文本挖掘与机器学习跟踪扫描动态快报(2020.04)
实时跟踪、关注文本挖掘与机器学习领域最新研究动态
深度观察
NLP领域自适应与深度学习视觉
1.引言
就个人而言,我对自然语言处理的兴趣远胜于对视觉的兴趣,但两者是相辅相成的,经常会一起讨论。在这篇文章中,我将说明如何将具有领域自适应的视觉、图像分割(即用游戏图像训练并转换到现实生活中的图像)转换为NLP以解决Question-Answering任务。
2.内容
什么是Question-Answering?例如,给定问题和段落(例如维基百科的文章),机器能否从段落中推断出答案?
什么是领域自适应,为什么它有用?
什么是领域自适应,为什么它有用?
举例而言,有各种Question-Answering数据集,比如SQuAD,它是通用数据集。如果我们想建立一个特定领域(比如金融、医学和法律)的搜索引擎,该怎么办?我们并不总是能够拥有丰富的特定领域的数据集,但在没有的情况下,我们可以依赖领域自适应模型来传递样式。
举例而言,通用数据集可能包含以下问题:巴黎圣母院有几所大学?(摘自SQuAD)
一个更具体的领域问题是:哪个基因通常与严重的先天性和周期性中性粒细胞减少有关? (摘自BioASQ)
3.NLP领域自适应(Domain Adaption)
所以现在的问题是,如何才能做到?在我们谈细节之前,请允许我向您展示文章的主要内容。稍后我将详细讨论如何设计下面的模型架构。
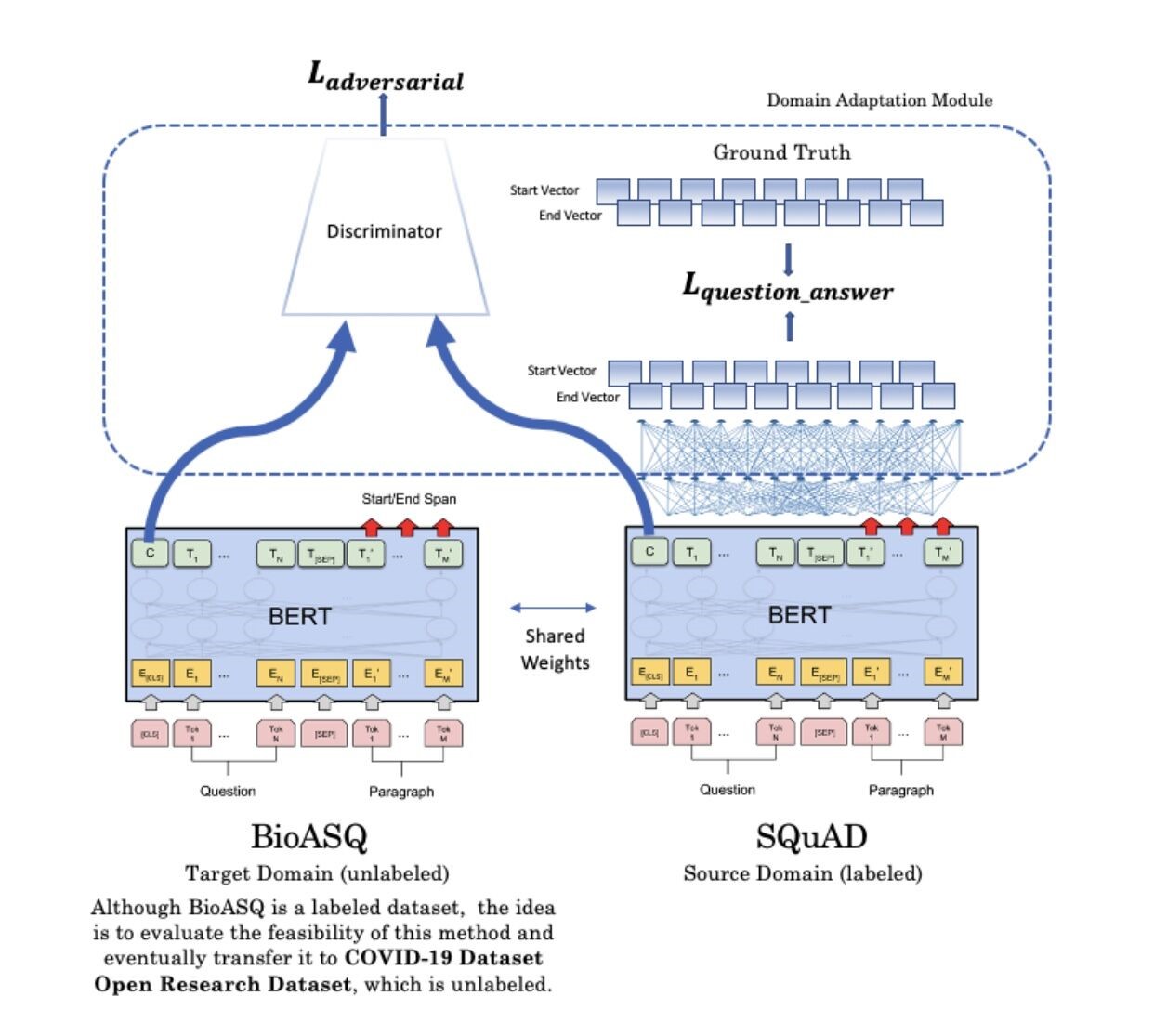
该模型可以使用任何一个语言模型,例如ALBERT、distilBERT、RoBERTa等等。出于本实验的目的,我坚持经典的BERT。同时,该模型利用了生成性对抗网络的思想进行域迁移。
4.生成对抗网络(GANs,Generative Adversarial Network)
该模型可以使用任何一个语言模型,例如ALBERT、distilBERT、RoBERTa等等。出于本实验的目的,我坚持经典的BERT。同时,该模型利用了生成性对抗网络的思想进行域迁移。
