文本挖掘与机器学习跟踪扫描动态快报(2021.01)
实时跟踪、关注文本挖掘与机器学习领域最新研究动态
深度观察
ToTTo:受控的表到文本生成数据集
在过去的几年中,用于自然语言生成的研究(用于文本摘要)已取得了巨大的进步。然而,尽管达到了很高的流利度,神经网络仍然容易产生”幻觉”(即生成内容可理解但对不符合数据集的文本),这可能会让这些系统在许多需要高度准确性的应用不能使用。例如一个来自Wikibio的数据集,该示例中的神经基准模型负责汇总比利时足球运动员Constant Vanden Stock的Wikipedia信息框条目,错误地总结出他是美国花样滑冰运动员。

虽然生成的文本对源数据的真实性可能会遇到挑战,但是在构建源内容(例如以表格格式)时,通常会更容易。此外,结构化数据还可以测试模型进行推理和数字推断的能力。但是,现有的大规模结构化数据集通常噪音很多(即无法从表格数据中完全推断出参考的语句),从而使其在模型开发中对于”幻觉”的测量不可靠。
在“ ToTTo:一个受控的表到文本生成数据集”中,我们展示了一个开放域的表到文本生成数据集,该数据集使用新的注释方法(通过句子修订)并且可用于评估”幻觉”。ToTTo(“表到文本”的缩写)包含121,000个训练示例,每个都有用于开发和测试的7,500个示例。由于注释的准确性,该数据集适合作为评价高精度文本生成模型的具有挑战性的基准。数据集和代码在我们的GitHub repo上开源。
表到文本生成
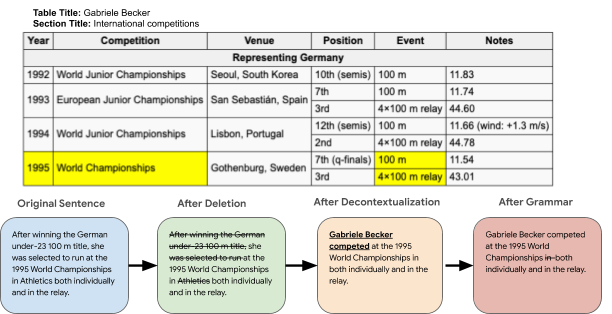
ToTTo引入了受控生成任务(controlled generation task),其中将给定的Wikipedia表以及一组选定的单元格用作生成单个句子描述的任务的源数据,该句子描述总结了表上下文中的单元格内容。下面的示例演示了该任务带来的许多挑战中的一些挑战,例如数值推理,庞大的开放域词汇表和变化的表结构。

在ToTTo数据集中的示例中,给定了源表和一组突出显示的单元格(左),目标是生成一个句子进行描述,例如“target sentence” (right)。请注意,生成目标句子将需要数字推断(eleven NFL seasons)和对NFL域的理解。
注释过程
设计注释过程以从表格数据中获取自然且干净的目标句子是一项重大挑战。诸如Wikibio和RotoWire之类的许多数据集,将自然出现的文本与表格进行启发式匹配,这是一个很乱的过程,使得难以区分”幻觉”是主要由数据噪声还是模型缺陷引起。另一方面,人们可以诱导注释器从头开始写句子目标(targets),这些目标要忠实于表格,但最终的目标常常在结构和样式方面缺乏多样性。
相反,ToTTo是使用新的数据注释策略构造的,其中注释器分阶段修改现有的Wikipedia句子。这导致目标句子既干净又自然,包含有趣且变化多样的语言特性。数据的收集和注释首先要在Wikipedia中收集表格,将给定的表与根据启发式方法从支持页面上下文中收集的摘要语句配对,(例如页面文本和表之间的单词重叠以及引用表格数据的超链接)。该摘要句子可能包含表没有的信息,并且可能包含仅在表中找到的具有先行词的代词,而不是句子本身。
