM:NLG的"活基准"
55 Researchers from 44 Institutions Propose GEM a Living Benchmark for NLG
为了更好地跟踪自然语言生成模型的进展,一个由40多个著名机构的55名研究人员参与的全球项目提出了GEM(Generation,Evaluation,and Metrics),这是一个专注于评估的NLG"活基准"环境。NLG模型将信息的非语言或文本表示作为输入,并自动生成可理解的文本。
NLP基准,如GLUE(一般语言理解评估)已经应用于NLG和NLU模型。虽然这类基准可以在统一的评估框架下汇总多个任务,并帮助研究人员高效地对模型进行比较,但它们也有可能将模型的复杂性简化为基准排行榜上的单一数字。正如研究团队在论文The GEM Benchmark: Natural Language Generation, its Evaluation and Metrics中所述,单一的衡量标准无法正确描述系统性能,因为模型大小和公平性等考虑因素被忽略了。
论文的第一作者,谷歌人工智能语言研究科学家Sebastian Gehrmann解释说,研究人员计划在今年夏天的ACL2021上进行一次共享任务研讨会:"由于数据、模型和评估是共同发展的,所以基准需要对所有的数据进行更新。作为一个'活'的基准,GEM没有一套固定的指标或排行榜。相反,我们的目标是发现不足和进步的机会。为此,共享任务将有两个部分;建模和评估。首先,我们要求在各种NLG挑战中提交11个数据集和7种语言的挑战集。在第二部分,参与者将分析输出结果。"
在不同的任务、设置和语言中,自动度量往往表现不同。在NLG研究人员中,评估人类评分和自动度量与基于任务的评估之间的相关性是一个常见的做法。GEM研讨会将帮助NLG研究人员探索共享任务,并将GEM发展成NLG的基准环境。通过让人类注释者对产出进行评估,研究人员还希望为未来的NLG研究建立可重复和一致的人类注释实践。
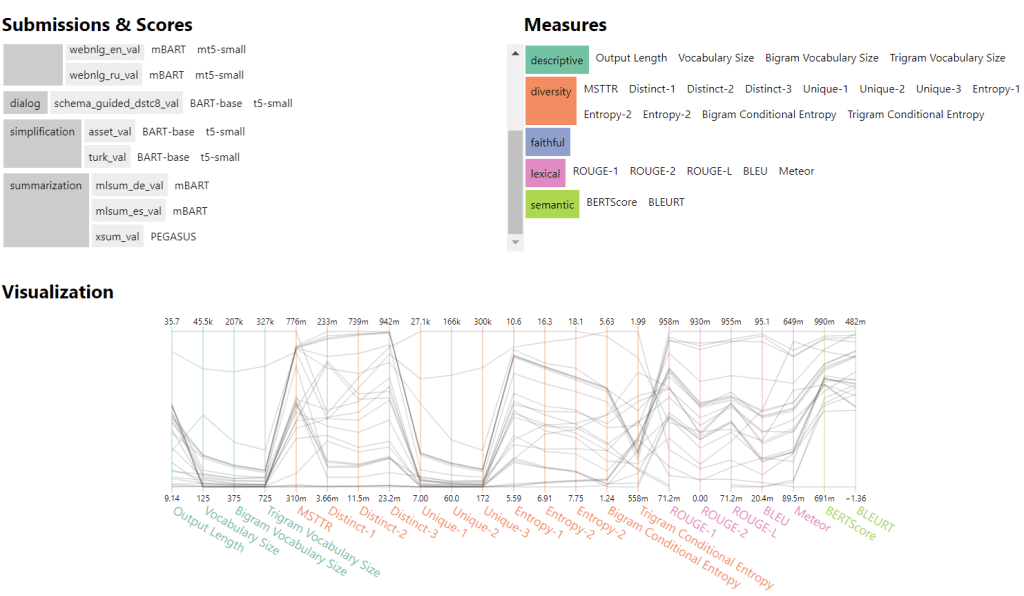