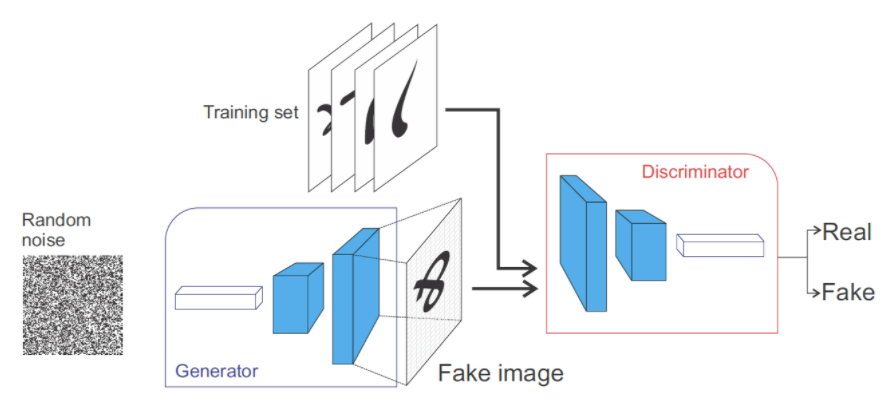
GANs最近非常令人兴奋,它以博弈论为模型。在博弈论中,一个玩家试图使自己的回报最大化,而其对手则试图使其利益最小化。这个两人博弈是使域迁移成为可能的基本概念。

生成器是生成图像(或句子)以欺骗对手生成的内容是真实的玩家之一。鉴别器旨在辨别内容是否真实。这就形成了一个循环,让他们都能从头到尾一起接受训练。
5.这个想法从何而来
在本文的开头,我提到了我刚刚完成的一个带有域自适应的图像分割任务。这是什么意思?基本上,模型是用一个带有标签的数据集和另一个没有标签的数据集训练的,目的是传递样式。
这个想法的要点来自这篇论文。作者介绍了利用对抗性实例进行领域迁移的思想。他还利用多层次的特征来构建不同的鉴别器。
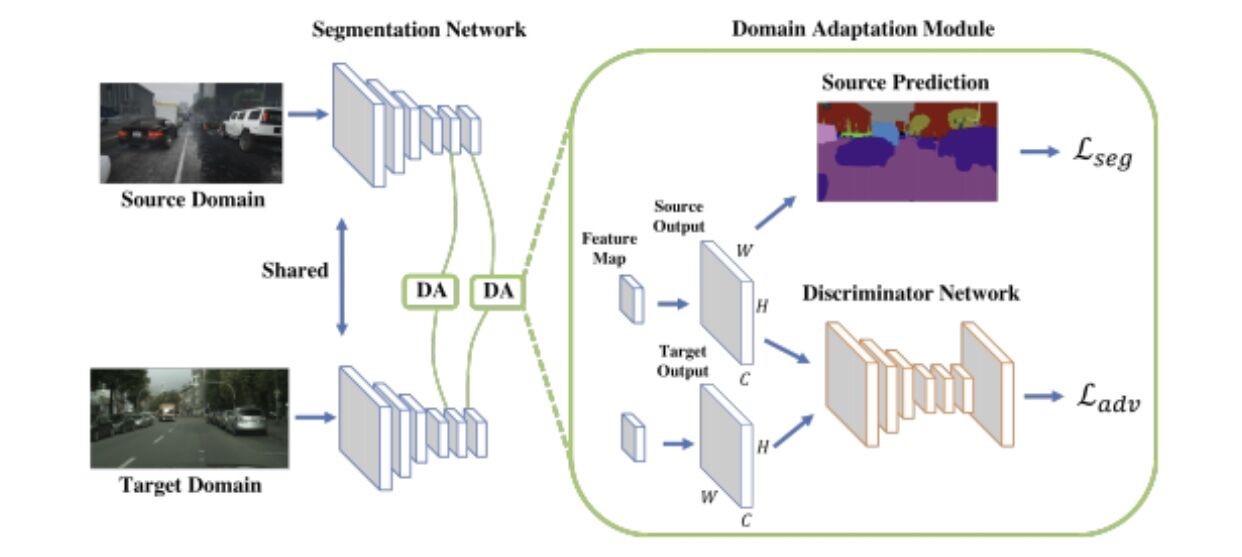
但是,对于后面的实验,我只使用了一个鉴别器,因此他的模型有了一个更简单的变体以便更快地进行。
为了熟悉,我使用GTA-V的子集作为源域(3072个带有标签的图像),将CityScape数据集的一个子集作为目标域(2975个没有标签的图像)。同时,使用来自目标域的297个标记数据进行验证。这只是两个数据集中的一个极小子集,但足以实现真正漂亮的结果。
在视觉上,我们希望从游戏(GTA-V)中传递样式:

GTA-V数据集的样本
到现实生活中的图像(Cityscape):

Cityscape数据集样本
注意,这对图像不必相似。这就是对抗模型背后的力量。
我使用最新的分割模型DeepLabV3PLus(以MobileNetV2作为主干)进行了一个简单的实验。仅使用数据集的极小子集(如前所述),以及使用较小的网络体系结构(以MobileNetV2为主干)来加快进度。
这么小的图像子集能做什么?我自己对结果感到非常惊讶。这是测试集中的一个样本。

297幅图像的验证集结果
使用更小的数据集、更小的网络(MobileNetV2作为DeepLabV3PLus的主干),以及仅使用单个鉴别器,这个结果如何与作者的结果相对应?
