文本挖掘与机器学习跟踪扫描动态快报(2021.07)
实时跟踪、关注文本挖掘与机器学习领域最新研究动态
深度观察
从视觉到语言的半监督学习
From Vision to Language:Semi-supervised Learning in Action... at Scale
监督学习是使用具有已知结果的数据点(即标记数据)训练预测模型的机器学习任务,由于其简单性,通常是工业中的首选方法。然而,监督学习需要准确标记的数据,这些数据的收集通常是劳动密集型的。此外,随着模型效率随着更好的架构、算法和硬件(GPU / TPU)的提高,训练大型模型以获得更好的质量变得更容易,这反过来需要更多的标记数据来持续进步。
为了缓解此类数据获取挑战,半监督学习是一种将少量标记数据与大量未标记数据相结合的机器学习范式,最近在UDA、SimCLR等方法上取得了成功。在我们之前的工作中,我们首次证明了一种半监督学习方法Noisy Student可以在 ImageNet上实现最先进的性能,ImageNet是一个大规模的图像分类学术基准,通过利用更多未标记的样本。
受这些结果的启发,今天我们很高兴地介绍半监督蒸馏 (SSD),这是 Noisy Student 的简化版本,并展示了其在语言领域的成功应用。我们将 SSD 应用于 Google搜索上下文中的语言理解,从而获得高性能提升。这是大规模应用半监督学习的第一个成功实例,并展示了此类方法对生产规模系统的潜在影响。
Noisy Student Training
在我们开发 Noisy Student之前,有大量关于半监督学习的研究。然而,尽管进行了广泛的研究,但此类系统通常仅在低数据范围内运行良好,例如 CIFAR、SVHN和10% ImageNet。当标记数据丰富时,此类模型无法与全监督学习系统竞争,从而阻止将半监督方法应用于生产中的重要应用,例如搜索引擎和自动驾驶汽车。这一缺点促使我们开发了Noisy Student Training,这是一种在高数据机制中运行良好的半监督学习方法,当时使用130M额外的未标记图像在 ImageNet上实现了最先进的准确性。
Noisy Student Training有4个简单的步骤:
- 1.在标记数据上训练分类器(Teacher);
- 2.Teacher在更大的未标记数据集上推断伪标签;
- 3.它在组合的标记和伪标记数据上训练更大的分类器,同时还添加噪声(Noisy Student);
- 4.(可选)返回第 2 步,该Student可能会被用作新Teacher。
人们可以将Noisy Student视为一种自我训练(Self-training)的形式,因为该模型会生成伪标签,通过这些伪标签重新训练自己以提高性能。Noisy Student Training的一个令人惊讶的特性是,经过训练的模型在未经优化的鲁棒性测试集上工作得非常好,包括 ImageNet-A、ImageNet-C 和 ImageNet-P。我们假设在训练过程中添加的噪声不仅有助于学习,而且使模型更加健壮。
与知识蒸馏的联系
Noisy Student类似于知识蒸馏,是将知识从大模型(即Teacher)转移到较小模型(Student)的过程。蒸馏的目标是提高速度,以便建立一个模型,该模型可以在生产中快速运行,而与Teacher相比,质量不会有太大牺牲。最简单的蒸馏设置涉及单个Teacher并使用相同的数据,但实际上,可以使用多个Teacher或为Student使用单独的数据集。