GEM项目的最终目标是实现对数据和模型的深入分析,而不是关注单一的排行榜分数。通过衡量跨越13个数据集的NLG进展,涵盖许多NLG任务和语言,希望GEM基准也能为未来使用自动和人类指标评估生成的文本提供标准。研究人员已经将该项目开放给NLG研究社区,资深成员将帮助新人做出贡献。
(周子喻编译,张梦婷校对)
项目工具
从文本到知识:信息提取Pipeline
信息提取Pipeline
到底什么是信息提取Pipline?简单来说,信息提取就是从文本等非结构化数据中提取结构化信息的任务。
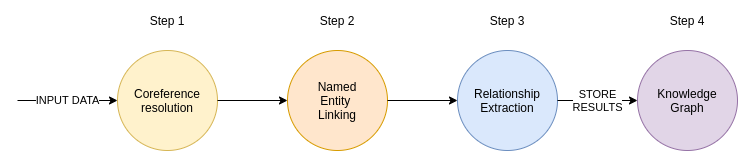
信息提取Pipline包括四个部分。第一步,我们通过一个共指解析模型(Coreference Resolution Model)来操作输入文本。共指解析是寻找所有引用特定实体的表达式的任务。简单地说,它将所有代词与被引用的实体联系起来。一旦这一步完成,它就会将文本分割成句子,并删除标点符号。我注意到,当我们首先去除标点符号时,用于命名实体链接的特定ML模型效果更好。在Pipeline的命名实体链接部分,我们尝试提取所有提到的实体,并将它们连接到目标知识库。在本例中,目标知识库是维基百科。命名实体链接是有益的,因为它还处理了实体的歧义,这可能是一个大问题。
一旦我们提取了上述实体,IEPipeline就会尝试根据文本的上下文来推断实体之间的关系,使之有意义。IEPipeline的结果是实体和它们的关系,所以使用图数据库来存储输出是有意义的。我将展示如何将IE信息保存到Neo4j中。
我将用下面摘自维基百科的内容来带你了解IEPipeline。

第一步:参照物解决
如前所述,共指解析试图找到文本中所有引用特定实体的表达式。在我的实现中,我使用了运行在SpaCy框架之上的Neuralcoref model from Huggingface。我使用了Neuralcoref模型的默认参数。在这一过程中,我确实注意到了一件事,那就是Neuralcoref模型对于位置代词的效果并不好。共指解析部分的代码如下。