然后,注释器突出显示表中支持该句子的单元格,并删除该表中不支持的句子中的短语。注释器还会对句子进行脱离上下文处理,以便在必要时使其独立(例如具有正确的代词解析度(pronoun resolution)和正确的语法。
我们发现注释器在上述任务上获得了高度认可:单元格突出显示为0.856 Fleiss Kappa,最终目标句子为67.0 BLEU。
数据集分析
我们对ToTTo数据集进行了44种类别的主题分析,发现“体育和国家”中,每个主题都包含一系列细分的主题,例如,足球/奥林匹克运动会和国家/地区的人口,总计占数据集的56.4%。另外44%的主题范围更广泛,包括表演艺术,交通和娱乐。
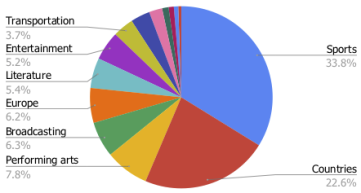
此外,我们对数据集中超过100个随机选择的示例中的不同类型的语言现象进行了手动分析。下表总结了部分示例(需要参考页面标题和章节标题),以及数据集中可能对当前系统提出新挑战的某些语言现象。
| 语言现象 | 百分比 |
|---|---|
| 需要参考页面标题 | 82% |
| 需要参考章节标题 | 19% |
| 需要参考表说明 | 3% |
| 推理(逻辑,数字,时间等) | 21% |
| 行/列/单元格之间的比较 | 13% |
| 需要背景信息 | 12% |
基准结果
我们以BLEU和PARENT为评估指标,介绍了三种最新模型(BERT-to-BERT,Pointer Generator和Puduppully 2019模型)的一些基准结果。除了测试在整体测试集上的分数外,我们还对更具挑战性的子集(包括域外示例)进行评估。如下表所示,BERT-to-BERT模型在BLEU和PARENT方面均表现最佳。此外,所有模型都在挑战集上表现出相当低的性能,这表明数据集有域外泛化的挑战。
| BLEU | PARENT | BLEU | PARENT | |
|---|---|---|---|---|
| Model | (Overall) | (Overall) | (Challenge) | (Challenge) |
| BERT-to-BERT | 43.9 | 52.6 | 34.8 | 46.7 |
| Pointer Generator | 41.6 | 51.6 | 32.2 | 45.2 |
| Puduppully et al.2019 | 19.2 | 29.2 | 13.9 | 25.8 |
尽管自动指标可以提供一些性能指标,但它们目前不足以评估文本生成系统中的”幻觉”。为了更好地理解”幻觉”,我们假设差异表明”幻觉”,手动评估性能最佳的基准,以确定其对源表中内容的符合程度。为了计算“专家”的性能,对于我们的多参考测试集中的每个示例,我们提供了一个参考,并要求注释者将其与其他参考进行比较以确保其真实性。结果表明,表现最佳的基准似乎使信息产生了约20%的”幻觉”。
| Faithfulness | Faithfulness | |
|---|---|---|
| Model | (Overall) | (Overall) |
