文本挖掘与机器学习跟踪扫描动态快报(2020.02)
实时跟踪、关注文本挖掘与机器学习领域最新研究动态
研究动态
170亿个参数! Microsoft DeepSpeed孕育世界上最大的NLP模型
17 Billion Parameters Microsoft Deepspeed Breeds Worlds Largest Nlp Model
深度学习模型正变得越来越大以满足对更好的性能的需求。同时,训练这些庞大的深度学习模型所需的时间和金钱也在不断增加。
最大的训练瓶颈之一是GPU内存,它限制模型训练中使用的参数数量。 Microsoft认为,现有的培训解决方案在计算、通信和开发效率方面会受到影响,主要有两个原因:
-
数据并行性无法减少每个设备的内存消耗-具有超过10亿个参数的模型将超过具有32G内存的GPU的容量。
-
模型并行性扩展到多个节点时无法有效扩展–由于细粒度的计算和昂贵的通信,模型的性能在扩展到多个节点时会降低。
为了解决此问题,Microsoft引入了一个名为DeepSpeed的新库,该库可以将每个节点的批处理大小扩大四倍,而将训练量减少三分之二,从而可以训练1000亿个参数模型。
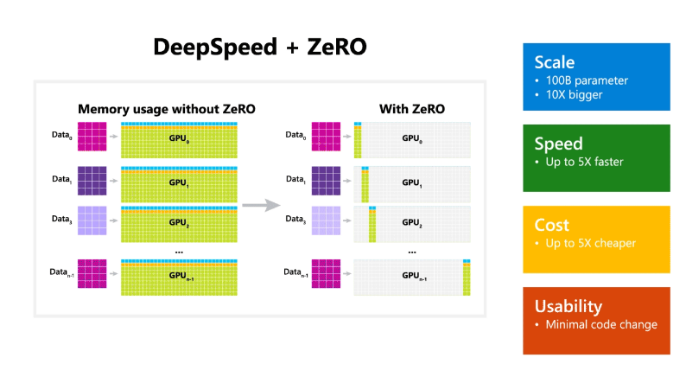
DeepSpeed的一个非常重要的组成部分是ZeRO(Zero Redundancy Optimizer),这是一种新颖的并行化优化器,可以显著减少模型以及数据并行化所需的资源,同时提高可训练参数的数量。

ZeRO的主要优化阶段对应于优化器状态、梯度和参数划分,使其能够减少训练有关内存消耗和增大通信量。
微软表示,ZeRO可以在当前的GPU集群上训练具有1000亿个参数的深度学习模型,“其吞吐量是当前最佳系统的三到五倍”。
微软利用DeepSpeed的大型培训功能,构建了图灵自然语言生成模型(T-NLG)。 这是有史以来最大的NLP模型,具有170亿个参数。 T-NLG已在主流NLP任务上实现了SOTA性能。
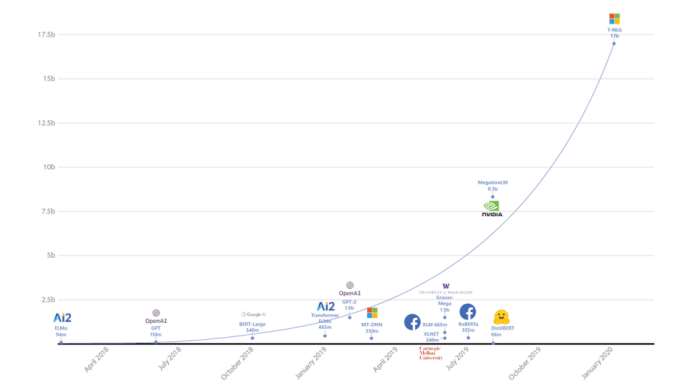
T-NLG具有比其他任何NLP模型都要多的参数
与Google著名的大规模语言模型BERT和OpenAI的GPT-2一样,T-NLG基于流行且强大的Transformer架构,能够处理要求很高的语言生成任务,例如问题解答和自动摘要。此外,借助DeepSpeed,在具有类似挑战性的NLP任务(依靠更大的训练参数来实现更自然,准确和流畅的文本生成)时,具有170亿个参数的T-NLG可以轻松胜过那些SOTA模型。
在准确性方面,T-NLG在标准语言任务以及抽象摘要任务上表现出明显的性能优势。

T-NLG与GPT-2和Megatron-LM模型在WikiText-103上(复杂性作为度量标准,较低者为佳)和LAMBADA(下一个词预测精度为度量标准,较高者为佳)上相比
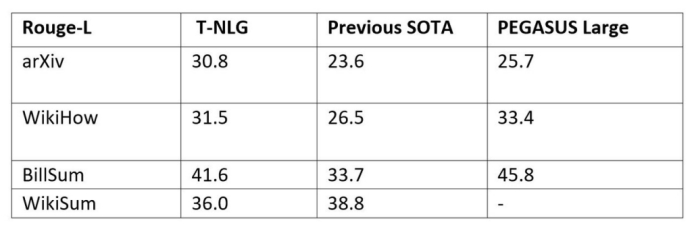
T-NLG与PEGASUS模型和以前的SOTA模型在四个常见的抽象摘要数据集上的比较(ROUGE分数作为度量标准,越高越好)

将T-NLG与类似于CopyNet的LSTM模型进行比较,由人类注释者评估的事实和语法正确性。
T-NLG可以做更多的事情,例如直接提问和零样本提问等功能,有关详细信息,请参见Microsoft的博客。
(https://www.microsoft.com/en-us/research/blog/turing-nlg-a-17-billion-parameter-language-model-by-microsoft/) 遗憾的是,虽然T-NLG尚未开源(但尚未发布),但值得庆幸的是,您可以在GitHub上找到与PyTorch兼容且开源的工具DeepSpeed,并亲自尝试。(https://github.com/microsoft/DeepSpeed)