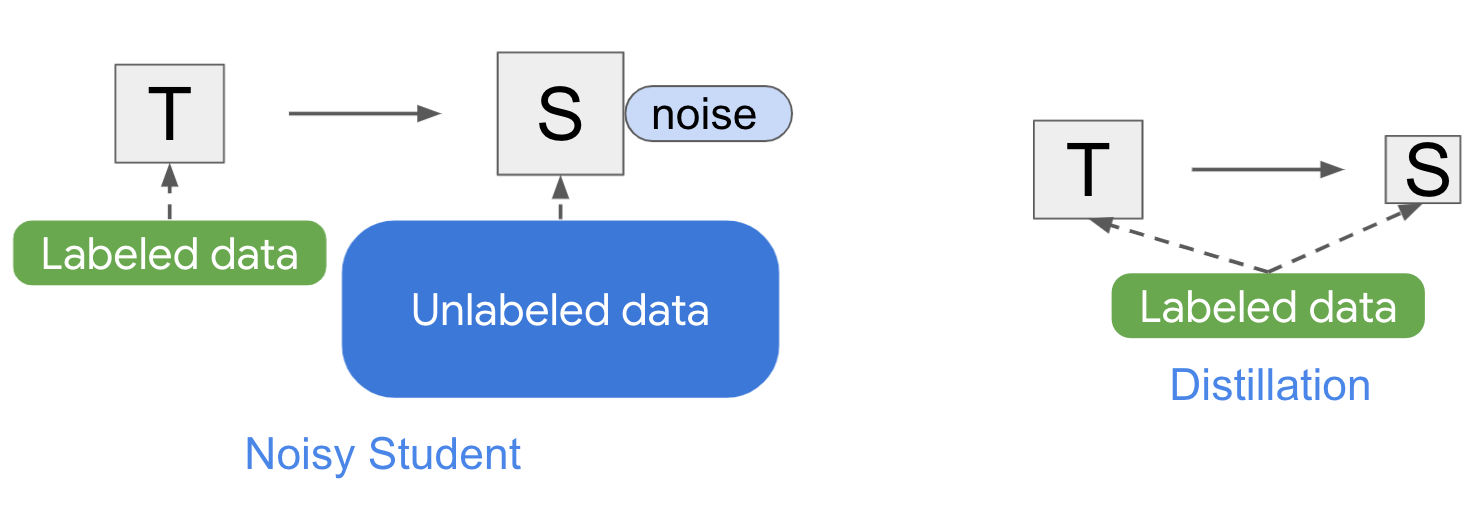
与Noisy Student不同,知识蒸馏不会在训练期间添加噪音(例如,数据增强或模型正则化),并且通常涉及较小的学生模型。相比之下,人们可以将Noisy Student视为“知识扩展”的过程。
半监督蒸馏
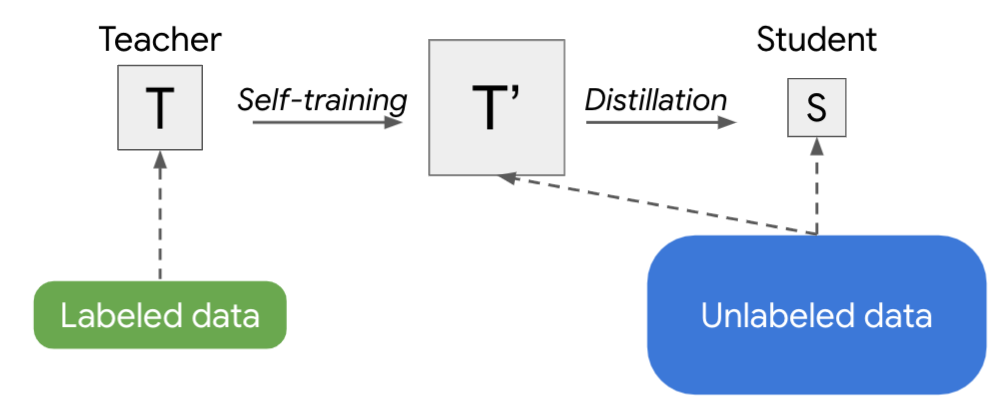
训练生产模型的另一种策略是两次应用Noisy Student 训练:首先得到一个更大的教师模型T',然后导出一个更小的学生S。这种方法产生的模型比使用监督学习或使用Noisy Student单独训练更好。具体来说,当应用于一系列 EfficientNet模型的视觉域时,从具有5.3M参数的EfficientNet-B0到具有66M参数的EfficientNet-B7,该策略对每个给定的模型尺寸实现了更好的性能。
Noisy Student训练需要数据增强,例如RandAugment(用于视觉)或 SpecAugment(用于语音)才能正常工作。但是在某些应用中,例如自然语言处理,这种类型的输入噪声并不容易获得。对于这些应用,Noisy Student Training 可以简化为没有噪音。在这种情况下,上述两阶段过程就变成了一种更简单的方法,我们称之为半监督蒸馏(SSD)。首先,教师模型在未标记的数据集上推断伪标签,然后我们从中训练一个新的教师模型(T'),其大小等于或大于原始教师模型。这一步本质上是自我训练(Self-training),然后是知识蒸馏,以产生一个较小的学生模型进行生产。
改进搜索
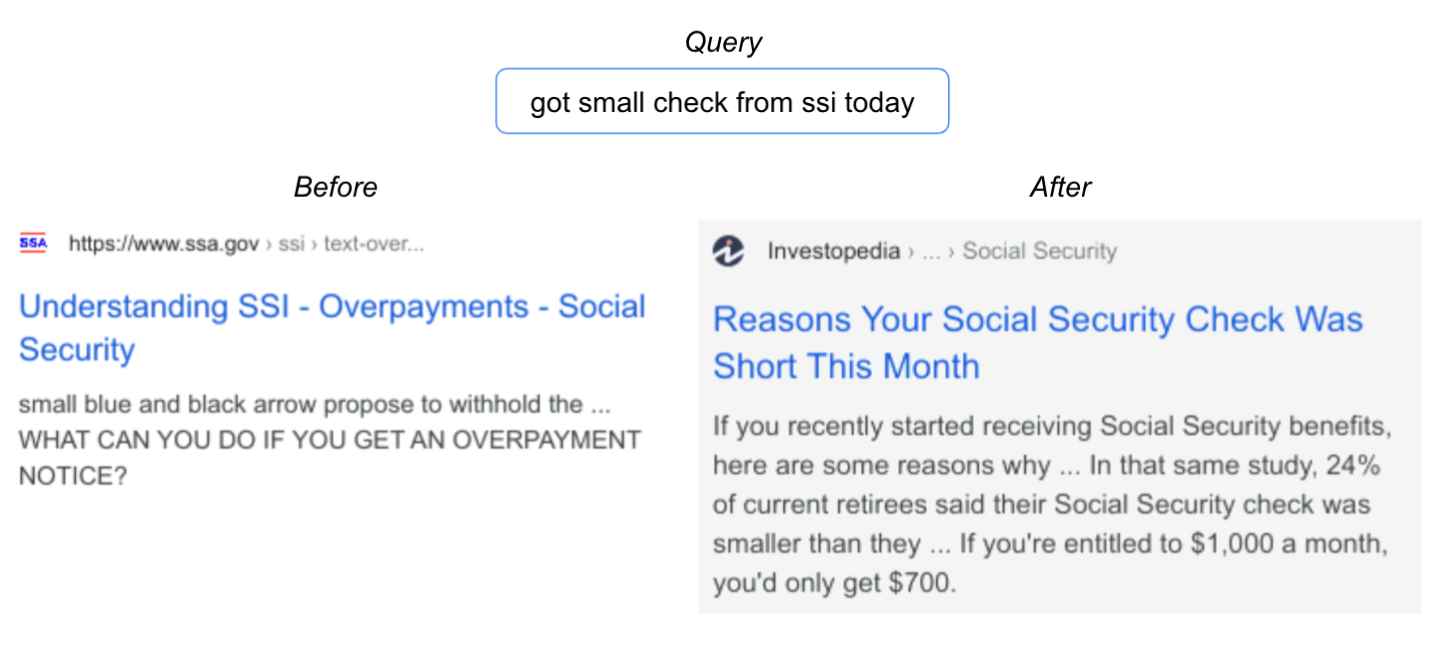
在视觉领域取得成功后,语言理解领域的应用程序(如Google搜索)是具有更广泛用户影响的合乎逻辑的下一步。在这种情况下,我们专注于搜索中的一个重要排名组件,它建立在BERT上以更好地理解语言。事实证明,这项任务非常适合SSD。事实上,将SSD应用于排名组件以更好地了解候选搜索结果与查询的相关性,在2020年搜索的顶级发布中实现了最高的性能提升之一。以下是一个查询示例,其中改进的模型展示了更好的语言理解。
未来展望
我们在搜索的生产规模设置中展示了半监督蒸馏 (SSD) 的成功实例。我们相信SSD将继续改变行业中机器学习使用的格局,从主要的监督学习到半监督学习。虽然我们的结果很有希望,但如何在现实世界中有效地利用未标记的示例(通常是嘈杂的)并将它们应用于各个领域,仍然需要进行大量研究。
(张梦婷编译,赵海喻校对)
研究动态
OpenAI微调GPT-3以解决困难问题
OpenAI Fine-Tunes GPT-3 to Unlock Its Code Generation Potential for Difficult Problems
OpenAI的GPT-3自去年6月发布以来一直是头条新闻。研究表明它能够从Python编程语言文档字符串生成简单程序。基于GPT-3的巨大成功以及GitHub存储库中大量开源代码,OpenAI的一个研究团队提出了Codex,它可以从自然语言文档字符串中生成功能正确的代码体,并且可以在各种编码任务中表现出色。


