文本挖掘与机器学习跟踪扫描动态快报(2020.12)
实时跟踪、关注文本挖掘与机器学习领域最新研究动态
深度观察
Transformer趋势
Transformers是一类基于注意力的神经架构。自2017年问世以来,它实现了诸如Google BERT和OpenAI GPT系列等高级预训练语言模型,并在语音识别和其他NLP任务上取得多项突破。Transformers在处理序列数据的问题上表现得异常出色,最近又被扩展到强化学习、计算机视觉和符号数学。
今年,NeurIPS接受了22篇Transformer相关的研究论文。Synced从中选择了十个作品来展示最新的Transformer趋势——从神经架构的扩展使用到技术创新、架构设计变更等等。
Transformer的广泛使用
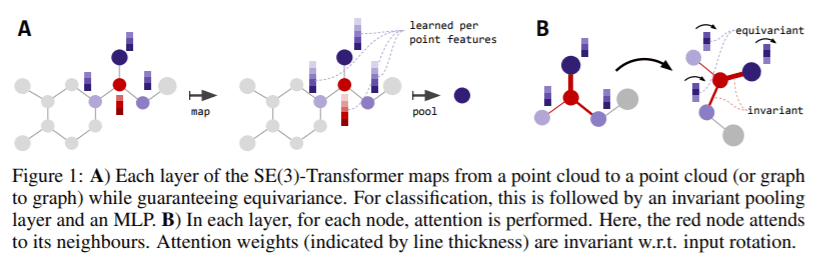
摘要:我们介绍了SE(3)-Transformer,它是3D point-clouds的自注意模块的变体,在连续的3D旋转平移下是等价的。在数据输入存在不利转换时,等价性对于确保稳定和可预测的性能非常重要。等价性的正推论是模型中的权重增加。SE(3)-Transformer充分利用了自我注意的优势来处理具有不同点数的大型点云,同时保证SE(3)-Equivariance的鲁棒性。我们在一个N体粒子模拟数据集上评估了我们的模型,展示了在输入旋转情况下预测的鲁棒性。我们在两个真实世界的数据集ScanObjectNN和QM9上进一步实现了竞争性能。在所有情况下,我们的模型都优于一个强大的、非等变的注意baseline和一个没有注意的等变模型。
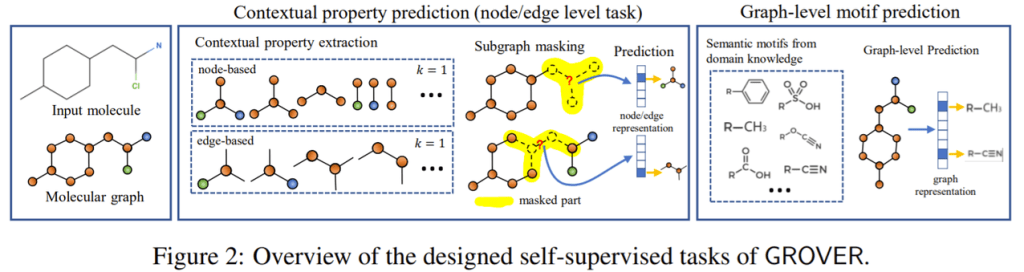
腾讯AI实验室、北京国家信息科学技术研究中心和清华大学提出了一个新的框架,即Graph Representation frOm self-superVised mEssage passing tRansformer, GROVER。
摘要:如何获得分子的信息表征是AI驱动药物设计和发现的关键先决条件。最近的研究将分子抽象为图,并利用图神经网络(GNNs)进行分子表征学习。然而,有两个问题阻碍了GNNs在实际场景中的应用:(1)用于监督训练的标记分子不足;(2)对新合成分子的泛化能力较差。为了解决这两个问题,我们提出了一个新的框架GROVER。通过精心设计的节点级、边级和图级自监督任务,GROVER可以从大量未标记的分子数据中学习到分子的丰富结构和语义信息。相反,为了编码这样复杂的信息,GROVER将消息传递网络集成到Transformer样式的架构中,以提供一类更具表现力的分子编码器。GROVER的灵活性使得它能够在大规模的分子数据集上进行有效的训练,而无需任何监督,因此不受上述两个问题的影响。我们在1000万个未标记分子上用1亿个参数预训练GROVER,这是分子表征学习中最大的GNN和最大的训练数据集。然后,我们利用预先训练的GROVER进行分子性质预测,然后进行特定任务的微调,在11个具有挑战性的基准上,与当前的最新方法相比,我们观察到了巨大的改进(平均超过6%)。我们认为精心设计的自我监督损失和大量表现力强的预训练模型在提升绩效方面具有巨大潜力。