(李朝安编译,张梦婷校对)
OpenAI → PyTorch
我们正在PyTorch上标准化OpenAI的深度学习框架。过去,我们根据项目的相对优势在许多框架中执行项目。现在,我们决定通过标准化,以使我们的团队更容易创建和共享模型的优化实现。
作为此举措的一部分,我们刚刚发布了在Deep RL中启用PyTorch的Spinning Up 版本,这是OpenAI制作的开源教育资源,可让您更轻松地了解深度强化学习。我们还在为高度优化的blockparse内核编写PyTorch绑定,并将在接下来的几个月中开源这些绑定。
我们选择PyTorch的主要原因是为了提高我们在GPU上的大规模研究效率。 在PyTorch中尝试并执行新的研究思路非常容易;例如,改用PyTorch将使我们在生成建模方面的研究思想的迭代时间从数周缩短至数天。我们也很高兴能加入一个快速增长的开发者社区,社区的活跃者还包括Facebook和Microsoft等组织,以推动GPU规模和性能的发展。
展望未来,我们将主要使用PyTorch作为我们的深度学习框架,但有时在某些特定技术原因时会使用其他框架。我们的许多团队已经做出了转换,我们期待在接下来的几个月中为PyTorch社区做出贡献。
(李朝安编译,张梦婷校对)
IBM将知识注入NLP模型的新方法
IBM Highlights New Approach to Infuse Knowledge into NLP Models
在MIT-IBM Watson AI Lab实验室,杜兰大学和伊利诺伊大学的研究人员本周公布了一项研究,该研究使计算机能够更接近人的阅读理解和推论。
研究人员创造了他们所谓的“突破性神经符号方法”,将知识注入自然语言处理过程。该方法于在纽约市举行一周的AAAI-20会议上宣布。
演绎和推理对于人类和人工智能都是至关重要的,但是许多公司的AI系统仍然难以理解人类语言和文本含义,IBM认为这被定义为两个自然语言句子之间的关系。
MIT-IBM Watson AI Lab实验室的负责人David Cox说:“自AI诞生以来,已经有两个思想流派:一个专注于神经网络/深度学习的使用,在过去几年中非常有效和成功。神经网络和深度学习需要数据和额外的计算能力才能蓬勃发展。 数据数字化的出现推动了神经网络/深度学习革命。象征性AI是另一个阵营,它认为人对周围世界的一些了解是基于理性的。不过,过去六年来,关于人工智能的所有硕果都与深度学习和神经网络有关。于是,我们有一个类比的想法,就像神经网络需要数据和计算等东西来重生一样,象征性AI也需要东西”。研究人员得出理论是它也许需要的是神经网络。这两个阵营可以相互补充,并以富有成效的方式利用各自的优势和劣势。
“我们在AI实验室中所做的工作是关于neuro-symbolic AI。它是象征性AI和神经网络的混合思想。” 他认为这篇论文提供了研究人员开始将经典象征性AI与神经网络思想融合在一起的示例。
Cox举例,一个人类能够判断,如果另一个人说他正在外面散步,并且在家吃午餐,那这两个说法是矛盾的。
“我们发现它们是如此自然,但我们没有能够达到如此自然的AI系统能够有同样的理解,这个团队将神经网络和符号AI混合在一起,并使用组合系统来解决问题。” 在论文中,研究人员写道,他们正在提出一种方法,以补充来自外部知识源的信息,对基于文本的包含模型(这是自然语言处理中的基本任务)进行补充。
