文本挖掘与机器学习跟踪扫描动态快报(2020.06)
实时跟踪、关注文本挖掘与机器学习领域最新研究动态
深度观察
高效PyTorch——消除瓶颈
PyTorch是用于研究和生产领域的出色工具,斯坦福大学、Udacity、SalelsForce、Tesla均采用这种深度学习框架就清楚地表明了这一点。然而,每种工具都需要投入时间来掌握技能,以便以最大的效率使用它。
第一部分给出识别和消除I/O和CPU瓶颈的一般技巧;第二部分将展示一些关于有效张量运算的技巧;第三部分是高效模型调试技术。
命令行工具,如nvidia-smi、htop、iotop、nvtop、py-spy、strace等,应该被经常使用。你的训练pipeline是否受CPU限制?IO绑定?GPU绑定?这些工具将帮助你找到答案。
1.数据预处理
几乎所有的训练pipeline都是从Dataset类开始的。它负责提供数据样本。此处可能会发生任何必要的数据转换和扩充。简言之,Dataset报告数据的大小并按给定的索引返回数据样本。
如果您使用的是类似图像的数据(2D、3D扫描),磁盘I/O可能会成为瓶颈。要获得原始像素数据,您的代码需要从磁盘读取数据并将图像解码到内存中。每个任务都很快,但是当你需要尽可能快地处理成千上万的任务时,这可能会成为一个挑战。像NVidia Dali这样的库提供了GPU加速的JPEG解码。如果您在数据处理管道中遇到IO瓶颈,这绝对值得一试。
还有一个选择。SSD磁盘的访问时间约为0.08–0.16毫秒。RAM的访问时间为纳秒。我们可以将数据直接放入内存!
如果您有足够的内存来加载和保存所有的训练数据,这是从pipeline中排除最慢的数据检索步骤的最简便方法。
该建议特别适用于云实例,比如亚马逊的p3.8xlarge。该实例具有EBS磁盘,默认设置下它的性能非常有限。但是,这个实例配备了惊人的248GB内存。这足以将所有ImageNet数据集保存在内存中!以下是实现这一目标的方法:
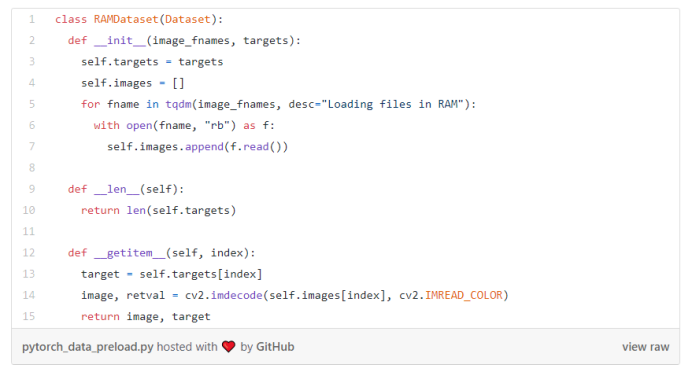
我有一台配备4x1080Ti GPUs的家用电脑。我曾使用具有四个NVidia Tesla V100的p3.8xlarge实例,并将我的训练代码移到了那里。鉴于事实,V100比我以前的1080Ti更新和更快,我预计训练速度会提高15-30%。但事实上,每个时期的训练时间都增加了,故而我们需要注意基础架构和环境的细微差别,而不仅仅是CPU和GPU的速度。
根据您的方案,您可以将每个文件的二进制内容保持不变,并在运行中对其进行解码,或者对未压缩的图像进行解码,而保留原始像素。
如果不对模型、超参数、数据集等进行任何更改,则此建议仅侧重于训练速度。您可以拥有一个神奇的命令行参数(magic switch),当指定该参数时,它将训练一些合理数量的数据样本。使用此功能,您始终可以快速分析pipeline:

如果您要训练由2048x2048张图片制成的512x512尺寸调整后的图像,请事先调整尺寸。如果使用灰度图像作为模型的输入,请离线进行颜色转换。如果您要使用NLP,请事先进行标记化,然后保存到磁盘。在训练过程中,反复重复相同的操作是没有意义的。在进行渐进式学习的情况下,您可以保存训练数据的多种分辨率,这仍然比在线调整为目标分辨率更快。
对于表格数据,请考虑在创建数据集时将pd.DataFrame对象转换为PyTorch张量。
PyTorch使用DataLoader类来简化用于训练模型的批处理过程。为了加快速度,它可以使用python中的多处理并行执行。大多数情况下,开箱即用效果很好。有几件事要记住:
每个进程生成一批数据,这些批数据通过互斥同步提供给主进程。如果有N个工作程序,那么脚本将需要N倍的内存来将这些数据存储在系统内存中。您到底需要多少内存?让我们计算一下:
1.假设我们为批处理大小为32的城市景观和大小为512x512x3(高度、宽度、通道)的RGB图像训练图像分割模型。我们在CPU端进行图像规范化。在这种情况下,我们的最终图像张量将是512*512*3*sizeof(float32)=3,145,728字节。乘以批处理大小可得到100,663,296字节或大约100MB。
2.除了图像,我们还需要提供真实的masks。它们各自的大小为(默认情况下,掩码的类型为long,即8字节)即512*512*1*8*32=67,108,864或大约67MB。
3.因此,一批数据所需的总内存为167 Mb。如果我们有8个工作程序,则所需的内存总量将是167 Mb*8=1,336 Mb。
听起来还不错吧?当您的硬件设置能够处理超过8个工作程序所能提供的批处理时,就会出现问题。我们可以把64个工作程序放进去,但这至少会消耗11GB的内存。
如果您的数据是3D-volumetric扫描,情况会变得更糟;在这种情况下,即使是单通道卷512x512x512的一个样本也将占用134 MB,而对于32批处理大小,它将为4.2 GB,如果有8个工作线程,则只需要32 GB内存。
有部分解决该问题的方案—您可以尽可能减少输入数据的通道深度:
1.将RGB图像保持在每个通道深度8位。在GPU上可以很容易地实现图像的浮点转换和规范化。
2.在数据集中改用uint8或uint16数据类型代替long数据类型。

这样可以大大减少RAM需求。对于上面的示例,内存高效数据表示的内存使用量为每批33 MB,而之前为167 MB。减少了5倍!当然,这需要在模型本身中执行额外的步骤,以便将数据规范化/转换为适当的数据类型。然而,张量越小,CPU到GPU的传输时间就越短。
应该合理地选择DataLoader的工作程序数量。您应该检查您的CPU和IO系统的运行速度,拥有多少内存以及GPU处理该数据的速度。
2.多GPU训练与推理
神经网络模型变得越来越大。当今的趋势是使用多个GPU来增加训练时间,它通常需要通过更大的批量来提高模型性能。PyTorch具有使用几行代码即可运行多GPU的所有功能。然而,有些警告乍一看并不明显。

使用多GPU的最简单方法是将模型包装在nn.DataParallel类中。而且在大多数情况下——除非你训练了一些图像分割模型(或任何其他产生大张量作为输出的模型)——它工作得很好。在前传结束时,nn.DataParallel将收集主GPU所有GPU输出,以反向运行输出并进行梯度更新。
有两个问题:
1.GPU负载不平衡。
2.在主GPU上采集需要额外的视频内存。
首先,只有主GPU在进行损耗计算、后向传递和梯度步进,而其他GPU在60℃下冷却等待下一批数据。
其次,在主GPU上收集所有输出所需的额外内存通常会迫使您将批处理大小减少一些。问题是,nn.DataParallel将批处理均匀地分配给多个GPU。假设您有4个GPU,总批量大小为32。然后每个GPU将得到它的8个样本块。但问题是,虽然所有非主GPU都可以轻松地将这些批处理放入其相应的VRAM中,但主GPU必须分配额外的空间来容纳批处理大小为32的所有其他卡的输出。
对于这种不均衡的GPU利用率,存在两种解决方案:
1.继续使用nn.DataParalleland并计算训练过程中前传的损失。在这种情况下,您不会将密集预测掩码返回到主GPU,而只返回单个标量损失。
2.使用分布式训练,也称为nn.DistributedDataParallel。借助于分布式训练,您可以从上面解决这两个问题,并且可以欣赏所有GPU的100%负载。