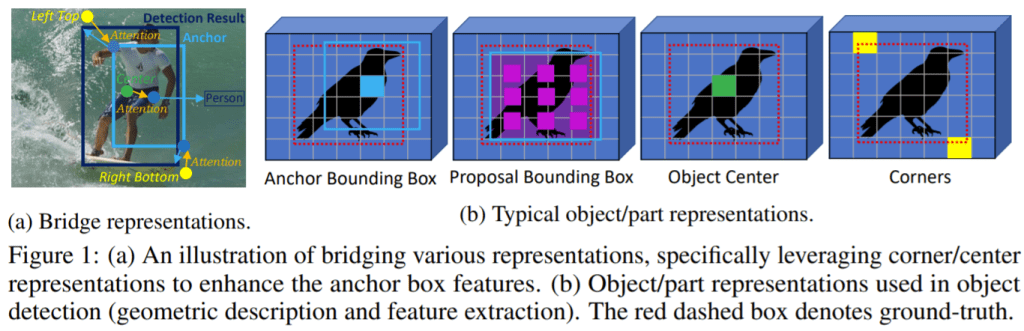
中国科学院和微软亚洲研究院的研究人员将各种视觉表示与类似Transformer的注意力机制联系在一起,旨在增强对象检测器中的主要表征。
摘要:现有的目标检测框架通常建立在目标/部件表示的单一格式上,即RetinaNet和Faster R-CNN中的锚点/建议矩形框、FCOS和RepPoints中的中心点以及CornerNet中的角点。虽然这些不同的表示通常会促使框架在不同方面表现良好,例如更好的分类或更精细的本地化,但是由于异构性和非网格性,通常很难将这些表示组合到单个框架中以充分利用每种优势。本文提出了一种基于注意力的解码器模块,该模块类似于Transformer中的模块,以端到端的方式将其他表示形式桥接到基于单个表示形式格式的典型对象检测器中。其他表征充当一组关键实例,以增强数据库中的主要查询表征特性。为了提高解码模块的计算效率,提出了一种新的技术,包括密钥采样方法和共享位置嵌入方法。该模块被命名为桥接视觉表示(Bridging Visual Representations,BVR)。它可以执行到位,并且我们证明了其在其他表征桥接到流行的目标检测框架(包括RetinaNet,Faster R-CNN,FCOS和ATDD)中的广泛有效性,在这些方面实现了约1.5∼3.0 AP的改进。我们还将具有强大主干的最新框架提高了约2.0AP,在COCO-test-dev上达到了52.7AP。生成的网络名为RelationNet++。
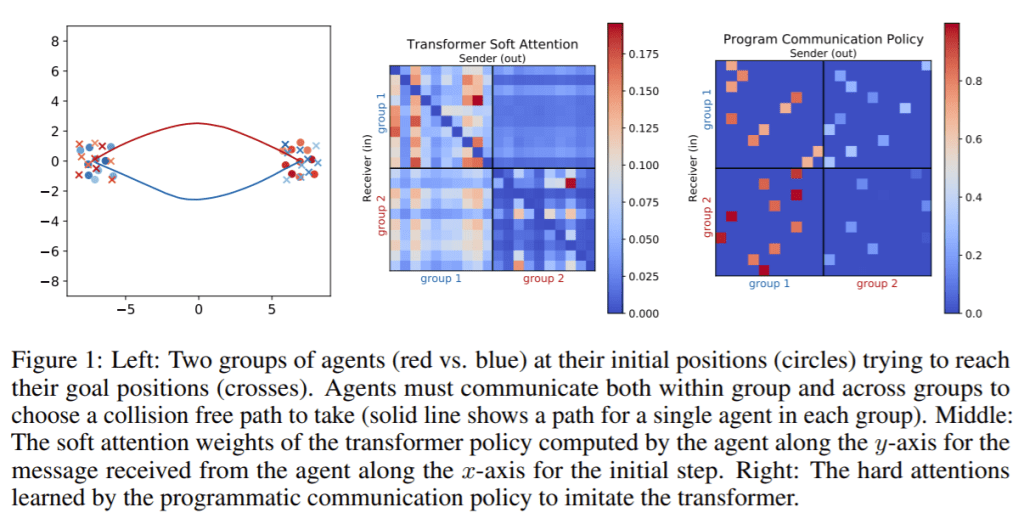
麻省理工学院CSAIL和宾夕法尼亚大学的研究人员将Transformer和编程通信策略结合在一个神经符号Transformer中,以减少协作多智能体规划问题中的通信量。
摘要:我们研究了一种推断通信结构的问题,该结构可以解决协作式多主体计划问题,同时最大程度地减少通信量。我们将通信量量化为通信图的最大度。由于决策空间和目标的组合性,最小化通信是一个具有挑战性的问题;例如,我们不能通过使用梯度下降法训练神经网络来解决这个问题。我们提出了一种新的算法,该算法综合了一个控制策略,该策略将用于生成通信图的编程通信策略与用于选择动作的转换器策略网络相结合。我们的算法首先训练Transformer,它隐式地生成一个“软”通信图;然后,它综合了一个程序化的通信策略,该策略可以“硬化”该图,形成一个神经符号Transformer。我们的实验证明了我们的方法可以综合生成低度的通信图,同时保持接近最优的性能。
创新技术进步
FacebookAI的这项工作提出了一种新的方法来训练深度Transformer,以学习有效的网络深度。
摘要:Transformer模型在许多序列建模任务中取得了最先进的性能。然而,如何利用大深度或可变深度的模型容量仍然是一个挑战。我们提出了一个概率框架,通过学习层选择的后验分布来自动学习要使用的层。作为该框架的一个扩展,我们提出了一种新的方法来训练一个共享Transformer网络用于多语言机器翻译,每个语言对具有不同的层选择后验率。所提出的方法减轻了消失梯度问题,并能够稳定地训练深度Transformer(如100层)。我们评估了WMT英语-德语机器翻译和掩盖语言建模任务,我们的方法在训练更深层的Transformer方面优于现有的方法。多语种机器翻译的实验表明,该方法能有效地利用增加的模型容量,对多对一和多对多语言的翻译都有普遍的改进。