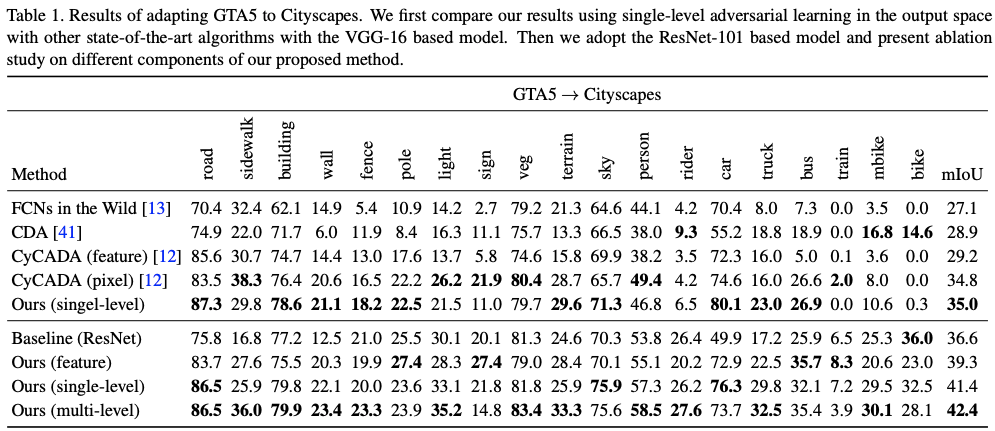
作者使用更大的网络VGG和ResNet作为DeepLabV3Plus的主干,实现了0.35的验证mIoU。考虑到我只使用了一个非常小的数据集和网络,我认为我得到的0.32的mIoU非常令人满意。
这个数字与测试图像是如何对应的?让我们看看。

样本测试集
测试结果之一来自基线,即在没有对抗性示例的情况下进行了训练,而另一训练时有。这就是mIOU中视觉上10%的增量,看起来好极了。
6.回到NLP领域自适应

现在,我将作者的图像分割网络架构与我绘制的NLP Question-Answering模型并排放置。你能说出相似之处吗?我实际上是根据作者的图表来绘制这幅画的。我们要做的就是使用不同的生成器(即BERT)和鉴别器(两个完全连接的层)。
这样做的动机是要解决COVID-19数据集开放研究数据集,我们作为数据科学家可以在其中调查有关COVID-19的问题。稍后我将详细说明该数据集。
由斯坦福大学众包(crowdsourced)和收集的一个非常小的BioASQ(约1000个question-answer pair)和一个更大的SQuAD数据集(约有100,000+个question-answer pair)被用作小型实验。

以前,我可以为视觉任务实现10%的增量。不幸的是,该NLP模型只实现了2%度量的增量。我想这是因为SQuAD和BioASQ之间不同数据对的数量存在巨大差异,范围是100,000和1,000,而之前的视觉任务中,是选择标记或未标记的两个数据集(包含约3,000张图片)。
7.NLP的评价
通常,评估NLP模型比评估图像要困难得多,因为人们只需查看图像并注意到明显的差异。我之前提到过COVID-19开放研究数据集。我做这个实验的原因是最终使用COVID-19开放研究数据集(而不是BioASQ)作为目标域,这样模型就可以学习特定的问题并回答COVID-19的问题。然而,最初使用BioASQ是因为它带有一个标记的测试集,可以对其进行评估。
幸运的是,对于该数据集,Anserini从COVID-19相关论文的大约30000篇学术文章中获得了一个倒排索引。他们还提供了可直接使用的Colab示例代码。因此,在对SQuAD和BioASQ上训练模型后,将通过以下管道在COVID-19数据库上进行了测试。
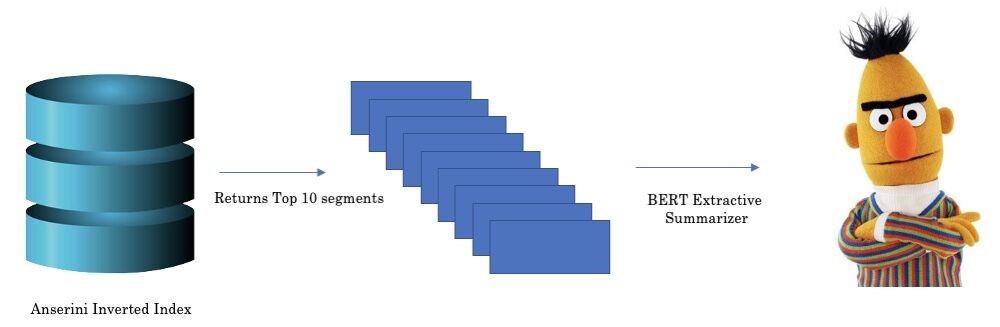
这是我使用的BERT摘要。之所以使用精炼的而不是抽象的总结方法(例如BART),是因为它可能会带走可能对评估有用的信息。
我已经回答了一些建议的COVID-19相关问题,并保存为一个HTML文件。这是一个示例。第一列代表问题,第二列代表表现稍好的模型的答案,用对抗性的例子训练,第三列则不训练。

没人会看完整的人工智能问答库,但你需要知道,它非常擅长回答语义问题,在更具体的问题上(例如病毒的潜伏期有多长)会有所回避。但是,如果我们向模型输入相同的问题,但是包含答案的上下文又会如何呢?这里是上下文:
为了避免病毒传播的风险,所有可能暴露的受试者都必须隔离14天,这是最长的预计潜伏时间。
的确!模型认为潜伏期为14天。那么它是索引还是模型呢?
通常,对抗模型(仅增加2%)在语义上是完全匹配的,因此在语义上没有显著差异。然而,对抗性和非对抗性模型之间的差异仍然可见的。例如,较短的答案通常对应于较高的置信度,而对抗模型往往给出较短的答案。
例如,体外膜肺氧合如何影响2019例NCOV患者。
对抗性模型
引言:目前,我国有5个转诊中心可以运送接受体外膜氧合的患者。