这项新颖的研究旨在从文档字符串生成独立的Python函数,并通过单元测试自动评估代码示例的正确性。该团队首先定义了pass@k指标,其中每个问题生成k个代码样本,如果任何样本通过单元测试,则认为问题已解决。然后报告解决的问题的总分数。接下来,他们构建了一个“HumanEval”手写问题数据集来评估语言理解、推理、算法。最后,他们定义了沙箱环境,用于针对单元测试安全地执行模型生成的代码。
训练数据集是从GitHub上托管的5400万个公共软件存储库中收集的,其中包含179GB小于1MB的独特Python文件。该团队使用具有175步线性预热和余弦学习率衰减的GPT模型训练 Codex,他们的代码词法分析器基于GPT-3 文本标记器,以最大限度地利用GPT文本表示。然后,他们根据生成的训练问题对Codex进行微调,以生成一组“监督微调”模型,他们将其称为 Codex-S。
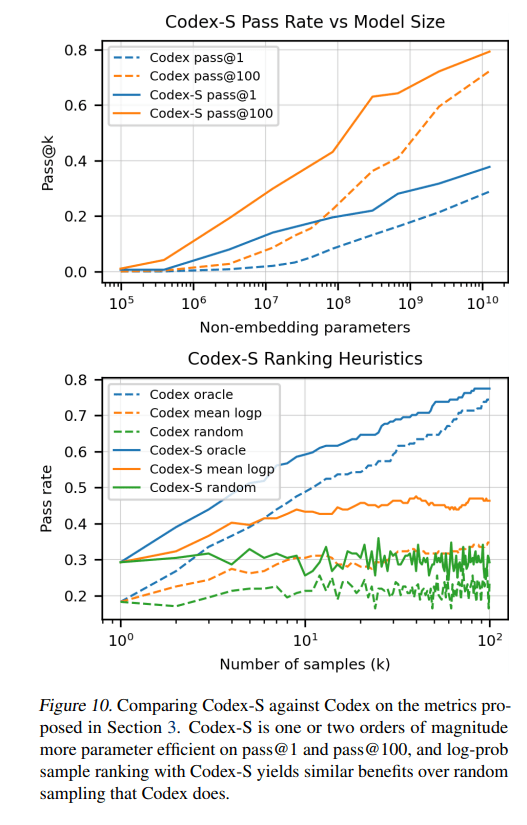
该团队进行了许多实验来评估他们微调的Codex-S模型的性能。在跨模型大小的pass@1和pass@100测试中,Codex-S分别超过相应的Codex模型6.5和 15.1个百分点。该团队还绘制了Codex-S-12B的不同样本选择启发式与 Codex-12B的相同启发式方法的性能对比,Codex-S的得分比Codex模型高出 2%以上。
总体而言,该研究表明在GitHub代码上微调的拟议GPT-3 Codex模型在人工编写的问题上取得了强大的性能,其难度可与简单的面试问题相媲美,这表明 GPT-3可以通过训练生成功能正确的代码体。
研究人员指出,可以通过对类似于评估集的分布进行训练以及从模型中生成多个样本来进一步提高模型性能,并且训练模型以完成从代码体生成文档字符串的反向任务相对简单。
(张梦婷编译,赵海喻校对)
谷歌的Wordcraft文本编辑器推进了人机协作的故事写作
Google's Wordcraft Text Editor Advances Human-AI Collaborative Story Writing
神经语言模型在现实生活中的创意任务中越来越受欢迎,例如文本冒险游戏、协作口号写作,甚至体育新闻、诗歌和小说创作。然而,大多数此类语言模型为用户提供有限的交互支持,因为超越简单的从左到右文本生成的控制需要明确的训练。
为了解决这个限制,谷歌研究院的一个团队提出了Wordcraft,一个内置AI 驱动的创意写作助手的文本编辑器。Wordcraft利用少量学习和对话的自然可供性来支持各种用户交互,并且可以帮助进行故事规划、写作和编辑。


