文本挖掘与机器学习跟踪扫描动态快报(2019.12)
实时跟踪、关注文本挖掘与机器学习领域最新研究动态
深度观察
检查BERT的原始嵌入(BERT编码评估)
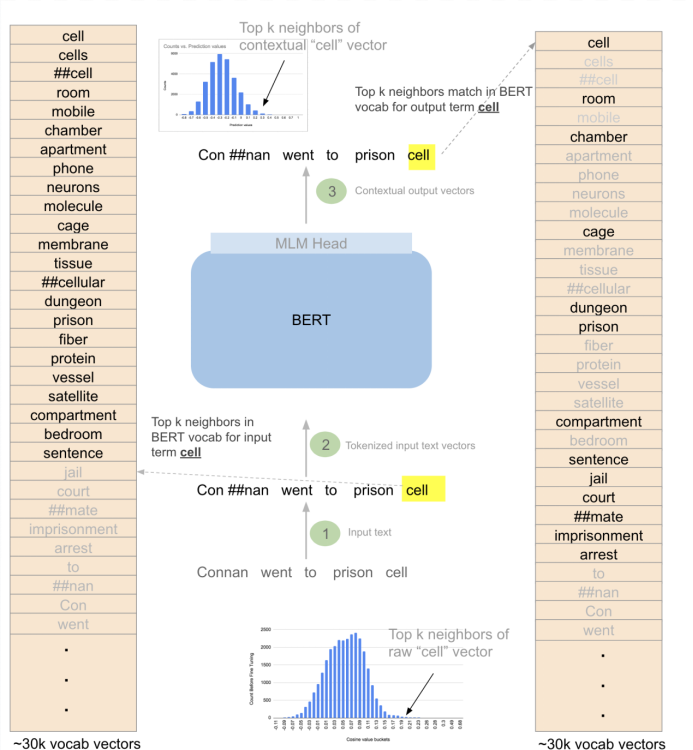
图中展示了通过BERT模型之前和之后cell的前k个邻居。(1)输入句。(2)输入句子的标记化版本——Conan在BERT的原始词汇中并不存在。它被分解成两个术语“Con”和“##nan”,这两个词都出现在BERT的词汇表中。(3)BERT的MLM的输出在BERT的词汇表中找到与变换后的向量最接近的预测。对于单词cell,最接近的k个邻居(如图右边所示)只包含语义为捕获监禁的词语。相比之下,它在输入到BERT之前的前k个邻居(如图左边所示)捕捉到了这个词的所有不同含义,——“监禁”感、“生物”感(蛋白质、组织)以及手机感(手机、移动)。输入前后的前k个相邻词落在直方图(距离/预测分数vs计数)的尾部,使得这些相邻词与词汇表中的其他词区别开来
BERT的原始词嵌入(raw word embeddings)可以根据其他词来捕获一个词的有用的和可分离的信息。这些信息可以从原始的嵌入和经过MLM的BERT的版本中获得。当一个BERT模型在一个大型语料库上进行自我监督训练时,通过让该模型学习预测每个句子中的几个masked words (约15%),我们得到输出有:
一个学习了权重的BERT模型。
大约30,000个向量。 (如果需要,我们可以使用自己的词汇表来训练模型,但在这样做之前需要考虑许多因素,例如需要使用新词汇表从头开始预训练)。在这篇文章中,这些向量被称为原始向量,以便在它们通过BERT模型后,将它们与转换后的对应向量区分开来。
这些原始向量类似于word2vec模型的向量输出,一个向量表示一个单词,而不考虑一词多义。例如,像cell这样的单词的所有不同的含义(手机、生物细胞、监狱)被组合成一个向量。
当单词被输入到一个训练过的模型中时,这些原始向量被用来表示单词。然后,该模型利用句子中相邻单词的上下文来转换单词的表示。例如,在预测一个句子里的一个单词的任务中(这个预测任务不需要进行微调,因为它与训练目标相同),该模型将句子中的所有单词转换为考虑上下文相关的表示。像cell这样的词,在“There are many organelles in a biological cell”这样的句子中会失去“移动”和“监狱”的感觉,只会保留“生物”的感觉。这样的句子“He went to prison cell with a cell phone to capture blood cell samples from sick inmates”,模型将“cell”的这三种感觉分别捕获,而不是把这些感觉混合在一起,最终输出为三个独立的向量。
检查BERT学习的原始词向量(大约30000个。其中78%是完整的“cell”、“protein”形式的单词,22%是不完整的单词像“##os”这种形式。例如,单词“icos”在BERT模型的输入时会表示为两个向量——“ic”和“##os”)显示:
BERT捕捉了不同形式的相似性。语义上的(crown, throne, monarch, queen),句法上的(he, she, they),词形变化上的(carry, carries, carrying),拼写上的(Mexico, México, Mexican),语音上的跨语言相似性(##kan, ##カ- Katakana letter ka , ##क-Devanagiri letter ka;这种相似性也许部分解释了机器翻译中transformer的性能)。在本质上,原始向量的嵌入空间是一个混合了不同类型的相似点的集合,上面的例子说明了这一点。
原始学习的向量,不管它们捕获的相似度度量的类型是什么,它们与其他向量的余弦相似度在直方图(余弦相似度vs项数)中都有一个非常相似的分布形状。对于每个单词,都有一个尾部,其计数通常为个位数。在这些尾巴中,有以上描述的一种或多种相似性占主导地位。当我们在一个目标上微调模型时,会改变分布形状(平均向右移动),但仍然有一个独特的尾巴。
这些原始向量和masked language model一起,可以用于各种任务。
给定一个术语,确定其不同含义和主要含义 (再次使用BERT的词汇捕捉)。例如,如前所述,术语“cell”有多种含义。在一个特定领域语料库上微调模型后,其中一种感觉可能会占主导。 (例如在生物医学语料库上调整一个模型,可能会使“cell”一词的“生物细胞”意义主导另外两种感觉)
给定两个或多个术语,识别它们之间的共同意义。例如,两种drugs有相同的描述,比如 drug, drugs, treatment。
特定类型的集群实体。(这通常只适用于彼此不同的实体类型)
无监督的“弱实体识别”——我们可以用BERT词汇表中存在的一组常见名词(如drug, drugs, treatment, therapy)标记一个专有名词(例如一种像阿托伐他汀的药物)。这些普通名词可以作为专有名词的实体标记代理。在某些情况下,词汇表中的专有名词也可以作为实体的代理(例如,人名——johnson, smith, cohen可以作为一个人的实体类型的描述符)
关系三元组的无监督收获。
BERT词汇统计数据
上述所有潜在应用的一个共同方面是使用BERT的词汇表来表示
在词汇表中,一个词与相邻词的连接是通过余弦相似度来度量。
MLM对句子中某个位置的单词进行最高预测。句子中的任何输入项都被标记为BERT词汇表中的单词。MLM对输入语句中某个位置的预测是根据BERT的词汇表进行的
使用通用词汇表或描述符来描述MLM的输入术语和输出预测,使上面列出的各种应用成为可能。预训练BERT生成约30,000(28,996)个表示BERT词汇表中的单词的向量。
小写词占BERT词汇量的近45%,大写词占27%——完整单词基本上占BERT词汇量的72%。包括其他语言字符和subwords(##kan)在内的符号占近28%,它们是预测subwords和语音相似的描述符。使用MLM来预测句子中的词的描述符通常是这些不同类别的混合。然而,对于像“cell”这样的术语来说,最高的邻居(包括原始向量邻居和MLM输出的预测)将主要是其他术语,如上面的细胞,监狱等等,而对于像“kan”这样的术语,将主要是subwords和其他语音相似的字符。
鉴于我们可以使用BERT的词汇来做一些任务,如用普通名词实体类型(drug, drugs, treatment)标记一个专有名词(阿托伐他汀),这可以通过将包含阿托伐他汀的句子在分词之前屏蔽整个单词来实现。(由于阿托伐他汀不是BERT词表的一部分,所以它会被标记成多个subwords) 这样出现了两个问题:
在向量的原始嵌入中描述一个单词的空间描述符是否与BERT词汇表中的其他词汇截然不同?