如果您想了解有关多GPU训练的更多信息,并深入了解每种方法的优缺点,请查看以下精彩文章以了解更多信息:
training-larger-batches-practical-tips-on-1-gpu-multi-gpu-distributed-setups
它将节省多少时间取决于您的方案,但我观察到在4x1080Ti上训练图像分类pipeline时大约减少了20%的时间。
您也可以使用nn.DataParallel和nn.DistributedDataParallel进行推断。
3.关于自定义损失函数
编写自定义损失函数是一项有趣且令人兴奋的练习。我建议大家不时地尝试一下。在实现具有复杂逻辑的损失函数时,有一件事您必须记住:它们都在CUDA上运行,你有责任编写高效CUDA的代码。高效CUDA意味着“没有python控制流”。在CPU和GPU之间来回访问GPU张量的各个值可以完成任务,但是性能会很差。
前段时间,我实现了一个自定义的余弦嵌入损失函数,用于《通过余弦嵌入和循环沙漏网络对单元实例进行分段和跟踪》一文中的实例分割。它在文本形式上非常简单,但实现起来有点复杂。
我编写的第一个简单的实现(除了bug)花了几分钟(!)来计算单个批次的损失值。为了剖析CUDA瓶颈,PyTorch提供了一个非常方便的内置分析器。它使用起来非常简单,并且为您提供了解决代码瓶颈的所有信息:

在对最初的实现进行性能分析后,我能够将实现速度提高100倍。有关在PyTorch中编写高效张量表达式的更多信息,请参见“Efficient PyTorch第2部分”。
4.时间vs金钱
有时值得投资于功能更强大的硬件,而不是优化代码。软件优化始终是高风险的过程,其结果是不确定的。升级CPU,RAM,GPU或一起升级可能会更有效。金钱和工程时间都是资源,两者的合理利用是成功的关键。
5.结论
充分利用日常工具是提高熟练度的关键。尽量不要走捷径,如果您不清楚的话,一定要深入挖掘,总是有机会获得新知识。问问自己或您的伙伴——“如何改进我的代码?”。我坚信这种完美的感觉与计算机工程师的其他技能一样重要。
(张梦婷编译,李朝安校对)
研究动态
从文本到小猫:OpenAI的GPT语言模型处理图像生成
from Texts to Kitties Openais Gpt Language Model Tackles Image Generation
OpenAI以其1750亿个参数的GPT-3语言模型惊艳全球仅仅三周。现在,这家总部位于旧金山的AI公司在社交媒体上引发了一场新的轰动——提出基于像素序列训练的大型Transformer语言模型可以在不使用标签的情况下生成连贯的图像。这篇新论文来自OpenAI研究团队,其中包括创始人兼首席科学家Ilya Sutskever。
自然语言处理(NLP)中无监督学习方法和Transformer模型的成功启发了OpenAI研究人员探索这一新方向。类似的模型也可以学习图像的有用表示吗?
OpenAI在一篇博客文章中解释道:“就像一个经过语言训练的大型Transformer模型可以通过建立样本质量和图像分类精度之间的相关性来生成连贯的文本一样,我们证明了我们的最佳生成模型也包含了在无监督环境下与顶级卷积网络相竞争的特征。”无监督学习通常是指不需要人工标注数据的模型训练。

AI先驱和图灵奖获得者Geoffrey Hinton发推文说,“无监督学习表示法已经开始运作良好,而无需重建。”在Hinton的论文A Simple Framework for Contrastive Learning of Visual Representations中,通过简单框架SimCLR学习的自我监督表示形式训练的线性分类器在图像识别方面实现了显着的性能飞跃。