Wordcraft网络界面包括一个传统的文本编辑器,增加了许多用于触发对AI 助手的请求的关键命令。该模型能够勾勒故事大纲、编写故事,甚至进行编辑和重写。例如,命令“get continuations”将从用户光标的位置生成额外的基于上下文的文本,而“rewrite”和“elaborate”命令可用于重新措辞或详细说明选定的文本块。用户还可以要求Wordcraft执行“帮我描述老人的情绪状态”等特定任务,并通过修改提示来尝试自己的查询。


为了支持他们新颖的human-AI写作助手协作系统,这是一种用于文本生成的开放式对话系统。Meena最初被设计为聊天机器人,能够遵循指示并回答以对话形式提出的问题。研究人员还应用了few-shot learning,使他们的语言模型能够根据用户的指令执行所需的任务。此外,如果AI助手不明白人类作者的要求,它会以自然语言对话格式返回澄清请求。
Wordcraft中内置的一些交互包括延续、填充、细化和重写,本文为每个交互提供了大量示例。通过Wordcraft的人机协作编辑器生成的故事自然且可解释,展示了此类人机协作语言模型的前景和潜力。研究人员将Wordcraft视为进一步研究人类与人工智能创意写作助手合作的起点。他们未来的计划包括进行更正式的用户研究,以提高对编写者需要什么帮助以及如何扩展Wordcraft的自然语言生成以满足这些需求的理解。
(张梦婷编译,周子喻校对)
谷歌和西北大学提出可证明有效的神经网络学习算法
Google & Northwestern U Present Provably Efficient Learning Algorithms for Neural Networks
深度神经网络(DNN)的实证成功激发了机器学习研究界发起关于DNN方面的理论研究,例如学习、优化和泛化。一个关键的相关研究领域是探索如何为神经网络设计可证明时间和样本效率高的学习算法——即使在深度为2的前馈神经网络的情况下,这一挑战也仍未解决。
为了推进该领域的研究,来自谷歌研究院和西北大学的一个团队引入了一组多项式时间和样本高效算法,用于学习具有通用整流线性单元(ReLU)激活的未知深度为2的前馈神经网络。他们最近的论文Efficient Algorithms for Learning Depth-2 Neural Networks with General ReLU Activations探讨了这种用于学习 ReLU网络的高效算法的合理性。

该团队考虑了监督学习问题,输入服从标准高斯分布,标签由element-wise ReLU 激活函数的神经网络生成。工作中使用的张量是通过对每个数据点评估的评分函数的加权平均值形成的。值得注意的是,该团队观察到可以通过分析多个高阶张量来实现对网络的良好近似。

该领域以前的工作假设具有ReLU激活的学习网络的偏差为零。与这种传统方法不同,所提出的算法包括由函数的Hermite展开产生的稳健分解的多个高阶张量,它们的性能证实了多项式时间算法即使在ReLU单元中存在偏差项的情况下也可以很好地设计。