研究人员写道,使用外部知识可以使模型更健壮并提高预测准确性。他们发现与多个基于文本的包含模型相比提高5%-20%”。
Cox表示目前正在应用于情绪分析的尝试。“对浅层文字有相对的了解将指引我们走向正确的方向” 但是,如果您读了一本科学教科书然后尝试通过测验,则需要对教科书中的数据实际含义有深刻的了解。
该团队发现,用神经网络注入知识图(即已知事物的表示)比以前任何依赖于没有知识图的神经网络方法都要强大。 考克斯强调说,研究人员处于研究的早期阶段,但他认为这是一项将影响许多行业的重要技术。
(李朝安编译,张梦婷校对)
Facebook的AI无需额外培训即可加速自然语言处理
Facebooks AI Speeds up Natural Language Processing without Additional Training
自然语言模型通常需要解决两个难题:将句子前缀映射到固定大小的表示形式,以及使用这些表示形式来预测文本中的下一个单词。 在最近的一篇论文中,Facebook AI Research的研究人员断言,第一个问题(映射问题)可能比预测问题(基于“最近相邻”检索机制来扩充语言模型的假设)更容易。他们说,它可以记住罕见的模式,并且无需额外的培训即可达到最领先的复杂性评分(用来衡量词汇和语法多样性)。
正如研究人员所解释的那样,语言模型将概率分配给单词序列,以便从上下文tokens序列中估计目标tokens的分布(发生不同可能结果的概率)。所提出的方法kNN-LM将上下文映射到由预训练的语言模型计算出的定长数学表示形式。 给定一个训练示例,定义一个键值对,其中键是上下文的数学表示,而值是目标单词。
在测试时,kNN-LM获取输入上下文,并且基于下一个的单词和上下文表示生成输出分布。它根据距离函数检索最近的邻居,此时它计算邻居上的分布,同时汇总每个词汇项在检索到的目标中出现的所有可能概率。
研究人员指出,kNN-LM与任何产生固定大小的上下文表示语言模型兼容。 在这项研究中,这使他们能够在包含所有Wikipedia文章的1.03亿个tokens组成的数据集上训练基于Transformer的模型,其中25万个tokens被保留,用于之后的开发和测试。
在实验中,kNN-LM在测试时“显著”优于基线,该团队将其归因于模型能够学习隐含相似的上下文表达的功能倾向。kNN-LM增加了一些计算开销,在单个处理器上花了大约两个小时才能为1.03亿个条目建立缓存,而运行验证集大约需要25分钟。但是团队指出,并行化模型是“简单的”,并且不需要基于GPU的培训。
(李朝安编译,张梦婷校对)
TextFooler算法愚弄NLP AI
近年来,自然语言处理算法和系统令人印象深刻,但它们仍然容易受到一种被叫做“对抗性示例”的攻击。有着精心设计的短语的“对抗性示例”可能导致NLP系统以意想不到的方式出现不好的效果。AI程序可能会因为这些奇怪的例子而表现失常,因此,AI研究人员正在尝试设计各种方法来避免对抗性例子的影响。
最近,来自香港大学和新加坡科学技术研究局的一组研究人员合作创建了一种算法,该算法演示了对抗性示例的危险。如Wired所报道,该算法被研究团队称为TextFooler,它通过巧妙地更改句子的一部分来影响NLP分类器对该句子的分类。例如,该算法将一个句子转换为另一个相似的句子,并将该句子输入分类器,该分类器用于确定评论是正面的还是负面的。原来的句子是:
The characters, cast in impossibly contrived situations, are totally estranged from reality.
它被转换成这个句子:
The characters, cast in impossibly engineered circumstances, are fully estranged from reality.
这些细微的变化促使文本分类器将评论分类为正面而不是负面。研究小组在几种不同的数据集和文本分类算法上测试了相同的方法(用同义词替换某些单词)。研究团队报告说,他们能够将算法的分类准确性从90%降低到10%。尽管事实是,人们阅读这些句子会把它们解释为具有相同的含义。
在一个越来越频繁地使用NLP算法和AI的时代,NLP算法被用于诸如评估医疗索赔或分析法律文件等重要任务,这些结果令人担忧。目前尚不清楚当前使用的算法对抗性的例子有多大危险。世界各地的研究团队仍在努力确定他们可以产生多少影响。最近,斯坦福大学Human-Centered AI小组发布的一份报告表明,对抗性示例可能会欺骗AI算法,并被用于进行税务欺诈。
最近的研究存在一些局限性。例如,虽然加州大学欧文分校计算机科学系的助理教授Sameer Singh注意到所使用的对抗方法是有效的,但它依赖于AI体系结构的一些知识。AI必须被反复探测,直到找到有效的单词组为止,这种重复的攻击可能会被安全程序注意到。Singh及其同事对此进行了研究,发现像OpenAI算法这样的高级系统可以在在某些触发短语的提示下传递带有种族主义色彩的有害信息。
在处理照片或视频等视觉数据时,对抗性示例也是一个潜在问题。一个著名的示例涉及对小猫的图像进行某些微妙的数字转换,促使图像分类器将其解释为监视器或台式PC。在另一个例子中,加州大学伯克利分校的教授Dawn Song的研究发现,对抗性例子可以用来改变计算机视觉系统对路标的感知方式,这可能对自动驾驶汽车造成危险。
像香港-新加坡团队所做的这样的研究可以帮助AI工程师更好地了解AI算法具有哪些漏洞,并设计出可能防范这些漏洞的方法。作为示例,集成分类器可用于减少对抗性示例欺骗计算机视觉系统的机会。通过这种技术,使用了许多分类器,并对输入图像进行了微小的变换。大多数分类器通常会识别图像真实内容的各个方面,然后将它们汇总在一起。结果是,即使一些分类器被骗了,大多数分类器也不会被欺骗,并且图像将被正确分类。
(王宇飞编译,张梦婷校对)
项目工具
Hub的过去和未来
我维护Hub(命令行git的扩展)已有10年了,现在我想反思过去,分享我的工作流程,并探讨GitHub的未来命令行。
在2010年,Hub1.0位于一个少于500行代码的Ruby文件中。
Hub是一个被GitHub的共同创始人兼首席执行官Chris Wanstrath看好的项目。Hub的最初想法很简单:使用它来包装git,并且Hub将为用户扩展参数,以便用户在使用GitHub时可以减少键入。例如,您可以git clone
由于在Ruby中对新功能进行开发相对容易,因此我开始扩展Hub来包装更多git命令,从而使其能够执行实际上没有人要求的强大功能,例如从GitHub URL中选择性地提交数据。同时,与其它的贡献者一起,我还添加了全新的命令例如create,fork,和pull-request。当时我还没有意识这完全违背了Hub的最初设计,该设计的主要目的是包装现有的git命令,而唯一的“自定义”Hub命令是browse。
同时,Hub最初用作git的包装这一前提,使尝试过该方法的人感到失望,并得出结论,它使git幅值变慢,有时甚至会超过140毫秒。Hub的缓慢性促使Owen Ou(@jingweno)创建了自己的Hub—“gh”,该Hub完全以一种新兴的语言Go编写。
更快的“gh”引起了大家的共鸣。巧合的是,当时有几个GitHubber为Go在内部用于GitHub微服务铺平了道路,他们提出了GitHub采用“gh”作为官方“GitHub CLI”的想法。