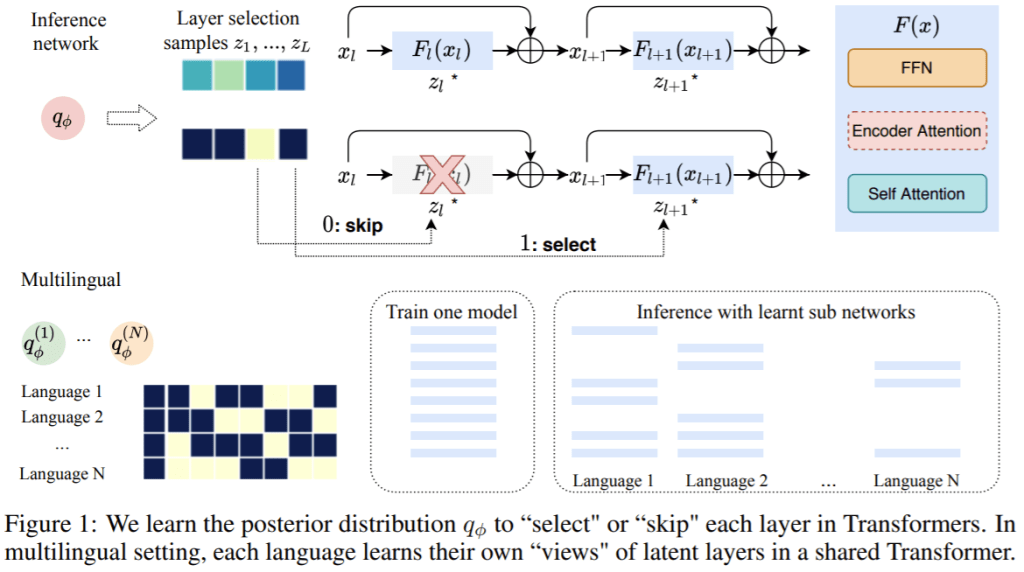
微软的研究人员提出了一种基于渐进层删除的方法来加速基于Transformer的语言模型的训练。
摘要:近年来,基于Transformer的语言模型在许多NLP领域都表现出了显著的性能。然而,这些模型的无监督预训练步骤会带来难以承受的总体计算成本。现有的加速预训练的方法要么依赖于与先进硬件的大规模并行,要么不适用于语言模型。在这项工作中,我们提出了一种基于递进层删除的方法来加速基于Transformer的语言模型的训练,而不是以牺牲过多的硬件资源为代价,而是从模型结构的改变和训练技术的提高来提高效率。在BERT上的大量实验表明,该方法在FLOPS中的计算量减少了25%,端到端的wall-clock训练时间减少了24%。此外,我们证明我们的预先训练模型具有很强的知识转移能力,在下游任务中达到与基线模型相似甚至更高的精度。
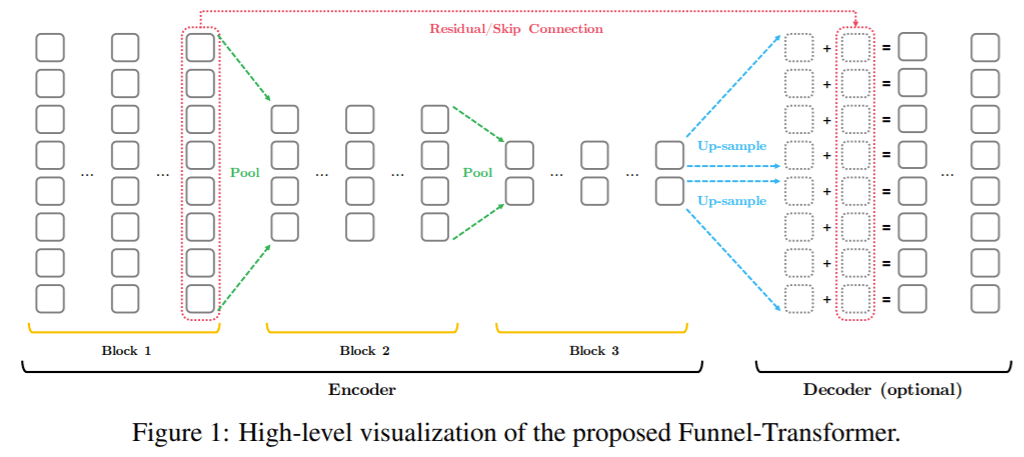
CMU和Google AI研究人员提出的Funnel-Transformer过滤掉了顺序冗余以降低计算成本。
摘要:随着语言预训练的成功,开发更高效、可扩展性更好的体系结构,以更低的成本利用丰富的未标记数据成为一个迫切需要。为了提高效率,我们检查了在维护一个完整的令牌级表示时被忽略的冗余,特别是对于只需要序列的单个向量表示的任务。基于这种直觉,我们提出了Funnel-Transformer,它将隐藏状态序列逐渐压缩为较短的状态序列,从而降低了计算成本。更重要的是,通过重新投资从长度缩减节省下来的FLOPs来构建更深或更宽的模型,我们进一步提高了模型的容量。此外,为了执行常见预训练目标所需的token级预测,Funnel-Transformer能够通过解码器从精简的隐藏序列中恢复每个token的深度表示。从经验上看,在相当多的FLOP或更少的FLOP情况下,Funnel-Transformer在各种各样的序列级预测任务(包括文本分类、语言理解和阅读理解)上都优于标准Transformer。
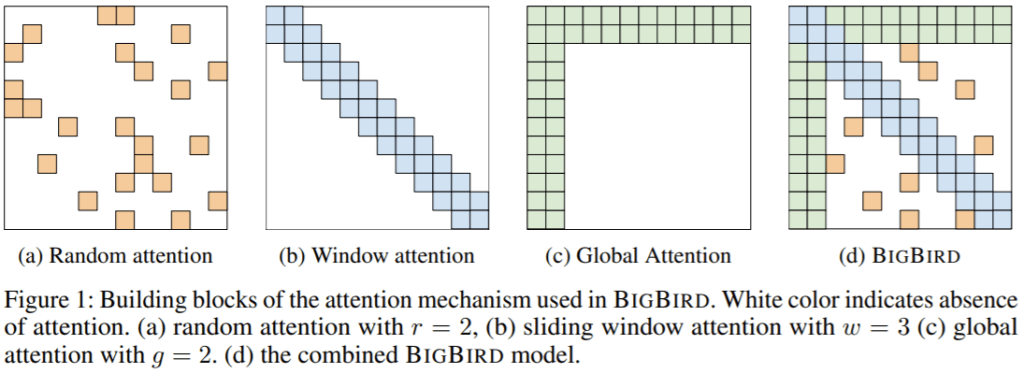
Google研究人员引入了一种称为BigBird的稀疏注意机制,以缓解Transformer的二次依赖性。
摘要:基于Transformer的学习模型(如BERT)已经成为自然语言处理中最成功的深度学习模型之一。不幸的是,由于其全注意机制,它们的核心局限之一是对序列长度的二次依赖(主要是存储方面)。为了弥补这一点,我们提出了稀疏注意机制的BigBird,将这种二次依赖性降低为线性依赖性。我们证明了BigBird是序列函数的一个通用逼近器,并且是图灵完备的,从而保持了二次全注意模型的这些性质。在此过程中,我们的理论分析揭示了拥有O(1)全局token(例如CLS)的一些好处,这些token作为稀疏注意机制的一部分参与整个序列。所提出的稀疏注意可以处理序列长度是使用硬件之前可能达到的8倍。由于能够处理更长的上下文,BigBird极大地提高了各种NLP任务(例如QA和文摘)的性能。我们还提出了对基因组数据的新应用。