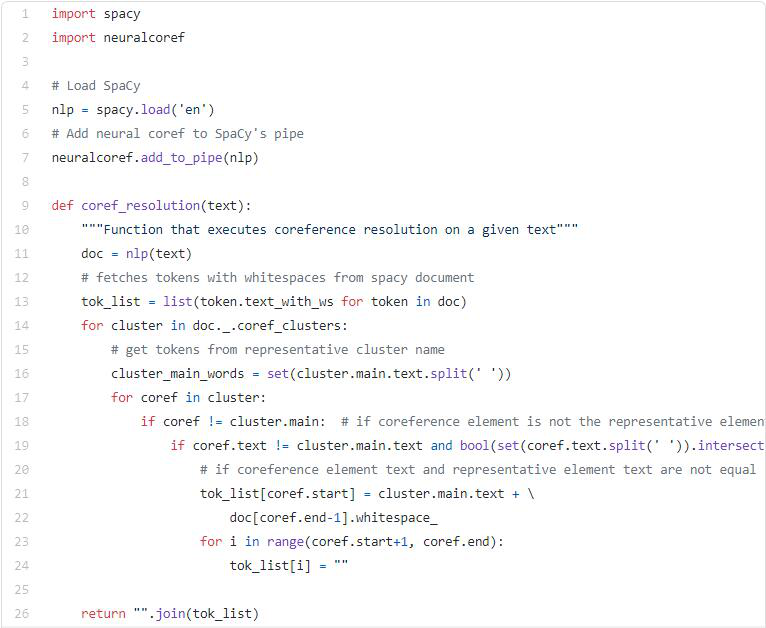
如果我们通过coref_resolution函数运行我们的示例文本,我们将得到以下输出。

在这个例子中,不需要高级的共指解析技术。Neuralcoref模型将几个代词"He"改为"Elon Musk"。虽然看起来非常简单,但这是一个重要的步骤,将提高我们IEPipeline的整体效率。
第二步:命名实体链接
在这里,我使用的是Wikifier API。在我们通过Wikifier API运行输入文本之前,我们将把文本分割成句子,并删除标点符号。这一步的代码如下。

维基化过程中一个很好的事情是,我们还可以得到相应的WikiData ids和实体的标题。有了WikiData ids,实体的歧义问题就迎刃而解了。
第三步:关系提取
OpenNRE项目的特点是在Wiki80或Tacred数据集上训练了五个开源关系提取模型。在Wiki80数据集上训练的模型可以推断出80种关系类型。在IEPipeline实现中,我使用了wiki80_bert_softmax模型。
如果我们看一下OpenNRE库中的一个关系提取调用的例子,我们会注意到它只推断关系,而不尝试提取命名实体。我们必须提供一对带有h和t参数的实体,然后模型会尝试推断关系。

结果输出一个关系类型以及预测的置信度。不清晰的关系提取代码是这样的:

我们必须将命名实体链接的结果作为关系提取过程的输入。我们迭代一对实体的每一个排列组合,并尝试推断出一个关系。从代码中可以看出,我们还有一个 relation_threshold 参数来省略置信度较小的问题。
所以,如果我们通过关系提取流水线运行我们的示例文本,结果如下。
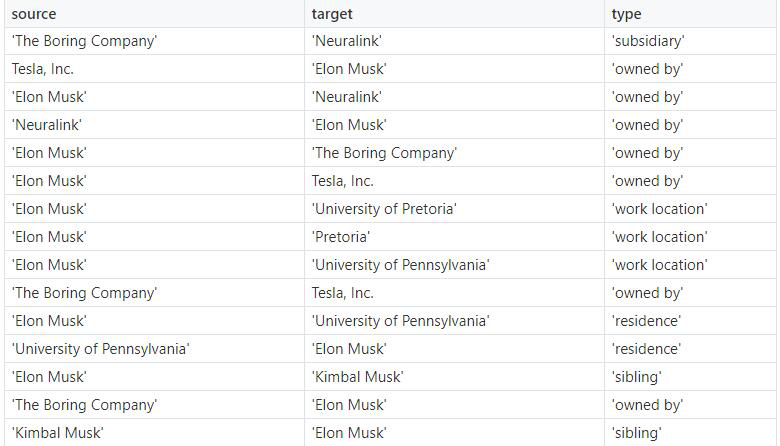
关系提取是一个具有挑战性的问题,所以不要期望完美的结果。我必须说,这个IEPipeline的效果和一些商业解决方案一样好,甚至更好。而显然,其他商业解决方案要好得多。
第四步:知识图谱