MLM使用BERT词汇表中的描述符来预测句子中某个位置的单词,在预测空间中与BERT词汇表中的其他词汇有区别吗?
结果表明,它们在原始向量空间和MLM预测空间都是不同的。此外,即使邻域的性质(这些术语所捕获的不同含义)发生了变化,也可以通过微调保留这种明显的分离
BERT的原始向量有不同的邻域
在微调之前和之后,BERT词汇表中每个词与其相邻词的邻域的累计直方图图显示了一个明显的尾,所有具有不同的相似性(语义、句法、语音等)的术语都在这个尾巴上。邻域是由BERT原始向量的余弦相似度来完成的。
下图显示了单个术语与BERT词汇表中的其他术语的直方图。也显示了微调后,尾部的术语是如何变化的。
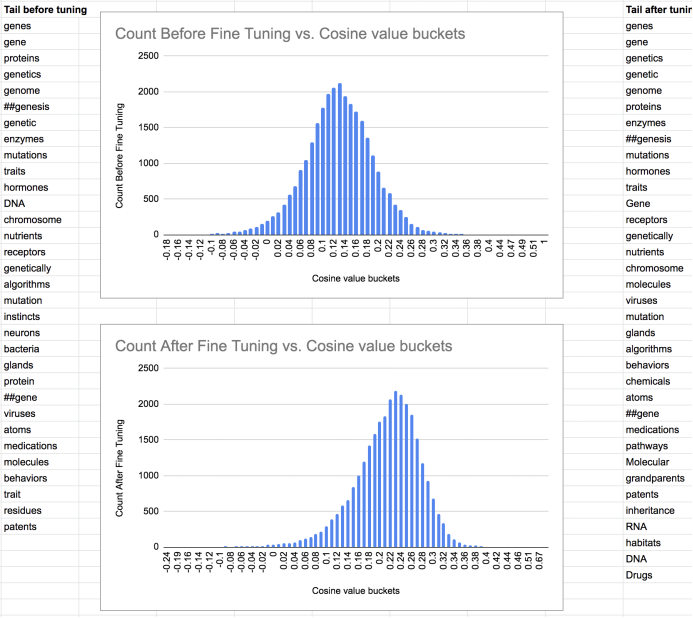
单个术语“gene”与BERT词汇表中所有其他术语向量的余弦相似度的直方图。词的邻域随着微调而变化
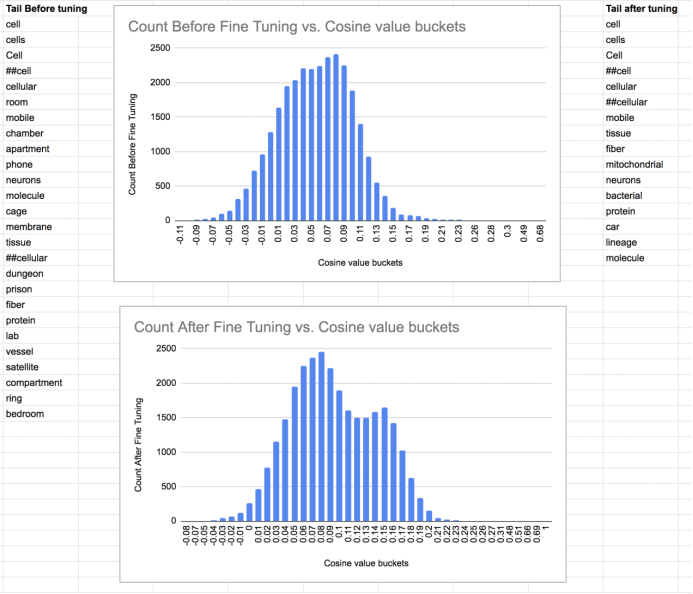
单个术语“cell”与BERT词汇表中所有其他术语的向量的余弦相似性的直方图。术语的邻域会随着微调而变化。请注意,在生物医学语料库上对“cell”一词进行微调后,应消除不同的含义。
Bert MLM对于一个token的预测也是不同的
下面的直方图显示了对输入语句“Connan went to prison cell”中的词“ cell”的预测(在标记化后变为“Con ##nan went to prison cell”)
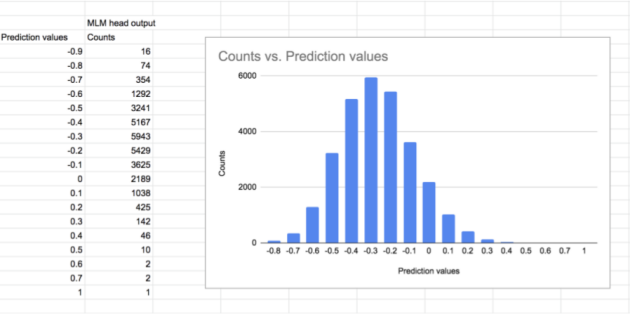
我们观察到图中有像原始嵌入空间图中的尾巴一样独特的尾巴
我们从尾部选择多少项作为阈值(用于原始嵌入空间和MLM头部的预测)都取决于我们应用程序的需求,特别是我们需要的精度和召回率。这些分布的平均值(在单个术语级别或总体级别上)有助于我们做出选择(将噪声与信号分离)。
Roberta是一个类似BERT的模型,词汇量为50,265个词,在其原始向量空间中,该词的余弦邻居以及MLM目标的预测分数显示出明显的尾巴,如下所示。
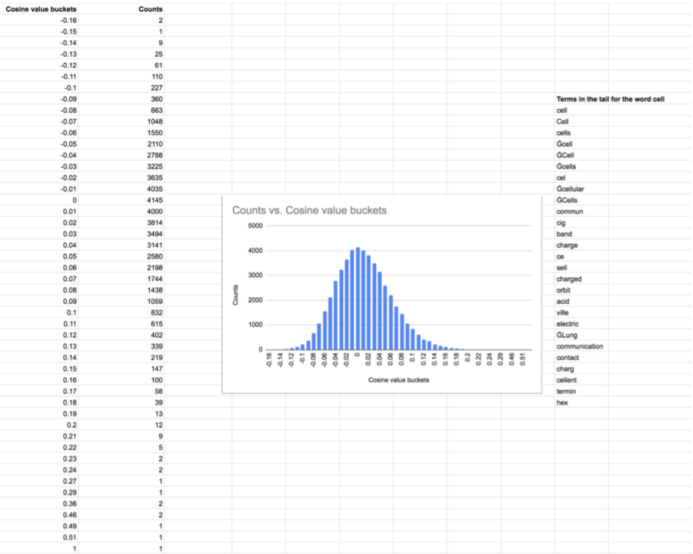
Roberta Cosine社区中的“ cell”一词。直方图中该术语相对于所有50,265个术语的尾巴不同。
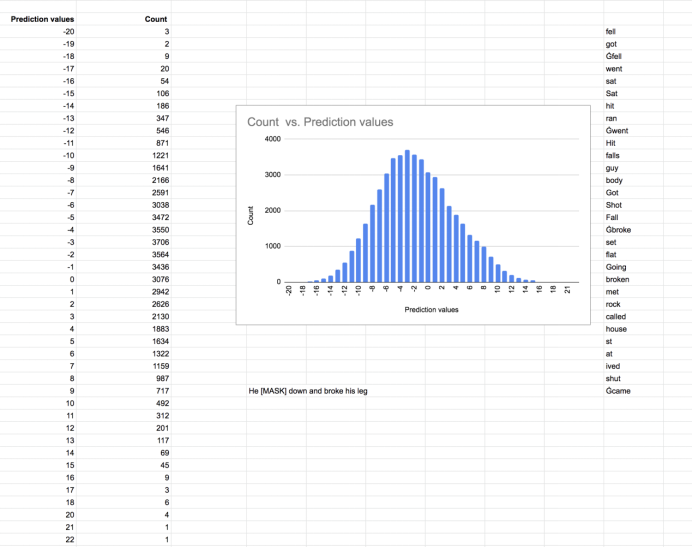
Roberta输出的词汇量为50,265个词,在预测句子中的词时表现出明显的尾巴。上面的输出是句子he [mask] down and broke his leg”中单词“fell”的预测分数的直方图分布。
具有MLM的其他transformer模型(Distilbert,Camembert)很可能在原始向量空间及其预测分数输出中表现出明显的尾部,尽管这需要确认。
使用原始嵌入的示例的详细信息
如果我们有两个术语(可以是单个单词或短语),我们的目标是确定这两个术语之间的共同点,我们会:
首先选择每个词在句子中单独出现的句子,然后使用MLM head查找这些词的预测邻居。这些描述符的交集独立地充当这些术语含义的签名。
选择两个词都出现的句子,并预测这些词的邻居。当它们相互关联时,会产生两个签名,每个术语一个。
