文本挖掘与机器学习跟踪扫描动态快报(2020.11)
实时跟踪、关注文本挖掘与机器学习领域最新研究动态
深度观察
文本摘要方法简要概述
引言
自动文本摘要或者文本摘要是创建较长文档的简短且连贯版本的过程。文本摘要是从一个(或多个源)提取最重要信息以为特定用户(或多个用户)和任务(或多个任务)生成精简版本的过程。
我们通常擅长此类任务,因为它涉及到首先理解源文档的含义,然后提取含义并在新描述中捕获重要细节。因此,自动创建文本摘要的目标是使最终的摘要与人类编写的摘要一样好。
仅生成涵盖源文档要旨的单词和短语是不够的。摘要不仅要是准确的,并且能作为新的独立文档被流利地阅读。自动文本摘要任务是在保持关键信息内容和整体含义的同时,生成简洁流畅的摘要。
鉴于语音识别导致的错误以及口语通常不如书面语那么正式的事实,单文档文本摘要中使用最广泛的方法句子抽取无法直接应用于语音摘要。但如果系统利用了可以从语音信号和对话结构中获取的附加信息,则提取方法可以扩展到口语,并可以通过新的方法加以扩充,例如专注于提取特定种类的信息并适当地对其进行重新表述的方法。
文本摘要的种类
有两种类型的摘要技术:抽取式文本摘要和生成式文本摘要。抽取式文本摘要的运行机理是从文本中识别出重要的句子或摘录,并逐字复制它们作为摘要的一部分。没有新的文本生成;摘要过程中仅使用现有文本。这不同于生成式文本摘要,后者采用更强大的自然语言处理技术来理解文本并生成新的摘要文本。
下面列出的三个独立任务大体上总结了所有任务。在本文中,我们将介绍不同生成式主题的表示方法。
1.主题词
该方法旨在识别描述输入文档主题的单词。有两种方法可以计算句子的重要性:
句子中包含主题词的数量或者所占的比例的函数。这两个句子评分函数都涉及相同的主题表示。但是,他们可能为同一句子打不同的分数。第一种方法可能给更长的句子打更高的分数,因为它们具有更多的单词。第二种方法衡量的是主题词的密度。
2.频率驱动的方法
在主题表示中分配单词权重时,我们可以考虑二进制(0或1)或实值(连续)权重,并确定哪些单词与主题更相关。此类别中最常见的两种技术是单词概率和TF-IDF。
2.1词频:
单词ω的频率为单词出现的次数f(ω)除以输入中所有单词的数量N(可以是单个文档或多个文档):
P(ω)=f(ω)/N
然后选择包含最高频率单词的最佳评分句子。此步骤确保摘要中包含表示该时刻文档主题的最高频单词。这些选择步骤将重复进行,直到达到所需的长度摘要。
2.2 TF-IDF:
这种加权技术通过对大多数文档中出现的单词给予低权重,来评估单词的重要性并识别文档中非常常见的单词(应忽略不计)。文档d中每个单词ω的权重计算如下:
q(ω)=fd(ω)*log(|D|/fD(ω))
其中fd(ω)是文档d中单词ω的词频,fD(ω)是包含单词ω的文档数,|D|是集合D中的文档数。
3.潜在语义分析
此方法首先构建词-句子矩阵(term-sentence matrix)(n×m矩阵),每行对应于输入中的一个单词(n个单词),每列对应于一个句子(m个句子)。 矩阵的每个元素aij是句子j中单词i的权重。单词的权重通过TF-IDF技术计算,如果句子中没有单词,则该单词在句子中的权重为零。然后在矩阵上使用奇异值分解(SVD),将矩阵转换为三个矩阵U,S&V。
最初的方法是每个主题选择一个句子。因此,他们根据句子的摘要长度保留主题的数量。这种策略有一个缺点,因为一个主题可能需要多个句子来传达其信息。后来对其进行了增强,以利用每个主题的权重来确定应涵盖该主题的摘要的相对大小,从而增大可变数量句子的灵活性。
4.贝叶斯主题模型
上述方法的两个主要局限是:
1)它们认为句子彼此独立,因此忽略了嵌入在文档中的主题。
2)大多数现有方法计算的句子分数通常没有明确的概率解释,许多句子分数是使用启发式方法计算的。
贝叶斯主题模型是揭示和表示文档主题的概率模型。它们非常强大且具有吸引力,因为它们代表了在其他方法中丢失的信息(即主题)。它们在详细描述和表示主题方面的优势使开发汇总系统成为可能,该系统可以确定摘要中要使用的文档之间的相似性和差异。
5.结论
本文受到Summarization Techniques: A Brief Survey一文的启发,并基于该论文详细介绍了不同的抽取式文本摘要技术。与抽取式摘要相比,生成式摘要仍处于起步阶段,并且没有明确的机制来衡量性能。但是它具有巨大的潜力,我们在未来的日子里肯定会看到一些突破。
(张梦婷编译,赵海喻校对)
研究动态
Google,海德堡大学和NEC建议利用人为反馈来促进NLP中的离线强化学习
Google, Heidelberg University & NEC Propose Human Feedback for Real-World RL in NLP Systems
一项新的研究建议使用人为反馈和交互日志来促进自然语言处理(NLP)中的离线强化学习(RL)。尽管人们通常倾向于批评或抱怨,但到目前为止,他们应用于ML中实用的反馈只限于错误报告(error reporting)。 在Learning from Human Feedback: Challenges for Real-World Reinforcement Learning in NLP一文中,来自谷歌研究所、海德堡大学和欧洲NEC实验室的团队探索隐藏在反馈和交互日志信息中的“金矿”及其在用户交互RL和NLP系统的潜力。
研究人员指出,在NLP的实际应用中往往会收集包含用户评分、点击或修改的大量交互日志,但这些日志往往仅出于评估目的。