由于我们要处理的是实体和它们的关系,所以将结果存储在图数据库中才有意义。我在例子中使用了Neo4j。
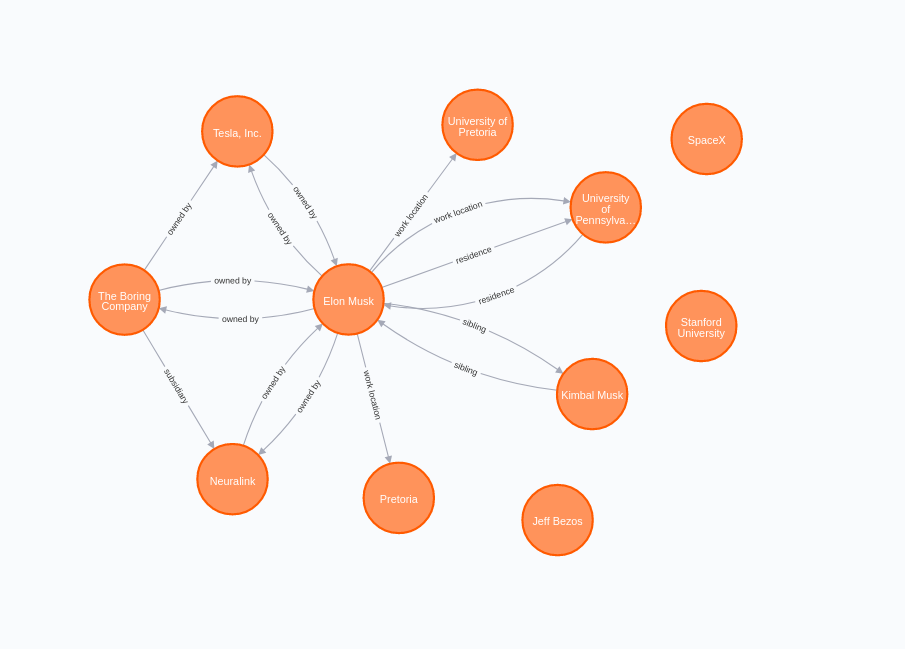
在图的可视化中,我们很容易观察到,虽然大多数关系是双向推断的,但并不是所有情况下都是如此。例如,埃隆-马斯克和宾夕法尼亚大学之间的工作地点关系只被假设为单一方向。这就涉及到OpenNRE模型的另一个缺点。关系的方向并不像我们希望的那样精确。
一个IEPipeline的实际例子
我们将通过Kaggle上找到的BBC新闻数据集来运行IEPipeline。IEPipeline实现中最难的部分是设置所有的依赖关系。
在第一次运行时,必须下载OpenNRE模型,所以一定不要使用-rm选项。如果你想对项目做一些修改,建立自己的版本,我也准备了一个GitHub仓库。
由于我们将把结果存储到Neo4j中,你也必须下载并设置它。在上面的例子中,我使用了一个简单的图模式,其中节点代表实体,关系代表关系。现在我们将重构一下我们的图模式。我们要在图中存储实体和关系,但也要保存原始文本。有一个计算跟踪在现实世界的场景中是非常有用的,因为我们已经知道IEPipeline并不完美。
把一个关系重构成一个中间节点,可能有点违背直觉。我们面临的问题是,我们不能让一个关系指向另一个关系。鉴于这个问题,我决定将一个关系重构成一个中间节点。我本可以发挥我的想象力来制作更好的关系类型和节点标签,但事实就是这样。我只想让关系方向保留其功能。
将BBC新闻数据集中的500篇文章导入Neo4j的代码如下。你必须运行trinityIE docker,IEPipeline才能工作。

运行以下代码:

结果如下
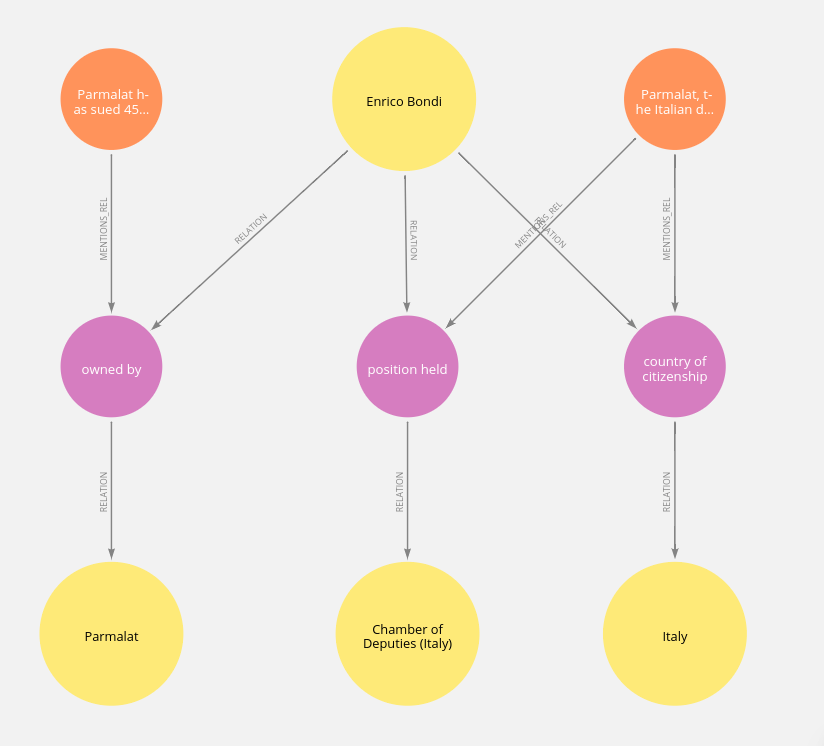
我们可以看到,Enrico Bondi是意大利公民。他在意大利众议院担任职务。另一个关系推断,他还拥有Parmalat。经过谷歌的短暂搜索,似乎这个数据至少在可能的范围内。
(赵海喻编译,周子喻校对)
近期论文