方法:回顾性病例系列研究由我们的移动式体外膜氧合团队管理,于2004年12月至2012年12月转入圣杰拉多大学医院。女性14例(33%),男性28例(67%)。平均运距121.69km(±183.08),范围在9km至1044km之间。28例(97%)采用静脉-静脉转流,1例(3%)采用静脉-动脉插管。在运输过程中未发现重大的临床或技术问题。我们开发了一个简化的无机械通风的ECMO运输系统,供公共紧急医疗服务使用。
非对抗性模型
引言:目前,我国有5个转诊中心可以运送接受体外膜氧合的患者。平均运输距离为121.69 km(±183.08),范围在9 km至1044 Km之间。29例(69%)患者接受了体外膜氧合支持,而13例(31%)患者采用常规通气。在运输过程中未发现重大的临床或技术问题。 该报告强调了导管置入术后迟发并发症的严重性,并显示了ECMO治疗在急性疾病治疗中的潜力。我们开发了一个简化的无机械通风的ECMO运输系统,供公共紧急医疗服务使用。根据新发冠状病毒性肺炎(NCP)的临床资料,结合以往临床研究的数据和体外生命支持机构(ELSO)的建议,中国体外生命支持学会(CSECLS)委员会提出该建议以用于指导临床ECMO在NCP患者中的应用。
注意一件事,该问题要求提供有关体外膜氧合的信息,并且答案能够推广到其首字母ECMO。
您喜欢谁的答案?
(张梦婷编译,李朝安校对)
研究动态
CMU、DeepMind和Google提出覆盖40种语言的多语言泛化XTREME基准
CMU, DeepMind & Google’s XTREME Benchmarks Multilingual Model Generalization Across 40 Languages
更通用的NLP模型要求达到更高水平的多语言能力。但全球约6900种语言中的大多数缺乏足够的数据来训练强健的模型,因而现有的NLP研究和方法仍然倾向于关注特定的英语任务。
Junjie Hu是卡内基梅隆大学语言技术学院的博士生。Hu曾在谷歌实习,他发现由于缺乏建立和全面的任务和环境来评估和比较模型在跨语言泛化方面的性能,很难训练跨语言模型。
尽管最近的mBERT和XLM等多语言方法在学习通用多语言表示形式方面取得了令人印象深刻的成果,但由于大多数评估都集中在为类似语言设计的不同任务集上,因此很难对这些模型进行公平的比较。
Hu和另一位CMU研究人员以及DeepMind的Sebastian Ruder和Google的研究人员最近发表了一项研究,介绍了XTREME,这是一个多任务基准,可评估40种语言和9种任务中多语言表示的跨语言泛化能力。Hu告诉Synced,“希望XTREME能够鼓励更多的研究工作来建立多语言NLP模型,并为多语言资源提供有效的人力资源管理。”
Hu和另一位CMU研究人员以及DeepMind的Sebastian Ruder和Google的研究人员最近发表了一项研究,介绍了XTREME,这是一个多任务基准,可评估40种语言和9种任务中多语言表示的跨语言泛化能力。Hu告诉Synced,“希望XTREME能够鼓励更多的研究工作来建立多语言NLP模型,并为多语言资源提供有效的人力资源管理。”

根据研究者的分析,当前模型的跨语言迁移性能在任务和语言之间存在显著差异。为了最大限度地提高基准语言的多样性,团队从Wikipedia文章最多的100种语言中选择了各种语言族中的40种语言,并使用了多种书面文字。
Hu表示:“我们还确保覆盖低、中、高资源的语言,换言之,在语言多样性和资源可用性之间找到平衡。” 该研究包括正在研究的语言,例如印度南部、斯里兰卡和新加坡使用的泰米尔语德拉维语。以及尼日尔-刚果语言斯瓦希里语和约鲁巴语。