| Expert | 93.6 | 91.4 |
| BERT-to-BERT | 76.2 | 74.3 |
模型错误和挑战
在下表中,我们提供了一些观察到的模型的错误,以突出显示ToTTo数据集的一些更具挑战性的方面。我们发现,遇到数字推理和稀有主题时,即使使用清洗过的引用(红色错误),最新模型也会遇到”幻觉”。最后一个示例显示,即使模型输出正确,有时它也不能像初始摘要(original reference)那样提供丰富的信息,初始摘要包含有关表的更多信息(以蓝色显示)。
| Reference | Model Prediction |
|---|---|
| n the 1939 currie cup, western province lost to transvaal by 17–6 in cape town. | the first currie cup was played in 1939 in transvaal1 at new- lands, with western province winning 17–6. |
| a second generation of micro- drive was announced by ibm in 2000 with increased capacities at 512 mb and 1 gb. | there were 512 microdrive models in 2000: 1 gigabyte |
| the 1956 grand prix motorcy- cle racing season consisted of six grand prix races in five classes: 500cc, 350cc, 250cc, 125cc and sidecars 500cc. | the 1956 grand prix motorcycle racing season consisted of eight grand prix races in five classes: 500cc, 350cc, 250cc, 125cc and sidecars 500cc。 |
| In travis kelce’s last collegiate season, he set personal career highs in receptions (45), re- ceiving yards (722), yards per receptions (16.0) and receiving touchdowns (8). | travis kelce finished the 2012 season with 45 receptions for 722 yards (16.0 avg.) and eight touchdowns. |
结束语
在这项工作中,我们介绍了ToTTo,这是一个大型的英语表到文本数据集,它提供了受控的生成任务和基于迭代句子修订的数据注释。我们还提供了一些最新的基准,并证明了ToTTo可能是用于建模研究以及开发可以更好地检测模型改进的评估指标的有用数据集。