Entity-level Factual Consistency of Abstractive Text Summarization
Feng Nan Ramesh Nallapati Zhiguo Wang Cicero Nogueira dos Santos Henghui Zhu Dejiao Zhang Kathleen McKeown Bing Xiang
摘要
摘要的一个关键挑战是确保生成的摘要与原始文档的事实一致性。例如,在现有数据集上训练的最新模型表现出实体幻觉(Entity Hallucination),生成源文档中不存在的实体名称。我们提出了一组新的度量标准来量化生成摘要的实体级事实一致性,并且我们证明了通过简单地过滤训练数据可以缓解实体幻觉问题。此外,我们还提出了一个有总结价值的实体分类任务,以及一个联合实体和摘要生成方法,从而进一步改进了实体级别的度量指标。
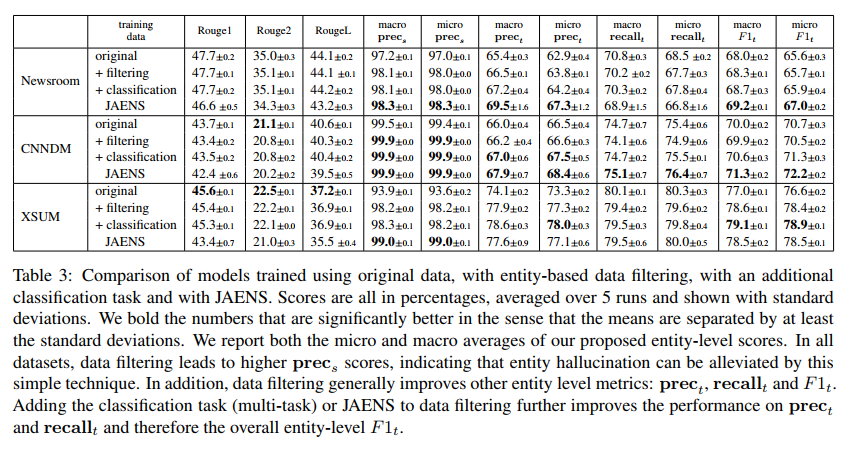
实体级事实一致性度量
提出了三个新的度量标准,它们依赖于离线工具来执行命名实体识别。使用N(t)和N(h)分别表示黄金摘要(Gold Summary)和生成摘要(Generated Summary)中命名实体的数量,用N(h∩s)表示在生成摘要中找到的、可以在源文档中找到匹配项的实体数。如果摘要中的命名实体由多个单词组成,只要在源文档中可以找到命名实体的任何n-gram,我们就认为它是匹配的。
用Precision-source(prec_s)来量化关于源的幻觉程度。低prec_s意味着幻觉严重。
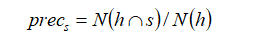
如果任何一个实体在源文档中找不到匹配项,我们将从ground truth summary中丢弃包含该实体的语句。如果基本事实摘要只包含一句话并且需要丢弃,我们将从数据集中删除文档摘要对。通过这种方式,我们可以确保过滤后的数据集在ground truth summary中不存在实体幻觉prec_s=1。