OpenAI研究人员从诸如BERT和GPT-2这样的Transfoemer模型中学到的重要见解之一是,它们是领域不可知的,这意味着它们可以直接应用于任何形式的一维序列。研究小组决定将原始图像展开为低分辨率,并将其重塑为类似文本的长像素序列,否则展开的序列将太大而无法处理。“如果我们天真地在2242×3的序列上训练一个Transformer,我们的attention logits将比语言模型中使用的要大数万倍,甚至单层也不适用于GPU。
该团队训练了一个模型,该模型使用与GPT-2语言中相同的Transformer结构,称为iGPT,它学习了通过线性探测、微调和低数据分类测量的强图像表示。该方法包括一个没有标签的预训练阶段,然后是一个微调步骤。该团队利用了两个预训练目标中的一个来实现像素预测:自回归(也是GPT-2预训练方法)和BERT。一旦目标了解了表示,团队便使用线性探针或微调来评估它们。
在CIFAR-10上进行的实验中,iGPT-L模型在线性探针的作用下达到了96.3%的精度,优于有监督的Wide ResNet。通过完全微调,它还达到了99.0%的准确率,与顶级监督预训练模型相匹配。在ImageNet上,ImageNet和web图像混合训练的更大型号iGPT-XL可与自监督基准相当,精度达到72.0%。
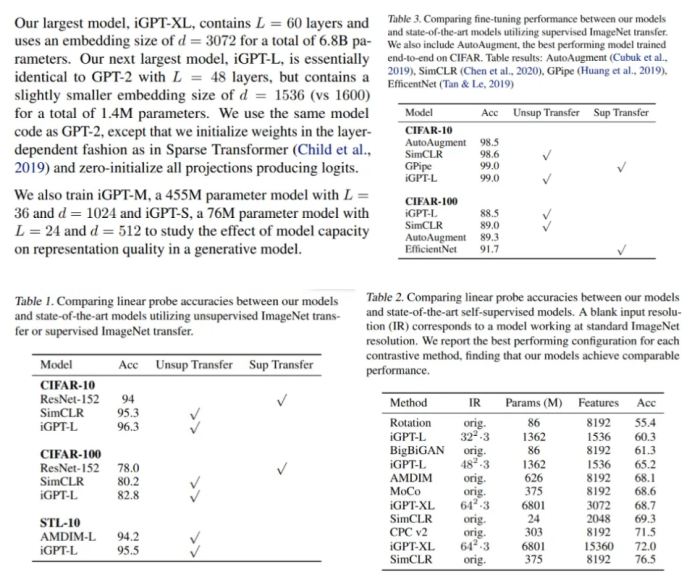
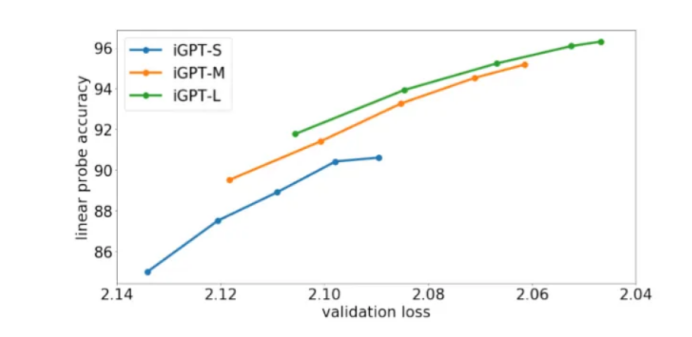
即使没有任何人工标记的数据的指导,iGPT也能产生广泛的连贯图像。但研究人员指出,这种性能要付出高昂的代价:“iGPT-L的训练时间约为2500 V100天,而性能类似的MoCo模型的训练时间则约为70 V100天。”
(张梦婷编译,李朝安校对)
OpenAI发布著名文本生成模型的商业版本
Openai to Release Commercial Version of Famous Text Generation Model
人工智能研究实验室OpenAI的著名的文本生成工具GPT-3现在可供购买,这是机器学习非营利组织生产的首个商业产品。
去年2月,OpenAI将其文本生成模型GPT-2开源。当提供简短提示时,GPT-2就能够生成连贯的文本,该模型被认为在自然语言处理和人工智能领域里是非常重要的。实际上,OpenAI最初拒绝发布GPT-2模型,称它过于危险,担心会被滥用。但是,经过将该模型的一个版本在一段时间内可供大家使用后,该组织报告说他们没有看到任何恶意使用的证据,因此决定将模型开源。就在最近,OpenAI宣布了名为GPT-3的GPT-2的后续模型。
GPT-3比其前任产品大100倍左右,作为商业产品提供。GPT-2模型包含约15亿个参数,而GPT-3模型包含约1,750亿个参数。GPT系列模型的复杂性和可靠性使这些模型逐渐成为涉及文本的机器学习项目的标准,就像卷积神经网络已成为图像领域相关项目的默认模型一样。与文本相关的项目也越来越多地使用GPT-2,也许很快就会使用GPT-3。
正如The Verge报道的那样,OpenAI似乎是希望通过使其GPT-3模型商业化来推动GPT标准的采用。目前,仅允许受邀请访问GPT-3的API。但是,这可能只是试运行,GPT-3可能会在不久的将来被更广泛地提供。OpenAI表示将对客户的模型进行审查,以防止将技术滥用于垃圾邮件,制造错误信息或骚扰等不道德用途。