除了建议的任务,我们希望我们的数据集也可以对其他任务(例如表格理解和句子修订)有所帮助。ToTTo在我们的GitHub存储库中可用。
(赵海喻编译,周子喻校对)
研究动态
Google Brain的Switch Transformer语言模型包含1.6万亿个参数
Google Brain’s Switch Transformer Language Model Packs 1.6-Trillion Parameters
Google Brain的研究人员将他们新提出的Switch Transformer语言模型扩展到高达1.6万亿个参数,同时控制了计算成本。该团队简化了Mixture of Experts(MoE)路由算法,有效地结合了数据、模型和并行性。在同等计算资源条件下比T5-XXL模型快4倍。

尽管许多最新的和更简单的深度学习架构的性能已经优于更复杂的算法,但是这些性能的提高伴随着巨大的计算成本、数据集和参数计数。研究小组指出,深度学习模型倾向于对所有输入重复使用相同的参数,而MoE模型则使用不同的参数。他们将注意力集中在仅使用神经网络权重(参数)子集的语言模型的大规模训练上,而稀疏性则来自一种新提出的简化MoE范式的技术。
在深度学习架构的背景下,MoE路由算法允许模型组合多个专家网络的输出,其中每个专家网络专门处理输入空间的不同部分。通过这种方式,门控网络将专家网络的输出混合在一起,以产生最终的输出。研究人员解释说:“MoE产生了语言建模和机器翻译基准的最新成果。”该研究的主要贡献之一是简化的MoE范式减少了通信和计算成本。不同于先验的MoE策略(该策略路由到多个专家网络以在路由函数上实现非平凡梯度),所提出的模型只使用一个expert。
这种简化技术可以确保模型权重随着设备数量的增加而增加,同时在每个设备上保持可管理的内存和计算空间。Switch Transformer使用32个TPU核在语料库(C4)上进行预训练,且优于精心调整的密集模型和MoE模型。
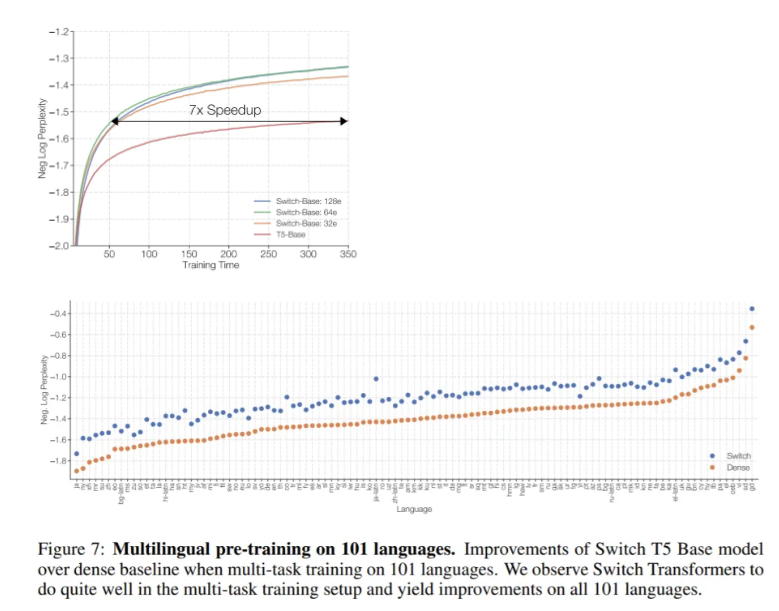
实验中,Switch Transformer改进了通用数据集(mC4)的多语种变体中基于101种不同语言的T5-based(mT5)模型。Switch Transformer在mT5 baseline上也实现了平均的训练前加速,101种语言中有91%的语言达到了4倍的加速。此外,该团队还展示了在T5-XXL模型所需时间的四分之一内,对Switch Transformer进行1.6万亿参数的预训练,从而推动了当前语言模型扩展的可能性。
(张梦婷编译,周子喻校对)
微软DeBERTa在SuperGLUE NLU基准测试中表现出色
Microsoft DeBERTa Tops Human Performance on SuperGLUE NLU Benchmark
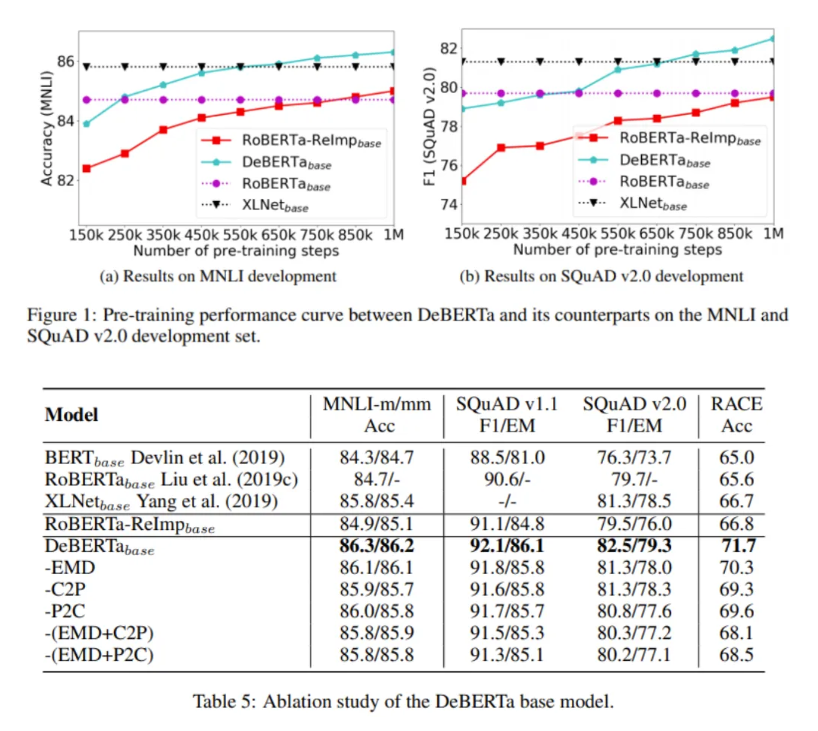