Hu表示目前正在努力扩展XTREME,从而覆盖多达100种语言。
每个任务涵盖了40种语言的子集,因此,要使模型在XTREME基准测试中获得成功,就需要学习多语言表示形式,该表示形式概括了不同级别的语言信息,并概括了各种跨语言的传输任务。
XTREME专注于zero-shot跨语言迁移脚本,其中带注释的训练数据以英语提供,但没有以目标语言提供。为了使用XTREME评估性能,首先必须使用鼓励跨语言学习的目标对模型进行多语言文本预训练,并对特定于任务的英语数据进行微调。然后,XTREME可以评估zero-shot跨语言传输性能的模型,例如在没有提供特定于任务的训练数据的其他语言上。
在使用最新的预训练多语言模型(例如mBERT,XLM,XLM-R和M4)进行的实验中,研究人员发现,在语法和句子检索任务上,性能差异最为明显。尽管多语言模型在许多英语任务上都达到了人类水平的性能,并且在印欧语系的语言上表现也相当不错,但对于汉藏语、日语、韩语和尼日尔-刚果语言,表现得并不理想。
Ruder和合著者Melvin Johnson在谷歌博客上写道:“总体而言,在所有的模型和设置中,英语和其他语言的性能仍然存在很大的差距,这表明在跨语言迁移方面有很大的研究潜力。”
为英语应用开发的先进技术主导了最近大部分的令人印象深刻的NLP突破。在跨语言深层语境表征的基础上,研究人员相信这项新的研究有助于提高80%讲英语以外语言的人的自然语言处理性能。
(张梦婷编译,李朝安校对)
ExBERT:用于探索NLP模型中学习表示的工具
ExBERT, a Tool for Exploring Learned Representations in NLP Models
MIT-IBM AI实验室和哈佛NLP小组发布了他们的交互式可视化工具的现场演示、初步的论文及源代码。该工具被称为exBERT,用于探索transformers模型中的学习表示。
交互式工具可帮助NLP研究人员深入了解由Transformers模型形成的强大的上下文表示的含义。由于这些模型是由一系列自我注意力机制建立的,因此准确分析注意力所学到的归纳偏差很重要。通过探究表示形式捕获到了语言特征还是位置信息,exBERT呈现了可视化效果,从而可以洞悉模型和语料库的注意力以及词嵌入。exBERT以Google的语言模型BERT(基于Transformers的双向编码器表示形式)命名,但要注意的是,任何Transformer模型和语料库均可应用于exBERT上的任何域或语言。在初步的论文中,研究人员对BERT进行了案例分析,因为它是表示学习中最常用的Transformer模型,并且具有大量用于转移学习的应用程序。使用《绿野仙踪》作为参考语料库,使用该工具分析BERT学习被屏蔽单词的语言特征的层和注意力头。
对于给定语料库中的每个单词,exBERT将显示注意力和内部表示的视图。在注意力视图中,用户可以改变层次,选择注意力头,并查看聚集的注意力。
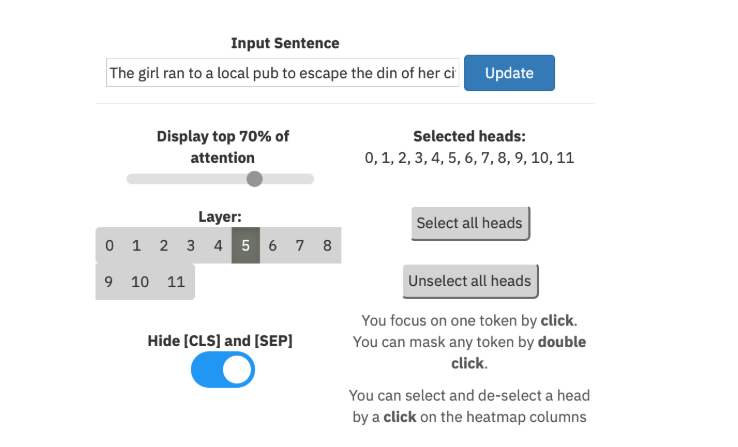
单词可以被屏蔽,可以在整个语料库中进行搜索,以在语料库视图中显示最高相似度匹配后的结果,使用户能够理解该表示。