研究人员指出,直接在线更新模型太“冒险”,特别是在商业环境中或获得不适当甚至有害于训练的反馈时。离线RL可以通过在现有交互日志数据上对RL代理进行预训练,而无需与环境进行任何进一步的交互。
研究人员专注于NLP应用的序列到序列(Seq2Seq)学习,例如机器翻译,文本摘要,语义解析和对话生成,因为这些可以包括与用户的丰富交互。
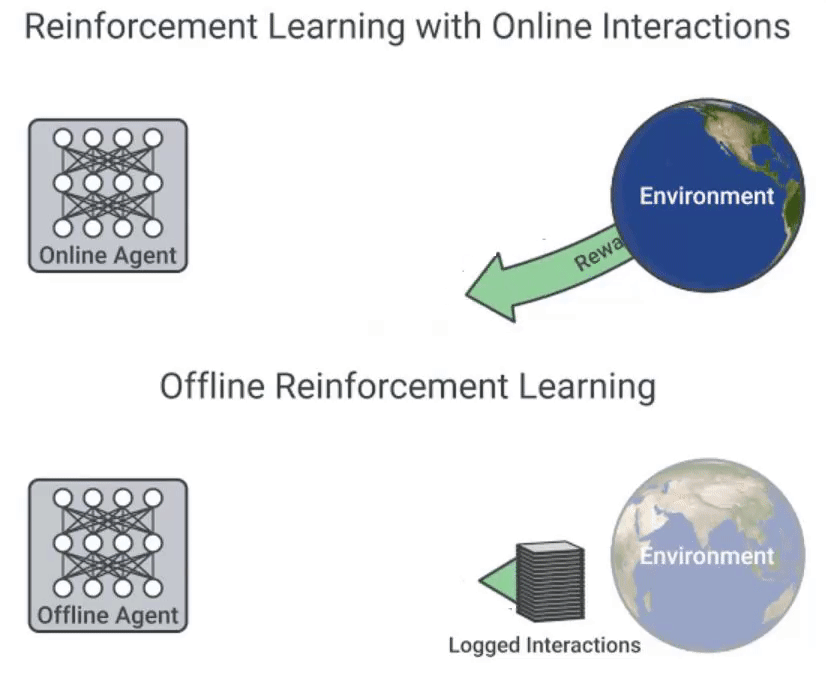
该团队确定了NLP中RL的三个主要挑战:
对于RL方法来说,探索输出空间是至关重要的——在Seq2Seq的情况下,输出空间特别大。虽然一个输出句子可能只包含100个单词,但这些单词可能来自30000个词汇集。正如海德堡大学统计自然语言处理小组在推特上所说,这产生了30000^100个可能的输出。
在现实世界的商业系统中,有效的探索尤其重要,因为低性能将为用户提供劣质的输出。研究人员建议对可用的监督数据进行RL策略的预训练,使模型能够集中在输出空间中的合理区域。
NLP应用程序的另一个相关约束是确定性日志记录策略。生产型NLP系统向用户提供最可能的输出并避免显示劣等选项,这导致确定性日志记录策略缺乏明确的探索,并且可能使收集的数据集偏向于日志记录策略选择。一旦NLP系统开始运行,就很难纠正这种偏差。该团队提出了应对这一挑战的两种方法:
1)由于输入或上下文变化而导致的隐式探索
2)从记录的数据估算中考虑退化行为的具体情况
该团队强调,即使系统可以从人为反馈中学习,但并非所有人为反馈都具有同等价值甚至有益。例如,从用户与聊天机器人的交互中获得“强盗反馈(bandit feedback)”以外的其他期望是不合理的,因为聊天机器人只为所呈现的一个输出提供奖励信号,而无法评估针对同一输入的多个输出。在这种情况下,反馈相对于输出空间的大小非常稀疏。收集反馈的方法也很重要,因为这会影响可靠性和学习近似人类奖励的奖励估算器(reward estimators)的能力,并且可以集成到NLP应用程序的端到端RL任务中。
该团队建议,由于反馈收集的界面会影响RL代理学习的奖励功能,因此研究人员应研究现实环境中的用户界面和体验,特别是对于代理与自然语言交互的下游任务。他们认为专注于此类系统可以帮助NLP研究人员在实际生产环境中检查离线RL,并鼓励开发创新算法来应对NLP应用中的挑战。
(张梦婷编译,赵海喻校对)
Amazon Alexa AI的“Language Model Is All You Need”将NLU作为探索对象
Amazon Alexa AI’s ‘Language Model Is All You Need’ Explores NLU as QA
Amazon Alexa AI的最新研究认为当前的自然语言理解方法与人类理解语言的方式相去甚远,并询问是否所有的NLU问题都可以通过转移学习有效地映射到问答(QA)问题上。
迁移学习是一种将从源域学习到的知识应用到目标域的ML方法。它在自然语言处理领域取得了很好的效果,特别是在将学习从高数据域迁移到低数据域时。亚马逊的研究人员专注于一种特定类型的迁移学习,即首先将目标域映射到源域。
自然语言理解是自然语言话语中决定意图、时隙或实体价值的工具。提出的“QANLU”方法基于NLU注释数据构建时隙和意图检测问题和答案。QA模型首先在QA语料库上进行训练,然后根据NLU标注的数据对问题和答案进行微调。通过迁移学习,这种上下文问答知识被用来寻找文本输入中的意图或时隙值。
与以前的方法不同,QANLU专注于低资源应用,不需要设计和训练新的模型架构或进行大量的数据预处理。这使它能够以较少的数据量级在时隙和意图检测中获得出色的结果。
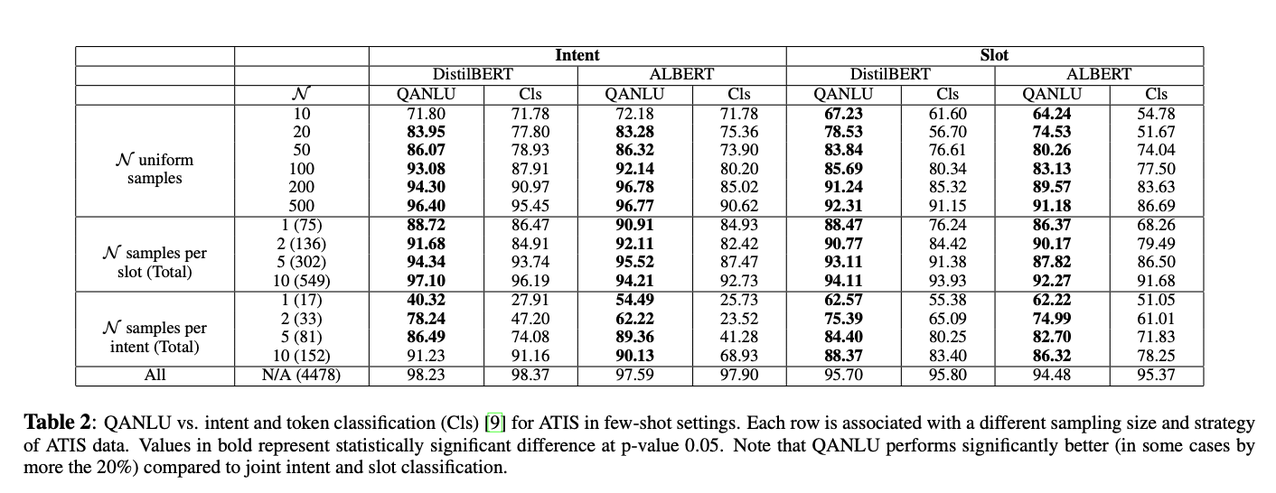
研究人员在ATIS和Restaurants-8k数据集上进行了实验,QANLU在低数据环境和few-shot设置下明显优于句子分类和token标记方法来进行意图和时隙检测任务,同时还改善了新的IC / SF few-shot方法在NLU中的表现。
研究人员说未来的方向可能包括扩展此配置并解决不同的NLP问题,衡量不同NLP任务之间的知识迁移以及研究如何根据上下文自动生成QANLU问题。
(赵海喻编译,周子喻校对)
麦吉尔大学,Facebook和蒙特利尔学习算法研究所发布了用于医学缩写消歧的14M NLP预训练数据集
在上周的EMNLP 2020临床医学NLP workshop上,一个蒙特利尔的研究团队介绍了一个大型医学文本数据集,该数据集旨在促进医学领域的缩写消歧。
在医学和卫生保健领域,正确的术语最为关键,文本挖掘和自然语言处理可以为诊断、预测和其他任务构建深度学习模型。不幸的是,由于隐私限制,这一领域的研究和临床应用一直缺乏公开的预训练数据,以及可用数据中大量的非标准缩写。今年早些时候,患者安全组织安全医疗实践研究所列出了不少于55,000个医学缩写,这些缩写可能“无法明确表达其本意,并对患者的健康构成潜在危险”。
来自麦吉尔大学、Facebook CIFAR AI主席和蒙特利尔-魁北克人工智能研究所的研究人员介绍了用于自然语言理解的缩写消歧医学数据集(MeDAL),以整理出所有矛盾的、模棱两可的和有潜在危险的缩写。