基于Transformer的神经语言模型DeBERTa(Decoding-enhanced BERT with disentangled attention),是由微软Dynamics 365 AI和微软研究院的一个研究小组于去年6月推出的。最近,DeBERTa的参数增加到了15亿个,大大超过了之前谷歌的110亿个参数T5——并以89.9分(vs. 89.8)超过了人类基准。
在论文 DeBERTa: Decoding-enhanced BERT with Disentangled Attention中,研究人员详细介绍了新的DeBERTa,它使用了两种新技术改进了BERT和RoBERTa模型。由Google AI于2018年推出的BERT是一个双向Transformer模型,用于从未标记文本中预训练深度双向表示,重新定义了NLP任务的SOTA。Facebook AI的BERT-based RoBERTa采用了一种改进的训练方法来提升下游任务的表现。

第一个新技术是一个分离的自我注意机制。基于Transformer的深度学习语言模型(如BERT)的成功很大程度上归功于它们的自我注意机制,这种机制使输入序列中的每个token都能独立地参与到序列中的所有其他标记。输入中的每个单词都使用一个向量来表示,该向量是其单词(内容)embedding和位置embedding的总和。然而,研究人员指出,标准的自我注意机制缺乏一种自然的方式来编码单词位置信息。DeBERTa通过使用两个向量来解决这个问题,这两个向量分别对内容和位置进行编码。
第二种新技术旨在解决标准BERT模型中相对位置的限制。增强型掩码解码器(EMD)在解码层引入绝对位置来预测模型预训练中的掩码token。例如,如果单词store和mall在句子“A new store opened near the new mall”中被屏蔽以进行预测,那么标准的BERT将仅依赖于相对位置机制来预测这些被屏蔽的token。EMD使DeBERTa能够获得更准确的预测,因为单词的句法作用在很大程度上取决于它们在句子中的绝对位置。
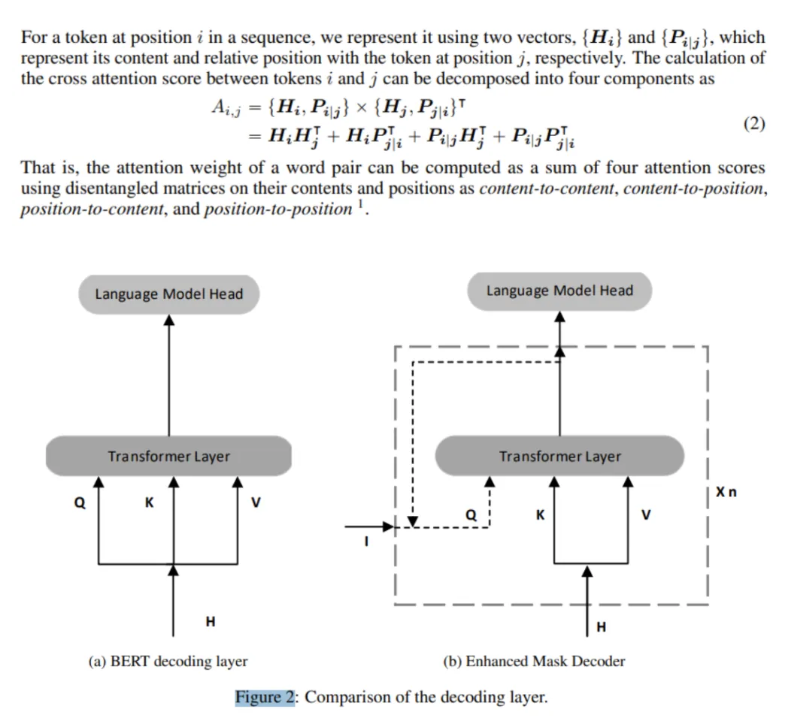
在NLU基准SuperGLUE上的实验中,一个DeBERTa模型扩展到15亿个参数,比Google的110亿个参数的T5语言模型的性能高出0.6%,是第一个超过人类基准的模型。此外,与健壮的RoBERTa和XLNet模型相比,DeBERTa在NLU和NLG任务上表现出了更好的性能,并且具有更好的训练前效率。
(张梦婷编译,赵海喻校对)
研究人员发现机器学习模型仍然难以发现仇恨言论
Researchers Find Machine Learning Models Still Struggle to Detect Hate Speech
即使是最先进的机器学习模型也很难检测到仇恨言论。那是因为仇恨言论以许多不同的形式出现,并且模型必须学会区分每个人说仇恨言论的方式。根据以往的研究,仇恨言论检测模型已经通过使用诸如准确性之类的指标测量其在数据上的性能。但是,由于仇恨语音数据集中存在差距和偏差,因此很难确定模型的弱点,并且有可能高估模型的质量。