上面有四个描述符集:单个术语的描述符和两个术语一起使用时的描述符。由于上面收集的所有描述符都是词汇表的一部分,因此我们可以在原始嵌入空间中将这些描述符作为无向图进行检查,其中节点之间的连接是基于阈值选择的(阈值是根据尾部选择的)。检查描述符往往会产生一个签名,该签名捕获两个空间中的相似性。同样,具有高阈值的原始嵌入空间可用于组合描述符中的拼写变化。事实证明,这在无监督地收集同义词候选词的任务中很有用。
最后的想法
自有关word2vec的论文发表以来已经过去了将近7年。BERT及其变体已成为NLP任务的主要内容。word2vec训练的输出只有向量,而在BERT的情况下,我们得到的输出中既有原始学习的向量,又有一个模型,这个模型可以将这些向量进行微调而转换为适合特定任务的表示。
虽然这两种模型都产生了一个向量,这些向量将一个词的多种含义组合成一个向量,并且每个都具有与其他词相比尾巴不同的直方图(word2vec情况下语料库中所有词的向量都与BERT中词和subwords的向量不同), BERT的向量由于以下原因而脱颖而出:
BERT的向量似乎捕获了更大范围的相似性-例如,像“kana”这样与其他语言的发音相邻的subwords的相似性
给定由单个字符,subwords和单词组成的词汇表,BERT可以有效地表示句子中的任何单词,消除了词汇量过大的情况(至少对于英语而言)。
不管语料库的大小,固定的词汇表具有明显的实际优势:在计算过程中,可以将词汇表的所有向量存储在GPU或其他受内存限制的环境中。
最后,除了转换为最适合特定NLP任务的表示这一关键功能之外,BERT的向量与训练后的模型相结合还可以表示句子中单词的特定含义。Word2vec模型学习了单词的向量表示,并通过自我监督学习捕获了单词之间的相似性。除学习向量外,基于transformers的BERT模型也学习了可以解决各种NLP任务的多层transformers向量。
(王宇飞编译,张梦婷校对)
研究动态
百度ERNIE取得新的NLP基准记录
Baidus Pre Training Model Ernie Achieves New NLP Benchmark Record
从搜索引擎到移动智能助手,随着自然语言处理广泛应用在越来越多的地方,诸如百度的ERNIE(通过知识整合增强表示)等预训练语言模型由于其先进性在机器学习领域受到了广泛关注。从今年早些时候ERNIE发布以来,今天,我们很高兴地宣布ERNIE在GLUE上取得了最新的性能,并成为世界上第一个在宏观平均得分方面超过90的模型(90.1)。
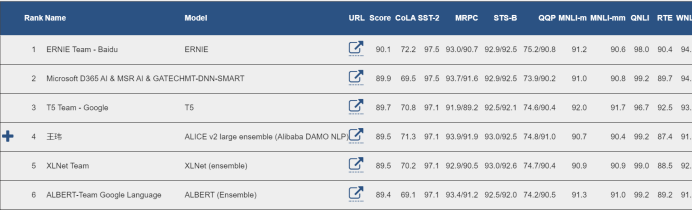
GLUE(通用语言理解评估)是一个被广泛认可的用于评估自然语言理解(NLU)的多任务基准和分析平台。它包括多个NLU任务,包括问题回答、情感分析以及用于模型评估、比较和分析的关联在线平台。
ERNIE是一个连续的预训练框架,通过顺序多任务学习对预训练任务进行逐步构建和学习。我们在今年年初推出了ERNIE 1.0,并在7月发布了改进的ERNIE 2.0模型。后者在中文和英文的16个NLP任务中均胜过Google的BERT和卡耐基梅隆大学的XLNet(竞争性的预训练模型)。
这次,ERNIE模型在GLUE公共排行榜上名列前茅,其次是Microsoft的MT-DNN-SMART和Google的T5。具体而言,ERNIE在CoLA,SST-2,QQP和WNLI上已取得了SOTA,并以10点的显着提升超过了Google的BERT。
为什么ERNIE表现这么好?