其中,N(h∩t)是生成摘要中可以在ground truth summary中找到匹配项的命名实体数,N(t)是ground truth summary中命名实体的数量。
实验结果

(张梦婷编译,赵海喻校对)
Non-Autoregressive Text Generation with Pre-trained Language Models
Yixuan Su Deng Cai Yan Wang David Vandyke Simon Baker Piji Li Nigel Collier
摘要
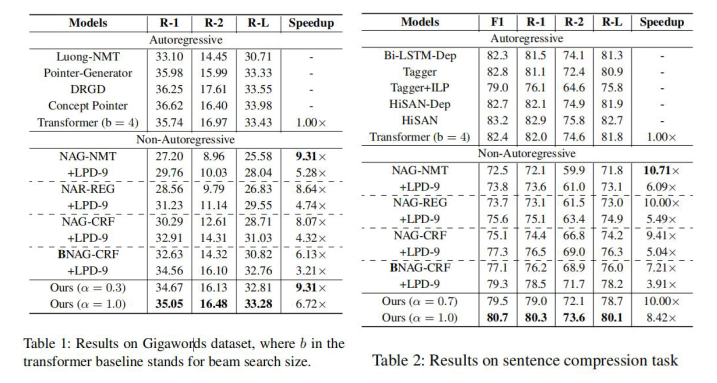
非自回归生成(Non-autoregressive generation,NAG)由于其快速的推理速度而重新引起了人们的极大关注。然而,现有NAG模型的生成质量仍然落后于自回归模型。在这项工作中,我们展示了BERT可以作为NAG模型的骨干,以大大提高性能。此外,我们还设计了一些机制来缓解普通NAG模型的两个常见概率问题:预设输出长度的不可控性和单个标记预测的条件独立性。最后,为了进一步提高所提出的模型的速度,我们提出了一种新的解码策略--比率优先(ratio-first),适用于输出长度可以事先大致估计的应用。为了进行全面的评估,我们在三个文本生成任务上测试了所提出的模型,包括文本摘要、句子压缩和机器翻译。实验结果表明,我们的模型明显优于现有的非自回归标准,并与许多强的自回归模型取得了竞争性的性能。此外,我们还进行了广泛的分析实验,以揭示每个组成部分的效果。
拟议模式
目前NAG模型所面临的两个重要限制:(1)预设输出长度的不可逆性(2)单个标记预测的条件独立性。据此,我们设计了解决这两个问题的方案。
我们提出了一个新的框架,在非自回归生成范式下利用BERT进行文本生成;我们提出了一个解码机制,允许模型动态地确定输出长度,以及一个新的上下文感知学习目标,以减少来自输出侧条件独立性假设的错误。我们引入了比率优先的解码策略,进一步提高了模型的推理效率。