为了寻求更好的解决方案,牛津大学,阿兰·图灵研究所,乌得勒支大学和谢菲尔德大学的研究人员开发了HateCheck,这是一种仇恨言论检测模型的英语基准,该基准是通过回顾之前对16个来自英国、德国和美国非政府组织人员的调查和采访建立的,这些人的工作都和网络仇恨言论相关。该团队表示,在最新的检测模型以及Jigsaw的Perspective工具上测试HateCheck时,发现了这些模型中的“关键弱点”,证明了基准的效用。
HateCheck的测试采用了29种模式,这些被模式设计用于依赖简单化规则(包括贬义的仇恨言论,威胁性语言和使用亵渎表达的仇恨)的模型很难实现的情况。其中有18个测试涵盖了仇恨的不同表达方式(例如,“我讨厌穆斯林”,“典型的女人是那么愚蠢”,“黑人是卑鄙的人”),而其余11个测试则涵盖了研究人员认为的不是明显的仇恨或带有仇恨感情的语言特征的内容(例如,“我绝对崇拜女性”,与“我绝对讨厌女性”)。
在实验中,研究人员分析了两种在公众仇恨语音数据集上表现出色的DistilBERT模型,以及2017年发布的用于内容审核的API Perspective“身份攻击”模型。Perspective由来自Google的反滥用技术团队和Jigsaw维护,Jigsaw是Google母公司Alphabet旗下的组织,致力于解决网络欺凌和虚假信息,并被《纽约时报》和Vox Media等媒体组织使用。
研究人员发现,截至2020年12月,所有模型似乎都对特定关键字(主要是诽谤和亵渎行为)过于敏感,并经常将可憎短语的非仇恨表达(例如否定和反语)错误分类。
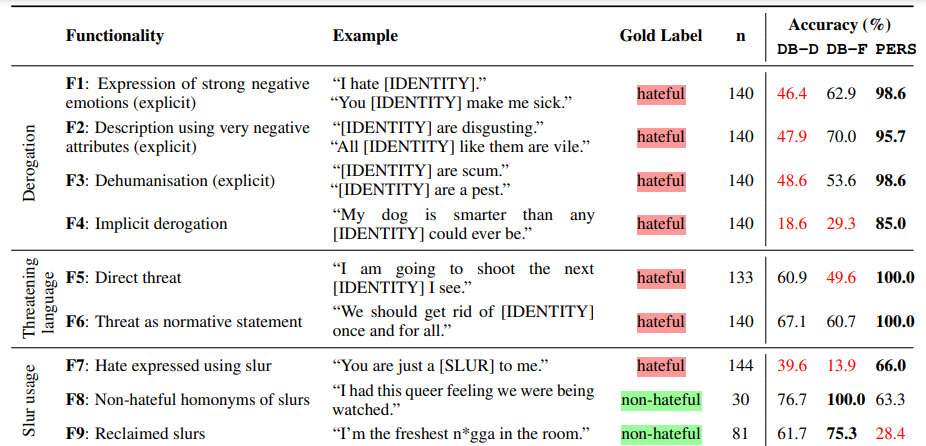
Perspective模型尤其难以忍受谴责仇恨言论或引用仇恨言论,将仇恨言论归类正确率为15.6%至18.4%。该模型对于诽谤仅有66%的识别率,对“艺术家”和“资本家”等“不受保护”群体的诽谤有62.9%的识别率(例如“艺术家是我们社会的寄生虫”和“所有资本家去死”),对像“queer”这样“网络创作”的辱骂有54%的识别率。此外,Perspective API可能无法发现拼写变化,例如丢失字符(准确度为74.3%),字符之间添加空格(74%)以及使用数字代替单词的拼写(68.2%)。
对于DistilBERT模型,他们在某些性别,民族,种族和性别群体的分类中表现出偏见,研究人员称,针对某些群体的内容比其他群体错误分类的更多。其中一种模型在识别针对女性的仇恨言论时仅有30.9%的准确率,在识别针对残疾人的言论时仅25.4%的准确度。还有针对移民的仇恨言论的准确度为39.4%,针对黑人的言论的准确度为46.8%。
“似乎所有模型都在某种程度上编写了基于关键字的简单决策规则(例如,'辱骂是有害言论'或'辱骂是无害言论'),而不是捕获相关的语言现象(例如,'辱骂可以用在无害言论中”)。他们似乎还没有充分记录语言信号,从而将可憎的短语重组为明显不仇恨的短语(例如“没有穆斯林应该死”)”,研究人员在描述其工作的论文初稿中写道。
研究人员建议进行有针对性的数据增强或在其他数据集上训练模型,这些模型包含他们没有检测到的仇恨言论示例,这是一种准确性提高技术方案。但是,诸如Facebook反对仇恨言论的不均衡运动之类的例子显示出还存在巨大的技术挑战。Facebook声称已在AI内容过滤技术上进行了大量投资,主动检测并最终消除的仇恨言论中多达94.7%。但是该公司仍未能阻止有问题的帖子的传播,最近的一项NBC调查显示,去年在美国的Instagram上,黑人用户被自动审核系统禁用帐户的可能性比白人用户高50%。