ERNIE 2.0的主要贡献是持续的预训练。我们的研究人员使用可用的大数据和先验知识创建不同种类的无监督预训练任务,然后通过多任务学习来逐步更新框架。
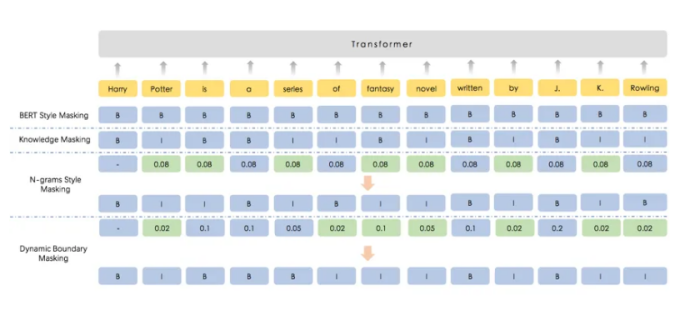
在ERNIE 2.0之上,我们的研究人员对知识掩盖和面向应用程序的任务进行了一些改进,目的是提高模型的一般语义表示能力。为了改进知识掩盖策略,我们提出了一种新的基于互信息的动态知识掩盖算法。它可以有效地解决ERNIE 1.0中掩盖的语义单元多样性低的问题。
首先,动态知识掩蔽算法通过假设检验从海量数据集中以高置信度提取语义单元,并计算它们的互信息。基于此信息及其统计信息,模型计算这些语义单元的概率分布,该概率分布用作掩蔽时的采样概率。这种动态知识掩蔽算法不仅保持ERNIE 1.0建模知识单元的能力,而且还提高了掩蔽先验知识的多样性。
下图显示了不同掩蔽算法之间的区别,其中B(开始)代表文本范围的开始,而I(内部)代表当前位置应形成一个范围,其中单词标记为B。以下图为例,动态知识屏蔽算法根据概率分布对语义单元进行采样,并动态构造要屏蔽的语义单元。
为了提高ERNIE在应用程序任务上的性能,我们还构建了针对不同应用程序的预训练任务。例如,我们的团队添加了一个共指解析任务,以识别文本中引用同一实体的所有表达式。在一个无监督的语料库中,我们的团队屏蔽了文本中同一实体的某些表达式,用不同的表达式随机替换了它们,并训练了模型以预测替换后的文本是否与原始文本相同。
此外,我们扩充了训练数据并优化了模型结构。在预训练数据集中,我们进一步使用对话数据来改进语义相似度计算。在对话数据中,对应于相同答复的话语通常在语义上相似。通过利用对话数据中的这种语义关系,我们训练ERNIE更好地对语义相关性进行建模,从而提高了诸如QQP之类的语义相似性任务的性能。
我们一直在将ERNIE的语义表示应用于我们的实际应用场景中。例如,我们的2019年第三季度财务结果突出显示,我们的前1个搜索结果所满足的用户查询百分比绝对提高了16%。这种改进是由于我们在搜索引擎中采用了ERNIE来回答问题。
尽管对语言的理解仍然是一个困难的挑战,但是我们在GLUE上的研究结果表明,具有持续训练和多任务学习的预训练语言模型是NLP研究的一个有希望的方向。我们将通过持续的预训练框架来不断提高ERNIE模型的性能。
(王宇飞编译,李朝安校对)
自然语言处理的黄金时代
通过软件自动操纵自然语言的自然语言处理(NLP)已有数十年的历史。在早期,它产生了一些有趣的结果,例如将“out of sight, out of mind”转换为“blind fool”。“The girls are sewing buttons on the second floor”,这是计算机无法理解的句子的一个示例(二层是女孩的位置还是缝制的目标?),因为它缺乏一般的现实世界智能。机器可能擅长数学,但是很难将涉及语音和文本的语言问题转换为数学公式。然而近年来,NLP技术取得了重大突破,迎来了新的“黄金时代”。到2025年,总收入预计将超过220亿美元。