当时的情况让我百感交集。尽管Owen的重新实施也给我留下了深刻的印象,但将Hub推到一边,并将一个相对较新的项目推广为“正式”项目的想法并不太使我感到舒服,主要是因为我最初并未加入或咨询这样的计划,也因为我担心实现之间的不兼容性。因此,我与Owen合作了6个月多,在过程中自学了Go,这样我们就可以使新的实现通过整个Hub测试套件。
2014年10月,Owen将自己的工作合并到了主线中,随后删除了旧的Ruby。(事实证明,即使分支具有不相关的历史记录,git也支持合并分支,因此我们能够将两个项目的完整历史记录保留在一个存储库中。)
但是,我们继续将项目称为“hub”,而不是“GitHub CLI”。Hub继续存在于Github组织中,在这里我继续尝试在命令行上使用GitHub API的可能性。
多年来,Hub积累了一系列的疯狂的工具,这些工具在一定程度上达到了实际目的,但大多数目的都是为了满足我对实验的需求。其中一些是:
-
Hub首先通过将其帮助文本转换为Markdown语法,然后将Markdown转换为通常由消耗的“roff”格式来生成自己的手册页。
-
Hub在CI运行期间使用其自己的hub release命令发布其自身的新版本。
-
Hub的大多数测试套件都是使用Cucumber的BDD风格编写的,并且仍然使用Ruby执行。实际上,由于测试套件始终从“外部”作为可执行文件调用Hub并检查其输出/结果,因此当从Ruby迁移到Go时,我们能够保留整个测试套件,这很大程度上使重写成为可能。
-
由于我们测试中心的方式,在测试运行后使用标准Go工具生成代码覆盖率报告对我们而言是不可行的。因此,Hub使用随意组合的变通方法来测量代码覆盖率。
-
为了使其命令行标志解析尽可能接近git,Hub在大约200行代码中实现了自己的POSIX兼容标志解析器。它还通过扫描该命令的帮助文本来定义每个命令支持的标志的列表。
作为我的第一个Go项目,Hub非常凌乱,从“github”包这样的结构的存在可以看出,该包基本上封装了整个代码库的一半。此外,随着Hub以新命令的形式获得更多功能,我意识到我反对Hub最初作为git包装器的前提,因此我停止在文档中建议人们使用alias git=hub。
git使用新功能扩展命令听起来很有趣,但实际上非常难以维护。即使git允许您通过将可执行文件添加到PATH来添加新的自定义命令git-
假设您要实现一个git clone
-
为了独立
/ 参数,您需要准确地解析命令行标志核心的git clone功能。每当您认为已达到平衡时,就会出现新版本的git,它添加了新的标志,您不得不补偿。 -
Core git clone还支持克隆本地目录。如果该
/ 部分也恰好与本地存在的目录匹配,则应扩展为URL还是保持不变? -
在扫描文件系统以解决诸如上一项目之类的情况之前,您需要首先解析,尊重并转发git所有全局标志(例如)的嵌套调用git -C
--work-tree= ...。clone -
如果用户不打算从github.com而是从另一台主机上的GitHub Enterprise实例克隆此存储库,该怎么办?现在,您需要支持选择主机名并维护企业身份验证的不同模式。
-
如果要支持SSH克隆URL,现在还需要从用户~/.ssh/config文件中解析并尊重主机名别名。
-
当您使用新功能/标志扩展git命令时,如何将这些信息添加到git clone -h?请记住,也有man git-clone和git help clone [--web]。
-
当您向git命令添加新标志时,如何确保添加的内容出现在git补全中(包括bash,zsh,fish和其他可能的shell)?