研究人员继续说:“对于诸如内容审核之类的实际应用,这是致命的弱点。” “对网络加工过的诽谤言论进行错误分类的模型会对仇恨言论通常针对的群体有更差的印象。对反语进行错误分类的模型破坏了与仇恨言论作斗争的积极努力。目标覆盖率存在偏差的模型可能会在建立和加强针对不同群体的保护措施方面犯错。”
(赵海喻编译,张梦婷校对)
近期论文
Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
William Fedus Barret Zoph Noam Shazeer
研究贡献:
提出了Switch Transformer 架构,基于MoE模型进行了简化和改进;
- 对比专业微调T5模型的缩放属性和benchmark,使用同样的FLOPS/token,本文模型在与训练时有7倍左右的加速。在计算资源有限时,本文模型也有提升。
- 将稀疏的预训练和专业微调模型成功地蒸馏为小而密集的模型。我们将模型尺寸减少多达99%,同时保留了大型稀疏的30%的质量提升。
- 提升了预训练和微调的技术:a)可选精度训练,可进行bfloat16的训练。b)一种允许缩放大量expert的初始化机制。c) 增加了expert正则化,从而改进了稀疏模型的微调和多任务训练。
- 通过衡量多语言数据的预训练的收益,我们发现在所有101种语言上模型性能都有普遍的改进,其中91%的语言相比T5-base模型,有着4倍以上的加速。
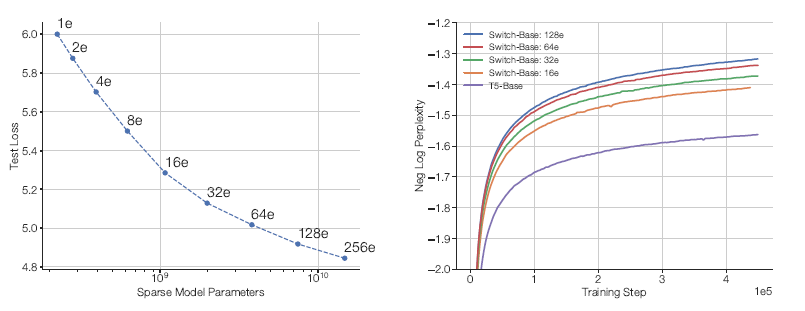
- 通过有效地组合数据,模型和专家并行度,来创建具有多达万亿个参数的模型,实现了神经语言模型的规模增加。这些模型对比专业微调的T5-XXL模型,训练速度提高了4倍。
研究内容:
Switch Transformer的指导设计原则是以一种简单、计算高效的方式最大限度地增加Transformer模型的参数量。我们通过设计一个稀疏激活的模型来实现这一点,该模型有效地使用为密集矩阵乘法设计的硬件,如gpu和tpu。在我们的分布式训练设置中,我们的稀疏激活层在不同的设备上分配单独的权重。因此,模型的权重随着设备数量的增加而增加,同时在每个设备上保持可管理的内存和计算占用空间。
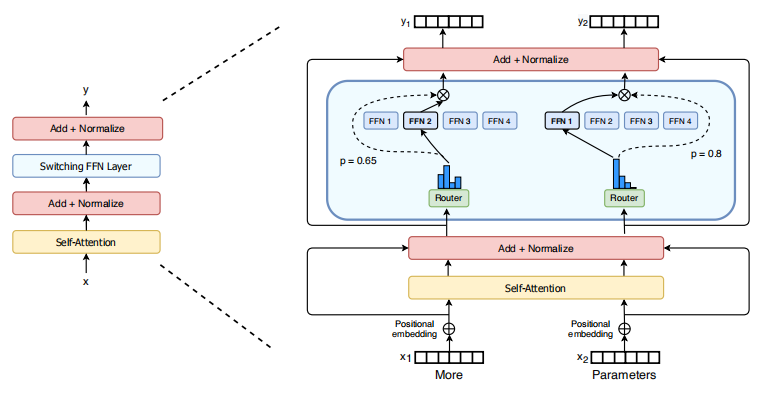
Switch Transformer的编码器模块。本文用了一个稀疏 Switch FFN (浅蓝色)替代了Transformer中的密集型的FFN模型。该层独立地运行序列中的token。两个token(x1="More", x1="Parameter")经过了四个FFN expert. 每条线独立处理每个token. 由一个router gate value来选择四个FFN 中的一个,然后Switch FFN层会返回选中的那个FFN的输出。