NLP技术在当前黄金时代的第一个突破是2013年推出的Word2Vec算法,该算法自动读取庞大的文本数据集,并了解该数据集内所有单词之间的关联和关系模式。Word2Vec并不是尝试理解文本,而是在单词嵌入之间寻找关联。例如,“Rather than attempting to understand text,”,单词rather和than在单词attempting之前,而单词attempting被单词rather 、than、to、understand包围。然后,Word2Vec将此信息压缩到较小的维度,以创建学习词汇的紧凑编码。就像斜视会使模糊的相似对象看起来更相似一样,这种压缩迫使单个单词关联形成表达单词关系的逻辑模式。结果是每个单词的向量,表达了该单词与压缩模式的关系。这些向量可用于为各种NLP任务(例如机器翻译,问题解答和情感分析)提供高度准确的结果。他们的单词向量还可以用于在单词上建立有趣的数学关系,例如,“gospel – God = jazz”和“fish + music = bass”。Word2Vec有其弱点,例如,它只能存储具有多种不同含义的单词的单一表示形式。但是,它在NLP准确性方面有了巨大的飞跃。
NLP的下一个进步,是2018年初的ELMo(语言模型嵌入)。与Word2Vec不同,Word2Vec中每个单词使用固定的向量,而ELMo会考虑周围的句子或段落来计算单个单词的向量。然后,ELMo使用深度学习的多个隐藏层来帮助捕获单词相关性。这使ELMo可以在不同的层次上学习不同级别的语言表示。例如,较早的一层可能专注于原始信息,例如将名词与动词区分开,而较下一层可能关注于更高级别的信息,例如将Janine与Jamie区分开。结果表明,在各种NLP任务中,ELMo在很大程度上胜过Word2Vec。
2018年下半年,随着BERT(transformers的双向编码器表示)的发布,NLP取得了更大的突破。BERT是基于注意力机制的,它首先观察到人类通过关注重要细节并消除噪音来处理信息。自然的,在机器翻译之类的NLP问题中,给定相关句子的训练语料库(例如,将源文本翻译成另一种语言),注意力机制可以学习源句子中位置最相关的一组信息集中。
NLP研究人员通过使用多个注意力分布来极大地提高注意力机制的性能,所以创建了一种称为Transformer的算法。BERT通过引入MLM使Transformer迈出了重要的一步,其中句子中15%的单词被随机屏蔽。然后,使用一个Transformer基于围绕它左右两边的未屏蔽字为每个屏蔽字生成预测。BERT似乎只是对Transformer的一个细微调整,而Transformer本身就是对注意力机制的细微调整。这些小的调整可以极大地提高NLP输出的质量。
目前,BERT是NLP研究社区的宠儿,它为某些NLP任务(如问题解答)提供了超过人类水平准确性的结果。但是,NLP可能不会长期保持这种状态。这是一个大胆的预测:在一年之内,我们会忘记BERT而取而代之的是名为ERNIE的更好算法。尽管名称可能最终会错误,但原则仍然存在:我们正处于NLP时代的曙光中,人们似乎每月都在寻找更好的算法,而且还看不到尽头。这些算法中的许多不仅作为研究论文,而且作为几乎可以立即用于商业NLP产品的开源代码向公众发布。欢迎来到自然语言处理的黄金时代!