麻省理工学院和Google研究所的一个团队设计了一个统一的框架,为可用的稀疏Transformer模型提供理论上的理解。
摘要:最近,Transformer网络重新定义了许多NLP任务中的最新技术。然而,这些模型在输入序列长度nn上要承受二次计算成本,以计算每一层中的成对注意力。这促使了最近对稀疏Transformer的研究,稀疏Transformer将注意力层中的连接稀疏化。尽管在经验上它可以用于长序列,但基本问题仍然没有得到解答:稀疏Transformer是否能近似任意密集的序列到序列函数?稀疏模式和稀疏级别如何影响它们的性能?在本文中,我们解决了这些问题,并提供一个统一的框架。我们提出了充分条件,在此条件下我们证明了稀疏注意模型可以普遍地逼近任意序列到序列函数。我们的结果表明,每个注意层只有O(n)个连接的稀疏Transformer可以近似于具有n2连接的稠密模型的函数类。最后,我们通过实验比较了标准NLP任务中不同的稀疏模式和稀疏程度。
Idiap研究所、法国洛桑理工学院和日内瓦大学的研究人员对自我注意机制进行了研究。
摘要:Transformer已被证明是一个成功完成序列建模的模型。然而,由于计算注意力矩阵是它们的关键组成部分,对于大型序列而言它们的计算成本过大。为了解决这个问题,我们提出了聚类注意。它不是计算每个查询的注意,而是将查询分组,只计算质心的注意。为了进一步改进这种近似,我们使用计算出的簇来识别每个查询关注度最高的键,并计算精确的键/查询点积。对于固定数量的簇,这将导致模型相对于序列长度具有线性复杂度。我们在两个自动语音识别数据集上评估了我们的方法,并表明在给定的计算预算下,我们的模型始终优于Vanilla Transformers。最后,我们证明了我们的模型可以通过在GLUE和SQuAD基准测试中仅训练25个簇且性能没有损失的情况下,对预训练的BERT模型进行近似,从而以最小的簇数来近似任意复杂的注意力分布。
(张梦婷编译,周子喻校对)
NeurIPS 2020-您不容错过的文章
半监督和自我监督
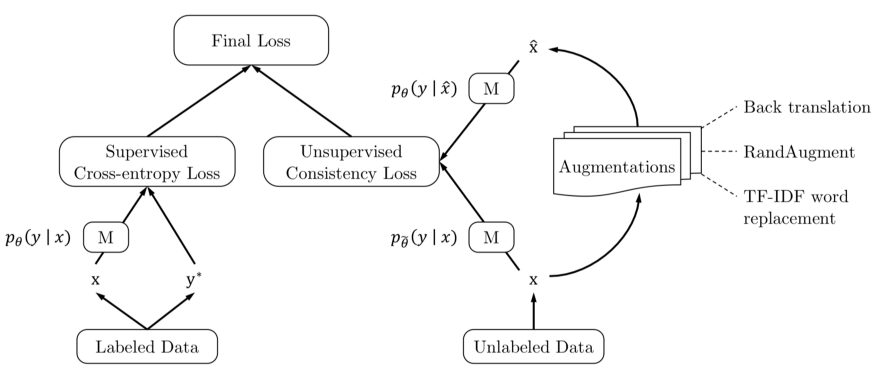
摆脱对标记数据的昂贵依赖是近年来ML议程的主要焦点之一,它甚至在今年的NeurIPS举办了自己的完整研讨会。
关键见解:简言之,无监督一致性损失是指在输入的不同变化(如文本的反译或图像的随机增强)上的一致性损失。直觉是:尽管不知道哪一个是分类模型M的有效学习信号,输入的不同变体需要具有相同的输出分类。在这种设置下,学习一个好的分类器所需的真正标签非常少。
结果在计算机视觉和自然语言处理方面都令人印象深刻,仅20个标签就足以在IMDb数据集上进行情感分析等任务,并有出色的表现。
Transformer和Attention
关键见解:全自注意存在序列长度(二次)伸缩性差的问题,而递归则存在由于消失梯度效应导致信息流无法“长时间距离”传播的问题。本文将这种权衡形式化,并说明了注意稀疏性和梯度流深度是如何限制这些类型网络的计算复杂性和信息流的。
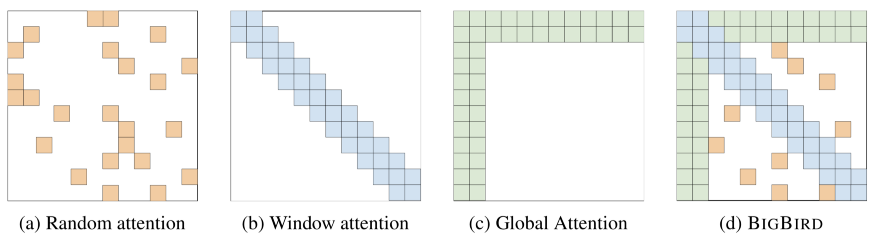