随着AI应用程序进一步嵌入我们的日常生活中,强调可解释AI(XAI)变得越来越重要。 从注意力矩阵热图到二部图表示,已经有许多工具来可视化NLP模型中的注意力。exBERT部分受到名为BertViz的开源工具的启发,该工具旨可视化在BERT模型中的多头自我注意力。 exBERT研究人员认为,BertViz在更快、更交互式地探索BERT的注意力机制上迈出了一大步,但他们在初步的论文上增加了“在不理解注意力嵌入的情况下解释注意力机制,或仅依靠注意力进行解释,可能会导致错误的解释。”exBERT希望将静态分析的优势与更具动态性和直观性的视图相结合,来关注模型的注意力和内部表示。
(王宇飞编译,李朝安校对)
苹果和谷歌正在iOS和Android中构建冠状病毒跟踪系统
Apple and Google are building a coronavirus tracking system into iOS and Android
上周五,苹果和谷歌宣布了一种追踪新冠状病毒传播的系统,使用户可以通过低功耗蓝牙(BLE)和卫生组织已经批准的应用程序来共享数据。
这个由一系列文件和白皮书组成的新系统,使用短距离蓝牙建立一个自愿接触跟踪网络,将大量数据保存在彼此距离很近的手机上。来自公共卫生部门的官方应用可以访问此数据,如果用户被诊断为COVID-19,该系统可以报告,还将提醒下载它们的人是否与感染者有过密切接触。
苹果和谷歌将在五月中旬引入一对iOS和Android的API,并确保这些卫生部门的应用程序能够实现它们。在此阶段,用户仍必须下载应用程序才能参与联系人跟踪,这可能会限制采用率。但是在API完成后的几个月内,两家公司将致力于在基础操作系统中构建跟踪功能,使此功能作为每个使用iOS或Android手机的人都可以立即使用的选项。
苹果和谷歌将在五月中旬引入一对iOS和Android的API,并确保这些卫生部门的应用程序能够实现它们。在此阶段,用户仍必须下载应用程序才能参与联系人跟踪,这可能会限制采用率。但是在API完成后的几个月内,两家公司将致力于在基础操作系统中构建跟踪功能,使此功能作为每个使用iOS或Android手机的人都可以立即使用的选项。
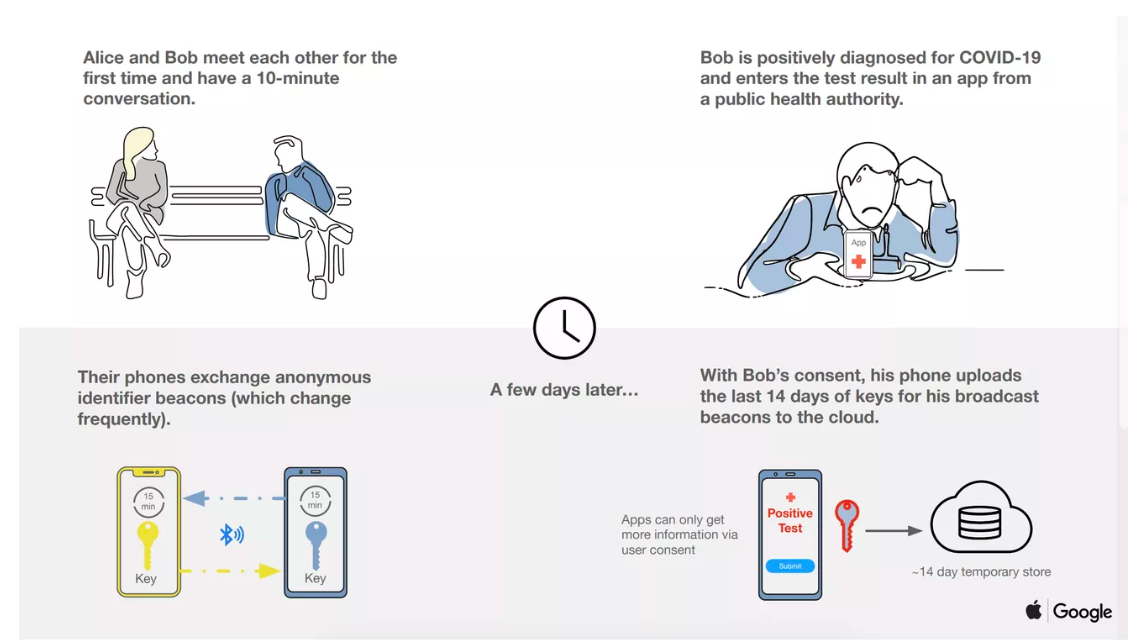
跟踪联系人(其中包括弄清感染者与谁有过接触并试图阻止他们感染他人)是控制COVID-19的最有希望的解决方案之一,但是使用数字监视技术来进行此操作会引起大量隐私问题以及关于有效性的问题。本周早些时候,美国公民自由联盟对用手机数据追踪用户表示担忧,认为任何系统都需要限制范围来避免损害用户隐私。
与其他一些方法(例如使用GPS数据)不同,该蓝牙计划不会跟踪人们的实际位置。它基本上会每隔5分钟获取附近手机的信号,并将它们之间的连接存储在数据库中。如果一个人的新型冠状病毒测试呈阳性,他们可以告诉该应用程序自己已被感染,并且可以通知其手机在前几天进行近距离传讯过的人。
即使人们已经共享了数据,该系统还采取了许多步骤来防止人们的身份被识别。该应用程序通过蓝牙定期发送信息时,会广播一个匿名密钥而不是静态身份,并且这些密钥每15分钟循环一次以保护隐私。即使有人分享了自己已被感染,该应用程序也只会分享他们具有传染性的特定时期的密钥。
至关重要的是,该软件没有可以集中访问的主列表,在此列表中手机已经与感染或其他相匹配。这是因为手机本身正在执行保护隐私所需的密码计算。中央服务器仅维护共享密钥的数据库,而不维护这些密钥之间的交互。
该方法仍然存在潜在的缺点。在拥挤的区域中,它可能标记相邻房间中但实际上没有与用户共享空间的人,从而使人们不必要地担心。它也可能无法捕捉到某人暴露了多长时间的细微差别,例如,整天在一个已感染的人旁边工作,会使用户承受比在街上走路时遇到已感染的人更大的病毒载量。而且,这需要人们在短期内拥有应用程序而且长期拥有最新的智能手机,这可能意味着它在连接性较低的地区效率较低。