在Hub中,我们已经针对上述各点以及更多内容做出了决策和解决方法,但始终都不够。我们总会错过一些东西;我们尚未考虑的一些极端情况。
在过去的几年中,我不再专注于git扩展,而是指导了项目的方向,使其更多地充当命令行API客户端,重点是促进脚本编写的功能。通过发布此类功能,我能够关闭对Hub的数十个功能请求,这说明用户现在可以编写其工作流程的脚本,而Hub不必实施它们,效果很好。
如果今天我要重新设计hub,那我会做出一套完全不同的决定。
首先,我甚至不再考虑制作git代理。我喜欢git,但是我的时间最好花在做其他事情上,而不是仔细地重新实现git核心功能的某些部分。git已经具有过多的功能,相比于对其进行扩展,我现在知道改善git的方法是围绕它设计更好的抽象。当然,后者要艰苦得多,因为每个抽象都不可避免地无法封装某人的特定流程。通过更好地定义和了解产品的受众群体,可以减轻这种影响。
其次,我将专注于严格维护命令行核心脚本,该核心只提供GitHub API身份验证,编码和将git remotes映射到GitHub存储库的逻辑。所有辅助功能(例如自定义命令)都将建立在此核心之上。此外,任何人都可以滚动自己的命令。用户不需要过多地依靠主线来覆盖他们的用例。
第三,我会选择使用更多社区支持的库和工具来避免维护自己的自定义方法,而不是养活自己的个人“Not Invented Here”综合征。开源项目以不同寻常的方式实现的每个组件都可能成为贡献的障碍,而且我感到Hub很难为之贡献力量,因为许多人都提出要进行修复或实现功能,但实际上很少有人跟进请求。
(王宇飞编译,张梦婷校对)
近期论文
A STUDY OF HUMAN SUMMARIES OF SCIENTIFIC ARTICLES
2020.2.10 by Odellia Boni Guy Feigenblat Doron Cohen Haggai Roitman David Konopnicki
研究背景
近年来,在各种在线资源(例如arXiv.org,Google Scholar)上发表的论文数量激增。在不到十年的时间里,每年向arXiv提交的论文数量几乎翻了一番。为了克服信息过多的问题,一些在线资源,例如paper a day, The morning Paper,现在可以访问由专家和专业人员在各自的博客中撰写的摘要。这样的摘要往往很长,很详细,并且包含原始论文的标题和数据。与各种在线资源中可用的人类撰写的摘要相比,现有的数据集(例如Scisumm,ScisummNet)仅专注于自动生成相对较短的摘要(150-200个单词),它们具有类似抽象的结构,并且缺少标题和图形等人类撰写的摘要的要素。
目的
研究人类撰写的科技论文的摘要,获得其特征以改进现有的自动摘要系统,并使之适应科技论文这一领域
数据集
ShortScience.org的491篇论文的561篇摘要。ShortScience是一个开放平台,用于发布计算机科学(CS),物理和生物学领域的科技论文摘要。
发现
在摘要主观性方面,该论文探索了人类摘要者表达意见的方式。53%的摘要被标记为中性,32%被标记为正极,15%被标记为负极。即当人们决定公开表达对科学工作的看法时,他们倾向于表现出积极或平衡的观点,而不是批评。这也可以表明人们会选择总结他们认为有价值的论文。