关键见解:结合3种不同的注意形式:窗口、全局和随机。有了这些技巧,注意机制所需的操作数可以与序列长度呈线性关系。虽然这并不是一个小模型——他们实验的窗口注意力已经是512个tokens,就像OG BERT⁶一样——这种注意力模式可以对更长的序列进行建模,比如基因组学中所要求的那些序列。
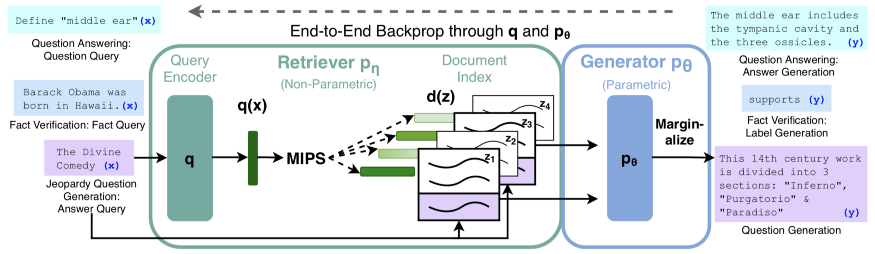
关键见解:它们是最先进的技术,展示了关于回答知识而不是知识变化的结果,并展示了RAG如何通过交换从中获取知识的文档集(无需任何再训练)来回答未经训练的答案。此外,事实的正确性似乎是这种方法的一个重要特征,尽管它仍然不足以被称为真正可靠的方法。
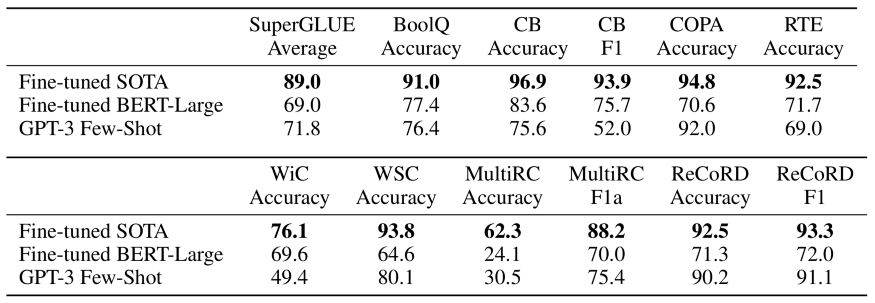
关键见解:GPT-3训练了一个1750亿参数的模型,该模型在few shot学习中显示了令人惊讶的结果,该模型只需要几个例子就可以将任何语言任务学习到令人惊讶的程度。但仍有许多问题存在,比如此类模型的成本等等。
基准与评估
关键见解:3个可重复的步骤:
- 从成对的摘要中收集人类偏好。
- 训练一个评估模型,学习如何在两个摘要之间预测人类偏好。
- 使用评估模型作为用于优化策略(模型)的奖励函数,该策略(模型)通过强化学习生成摘要。
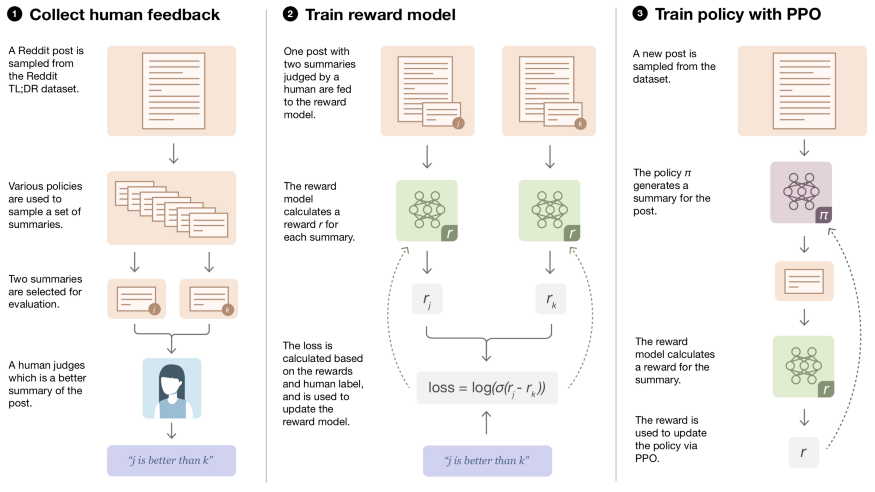
(张梦婷编译,赵海喻校对)
研究动态
空客AI为机组人员引入问答系统
Airbus AI Introduces Natural Language QA System for Flight Crews
空客AI研究人员开发了一种系统,该系统改善了机组人员搜索飞机运行信息时的问答(QA)性能。航空航天业依靠诸如飞机操作手册(AOM)、飞机操作说明以及组人员操作手册(FCOM)等技术文件来指导机组人员在正常、异常和紧急情况下进行飞机操作。FCOM由飞机制造商签发,涵盖系统描述、程序、技术和性能数据。它们是用于开发标准操作程序以提高安全性和效率的参考。
大多数政府航空管理局已经授权商业航空公司飞行员和机组人员使用平板电脑来获取FCOM信息。空客AI的研究人员注意到,现有的电子飞行包(EFB)系统实际上只不过是具有关键字搜索功能的pdf浏览器。Smart Librarian(SL)系统使用自然语言理解和交互式搜索来提高FCOM问答系统性能。

空客AI的SL FCOM问答系统有三个主要组件:对话引擎、检索器(搜索引擎)和QA模块。
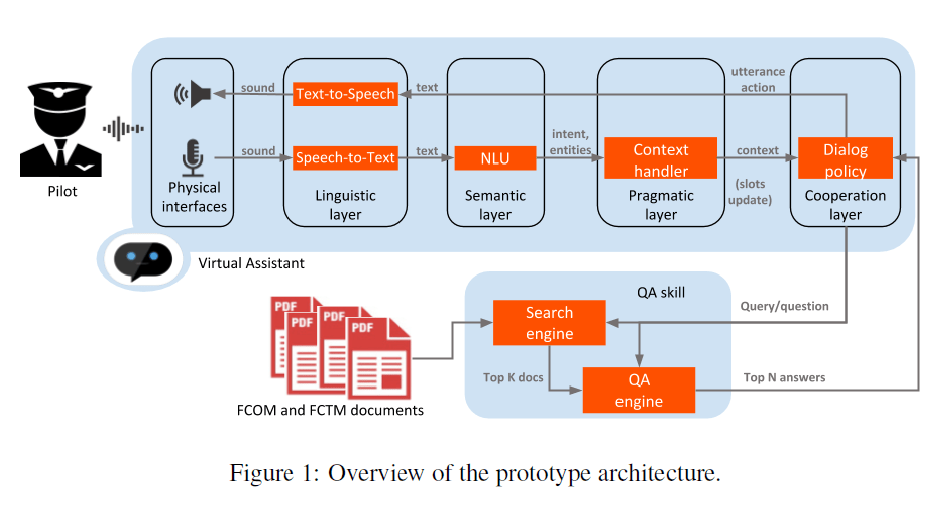
该系统使用基于开源的Rasa框架作为对话引擎,从而使其能够识别高级用户的话语,预测下一个最佳动作并根据对话状态识别用户的问题。检索系统是建立在一个经典的QA系统架构下,具有一个完整的文档过滤功能,可以在有限的时间内找到答案。检索器还利用概率相关性框架BM25作为索引方案来提高性能。
有了对话引擎和检索过滤器搜索系统,研究人员的下一个挑战是触发QA模块,用自然语言给出正确的最终答案。为此,他们利用了大型Google BERT模型、DrQA模型、多任务学习方法以及XGBoost。
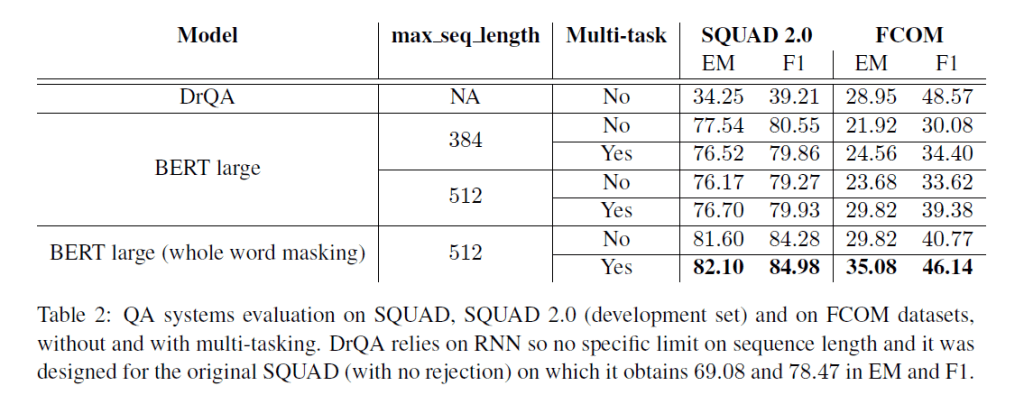