所提出的模型的架构如图2所示,其中嵌入层和变压器层的堆栈是用BERT初始化的(Devlin等人 ,2019)。
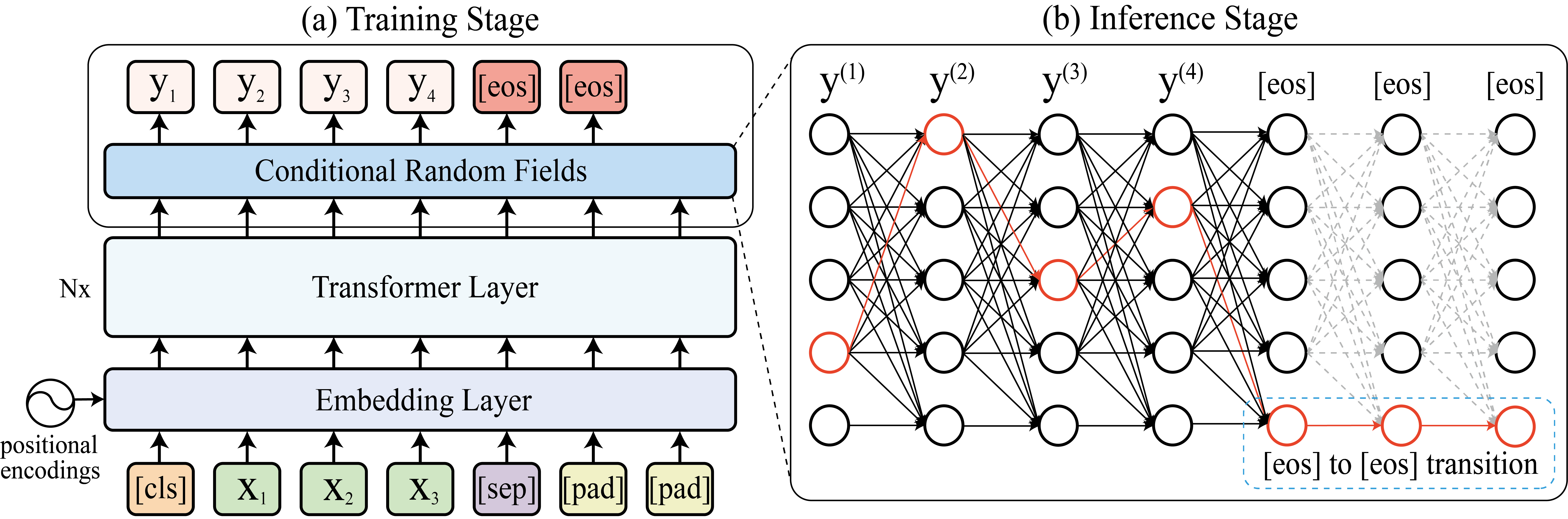
我们希望模型通过发出一个特殊的[eos]标记来停止生成。为了达到这个目的,在训练过程中,我们手动将两个连续的[eos]标记附加到目标序列的末端,如图1左上角部分所示。通过这种方式,模型可以学习到两个[eos]状态之间的确定性过渡b- haviour,也就是说:
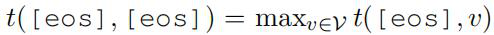
一旦解码后的轨迹进入[eos]状态,S(X,Y′)中的状态转换项将以转换得分项为主,t([eos],[eos])。因此,在剩下的步骤中,模型将不断过渡到[eos]。这样,我们的模型就可以在生成过程中通过进入[eos]状态来动态控制输出序列的长度。在整个生成过程完成后,通过删除所有生成的[eos]标记,可以得到最终的输出序列。
只考虑BERT输出的开始部分就可以提高推理速度,特别是对于像摘要这样的任务,当已知目标长度比源序列短时,我们可以安全地只使用BERT的第[α* T]个输出来执行推理。这里T去说明源长度,α∈(0,1)是根据数据统计设置的,[.]是整数舍入操作。从形式上看,给定源序列X,比值-译码被定义为:
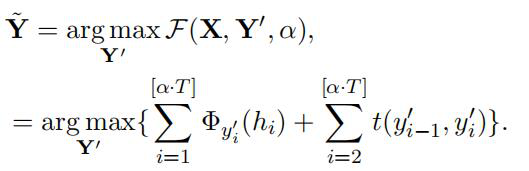
当α=1.0时,ratio-first退化到基于CRF模型水平的解码策略。
实验结果
(赵海喻编译,周子喻校对)
近期会议
Global Artificial Intelligence Virtual Bootcamp
Feb 22 - Feb 26, 2021 线上
此会议将提供为期5天的人工智能(AI)全面训练营。这是关于AI领域的快速,与供应商无关的技术概述。不需要提前具备AI或编程的知识。全球人工智能训练营面向希望了解AI新兴世界的技术人员和非技术人员,特别关注NLP,深度学习,Tensorflow,Keras,机器学习和比较框架。与会者将获得实践经验。
(赵海喻)