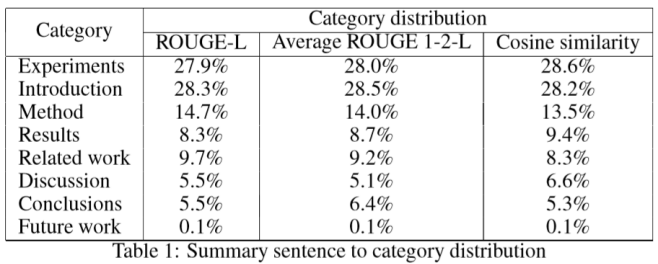
在摘要范围方面,文章将论文和摘要分为9个部分:简介,相关工作,方法,结果,实验,讨论,结论,未来工作和未知。如表中所示,当使用不同的相似性方法时,各类别权重相当稳定,即一种汇总算法可以旨在将更多的焦点分配给更显著的部分。
在摘要样式方面,该研究发现,大约31%的摘要至少包含一个图。同样,在科技论文中,图也被广泛用于说明流程、举例和报告结果。这意味着自动生成摘要时需要考虑多模式摘要(multi-modal summarization),但目前还没有研究涉及此方面。
(王宇飞编译,张梦婷校对)
近期会议
iConference 2020:International Conference on Learning Representations
March 23-March 26, 2020 瑞典 布洛斯
iConference由iSchools联盟举办,致力于通过跨学科交流不断扩展信息科学的研究视野和丰富信息科学的内涵。自2005年首次举办以来,iConference已持续15届,成为信息领域学者、研究人员和专业人士分享当代社会关键信息问题见解的广阔平台。其主要特征是对信息科学的新思想和研究领域的开放。会议旨在推动突破信息研究的界限,探索核心概念和理念,并创建新的技术和概念。
ICLR 2020: International Conference on Learning Representations
Apr 26 - Apr 30 ,2020 埃塞俄比亚 亚的斯亚贝巴
ICLR是每年春季举行的机器学习会议。自2013年成立以来,ICLR就采用了公开的同行评审程序来提交裁判论文(基于Yann LeCun提出的模型)。 2019年,有1591篇论文提交,其中500篇接受海报展示(31%),24篇接受口头演讲
JCDL 2020: Joint Conference on Digital Libraries
June 19 - June 23 ,2020 陕西 西安
数字图书馆联合会议(JCDL)是一个重点讨论数字图书馆及其相关的技术实践以及社会问题的国际论坛。JCDL通过将ACM数字图书馆会议和IEEE-CS数字图书馆会议的进展结合起来,加强了ACM和IEEE-CS已经建立的会议卓越的传统。在本次会议上,JCDL向在该领域做出杰出贡献的人士颁发Vannevar Bush最佳论文奖、最佳学生论文奖、最佳国际论文奖、最佳海报奖。该会议邀请国家和国际社会就数字图书馆感兴趣的广泛主题发表论文。
ASIS&T 2020: Association for Information Science & Technolog
October 23-October 28,2020 美国 匹兹堡
ASIS&T成立于1937年,是目前图书馆情报学、信息技术、信息管理等领域最具学术影响力的国际学术组织之一。学会下设17个特别兴趣小组、14个区域分会和39个学生分会,其会员遍布全球50多个国家和地区,出版有JASIST、Bulletin of the ASIS&T等专业刊物,每年举办年度大会及相关主题峰会。