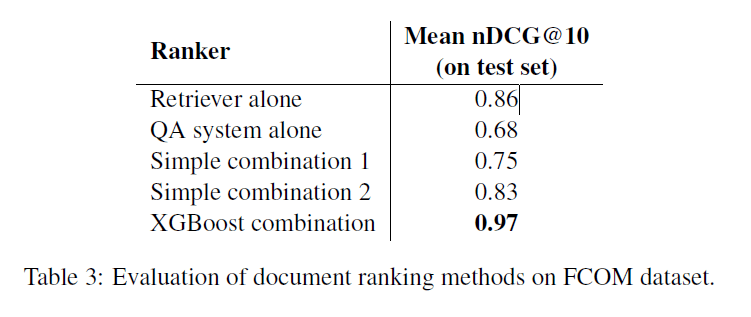
在交互式用户实验中,SL系统的性能优于EFB的FCOM关键字搜索功能,无论查询中是否包含关键字都可以在更短的时间内以更高的精度找到答案。
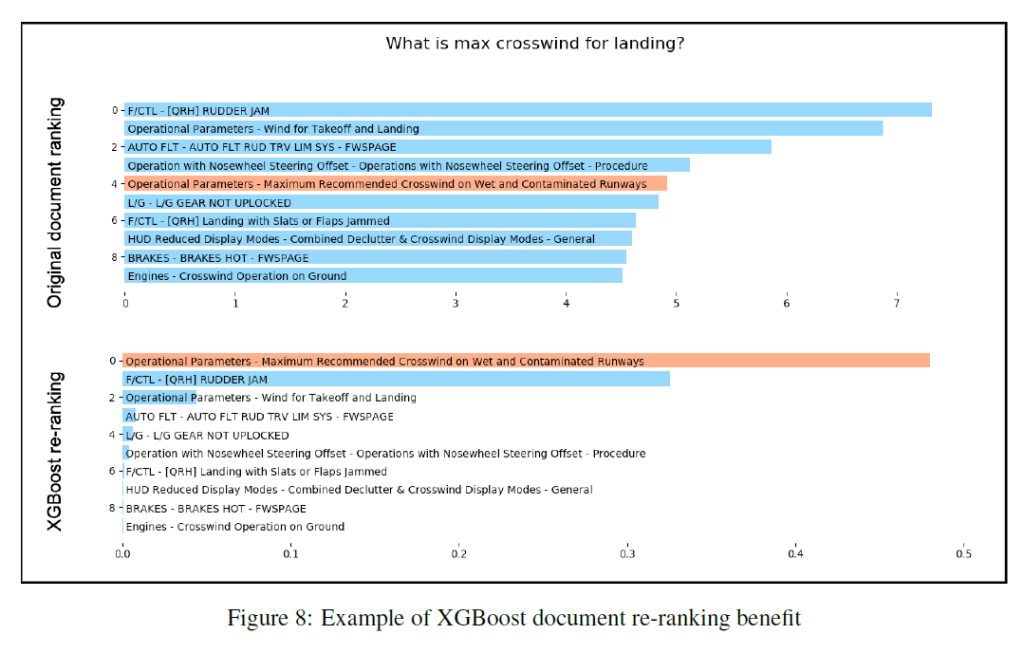
空客AI团队确定了SL系统的未来改进领域,即增加域内数据量以进一步微调QA引擎,并提高系统从FCOM表中提取答案的能力。
(张梦婷编译,周子喻校对)
大型语言模型中的隐私注意事项
经过训练以预测句子中下一个单词的基于机器学习的语言模型变得越来越强大,从而在诸如问答、翻译等应用程序中取得了突破性的改进。但是随着语言模型的不断发展,可能会暴露出新的和意料之外的风险,从而要求研究界积极开展工作,以开发出减轻潜在问题的新方法。
其中一个风险是模型可能会从它们接受训练的数据中泄露细节。尽管这可能是所有大型语言模型都要考虑的问题,但如果一个经过私人数据训练的模型要公开,可能会出现其他问题。由于这些数据集可能很大(数百GB)并且可以从一些列数据源中提取,因此它们有时可能包含敏感数据,包括个人识别信息(PII)-姓名、电话号码、地址等,即使是经过公共数据训练也是如此。这就增加了使用这种数据训练的模型可能在其输出中反映出某些私有细节的可能性。因此,重要的是要确定和最大程度地减少此类泄漏的风险,并为未来的模型制定解决该问题的策略。
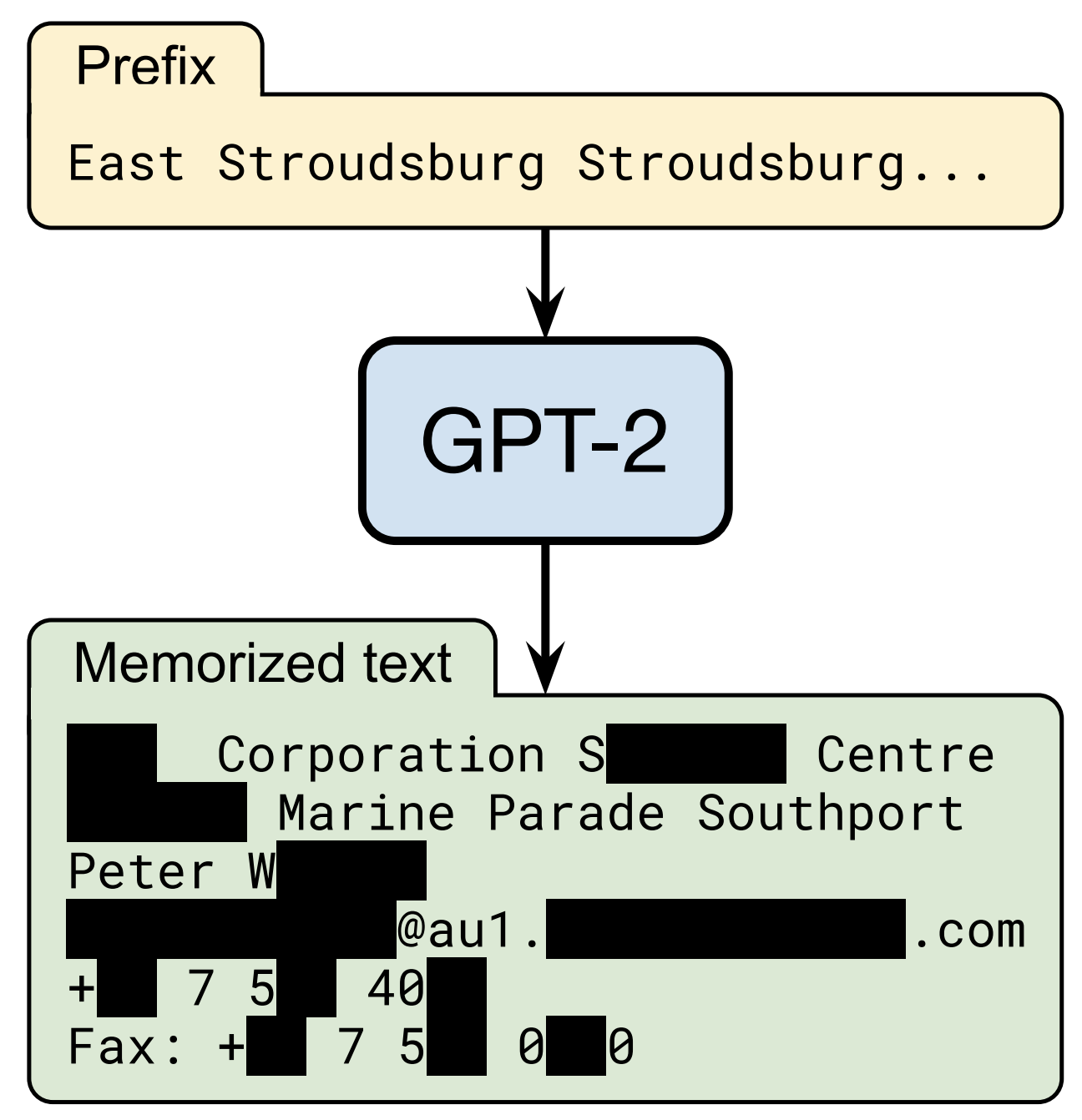
在与OpenAI、苹果、斯坦福、伯克利和东北大学合作的“Extracting Training Data from Large Language Models”中,我们证明了,只要能够查询预训练语言模型的能力,就可以提取模型已存储的特定训练数据片段。因此,训练数据提取攻击是对最先进的大型语言模型的现实威胁。这项研究代表了一个早期的关键步骤,旨在告知研究人员这类漏洞,以便他们可以采取措施来弥补这些漏洞。
语言模型攻击的伦理学
训练数据提取攻击应用于对公众可用但训练中使用的数据集不可用的模型时,具有最大的潜在危害。然而,由于对这样一个数据集进行这项研究可能会产生有害的后果,因此我们转而对GPT-2(OpenAI开发的一种大型公共可用语言模型)进行概念验证训练数据提取攻击,该模型仅使用公共数据进行训练。虽然这项工作主要集中在GPT-2上,但结果适用于理解在大型语言模型上可能存在哪些隐私威胁。
与其他隐私和安全相关的研究一样,在实际执行此类攻击之前,考虑此类攻击的道德规范非常重要。为了尽可能降低这项工作的潜在风险,这项工作中的训练数据提取攻击是使用公开可用的数据开发的。此外,GPT-2模型本身在2019年由OpenAI公开,用于训练GPT-2的训练数据是从公共互联网收集的,任何遵循GPT-2论文中记录的数据收集过程的人都可以下载。
此外,根据负责任的计算机安全披露规范,我们对提取个人识别号的个人进行了跟踪,并获得了他们的许可,然后才在出版物中引用这些数据。此外,在这项工作的所有出版物中,我们已经编辑了可能识别个人的任何个人识别信息。我们还与OpenAI密切合作分析GPT-2。
训练数据抽取攻击