目前尚不清楚使用者打算如何使用GPT-3。这可以说是因为GPT-3非常灵活并且具有许多潜在的应用。基于GPT的模型可以根据需要进行微调,以生成适合于特定任务的文本。该模型能够适应各种提示和输入样式,这意味着它可以用于创建文本摘要工具,回答简单问题或充当复杂聊天机器人的基础。正如OpenAI首席技术官Greg Brockman向Wired解释的那样:“最大的思想转变是,与格式化机器相比,这更像是与人类交谈。”“您给它一些问题和答案,它将马上处于问答模式。”
尚不清楚GPT-3衍生的商业模型的可靠性如何。虽然GPT-3可以生成语法正确,听起来自然的语言,但它对现实世界以及概念之间的关系缺乏直观的了解。对于保存上下文特别重要的应用(例如为客户设计的聊天机器人),这可能会被证明是有问题的。
Hugging Face的研究工程师Joe Davison向Digital Trends表示,GPT-3的庞大规模可能会限制其潜在用途。Davison认为,尽管OpenAI在文本生成方面取得了显著进步,它表明创建通用模型可以减少对特定任务数据的需求,但利用GPT-3所需的计算资源对于许多公司来说都不切实际。
OpenAI以前是一家非营利性企业,但自2019年以来,该实验室已转变为营利性模式。GPT-3是该实验室生产的第一款主要的商业产品,转用营利性模式是否会改变OpenAI的研究重点还有待观察。
(王宇飞编译,李朝安校对)
项目工具
卡内基梅隆工具自动把数学变成图像
卡内基梅隆大学发明的一种新工具,使得任何人都可以把数学的抽象概念转化为精美而有启发性的插图。该工具使用户只需键入一个普通的数学表达式并让软件绘制图表即可。与绘图计算器不同,这些表达式不限于基本函数,但可以是来自任何领数学域的复杂关系。
研究人员以著名的数学家和物理学家Roger Penrose的名字命名为Penrose,他以使用图表和其他图形来传达复杂的数学和科学思想而闻名。计算机科学和机器人学助理教授 Keenan Crane表示,一些数学家擅长手工绘制美丽图表,但一旦黑板被擦除,它们就会消失。他们想让所有人都能拥有这种表达能力。
图表在技术交流中经常没有得到充分利用,因为产生高质量的数字插图超出了许多研究人员的技能范围,并且需要大量乏味的工作。Penrose通过使绘图专家对他们在系统中的工作方式进行编码来解决这些挑战。然后其他用户可以使用熟悉的数学语言访问此功能,从而使计算机完成大部分繁重的工作。研究人员将在SIGGRAPH 2020计算机图形学和交互技术会议上介绍Penrose,会议由于COVID-19将于今年7月举行。
计算机科学系的博士生Katherine Ye表示他们系统的秘诀是让人们能够轻松地向计算机“解释”该翻译过程,这样计算机就可以完成所有实际制作图片的艰苦工作。一旦计算机了解到用户希望如何看到可视化的数学对象(例如,用一个小箭头表示的向量,或用一个点表示的点),它就会使用这些规则绘制几个候选图。然后,用户可以从可能性库中选择并编辑所需的图表。
Crane提到研究小组为此开发了一种特殊的编程语言,数学家应该不会有任何学习上的困难。他解释道,数学家会对符号非常挑剔,所以应该让他们自己定义想要的符号,以便他们能够自然地表达自己。
“我们的愿景是能够从图书馆中清除一本旧的数学教科书,将其放入计算机中,并获得精美的插图书,使更多的人理解。” Crane指出,Penrose是朝着这一目标迈出的第一步。
(张梦婷编译,李朝安校对)
近期论文
PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization
Jingqing Zhang Yao Zhao Mohammad Saleh Peter J.Liu
背景
在先前的工作中,预训练模型的目标绝大多数是通用性的(如BERT的MLM和NSP),这些目标对下游任务的影响并不可知。如果预训练的目标与下游任务联系紧密,是否可以实现更好的性能呢?