这也是一个相对较新的计划,Apple和Google仍在与公共卫生部门和其他利益相关者讨论如何运行该计划。该系统可能无法替代老式的联系人跟踪方法,即涉及采访受感染的人有关他们去过的地方以及与谁在一起的时间,但它可以使用数十亿人已经拥有的设备提供高科技设备。
(王宇飞编译,李朝安校对)
项目工具
TensorFlow Lite Model Make可为设备上的AI调整最新模型
Google’s TensorFlow Lite Model Maker adapts state-of-the-art models for on-device AI
谷歌今天发布了TensorFlow Lite Model Maker,该工具使用一种迁移学习(transfer learning)的技术,将最先进的机器学习模型应用于自定义数据集。它用一个API包装机器学习概念,使开发人员只需几行代码就可以在谷歌的TensorFlow人工智能框架中训练模型,并为设备上的人工智能应用程序部署这些模型。
像Model Maker这样的工具可以帮助公司更快地将人工智能融入到工作流程中。根据一项由Algorithmia进行的研究,50%的公司花8到90天时间部署一个单一的机器学习模型,其中大多数将持续时间归咎于无法扩展。
目前只支持图像和文本分类用例,它与TensorFlow Hub中的许多模型一起工作,TensorFlow Hub是谷歌的可重用机器学习模块库(本文中的“模块”指的是自包含的算法以及可以跨不同人工智能任务使用的资源)。本质上,Model Maker根据在开始时指定的几个参数,以不同的精度将在一个任务上训练的模型应用于另一个相关任务。
通过修改模型结构(需要编辑一行代码),Model Maker可以提高模型精度。在加载特定于设备上AI的输入数据之后,Model Maker评估该模型并将其导出为TensorFlow Lite模型。(TensorFlow Lite是TensorFlow的一个版本,针对移动、嵌入式和物联网设备进行了优化。)
TensorFlow Lite Model Maker创建的模型附加了元数据,包括机器可读的参数(例如均值、标准差、类别标签文件)和人类可读的参数(例如模型描述和许可证)。Google指出,许可证等字段对于确定是否可以使用模型至关重要,而其他系统则可以使用机器可读的参数来生成包装器代码。
在接下来的几个月里,Google打算增强Model Maker以支持更多的任务,包括对象检测和一些自然语言处理任务。具体来说,它将为诸如问答之类的应用程序添加BERT。
Model Maker的推出紧随API-Quantization Aware Training(QAT)之后,该API可以训练更小、更快的TensorFlow模型,并具有量化的性能优势(将输入值从较大集合映射到较小集合的过程),同时保持接近原始精度。今年早些时候,谷歌在TensorFlow开发者峰会上发布了TensorFlow Quantum,这是一种用于训练量子模型的机器学习框架。
(张梦婷编译,李朝安校对)
近期论文
At Which Level Should We Extract? An Empirical Study on Extractive Document Summarization
我们应该在哪个级别提取?提取式文本摘要的实证研究
Qingyu Zhou Furu Wei Ming Zhou
研究背景
之前提取式的文本摘要,大都通过识别句子级别的信息来生成摘要。但是尚不清楚在句子级别执行提取是否是最佳解决方案。