通过设计,语言模型使得生成大量的输出数据变得非常容易。通过在模型中植入随机的短短语,该模型可以生成数百万个连续体,即完成句子的可能短语。大多数情况下,这些连续体都是一串串合理的文本。例如,当被要求预测字符串“Mary had a little…”的连续性时,语言模型会非常确信下一个标记是单词“lamb”。然而,如果一个特定的训练文档碰巧多次重复字符串“Mary had a little wombat”,那么模型可能会预测该短语。
训练数据提取攻击的目标是从语言模型中筛选出数以百万计的输出序列,并预测哪些文本被记忆。为了实现这一点,我们的方法利用了这样一个事实,即模型往往对直接从训练数据中获取的结果更有信心。这些成员推断攻击使我们能够通过检查特定序列上模型的置信度来预测训练数据中是否使用了结果。
这项工作的主要技术贡献是开发了一种高精度推断成员资格的方法,以及从模型中取样的技术,以鼓励记忆内容的输出。我们测试了许多不同的抽样策略,其中最成功的一种是根据各种各样的输入短语生成文本。然后我们比较两种不同语言模型的输出。当一个模型在一个序列中有很高的置信度,而另一个(同样精确的)模型在一个序列中有很低的置信度时,很可能第一个模型已经存储了数据。
结果
在GPT-2语言模型的1800个候选序列中,我们从公共训练数据中提取了600多个记忆序列,总数受手动验证的限制。记住的例子涵盖了广泛的内容,包括新闻标题、日志消息、JavaScript代码、PII等等。尽管这些例子很少出现在训练数据集中,但其中许多例子都被存储了。例如,对于我们提取的许多PII样本,只能在数据集中的单个文档中找到。然而,在大多数情况下,原始文档包含多个PII实例,因此,模型仍然将其学习为高可能性文本。
最后,我们还发现语言模型越大,越容易存储训练数据。例如,在一个实验中,我们发现15亿个参数的GPT-2xl模型比1.24亿个参数的GPT-2small模型存储的信息多10倍。鉴于研究界已经培训了10到100倍大的模型,这意味着随着时间的推移,在越来越大的语言模型中,需要更多的工作来监控和缓解这个问题。
教训
虽然我们具体演示了这些针对GPT-2的攻击,但它们显示了所有大型生成语言模型中的潜在缺陷。这些攻击是可能的,这一事实对使用这些模型的机器学习研究的未来具有重要的影响。
幸运的是,有几种方法可以缓解这个问题。最直接的解决方案是确保模型不会针对任何潜在的有问题的数据进行训练。但这在实践中很难做到。
差异隐私的使用允许在数据集上进行训练,而不暴露任何单个训练示例的细节,是训练具有隐私的机器学习模型的最有原则的技术之一。在TensorFlow中,这可以通过使用TensorFlow/privacy模块(或PyTorch或JAX类似的模块)来实现,它是现有优化器的替代品。即使这样也会有局限性,并且不会妨碍对重复次数足够多的内容的存储。
语言模型继续显示出巨大的实用性和灵活性,但与所有创新一样,它们也可能带来风险。负责任地开发它们意味着主动识别这些风险并制定减轻风险的方法。我们希望,这项旨在突出当前大型语言建模中的弱点的努力将提高广大机器学习界对这一挑战的认识,并激励研究人员继续开发有效的技术来训练记忆能力较低的模型。
(张梦婷编译,周子喻校对)
项目工具
NLP的TandA:迁移与适应,还是适应与迁移?