创新点:
文章提出了一种新的预训练目标,Gap Sentences Generation(GSG)。 作者认为,预训练目标与下游任务越相似,性能会越好,所以预训练目标应涉及从输入文档中生成类似摘要的文本。为了能利用大量的文本语料库进行预训练,作者设计了在缺少摘要的情况下的预训练目标。具体做法为:从文档中选择并掩盖了一整个句子(将句子替换为[MASK1]),将空缺句作为一个伪摘要,模型的任务是恢复它们。为了更加接近摘要,作者选择对文档重要的句子进行遮盖。(通过计算一个句子与文档其余部分的ROUGE1-F1得到)
模型结构:
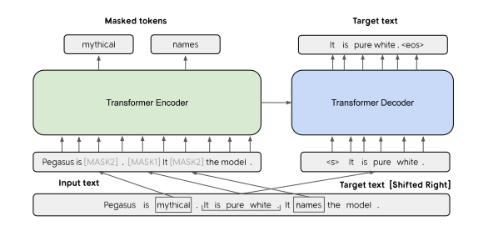
PEGASUS是一个标准的使用transformer的编码器-解码器模型,使用GSG和MLM同时作为预训练目标。上例本来有三句话,用[MASK1]掩盖一个句子,用作目标生成文本(GSG)。其他两个句子仍然在输入中,但被[MASK2]随机掩盖掉一些token。(文章没有在PEGASUS-LARGE中使用MLM)
具体实验:
预训练语料:
- C4:350M网页中的文本(750GB)。
- Huge News:新闻和类似新闻的网站中收集的1.5B文章,时间范围为2013-2019年(3.8 TB)。
下游任务:
作者在12个生成式摘要数据集上对模型进行了微调,包括新闻、科技文献、专利、短篇小说、电子邮件、法律文件和使用说明。
实验结果:
与PEGASUS-BASE相比,大型模型PEGASUS-LARGE具有更大的隐藏大小(H:768→1024,F:3072→4096,A:12→16),层数(L:12→16),并且遍历了更多数据,因为批量较大(B:256→8192)(相同的预训练步骤数,500k)。
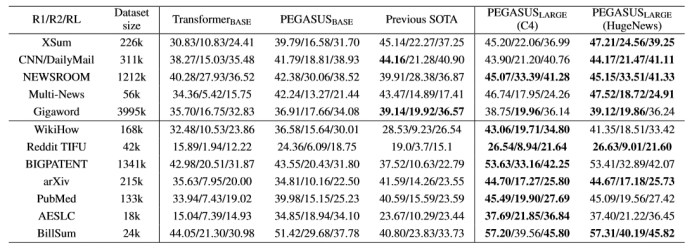
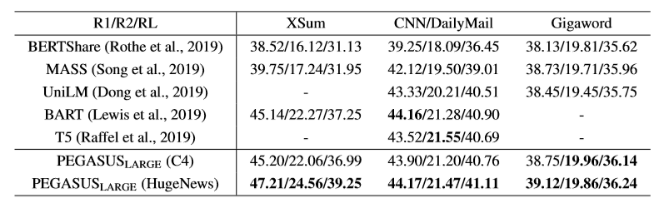
上表显示了PEGASUS-BASE和PEGASUS-LARGE在下游数据集上的性能改进。PEGASUS-BASE在许多数据集上都超过了当前的最新水平,但PEGASUS-LARGE在所有下游数据集上使用HugeNews的结果都优于最新数据,尽管C4在WikiHow上的表现更好。
(王宇飞编译,李朝安校对)
近期会议
IFLA WLIC 2020
Aug15 – Aug21, 2020 爱尔兰 都柏林
https://2020.ifla.org/conference-programme/calls-for-papers/
国际图书馆协会联合会(International Federation of Library Associations and Institutions)成立于1927年,是联合各国图书馆协会、学会共同组成的一个机构,是世界图书馆界最具权威、最有影响的非政府的专业性国际组织,也是联合国教科文组织“A 级”顾问机构,国际科学联合会理事会准会员,世界知识产权组织观察员,协会总部设在荷兰海牙。
ICADL 2020
Nov30 – Dec1, 2020 线上
https://2020.ifla.org/conference-programme/calls-for-papers/
亚太数字图书馆国际会议(ICADL)于1998年在香港开始举办,被评为“核心A”会议。在过去的几十年中,许多新兴的研究领域,如数字人文科学、开放科学、社会信息学,都起源于数字图书馆,ICADL将继续致力于为学者们提供一个就新兴、现存领域进行讨论、交流的平台。第22届“亚太数字图书馆国际会议”将采取线上形式,论文集将由Springer出版,并由Scopus索引。今年提交论文形式有三种:长文,短文和实践性论文(practitioners papers)。