MeDAL是由PubMed(文献服务检索系统)在2019年年度baseline中发布的摘要创建的,它是一个大型医学文本数据集,用于医学缩写消歧任务,可用于预训练自然语言理解模型。数据集包含14393619篇文章,平均每篇文章有三个缩写。研究人员说,在对下游医疗任务进行微调时,MeDAL的预先训练可以提高模型的性能和收敛速度。
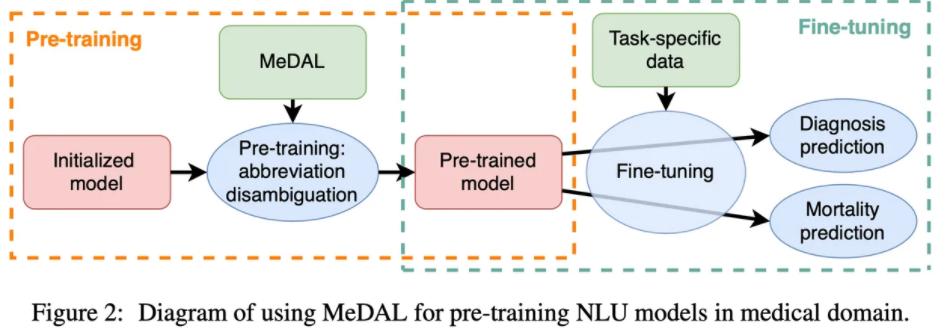
与现有的医学缩写消歧方法侧重于提高缩写消歧性能不同,该方法将缩写消歧作为迁移学习其他临床任务的预训练任务。该团队建立了一个足够大的数据集来进行有效的预训练,因为现有的医学缩写消歧数据集与用于一般语言模型预训练的数据集相比非常小。
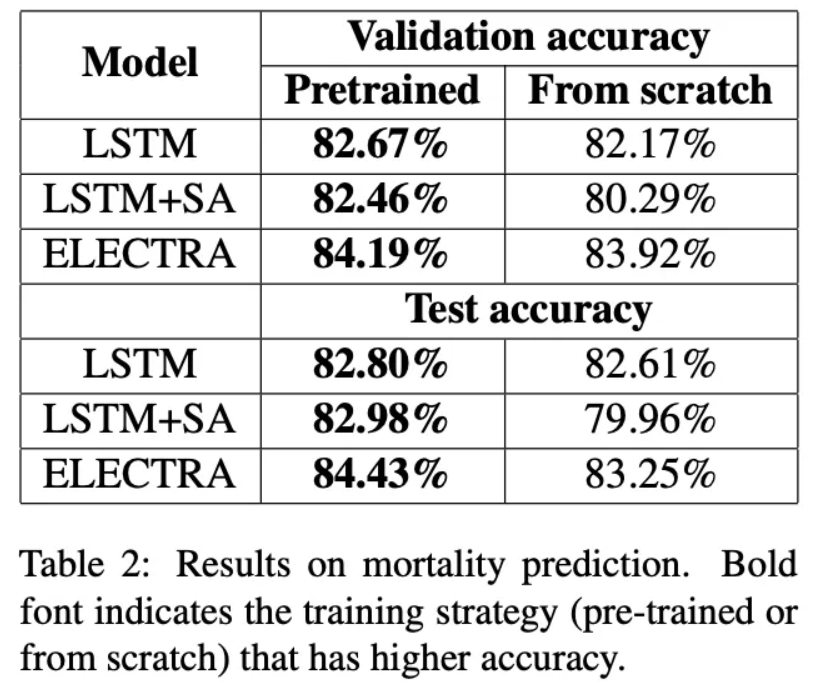
该团队使用LSTM、LSTM +自注意力和transformer模型对死亡率预测和诊断预测等任务进行了评估。在死亡率预测任务中,所有三个预先训练过的模型都比刚建立的模型表现得更好。在诊断预测任务中,LSTM和LSTM +自注意力都提高了70%以上。
结果表明,在医学领域对MeDAL数据集进行预训练可以普遍提高模型的语言理解能力。
(赵海喻编译,周子喻校对)
这可能会引领常识AI领域的下一个重大突破
This could lead to the next big breakthrough in common sense AI
最近来自北加利福尼亚大学的研究者Chapel Hill设计了一个新的技术叫做 vokenization, 该技术赋予了诸如 GPT-3 这样的模型“看”的能力。
这并非人类第一次尝试将语言模型和计算机视觉相结合,实际上这是一个快速发展的AI领域。产生这种想法是因为两种类型的AI都有不同的优势。像 GPT-3 这样的语言模型是通过无监督学习进行训练的,该过程不需要手动标记数据,因此易于扩展。相比之下,像目标识别系统这样的图像模型可以直接从现实中学习到更多。换句话说,他们学到的东西并不依赖于文本所提供的内容。
可以同时解析语言和视觉输入的 AI 模型也有非常实际的用途。例如,如果我们要构建机器人助手,则他们需要计算机视觉来在世界中进行导航,需要语言来与人类进行交流。但是,将两种类型的 AI 结合起来说起来容易做起来难。这并非简单地将现有语言模型与现有目标识别系统装订在一起。它需要使用包含文本和图像的数据集从头开始训练新模型,该数据集也称为视觉-语言数据集。
获得此类数据集的最常用方法是收集带有描述性标题的图像集合。例如,下面的图片的标题为“一只橘猫坐在准备打包的手提箱里。”这与典型的图像数据集不同,后者仅用一个名词来标记下面的图片,例如“猫”。因此,一种视觉语言数据集不仅可以教一个AI模型如何识别目标,而且还能使用动词和介词来告诉模型目标之间是如何相互影响和相互作用的。
但是制作这种数据集非常耗时,这就是为什么现有的视觉-语言数据集如此之小。一个常用的纯文本数据集,如英文 Wikipedia(实际上几乎包括所有英语 Wikipedia 条目),可能包含近30亿个单词,但像MS COCO这样的视觉-语言数据集仅包含700万数据。根本没有足够的数据来训练AI模型以提供有用的信息。
“Vokenization”解决了这个问题,它使用无监督学习方法将MS COCO中的少量数据缩放到英文Wikipedia的大小。在当今用于评估 AI 语言理解力最困难的测试中,经过该训练集训练的视觉语言模型优于目前最好的模型。
自然语言处理初创公司HuggingFace的联合创始人兼首席科学官托马斯・沃尔夫(Thomas Wolf)表示:“只进行了一点点变动,就在这些困难的测试上超过最先进的水平。这就是为什么这令人如此兴奋。”
从token到voken
首先让我们理清这些术语,究竟什么是 voken?
在 AI 语言中,用于训练语言模型的单词称为token。因此,UNC 研究人员决定将视觉语言模型中每个token和相关联的图像称为“voken”。为每个 token 查找 voken 的算法叫 Vokenizer,整个过程称为 vokenization。
这有助于理解 vokenization 背后的基本思想。UNC 研究人员不是从图像数据集开始并手动写句子作为标题(这是一个非常缓慢的过程),而是从语言数据集开始,并使用无监督学习来将每个单词与相关图像进行匹配(稍后会详细介绍)。这是一个高度可扩展的过程。因此无监督学习技术才是本论文最大的贡献,即如何为每个单词找到相关图像。
Vokenization
GPT-3是Transformer语言模型家族的一员,2017年Transformer的出现带来了重大的突破,因为其将无监督学习应用到自然语言处理上。Transformer通过观察词在上下文中的用法来学习人类语言的模式,然后根据该上下文为每个词创建数学表示,称为“词嵌入”。
有一种并行技术也可以用于图像。它不通过扫描文本来查找单词使用模式,而是扫描图像以查找视觉模式。
UNC研究人员的想法是,他们应该在MS COCO上同时使用两种嵌入技术。他们将图像转换为视觉嵌入,将标题转换为词嵌入。这些嵌入的真正精巧之处在于可以将它们嵌入三维空间中,并直接看到它们之间的关系。与词嵌入紧密相关的视觉嵌入会在图中显示得更近。
一旦将所有嵌入进行图形化表示并与其他嵌入进行比较和关联,就可以轻松地将图像(vokens)与单词(tokens)进行匹配。由于图像和单词是根据其嵌入进行匹配的,因此在上下文中他们也是匹配的。该技术通过为词的每个实例找到不同的voken来成功地解决这一问题。
研究人员使用 MS COCO 创建的视觉和词嵌入来训练其 vokenizer 算法。训练完成后,vokenizer 便可以在英语维基百科中为每个 token 找到对应的 voken。这不是完美的。该算法仅为大约 40%的 token 找到了 voken。但这已经是拥有近 30 亿个字数据集的 40%了。
利用这个新的数据集,研究人员重新训练了 BERT 的语言模型,BERT 是 Google 早于 GPT-3 开发的一种开源 Transformer。然后,他们在六种不同的语言理解测试中测试了新改进的 BERT。
博士研究生 Hao Tan 和他的导师 MohitBansal 将在 EMNLP 会议上介绍其新的 vokenization 技术。尽管这项工作还处于初期阶段,但 Wolf 认为他们的工作是使无监督学习适用于视觉语言模型的一项重要的概念突破。这有助于大大推动自然语言处理的发展。
(周子喻编译,张梦婷校对)
项目工具
用于自然语言处理的深度学习pipeline
在本文中,我将探索自然语言处理的基础知识,并演示如何实现一个pipeline,将传统的无监督学习算法与深度学习算法结合起来,以训练无标记的大型文本数据。因此,本文旨在演示如何建立pipeline,以方便原始文本数据的收集和创建,预处理和分类未标记的文本数据,最终在Keras中训练和评估深度学习模型。
阅读本教程后,您将能够执行以下操作:
1.如何通过Twitter API和Tweepy Python包从Twitter收集数据
2.如何使用pandas包有效地读取和清理大型文本数据集
3.如何使用基本的NLP技术对文本数据进行预处理并生成特征
4.如何分类未标记文本数据
5.如何在Keras中培训、编译、适应和评估深度学习模型
在进行这个项目的时候,美国2020年大选即将来临,对与即将到来的选举相关的推文进行情绪分析,了解在选举日前大约2周在Twitter世界中讨论的观点和话题是很有意义的。与我们从主要媒体看到的典型过滤新闻相比,Twitter 是未经过滤意见的一个很好的来源。因此,我们将通过使用 Twitter API 和 python 包 Tweepy 从 Twitter 收集推文来构建我们自己的数据集。
第一步:数据收集
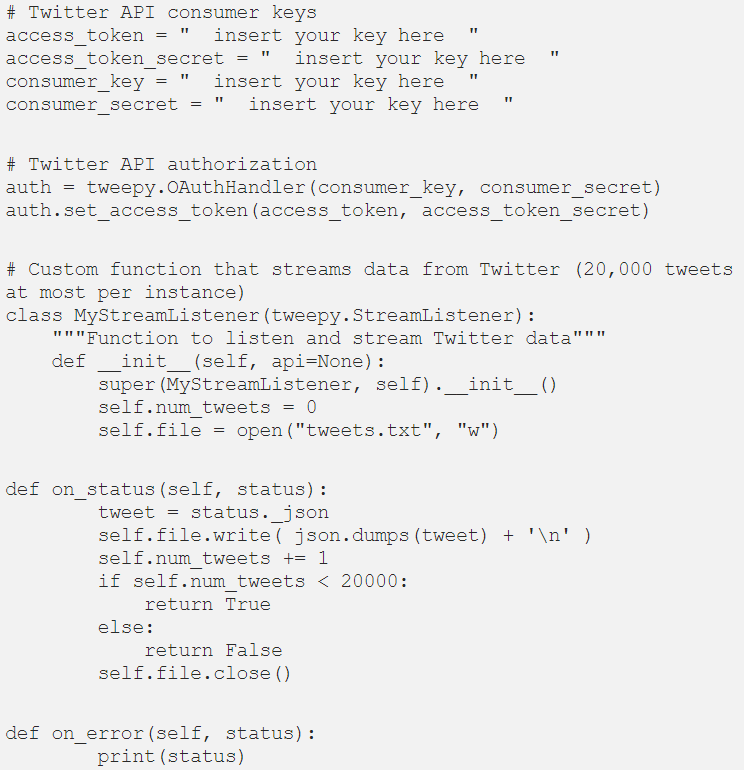
在开始使用Twitter流数据之前,您必须具备以下条件:
1.Twitter帐户和Twitter API用户密钥(access token key, access token secret key, consumer key and consumer secret key)
2.Tweepy包安装在你的Jupyter notebook
Tweepy可以通过pip安装在Jupyter notebook上,下面一行代码就可以做到。