(王宇飞编译,李朝安校对)
Google推出了AutoML Natural Language,改进了文本分类和模型训练功能
Google Launches Automl Natural Language with Improved Text Classification and Model Training
今年早些时候,Google完成了对AutoML Natural Language的总结,这是其Cloud AutoML机器学习平台向自然语言处理领域的扩展。经过长达一个月的测试后,AutoML 今天开始向全球客户开放,支持分类,情感分析和实体提取等任务,也支持一系列文件格式,包括本机和扫描的PDF。
通过复习,AutoML Natural Language可以利用机器学习来揭示电子邮件,聊天记录,社交媒体帖子等文本的结构和含义。它可以从上传粘贴的文本中或Google Cloud Storage文档中提取有关人员,地点和事件的信息,并且允许用户训练自定义的AI模型来分类,检测和分析情感、实体、内容和句法。此外,它还提供了自定义实体提取功能,该功能可以识别标准语言模型中未出现的文档中的特定域的实体。
AutoML Natural Language具有5,000多个分类标签,并且可以训练多达100万个最大10MB的文档。Google表示,它非常适合“复杂”用例,例如对包含大型内容分类法的组织,来进行法律文件的理解或文档分割。自发布以来的几个月中,它已经得到了改进,特别是在文本和文档实体提取方面。Google表示,AutoML Natural Language现在考虑了额外的上下文(例如文档的空间结构和布局信息)来进行模型训练,预计将提高对发票,收据,简历和合同中文本的识别能力。
此外,谷歌表示,AutoML Natural Language现在已获得FedRAMP的中等级别授权,这意味着它已经根据美国政府的规定对丢失影响有限或严重的数据进行了审查。谷歌表示,这与新引入的功能(使客户可以创建数据集,训练模型并进行预测,同时将数据和相关的机器学习处理保持在单个服务器区域内)一起,使联邦机构更容易利用这一优势。
Hearst已经在使用AutoML Natural Language来帮助其组织其国内外杂志的内容,日本出版商Nikkei Group正在利用AutoML Translate来发布不同语言的文章。Chicory,第三个早期采用者,利用它为克罗格,亚马逊和Instacart等杂货零售商开发定制的数字购物和营销解决方案。
自然语言的产品经理Lewis Liu在博客中解释说,他们最终目标是为需要自定义机器学习模型的组织,研究人员和企业提供一种简单,轻松的方式来训练模型。他说:“自然语言处理是用于揭示文本结构和含义的有价值的工具。” “我们通过更好的微调技术和更大的模型搜索空间,与Google AI研究机构合作,不断提高模型的质量。我们还将引入更多高级功能,以帮助AutoML Natural Language更好地理解文档。”
值得注意的是,AutoML的发布是紧随AWS Textract之后的,AWS Textract是Amazon的用于文本和数据提取的机器学习服务,该服务于5月份首次亮相。Microsoft在Azure Text Analytics中也提供了类似的服务。
(王宇飞编译,李朝安校对)
项目工具
2019年Google搜索算法更新大名单
Google调整和更新Search的步伐已大大加快。仅在2018年,Google就对Search进行了3,200项更改,高于2010年的400项更改。这些更改中只有一小部分获得了公众的认可,或者说引起了广泛关注,但这些更改有时确实可以提供对Google优先处理的内容的见解。
2019年看到了一些公开披露的核心和其他搜索算法更新。在2019年的许多变化中,谷歌为核心更新建立了命名约定,并将自然语言理解带入了搜索结果。
2019年的核心更新
2019年3月核心更新。除了是本年度的首次重大算法更改外,此更新还是第一个遵循Google的新命名约定的内容,涉及更新的类型和发生的日期。在2019年3月核心更新发布后,我们对500多个搜索社区成员进行了调查。反馈并没有显示出任何明显的网站类型或内容受到影响的模式。超过一半的受访者(58%)表示他们在更新后产生了负面影响,三分之一(33%)的人表示看到了积极的变化,而9%的受访者说没有变化。
2019年6月核心更新。Google于6月2日提前宣布其2019年6月的核心更新。该更新大约花了五天的时间才能完全推出,在此期间,也发生了不相关的多样性更新。
2019年9月核心更新。Google于9月24日发布了2019年9月的核心更新,比发布日期提前了几个小时。根据各种SEO工具集提供商提供的数据显示,此更新似乎对YMYL网站的排名产生了较大影响,但是,其影响没有6月核心更新那么重要。RankRanger和Sistrix均指出,医疗和旅行领域内的站点受到了影响,而SEMRush表示,赢家和输家之间的格局并不明显。
BERT