该团队使用平滑的分析框架——超越最坏情况的分析范式——来探索和解释各种算法的实际成功,并在最小假设下建立超越最坏情况的保证和网络参数的可识别性。
(张梦婷编译,赵海喻校对)
MIT研究人员称深度学习正在接近计算极限
MIT researchers warn that deep learning is approaching computational limits
我们正在接近深度学习的计算极限。这是麻省理工学院、麻省理工学院-IBM 沃森人工智能实验室、安德伍德国际学院和巴西利亚大学的研究人员在最近的一项研究中发现的,他们在最近的一项研究中发现,深度学习的进步“强烈依赖”计算的增加。他们断言,持续的进步将需要计算效率更高的深度学习方法,无论是通过改变现有技术还是通过尚未发现的新方法。
深度学习的计算成本不是偶然的。同样的灵活性使其在建模各种现象和超越专家模型方面表现出色,也使其计算成本显着增加。尽管如此,我们发现深度学习模型的实际计算负担比理论上的(已知)下界扩展得更快,这表明可能会有实质性的改进。
深度学习是机器学习的子领域,涉及受大脑结构和功能启发的算法。这些算法——称为人工神经网络——由分层排列的函数(神经元)组成,这些函数将信号传输到其他神经元。信号是输入到网络中的输入数据的产物,在层与层之间传播并缓慢地“调整”网络,实际上是在调整每个连接的突触强度(权重)。网络最终学会通过从数据集中提取特征并识别跨样本趋势来进行预测。
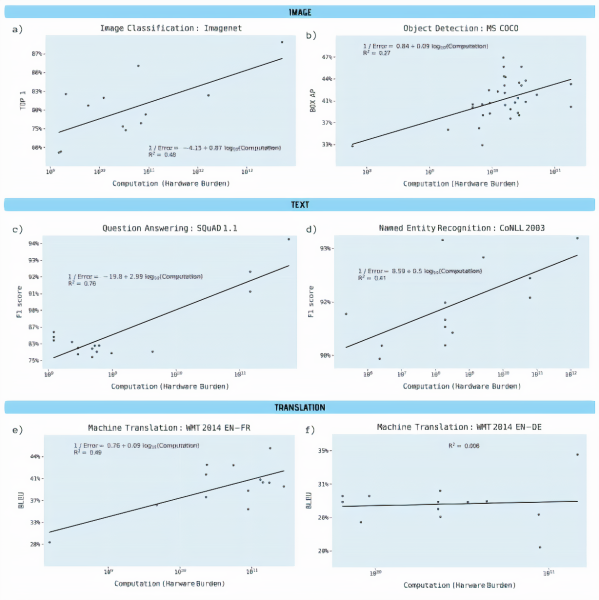
研究人员分析了来自预印本服务器 Arxiv.org 以及其他基准源的1,058篇论文,以了解深度学习性能与计算之间的联系,特别关注图像分类、对象检测、问答、命名实体识别和机器学习等领域。他们对反映两种可用信息的计算要求进行了两次单独的分析:
- 每次网络传递的计算量,或给定深度学习模型中单次传递(即权重调整)所需的浮点运算次数。
- 硬件负担,或用于训练模型的硬件的计算能力,计算为处理器数量乘以计算速率和时间。
合著者报告了所有基准的“具有高度统计显著性”的斜率和“强大的解释力”,除了从英语到德语的机器翻译,其中使用的计算能力几乎没有变化。对象检测、命名实体识别和机器翻译尤其显示出硬件负担的大幅增加,结果的改进相对较小,计算能力解释了流行的开源ImageNet基准测试中43%的图像分类精度差异。
研究人员估计,三年的算法改进相当于计算能力增加10倍。他们写道:“总的来说,我们的结果清楚地表明,在深度学习的许多领域,训练模型的进步取决于所使用的计算能力的大幅增加。另一种可能性是,获得算法改进本身可能需要计算能力的补充增加。”
在他们的研究过程中,研究人员还对预测进行了推断,以了解达到各种理论基准所需的计算能力以及相关的经济和环境成本。即使按照最乐观的计算,降低 ImageNet上的图像分类错误率也需要多105次计算。
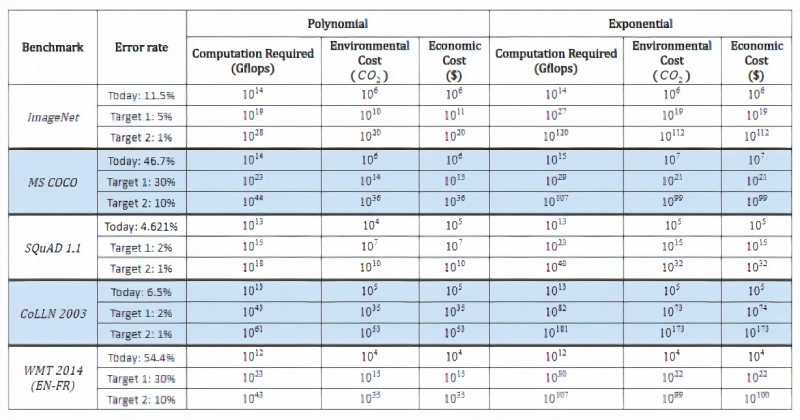
就他们而言,Synced的一份报告估计,华盛顿大学的Grover假新闻检测模型在大约两周内的训练成本为25,000美元。 据报道,OpenAI花费了1200万美元来训练其GPT-3语言模型,而谷歌估计花费了6912美元来训练 BERT。
在去年6月的另一份报告中,马萨诸塞大学阿默斯特分校的研究人员得出结论,训练和搜索某个模型所需的电量涉及大约626,000磅的二氧化碳排放。这相当于美国汽车平均寿命排放量的近五倍。
研究人员指出,在算法层面上有深度学习改进的历史先例。他们指出谷歌张量处理单元、现场可编程门阵列 (FPGA) 和专用集成电路 (ASIC) 等硬件加速器的出现,以及通过网络压缩和加速技术降低计算复杂性的尝试。他们还引用了神经架构搜索和元学习,它们使用优化来寻找在一类问题上保持良好性能的架构,作为提高计算效率的方法的途径。
事实上,OpenAI的一项研究表明,自2012年以来,在ImageNet中将AI模型训练到相同性能所需的计算量每16个月就减少了2倍。谷歌的Transformer 架构超过了之前最先进的模型seq2seq,它也是由谷歌开发的,在seq2seq推出三年后计算量减少了61倍。DeepMind的AlphaZero是一个从头开始自学如何掌握国际象棋、将棋和围棋游戏的系统,一年后与该系统的前身AlphaGoZero的改进版本相匹配,所需的计算量减少了八倍。
(张梦婷编译,周子喻校对)
项目工具
数据预处理概述:特征增强以及特征选择
An Overview of Data Preprocessing:Features Enrichment,Automatic Feature Selection
本文包含不同的角度来看待数据集,让算法更容易学习数据集。所有研究都通过Python应用程序变得更容易理解。
分箱
分箱用于将数字数据转换为分类数据,从而使模型更加灵活。考虑到数字数据,创建由用户确定的bin数量,所有数据都填充到这些范围内并重命名。现在让我们对数据集中的年龄列应用分箱。
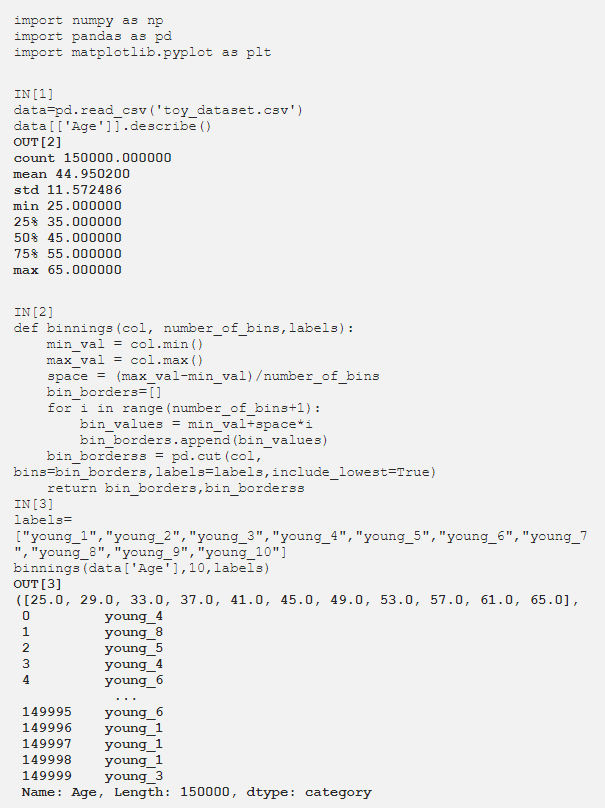
通过将数据集中的年龄范围等间隔地划分为11个部分,创建了10个 bin。 每个范围都被赋予选定的标签 (young_1 ..... young_10) 并作为一列添加到数据集中。现在如果我们想向数据集添加一个新列:

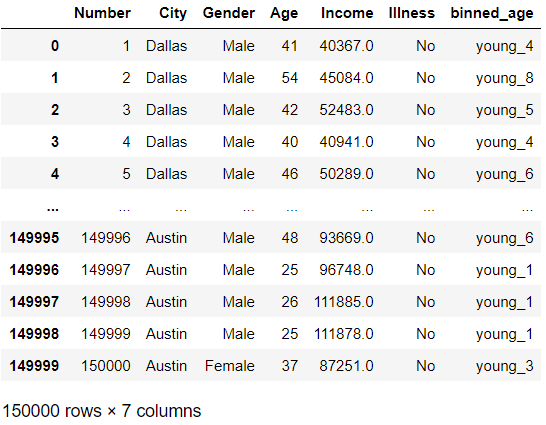
现在让我们看看算法准确性对我们创建的数据集的影响。


现在让我们创建 bin 并使用 bin 测试新数据集。
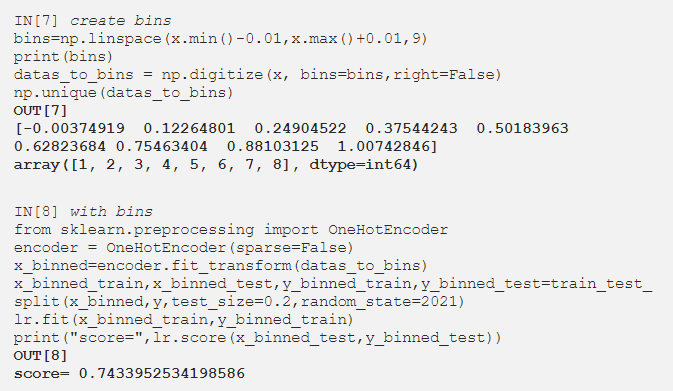
分箱不会影响基于树的算法,且对线性模型非常有效。
多项式和交互特征
可以对数据集进行的另一个改进是添加交互特征和多项式特征。如果我们考虑上一节中创建的数据集和分箱操作,可以创建各种数学配置来增强这一点。 例如,让我们以分箱数据为例,该数据从数值变量转换为分类变量,然后使用 OneHotEncoder转换回数值。我们将通过添加0到1之间的100个随机数据与分箱所创建的数据集分组,现在让我们将binned数据集与普通数据集组合并创建一个新数据集,或者将binned数据集与普通数据集相乘并添加到binned数据集,或将分箱数据集划分为普通数据集并添加到分箱数据集。所有线性回归和得分如下所示:

由于多项式和交互特征没有取得很好的结果,数据集是随机创建的。这些方法在实际项目中经常使用,效率很高。
非线性转换
数据集中的数值若服从高斯分布,则非常适合模型学习和进行预测。可以通过一些数学运算将数据集转换为高斯分布。这就像从另一个角度看同一个数据集,就像在同一个信号的频率分析中使用傅立叶变换一样。相同的mat操作应用于列中的所有数据。现在,在我们查看这些方法之前,让我们准备我们将使用的列和qq_plot。
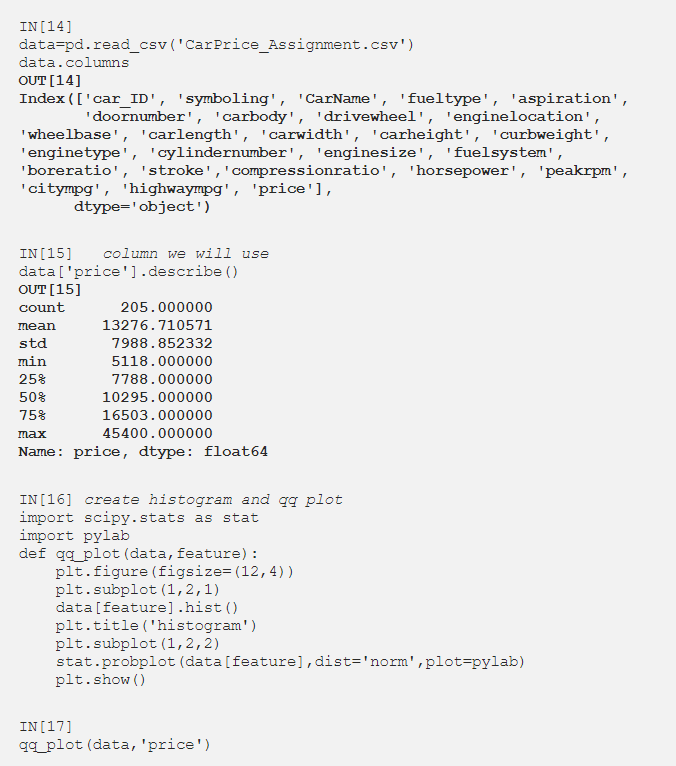
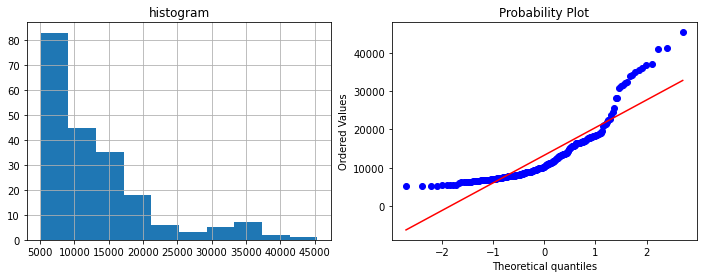
特征选择
通过特征增强扩展了数据集,但由于此操作会创建一个复杂的数据集,因此可能会导致过度拟合。故而需要根据高维数据集或复杂数据集的特征重要性来减少特征的方法。
方差分析(ANOVA)
对每个特征与目标的关系进行单独分析,按照用户选择的比率剔除与目标关系较小的特征。这种特征-目标关系是根据p值确定的。首先消除具有高p值的特征。现在让我们导入乳腺癌数据集,然后应用线性回归和决策树算法。
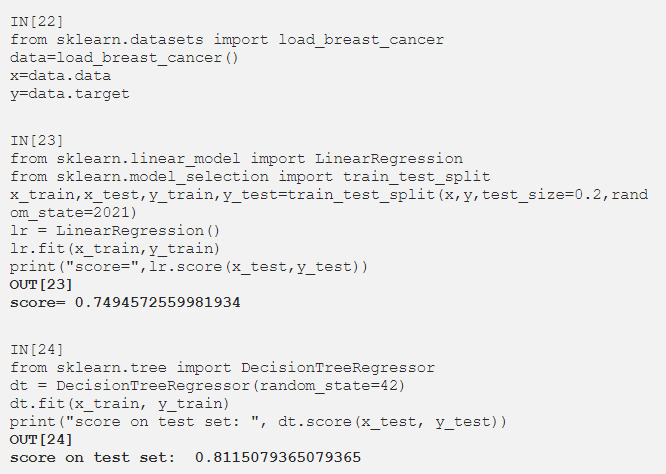
添加DecisionTreeRegressor以查看特征重要性:

方差分析。

选定特征的线性回归:
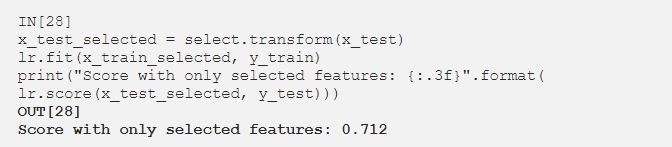
仅使用9个特征获得 0.712,而使用30个特征获得0.749。现在让我们看看SelectPercentile选择了哪些特征:

基于模型的特征选择
它一次评估所有特征并根据它们的相互作用选择特征。它根据用户设置的阈值选择重要性较高的那些。例如,如果选择了threshold=medium,则选择了50% 的特征。Sklearn中阈值的默认值是mean。

选定特征的线性回归:

迭代特征选择
它根据某个阈值以两种方式工作:第一个从0个特征开始,并根据它们的重要性继续添加特征,直到达到阈值。第二个选择所有特征并一一消除,直到阈值。 顾名思义,递归特征消除(RFE)选择所有特征并消除特征直到指定条件。

Condition设置为20个特征,从30个特征开始,逐个消除特征,直到剩下 20个特征。

(张梦婷编译,周子喻校对)
近期论文
FastSeq:Make Sequence Generation Faster
摘要
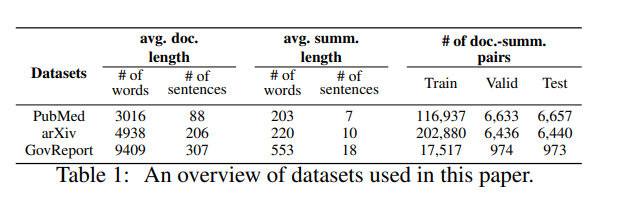
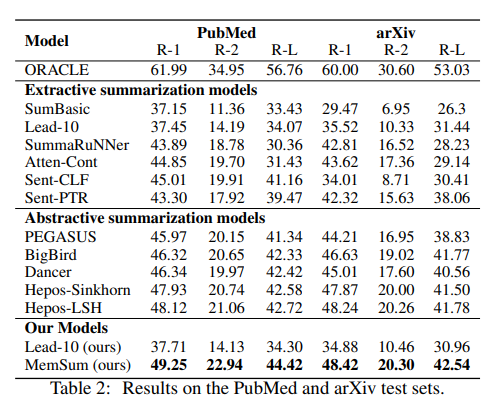
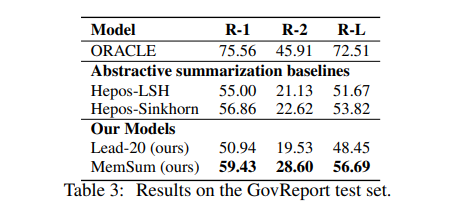
MemSum (Multi-step Episodic Markov Decision Process Extractive SUMmarizer)是一种基于强化学习的抽取式自动文摘模型,在任何给定的时间步长都包含有关当前提取历史的信息。与之前的模型类似,MemSum迭代地将句子选择到摘要中。本文的创新在于在自动文摘时考虑更广泛的信息集,人类在此任务中也可以直观地使用这些信息集:1) 句子的文本内容,2) 文档其余部分的全局文本上下文,以及 3) 由一组已经抽取的句子组成。 凭借轻量级架构,MemSum 在长文档数据集(PubMed、arXiv和GovReport)上获得了最先进的测试集性能。
主要贡献
我们表明与没有历史意识的模型相比,对抽取历史的了解使我们的模型能够提取更紧凑的摘要,并且对文档中的冗余表现得更稳健。MemSum模型优于 PubMed、arXiv和GovReport数据集上的抽取式和生成式自动文摘模型。此外,我们还提供了一个开源包来复现我们的结果,可以在三个数据集上实现自动文摘。
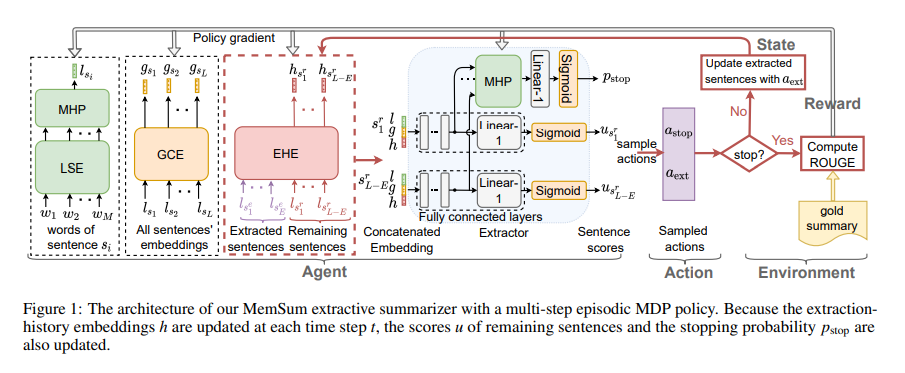
实验
在这项工作中,我们提出了FastSeq,它提供了在不损失精度的情况下加速序列生成的通用解决方案。提出的优化方案包括注意缓存优化、基于GPU的n-grams阻塞算法和异步生成pipline。在未来,我们将支持更多的模型和探索更多的技术,以加快生成速度。
(张梦婷编译)
近期会议
MemSum : Extractive Summarization of Long Document Using Multi-Step Episodic Markov Decision Processes
Aug 21 Chennai, India
DNLP 2021将提供一个极好的国际论坛,以分享数据挖掘和NLP的理论、方法和应用方面的知识和成果。 这次会议的目的是将学术界和工业界的研究人员和从业人员聚集在一起,集中精力于理解数据挖掘和NLP概念,并在这些领域建立新的合作关系。
(张梦婷)
NLPCC 2021:Natural Language Processing and Chinese Computing
Oct 12 - Oct 17 Chennai, India
NLPCC是一个领先的国际会议,专门研究自然语言处理(NLP)和中文计算(CC)领域。NLPCC在CCF推荐的CS会议列表中。它是学术界、工业界和政府的研究人员和实践者分享他们的想法、研究成果和经验,并促进他们在该领域的研究和技术创新的主要论坛。
(张梦婷)