安装后,继续将包导入notebook。
设置数据流pipeline
在本节中,我将向您展示如何使用 Twitter API、Tweepy 和自定义函数设置数据流pipeline。我们可以通过 3 个步骤实现此目的:
1.设置您的推特 API用户密钥
2.设置 Twitter API 授权处理程序
3.编写侦听和流式传输实时推文的自定义函数
开始流式传输实时推文
现在,环境已经设置,您已经准备好开始从 Twitter 流式传输实时推文了。在这样做之前,请确定一些关键字,用于收集您感兴趣的相关推文。由于我将流式传输有关美国大选的推文,我选择了一些相关的关键字,如 "美国大选", "Trump", "Biden" 等。
我们的目标是收集至少400000条推文,使其成为足够大的文本数据,而且一次性收集所有这些信息的计算量非常大。因此,我将设置一个pipeline,以便有效地以区块的方式传输数据。从上面的自定义函数中可以注意到,它在每个区块将侦听和流传输最多 20000 条推文。因此,为了收集超过 400000 条推文,我们需要运行至少 20 个区块。
下面是如何寻找数据块,侦听并将实时推文流传输到pandas的DataFrame中的代码:
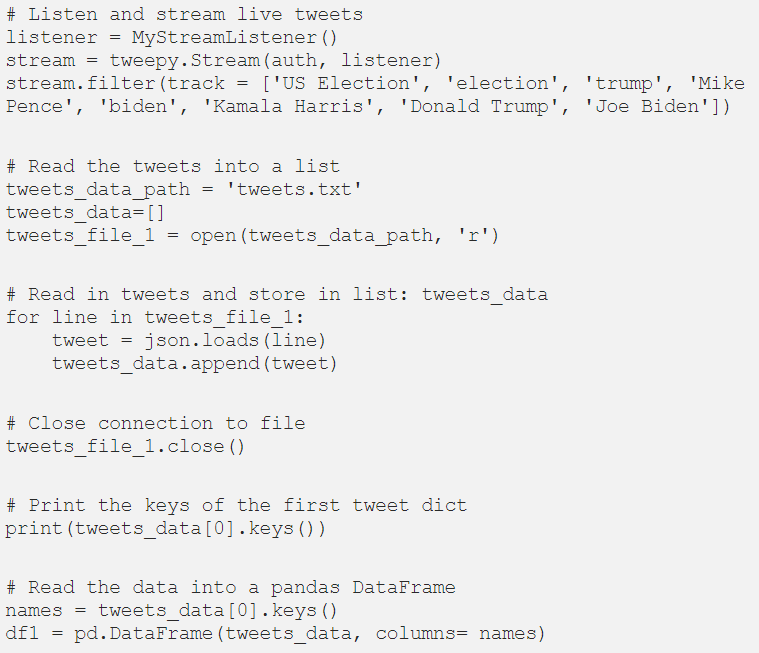
如前所述,为了收集400000条推文,您将必须至少运行上述代码20次,并将收集到推文保存在单独的pandas Dataframe中,该Dataframe稍后将被连接起来,以将所有推文合并到一个数据集中。
将所有的数据块合并成一个数据集