研究贡献
-
证明了提取完整的句子存在不必要和冗余的问题,而提取子句是一种不错的选择。
-
建议在相应的选区解析树(constituency parsing tree)上提取子句单元,并提出了提取它们的神经网络模型。
研究方法
该研究使用了Penn Treebank对句子构建成分分析树。PTB有两个主要的标签:短语或从句,该研究将标记为从句标签的句子作为候选句子。
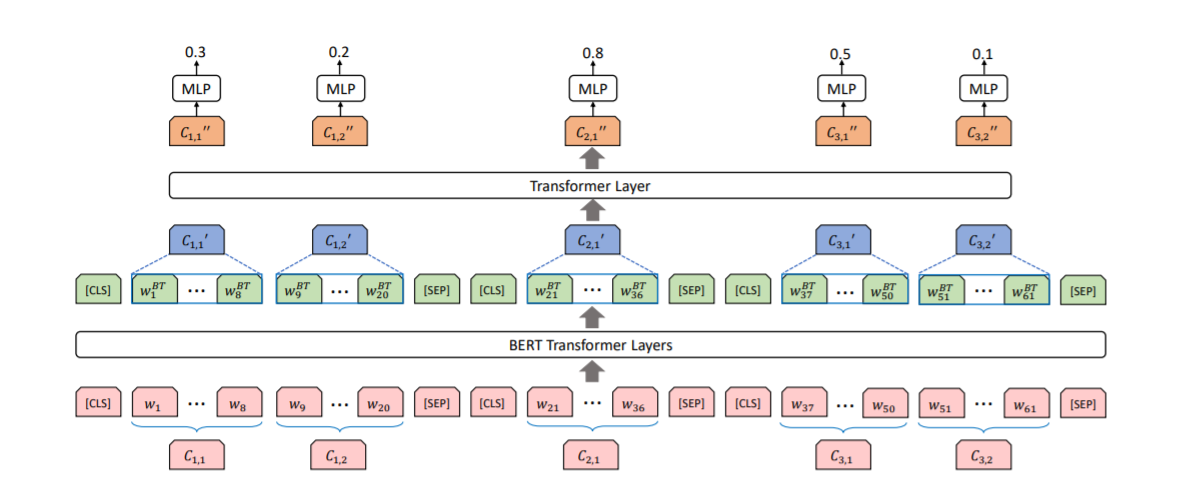
该研究将文本摘要问题看做是序列标注问题,提取句子的模型结构如上图所示,该模型由两个级别的编码器构成,第一个是基于BERT的文本编码器,第二个是基于transformer的句子编码器。
在基于BERT的文本编码器中,输入一个文档,用[cls]和[sep]将不同的句子分开,通过BERT对每个单词编码;然后,针对每个子句,对单词向量求平均,得到子句向量;最后在子句级别上,应用transformer。训练的目标是与给定的标签的二进制交叉熵损失。
在基于BERT的文本编码器中,输入一个文档,用[cls]和[sep]将不同的句子分开,通过BERT对每个单词编码;然后,针对每个子句,对单词向量求平均,得到子句向量;最后在子句级别上,应用transformer。训练的目标是与给定的标签的二进制交叉熵损失。
实验结果
使用CNN/Daily数据集,采用ROUGE和人工评价的方法评价结果。
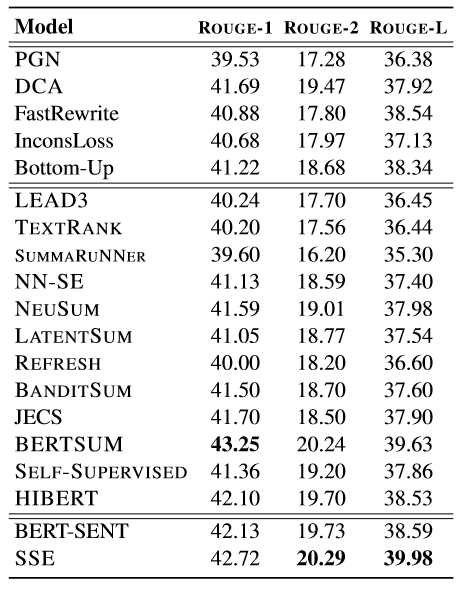
结果证明使用子句会带来效果的提升。下表为人工评价的结果,该研究随机抽取50篇文本进行人工评价,不必要和冗余度以发生频率衡量,越低越好;可读性与总体水平以排名衡量,越低越好。

结论
文本摘要在句子级别进行提取时,会产生冗余和不必要的问题,进行子句提取可以较好的缓解这一问题。
(王宇飞编译,李朝安校对)
近期会议
BMVC 2020: British Machine Vision Conference Manchester
Sep 7 - Sep 11, 2020 Manchester, United Kingdom
英国机器视觉会议(BMVC)是有关计算机视觉和相关领域的主要国际会议之一。它由英国机器视觉协会(BMVA)组织。 第31届BMVC将于2020年9月7日至11日在曼彻斯特举行。
邀请作者在2020年英国机器视觉会议上提交有关图像处理,机器视觉及相关领域的高质量论文。提交的论文将参考其原创性,介绍,经验结果和评估质量。
所有论文通常都会由我们国际计划委员会的三名成员进行双盲审查。BMVC是一个包含口头和海报演示的单一跟踪会议,并将包括三个主题演讲和两个教程。
INTERSPEECH 2020:Conference of the International Speech Communication Association
Oct 25 - Oct 29, 2020 Shanghai, China
INTERSPEECH2020组织者希望宣布,在密切监视COVID-19的状况并与ISCA董事会保持密切沟通之后,决定将IS2020推迟到2020年10月26-29日(教学日为10月25日),但仍保留在上海。
将与卫星研讨会的组织者合作,并根据这些变化提出挑战。下期待着在上海举办IS2020及相关活动,作为一个人满为患的会议,并将通过一小部分参与者的远程参与而扩大。 有关远程参与的详细信息将在适当时候宣布。 在任何情况下,IS2020组织者都将推动并完成会议论文集的发布过程。