10月25日,Google引入了BERT算法进行搜索。BERT是一种开放源代码的自然语言理解技术,谷歌表示,它将提高搜索引擎对查询的理解,特别是较长的口头或书面查询。这个操作被吹捧自2015年RankBrain回归以来,谷歌搜索系统最大的变化,谷歌也表示BERT将影响十分之一的查询。
BERT与其他基于神经网络的技术的不同之处在于,它可以基于句子或查询中的整个单词集来训练语言模型,从而使这些语言模型可以根据周围的单词来学习单词上下文,而不只是根据给定单词之前或之后的单词。
谷歌表示,在搜索的背景下,BERT帮助Google理解了“更长,更多”的对话查询,或者在诸如对含义有重大影响的“for”、“to”之类的介词中进行搜索。
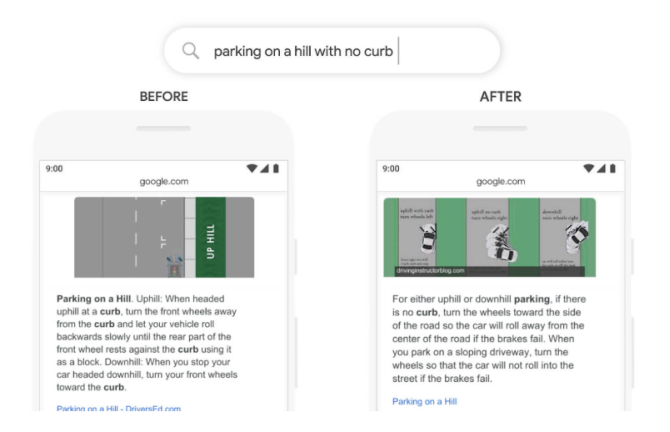
应用BERT后,Google可以了解查询中“否”一词的重要性,并可以提供更相关的结果。资料来源:谷歌。
应用BERT时,它也会影响出现在精选片段中的结果。谷歌现在将BERT应用于全球70多种语言的搜索中。BERT的自然语言处理能力也已应用于Bing查询。Bing的BERT实施比Google的实施早六个月,但该公司直到Google宣布后才宣告它。
尽管对于搜索引擎而言,这是一个重大更新,但其影响可能难以评估,因为许多跟踪工具主要衡量较短的查询,而网站所有者通常不会跟踪长尾查询。
(王宇飞编译,张梦婷校对)
近期论文
PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization
Jingqing Zhang Yao Zhao Mohammad Saleh Peter J.Liu
主要贡献:
文章提出了PEGASUS——一种带有空缺句生成的序列到序列模型,作为针对抽象文本摘要量身定制的预训练目标。文章研究了几种空缺选择方法,并将确定的主句选择作为最佳策略。
研究动机:
目前,对大型文本语料库中具有自我监督目标的transformers进行预训练,然后对下游NLP任务进行微调取得了巨大的成功。然而,适合抽象的文本摘要的预训练目标尚未得到探索。文本摘要旨在从输入文档中生成准确而简洁的摘要。与仅从输入中复制信息片段的提取摘要相反,抽象摘要可能会产生新颖的单词。所以,一个好的抽象摘要应涵盖输入中的主要信息,并且在语言上是流利的。
模型思路:
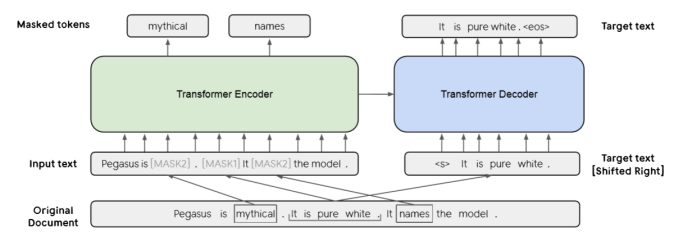
PEGASUS的基本体系结构是标准的Transformer编码器/解码器。
GSG和MLM同时作为预训练的目标。输入三句话, 一句话用[MASK1]掩盖,并用作目标生成文本(GSG)。 其他两个句子保留在输入中,但某些标记被[MASK2](MLM)随机掩盖。
训练语料考虑了两个大型文本语料库:C4,由350M个网页(750GB)中的文字组成; HugeNews,从2013-2019年的新闻和类似新闻的网站收集的1.5B文章(3.8TB)数据集。
实验结果:
在涉及新闻、科学、故事、说明、电子邮件、专利和立法法案的12个下游汇总任务中评估了PEGASUS模型。实验表明,在通过ROUGE分数衡量的所有12个下游数据集上,它均达到了最先进的性能。我们的模型还显示了对低资源摘要的惊人性能,仅使用1000个示例就超过了6个数据集上的最新结果。
(王宇飞编译,李朝安校对)
近期会议
ICAART 2020: International Conference on Agents and Artificial Intelligence
Feb 22 - Feb 24, 2020 马耳他 瓦莱塔
ICAART中有2条路线,一条与一般的Agent和Distributed AI相关,另一条与智能系统和计算智能相关。会议计划由几种不同类型的会议组成,例如技术会议,海报会议,主题演讲,教程,专题会议,博士联合会,小组和工业会议。会议上发表的论文可在SCITEPRESS数字图书馆中获得,并在会议记录中发表,并且一些最佳论文被邀请与Springer进行后期公开。
ICLR 2020:International Conference on Learning Representations
Apr 26 - Apr 30 ,2020 埃塞俄比亚 亚的斯亚贝巴
ICLR是每年春季举行的机器学习会议。自2013年成立以来,ICLR就采用了公开的同行评审程序来提交裁判论文(基于Yann LeCun提出的模型)。 2019年,有1591篇论文提交,其中500篇接受海报展示(31%),24篇接受口头演讲
JCDL 2020: Joint Conference on Digital Libraries
June 19 - June 23 ,2020 湖北 武汉
数字图书馆联合会议(JCDL)是一个重点讨论数字图书馆及其相关的技术实践以及社会问题的国际论坛。JCDL通过将ACM数字图书馆会议和IEEE-CS数字图书馆会议的进展结合起来,加强了ACM和IEEE-CS已经建立的会议卓越的传统。在本次会议上,JCDL向在该领域做出杰出贡献的人士颁发Vannevar Bush最佳论文奖、最佳学生论文奖、最佳国际论文奖、最佳海报奖。该会议邀请国家和国际社会就数字图书馆感兴趣的广泛主题发表论文。