现在您已经将组合的数据集导出到CSV文件中,您可以使用它来进行下一步的清理和可视化数据。
我已经公开了我创建的数据集,它在Kaggle公开可用。
第二步:数据整理
在本节中,我们将清理刚刚收集的数据。在可视化数据之前,必须清理数据集并将其转换为可有效可视化的格式。对于具有440000行的数据集,必须找到一种有效的方法来读取和清理它。要做到这一点,pandas chunksize属性可以用来从CSV文件中读取数据到一个pandas dataframe中的块。此外,我们可以指定我们感兴趣的列的名称来读取,而不是读取包含所有列的数据集。通过使用块大小和更少的感兴趣的列,可以非常高效和快速地将大型数据集读入数据格式中,而不需要使用其他替代方法,比如在集群上使用PySpark进行分布式计算。
要将数据集转换为可视化所需的形状,将应用以下基本的NLP技术:
1.只提取英文推文
2.如果有的话,删除重复
3.如果有丢失的值,则删除
4.Tokenize(将推文分成单个单词)
5.将单词转换为小写字母
6.删除标点符号
7.删除stopwords
8.删除url、“twitter”和其他首字母缩写词
执行上述步骤的方法如下:
1.编写一个自定义函数来tokenize推文。
2.编写另一个自定义函数,对数据应用上述所有清理步骤。
3.最后,以区块的形式读取数据,并在读取数据块时通过自定义函数将这些整理步骤应用到每个数据块。
让我们看看它们的实际操作……
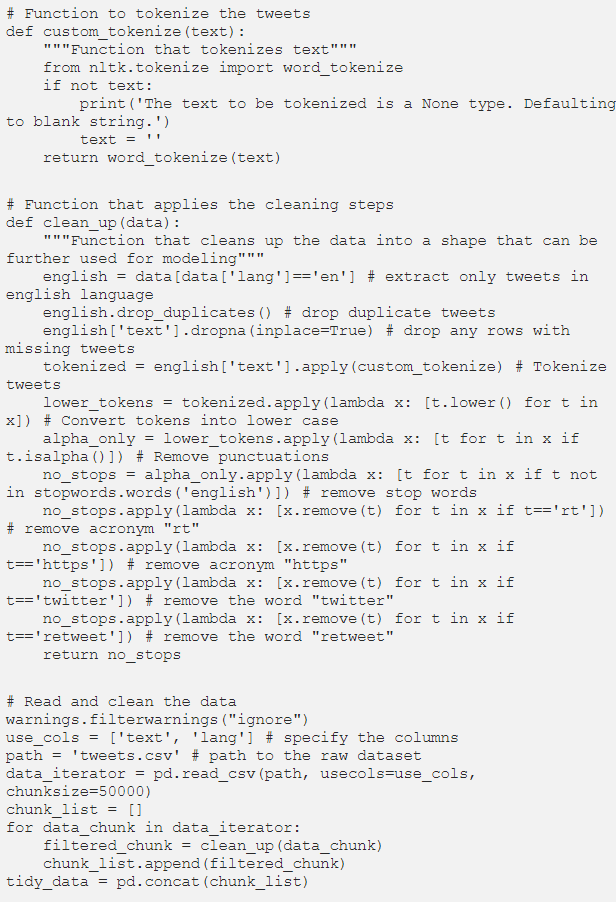
chunksize这里被设置为50000,这就是pandas在每个块中读取50000条推文,并在读取下一批之前对它们应用清理步骤,以此类推。
在此过程之后,数据集将被清理并准备好进行可视化。为了避免每次打开笔记本时都要执行数据整理步骤,您可以简单地将整洁的数据导出到一个外部文件中,并在将来使用该文件。对于大型数据集,将它们导出到JSON文件比导出到CSV文件更有效。

以下是整洁数据的外观:

第三步:探索性数据分析(可视化)
现在数据已经清晰了,让我们可视化并理解数据的本质。我们可以看的一些显而易见的事情如下:
1.每条推文的字数
2.推文的平均长度
3.频率最高的单词,二元词组和三元词组
4.词云图
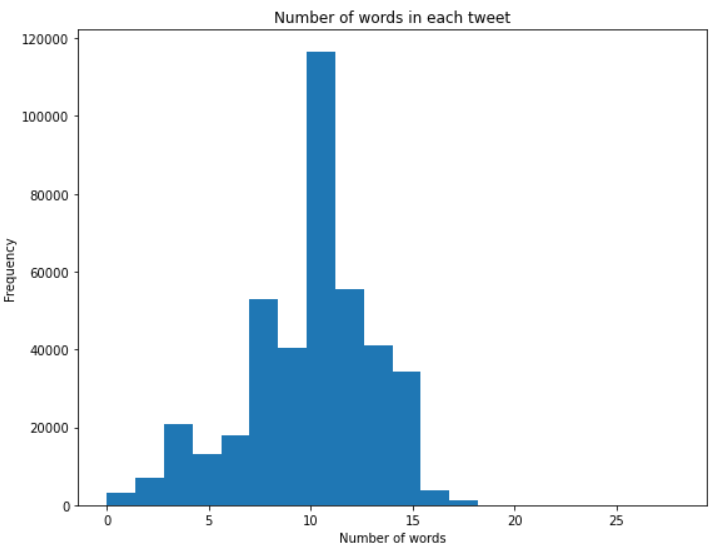
看来每个推文的单词数范围从 1 到 19 个单词,平均在 10 到 12 个单词之间。
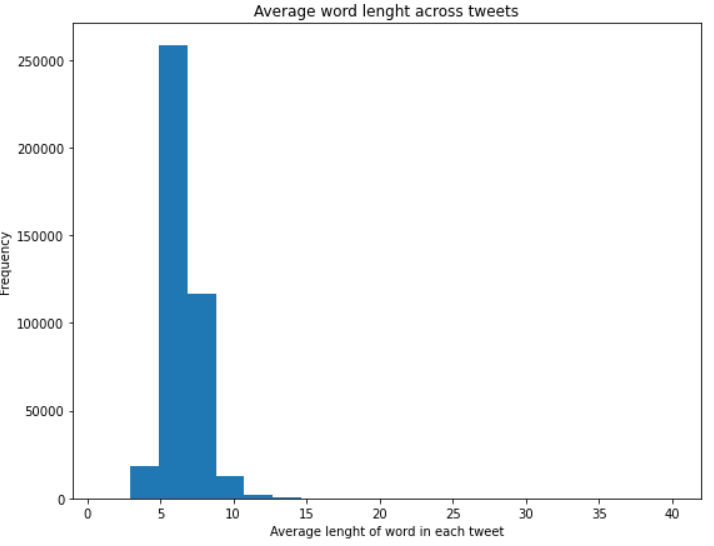
推特上一个单词的平均字符数似乎在3到14个字符之间,平均出现在5到7个字符之间。人们可能选择简短的词语来表达他们的意见,在Twitter设定的280个字符的限制范围内,他们可以以最好的方式表达他们的意见。
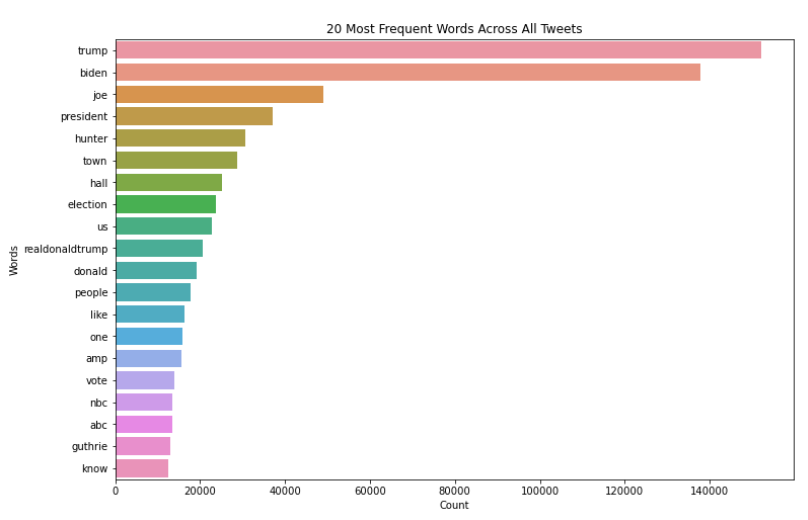
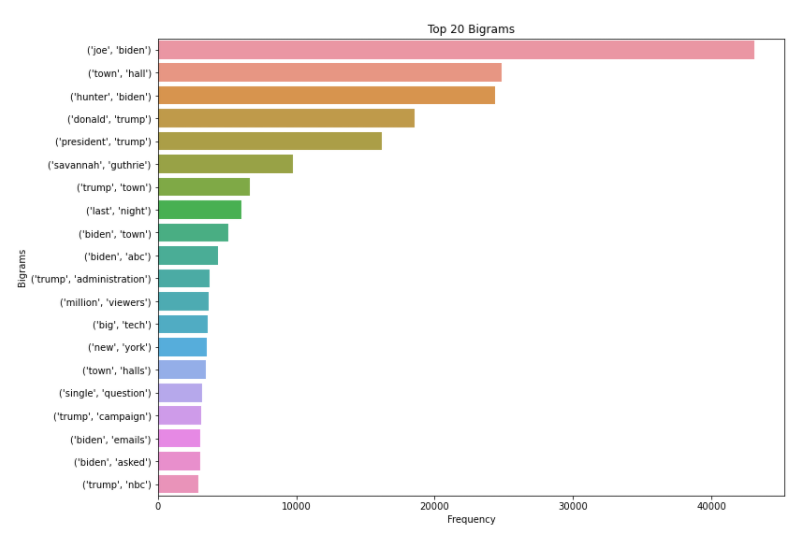
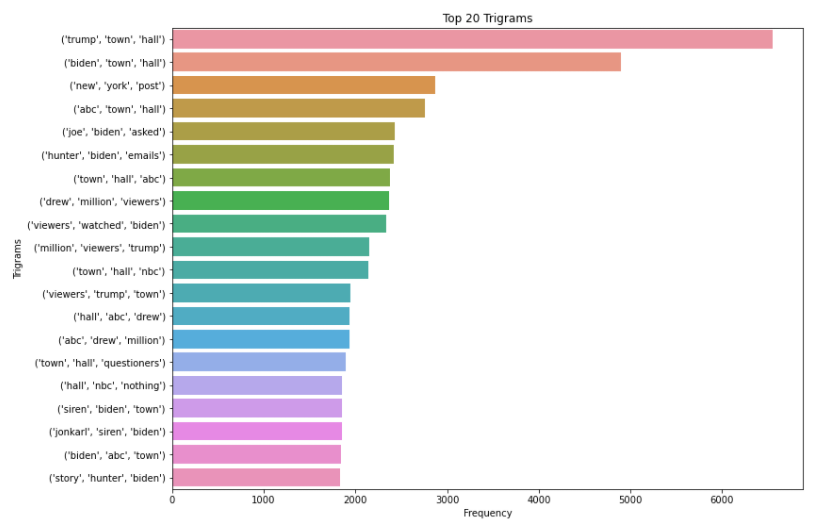
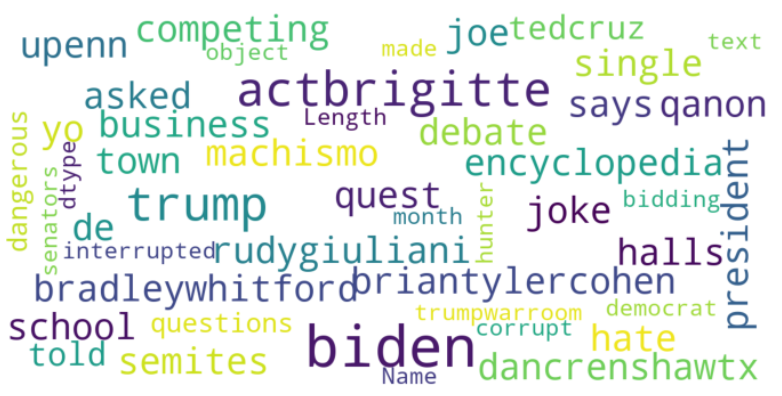
从可视化数据来看,请注意单词并没有被词元化。词元化(Lemmatization)是将单词转化为词根或字典形式的过程。它是自然语言处理和机器学习中常用的一种技术。因此,在下一步中,我们将用下面的代码对记号进行词元化。
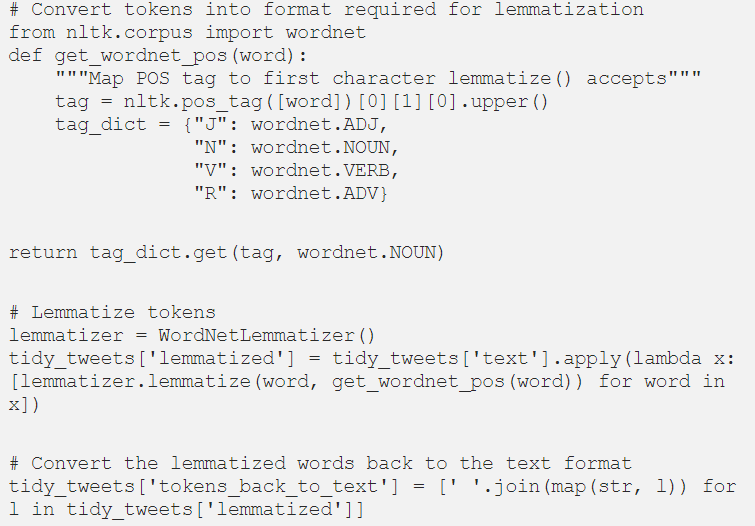
现在,让我们将词元化token保存到另一个JSON文件中,以便于在pipeline中的下一步中使用。

在进行预处理和建模步骤之前,让我们回顾我们的方法,以便进行下一步。在我们预测推文属于哪个类别之前,我们必须首先用类别来标记原始推文。请记住,我们将我们的数据作为Twitter原始推文传输,因此数据没有标签。因此,宜采用以下方法:
1.用k-means聚类算法标记数据集
2.训练深度学习模型来预测推文的类别
3.评估模型并确定有效性
第四步:标记未标记的文本数据并进行预处理
在本节中,目标是用对应于积极或消极情绪的两种标签来标记这些推文,然后进一步预处理并将标记的文本数据转换为一种可以进一步用于训练深度学习模型的格式。
有许多不同的方法来分类未标记的文本数据,这些方法包括但不限于SVM、分层聚类、余弦相似性,甚至Amazon Mechanical Turk服务(通过人工)。在此示例中,我将向您展示另一种更简单的方法,也许不是最准确的方法,对文本数据进行快速而粗糙的分类。为此,我首先用 VADER 进行情绪分析,以确定推文是正面的、负面的还是中性的。接下来,我将使用简单的 k-means 聚类算法,根据从推文的正、负和中性值得出的计算复合值对推文进行聚类。
创建情绪
让我们先看看数据集:

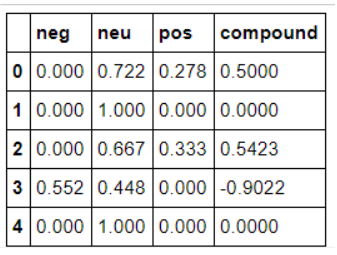
列"tokens_back_to_text"是转换回文本格式的词元化标记,我将使用 VADER 包中的SentimentIntensityAnalyzer使用此列从整洁的数据集创建情绪。