TandA for NLP: Transfer and Adaptation, or Adaptation and Transfer?
在过去的两年,NLP迅猛发展,发布了许多基于大型深度神经网络和Transformer模型的模型。这些模型已经在大量的语料库上进行了大量的预训练,可以随时使用。
良好的特定域标记数据集是稀缺的,而且构建起来成本很高。例如,生物医学 BioASQ 挑战每年只发布500个新的专家注释问题(目前总数达到3000个)。作为比较, SQUAD数据集包含超过十万个示例。如果注释数据很少或缺乏注释,如何使自己的模型适应特定的域?在1000个项目的数据集上直接微调一个类似BERT的预训练模型可能会产生很差的结果;而且,尽管有一些无监督方法可以从纯文本生成问题,但我还是愿意把研究的重点放在TandA方法以及在无需合成数据的适应或迁移方法上。
TandA方法
一年前,发布了一种用于精细训练大型NLP模型的鲁棒性方法,称为TandA for Transfer and Adapt。其思想是将任务的学习与领域的学习分离开来。这使学习更稳定、效果更好。有两个步骤:1. 迁移:使用一个大的通用数据集,在有监督的任务上对预先训练的模型进行微调。任务可以是句子分类、抽取式QA或选择答案句子等。2. 适应:然后在一个小的特定数据集上进行微调。例如,这可以是BioASQ数据集。它必须与先前学习的任务相对应。
我在这里提供了一种使用Transformers包来实现和运行此功能的方法,因为项目的github存储库没有提供教程和完整的代码。我将演示如何将Transformer迁移到答案句子选择任务。这是类似GLUE的二进制分类任务:答案是否与问题匹配?我使用的数据集为ASNQ。然后,出于本篇第二部分的目的,我将展示如何利用BioASQ挑战发布的数据集来使此Transformer适应生物医学领域。



我用BERT-base cased得到了88%的精度。我将此模型称为bert(asnq);这是一个迁移到ASNQ任务的BERT。
您可以使用更复杂的句子标记器,例如nltk的PunktSentenceTokenizer。 我得到了以下分布:

你可以优化超参数。我的bert-base-asnq,得到了81%的精度。我将此模型称为bert(asnq–bioAsq);这是一个迁移到asnq任务并适应BioAsq数据的BERT。
适应和转移,没有特定的标记数据
1.借助特定于领域的纯文本来适应模型的预训练;
2.借助通用的标记数据集将其转移到特定任务;
3.可能使其适应特定的数据集。
第一步的适应是指对领域词汇表的适应;而第三步的适应是对特定数据集词汇表和统计模式(即可能的偏差)的适应。
第一步并不简单。对一个随机初始化的Transformer进行整个预训练成本非常高,并且需要千兆字节的文本。这样做更好的方法是改进预训练,在语料库中添加更多的步骤。
我更喜欢使用BioBert-base模型。它的工作原理与经典的BERT一样;由于提供了一个Transformer实现,所以run_glue.py仍然有效。BioBert是一个适合BioASQ使用的生物医学领域的模型。
我使用以下命令执行上一部分的最后两个步骤:


将训练后的模型称为biobert(asnq)和biobert(asnq-bioAsq)。
下面是用bert(asnq)和biobert(asnq)得到的精确度对比:

下面是使用bert(asnq-bioAsq)与biobert(asnq-bioAsq)得到的精度对比:
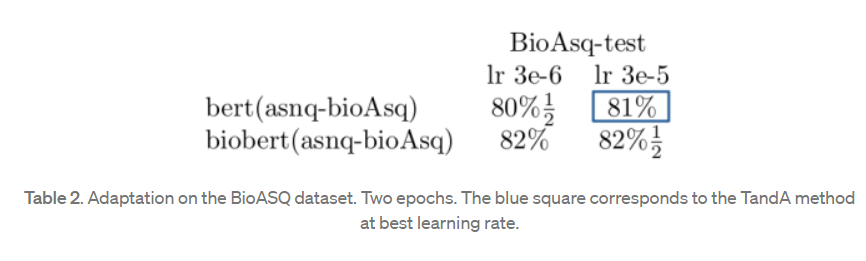
在没有看到任何BioASQ数据之前,Biobert在生物医学领域的表现优于BERT;它们的精确度相差4个点(BioASQ序列的评估)到5.5个点(BioASQ测试)。BERT仍然表现得很好。一个警告:BioASQ集的质量是值得怀疑的,表中训练集和测试集之间的分数存在差异。
主要结论:不需要使用任何特定的标记数据集就可以获得良好的结果。在bioAsq测试集上,biobert(asnq)(红方块)与bert(asnq–bioAsq)(蓝方块)的精确度接近。
还原TandA方法提供了第二个优点。biobert(asnq)应该能够处理更一般的数据,即不像BioASQ那样分布;而bert(asnq–BioASQ)可能过于专业化,无法一概而论。通过这种方式,适应是在文本而不是在数据集上完成的。数据集可能有虚假的相关性;纯文本的偏差较小。这样你的模型就可以学习整个领域。如果您可能标注的数据不够具有代表性,那么这一点很重要。这对于BioASQ之类并不重要,因为在BioASQ中,您的模型将运行在类似的数据集上,但这种情况是人为的。bert(asnq–bioAsq)(TandA方法)的实际性能可能被夸大了。
最终,停用带标签的数据集将模型迁移到任务上就可以了。迁移数据集(这里的ASNQ)也可能有虚假的相关性,必须为每个新任务构建它。正如我所建议的,从纯文本学习、适应和迁移是一种很有前途的方法。
(张梦婷编译,赵海喻校对)
近期会议
CLNLP 2021:Computational Linguistics and Natural Language Processing
July 23 - July 25, 2021 大连
CLNLP 2021将围绕“计算语言学和自然语言处理”的最新研究领域而展开,来自世界各地的主要研究人员和行业专家将通过论文和口头报告介绍最新研究成果。
ECNLPIR 2021:European Conference on Natural Language Processing and Information Retrieval
Aug 13-Aug 15,2021 Stockholm, Sweden
ECNLPIR 2021致力于促进世界顶尖创新者、科学家、学者、研究人员和思想领导者之间的交流和探讨,促进自然语言处理与信息检索领域的发展与进步。在会议的这三天里,您将有机会聆听到前沿的学术报告,见证该领域的成果与进步。