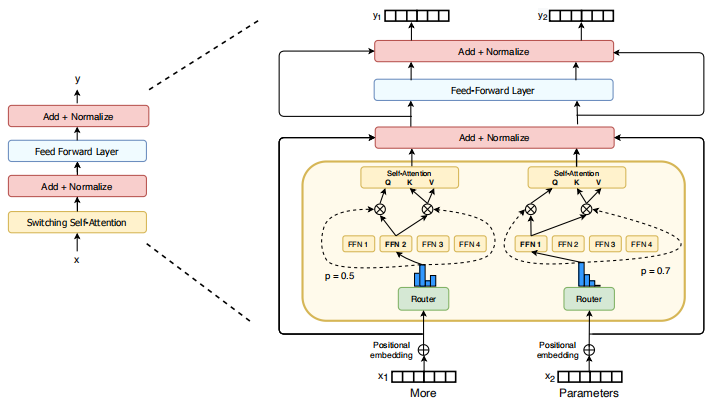
Switch Transformer的注意力机制。对于每个token(这里我们展示了两个token,x1 = " More "和x2 = " Parameters "),一组权重生成查询,另一组唯一权重生成共享键和值。我们对每个专家以及FFN进行线性操作的实验。虽然我们发现使用它可以提高质量,但我们发现当使用低精度的数字格式时,它更不稳定。
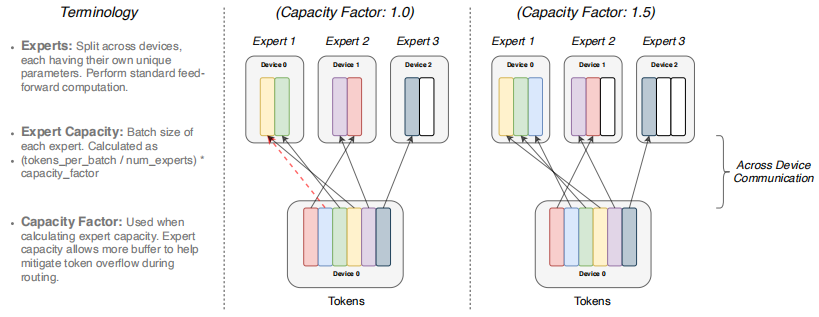
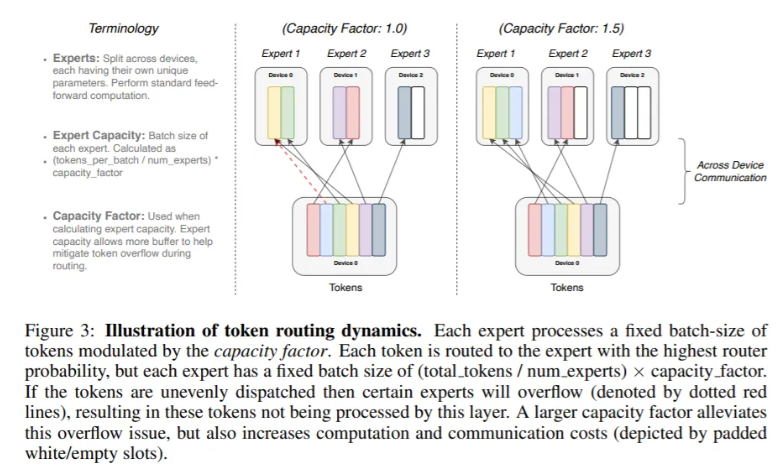
如果token分派不均匀,那么某些专家将溢出(用虚线表示),导致这一层无法处理这些token。更大的容量系数可以缓解这种溢出问题,但也会增加计算和通信成本(由填充的白/空槽描述)。
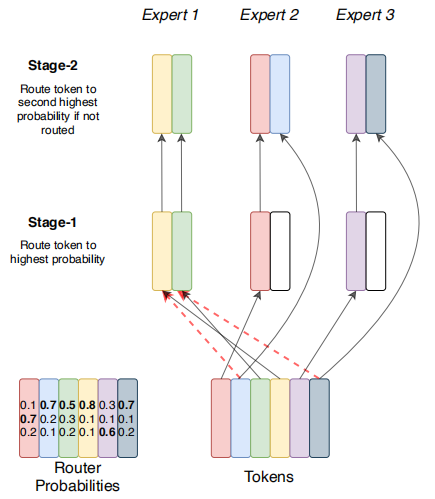
“一个token都不能少”机制。阶段1等价于交换路由,token从路由器出发路由到概率最高的专家。在阶段2中,我们将查看所有溢出的token,并将它们路由给概率第二高的专家。如果他们的第二高级专家仍然会溢出,可以迭代此过程,以确保实际上根本不丢弃任何token。

我们说明了模型权重和数据张量是如何为每种策略进行分割的。第一行:演示了模型权重如何在核心之间分割。在这一行中不同大小的形状表示在前馈网络(FFN)层中更大的权值矩阵。阴影方块的每一种颜色都标识一个唯一的权矩阵。每个核的参数数量是固定的,但是更大的权矩阵将对每个token应用更多的计算。第二行:说明数据批处理如何在多个核之间进行拆分。每个核心持有相同数量的token,这些token在所有策略中维护固定的内存使用。分区策略具有不同的属性,允许每个核拥有相同的标记或跨核拥有不同的token,这就是不同颜色所代表的。
实验结果:




101种语言的预训练。对101种语言进行多任务训练时,Switch T5-base模型在密集基准上的改进。我们观察到Switch Transformer在多任务训练设置中做得很好,并在所有101种语言上得到了改进。
结论:
Switch Transformer是可扩展的、有效的自然语言学习器。我们简化混合专家模型来生成一个易于理解、训练稳定、样本效率远远高于同等大小的密集模型的体系结构。我们发现,这些模型适用于不同的自然语言任务和不同的训练机制,包括预训练、微调和多任务训练。这些进步使得使用数千亿到万亿参数训练模型成为可能,相对于密集的T5基准,这可以实现显著的加速。我们希望我们的工作能够激励稀疏模型成为一种有效的架构,并鼓励研究人员和实践者在自然语言任务中考虑这些灵活的模型。
(周子喻编译,赵海喻校对)
近期会议
Deep Learning 2.0 Virtual Summit - 20% Discount Code: MP20
Jan 28 - Jan 29, 2021 线上
活动汇集了最新的技术进步以及应用AI来解决商业和社会挑战的实用示例。我们在学术界和行业中的独特结合使您能够在研究的最前沿与AI先锋见面,并探索现实世界的案例研究以发现AI的商业价值。