前五行的情绪数据长这样:
对未标记数据进行k-means聚类标注
现在,我将使用上述dataframe中的“复合”列,并将其输入k-means聚类算法,分别用0或1表示“消极”或“积极”情绪对推文进行分类。也就是说,我会将对应的大于等于0.05的复合值标记为积极情绪,小于0.05的复合值标记为消极情绪。这里没有什么硬性规定,这就是我的实验设置。
下面是如何使用来自scikit-learn的k-means聚类算法在python中实现文本标记作业。记住要给标签和你的推文/文本的原始数据提供相同的索引。

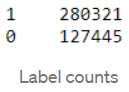
查看0和1的标签计数,注意到数据集是不平衡的,其中被标记为1的推文超过两倍。这将影响模型的性能,因此我们必须在训练模型之前平衡我们的数据集。
此外,我们还可以通过一种名为“潜狄利克雷分配”(LDA)的强大的NLP算法从每个类别中识别出推文的主题,该算法可以提供对正面和负面推文主题的直觉。稍后我将在另一篇文章中展示这一点。现在,为了这个练习,我们使用0和1这两个类别。现在,我们已经成功地将我们的问题转化为一个监督学习问题,接下来我们将继续使用我们现在标记的文本数据来训练深度学习模型。
第五步:建模
我们有一个相当大的数据集,其中包含超过40万条推文和60000多个不同单词。在如此大的数据集上训练具有多个隐藏层的RNN会增加计算负担,如果尝试在CPU上训练它们,则可能需要几天(或者几周)的时间。训练深度学习模型的一种常见方法是使用GPU优化的机器以获得更高的训练性能。在本练习中,我们将使用预装有TensorFlow后端和CUDA的Amazon SageMaker p2.xlarge。我们将使用Keras接口连接TensorFlow。
训练步骤:
1.对数据集进行标记,填充和排序
2.用SMOTE平衡数据集
3.将数据集分为训练集和测试集
4.训练SimpleRNN和LSTM模型
5.评估模型
由于机器学习算法无法理解自然语言,因此必须将数据集转换为数字格式。在向量化数据之前,让我们看一下数据的文本格式。


对数据集进行标记,填充和排序

使用SMOTE平衡不平衡数据

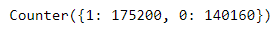
从上方的0到1之间的数据分布可以看出,与以前相比,现在的数据看起来非常平衡。
将数据分为训练集和测试集
现在数据已经平衡,我们准备将数据分为训练集和测试集。我将用30%的数据集进行测试。

训练RNN
在本节中,我将向您展示如何实现RNN深度学习架构,3层SimpleRNN和3层LSTM架构的几个变体。默认情况下,对于SimpleRNN和LSTM层,激活函数均设置为“ tanh”,因此让我们将其保留为默认设置。我将使用所有65125个不同单词,将每个输入的最大长度限制为14个单词,因为它与推文中单词的最大长度一致,并将嵌入矩阵的输出维设置为32。
Dropout层将用于强制执行正则化项(regularization terms)以防止过拟合。因为我的数据集被标记为二进制类,所以我将使用二进制交叉熵作为损失函数。就优化器而言,Adam优化器是一个不错的选择,我将准确性作为度量标准。在训练集上运行10遍,其中训练集的70%将用于训练模型,而其余30%将用于验证。请勿将其与我们之前的设置混淆。

模型参数如下:

SimpleRNN模型的结果显示如下——10次训练:

在没有dropout的情况下训练3层lstm。我将在训练集上运行10遍,其中训练集的70%将用于训练模型,而其余30%将用于验证。请勿将其与我们之前的设置混淆。
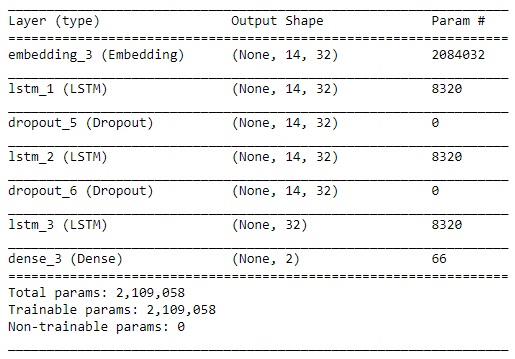
模型参数如下所示:

LSTM模型结果显示如下——10次训练:
第六步:模型评估
现在,让我们绘制模型在一段时间内的性能,并查看它们在10次训练内的准确性和损失。
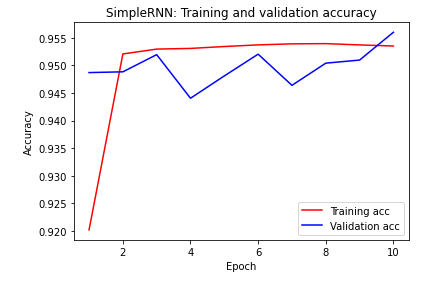
SimpleRNN:准确性
SimpleRNN:损失
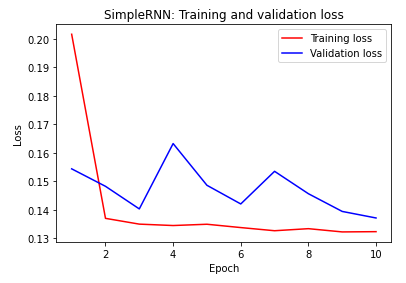
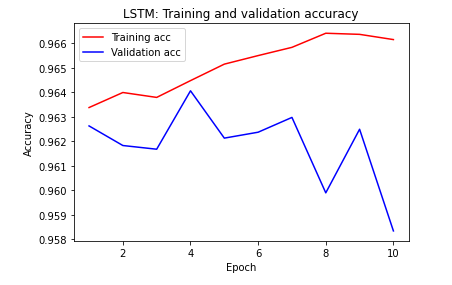
注意训练精度,由于相同的原因,SimpleRNN模型很快开始过度拟合,并且验证精度具有较高的方差。
LSTM:准确性
LSTM:损失
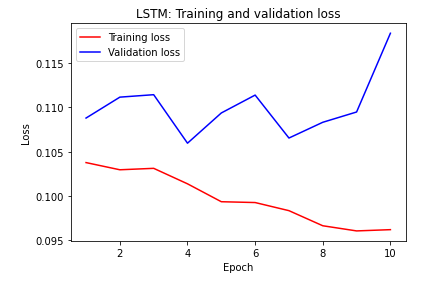
从LSTM的精度和损失曲线可以看出,该模型过度拟合,并且由于相同的原因,验证精度不仅具有较高的方差,而且还会迅速下降。
结论
在这个项目中,我试图演示如何建立深度学习pipeline,以预测与2020年美国大选相关的推文的情绪。为此,我首先通过Twitter API和Tweepy包抓取了原始推文,创建了自己的数据集。
通过Twitter API抓取了超过440000条推文,并将其存储到CSV文件中。在对数据进行整理和可视化之后,使用传统的聚类算法(在这种情况下为k-means聚类)为推文添加了两个不同的标签,分别代表正面或负面情绪。也就是说,在使用数据训练深度学习模型之前,该问题已转换为监督学习问题。然后将数据集分为训练集和测试集。
后来,训练集分别用于训练SimpleRNN和LSTM模型,并使用每个时期的模型性能使用损失和准确性曲线对其进行了评估。总体而言,这两种模型似乎都按预期运行,并且可能会根据从精度曲线中看到的数据过度拟合,因此,为下一步提出了以下建议。
1.寻找另一种方法或不同的学习算法来标记数据集
2.尝试使用Amazon Mechanical Turk或Ground Truth标记数据集
3.尝试不同的RNN架构
4.对RNN架构执行更高级的超参数调整
5.进行交叉验证
6.使数据成为多类别的
在此项目/教程中实践的技能:
1.如何通过Tweepy和Twitter API从Twitter有效收集数据
2.如何有效处理大型数据集
3.如何构建深度学习架构,如何在Keras中进行编译
4.如何将基本的NLP概念和技术应用于文本数据
(周子喻编译,张梦婷校对)
语言可解释性工具(LIT):NLP模型的交互式探索和分析
随着自然语言处理模型变得越来越强大且应用于更广泛的现实情景中,理解模型机理和表现变得越来越重要。尽管建模方面的进步为许多NLP任务带来了空前的性能,但仍然存在许多研究问题,这些问题不仅涉及这些模型在领域迁移和对抗环境下的行为,还涉及到它们的行为是否符合社会发展趋势。
对于任何新模型,人们可能想知道模型在哪种情况下效果不佳,模型为何做出特定的预测,或者模型在各种输入(例如文本样式或性别代名词的改变)下是否会表现一致。但是,尽管最近在模型理解和评估方面的工作激增,但没有用于分析的“万金油”。从业人员必须经常试验多种技术,研究局部解释,汇总指标和输入的反事实变化,以更好地理解模型行为,而这些技术中的每一种通常都需要使用自己的软件包或定制工具。我们之前发布的假设分析工具旨在通过对分类和回归模型进行黑盒探测来应对这一挑战,从而使研究人员可以更轻松地调试性能,并通过交互和可视化分析机器学习模型的公平性。但是仍然需要一种工具包来解决NLP模型特有的挑战。
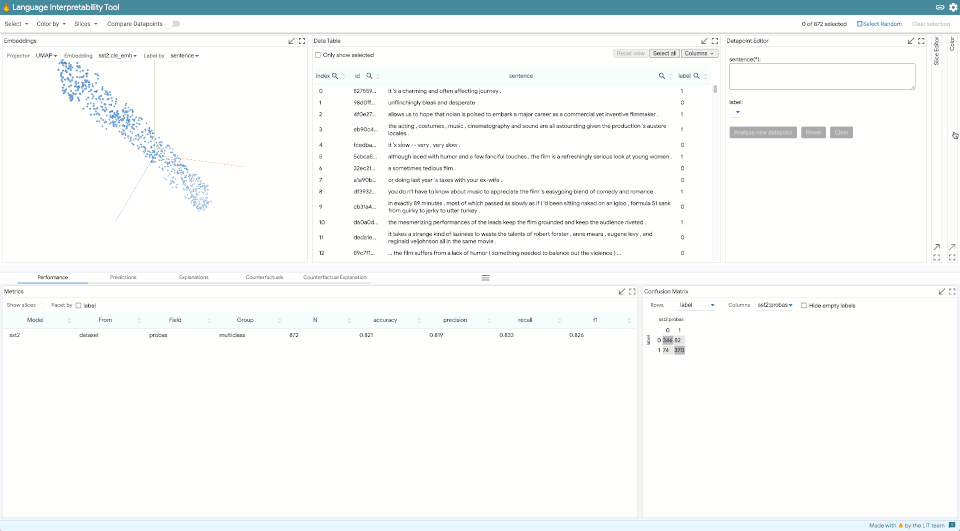
考虑到这些挑战,我们构建并开放了语言可解释性工具(Language Interpretability Tool,LIT),这是一个用于NLP模型理解的交互式平台。LIT建立在从假设分析工具中获得的经验教训的基础上,具有极大的扩展功能,涵盖了一系列NLP任务,包括序列生成、范围标记、分类和回归以及可自定义和可扩展的可视化和模型分析。
LIT支持局部说明,包括显著性映射、注意力和模型预测的丰富可视化,以及包括度量、嵌入空间和灵活切片的聚合分析。它使用户可以轻松地在可视化效果之间进行切换,以测试局部假设并通过数据集对其进行验证。LIT为反事实生成提供支持,可以在其中即时添加新的数据点,并立即可视化它们对模型的影响。 并排比较允许同时显示两个模型或两个单独的数据点。有关LIT的更多详细信息,请参见我们在EMNLP 2020上发表的系统演示文件。
可定制性
为了更好地满足希望使用LIT的具有不同兴趣和优先级的广泛用户,我们从一开始就构建了易于定制和扩展的工具。 在特定的NLP模型和数据集上使用LIT仅需要编写少量Python代码。可以使用Python编写自定义组件,例如特定于任务的度量计算或反事实生成器,并通过我们提供的API将其添加到LIT实例中。 此外,可以使用直接集成到UI中的新模块来定制前端本身。有关扩展该工具的更多信息,请查看我们在GitHub上的文档。
演示版
为了说明LIT的某些功能,我们使用预先训练的模型创建了一些演示。 完整列表可在LIT网站上找到,我们在这里描述其中两个:
在此示例中,用户可以探索基于BERT的二进制分类器,该分类器预测句子是具有正面还是负面情绪。该演示使用电影评论中的Stanford Sentiment Treebank句子来演示模型行为。可以使用多种技术(例如LIME和集成梯度)提供的显著性映射来检查局部解释,还可以使用反向翻译(back-translation)、单词替换(word replacement)或对抗攻击(adversarial attacks)等技术来测试模型行为。这些技术可以帮助查明模型在哪些情况下会失败,以及这些失败是否可以泛化,然后可以用来告知如何最好地改进模型。

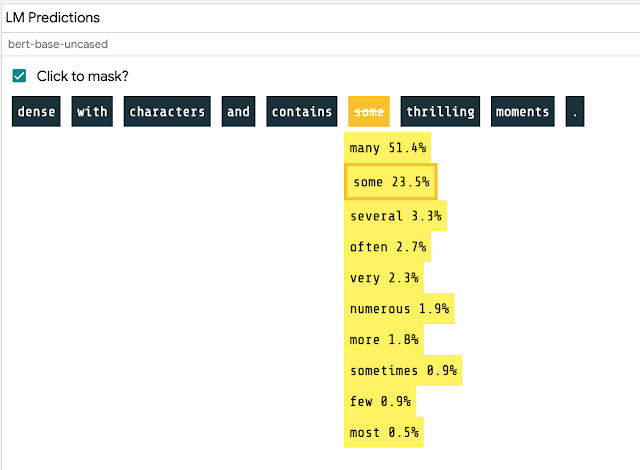
掩盖语言建模是一项“填空”任务,其中模型预测可以完成一个句子的不同单词。例如,在提示“我带着___散步”的提示下,模型可能会预测“狗”的得分较高。在LIT中,可以通过键入句子或从预加载的语料库中进行选择,然后单击特定的标记以查看像BERT这样的模型对语言或世界的理解。
LIT实践与未来工作
尽管LIT是一种新工具,但我们已经看到了它可以为模型理解提供的价值。它的可视化可用于查找模型行为中的模式,例如嵌入空间中的较远的数据群或对预测而言具有重要意义的单词。在LIT中的探索可以测试模型中的潜在偏差,正如我们的LIT探索共指模型中的性别偏见案例研究所示。这种类型的分析可以为提高模型性能提供后续步骤,例如应用MinDiff减轻系统偏差。它也可以用作为任何NLP模型创建交互式演示的便捷方法。LIT的工作才刚刚开始,并且我们计划了许多新功能和改进,包括从最前沿的ML和NLP研究中添加新的可解释性技术。
(张梦婷编译,周子喻校对)
近期会议
NeurlPS 2020:the Neural Information Processing Systems annual meeting
Dec 6-Dec 12,2020 线上
神经信息处理系统年会的目的是促进有关神经信息处理系统的生物学,技术,数学和理论方面的研究交流。核心重点是在同行大会上介绍和讨论的同行评审新颖研究,以及各自领域的领导人邀请的演讲。