文本挖掘与机器学习跟踪扫描动态快报(2021.05)
实时跟踪、关注文本挖掘与机器学习领域最新研究动态
深度观察
通过标记和插入实现灵活的文本编辑
Introducing FELIX: Flexible Text Editing Through Tagging and Insertion
序列到序列(Seq2Seq)模型已经成为处理自然语言生成任务的热门方法,其应用范围从机器翻译到单语生成任务,如自动文摘、句子融合、文本简化和机器翻译后编辑。然而,对于许多单语任务来说,这些模型似乎是次优的选择,因为所需的输出文本通常表示对输入文本的轻微重写。当完成这些任务时,seq2seq模型速度较慢,因为它们一次只生成一个字(即自回归)。
文本编辑模型最近受到了极大的关注,因为它们提出了预测编辑操作(如单词删除、插入或替换)的方法,这些操作将应用于输入以重建输出。然而,以往的文本编辑方法有其局限性。它们要么快速但因为使用的编辑操作数量有限而不灵活(非自回归),要么灵活但因为需要支持所有可能的编辑操作而速度缓慢(自回归)。在这两种情况下,他们都没有专注于对大型结构(句法)转换建模,而是专注于局部转换、删除或替换短短语。当需要进行大规模的结构转换时,它们要么无法生成,要么缓慢地插入大量的新文本。
在 FELIX:Flexible Text Editing Through Tagging and Insertion 一文中,我们介绍了FELIX,其是一个快速灵活的文本编辑系统,它模拟了巨大的结构变化,与Seq2Seq方法相比,它的速度提高了90倍,同时在四个单语生成任务上取得了非常好的结果。与传统的Seq2Seq方法相比,FELIX具有以下三个关键优势:
- 样本效率:训练高精度文本生成模型通常需要大量高质量的监督数据。FELIX使用三种技术来最小化所需的数据量:(1)微调预训练的checkpoint(2)学习少量编辑操作的标记模型(3)与预训练任务非常相似的文本插入任务。
- 快速推理:FELIX是完全非自回归的,避免了像自回归解码器一样需要耗费很长的推理时间。
- 灵活的文本编辑:FELIX平衡了所学习到的编辑操作的复杂性与建模转换的灵活性。
简言之,FELIX旨在从自我监督的预训练中获得最大的收益,在资源匮乏的情况下,只需较少的训练数据就可以有效地进行训练。
概述
为了实现上述目标,FELIX将文本编辑任务分解为两个子任务:标记以确定输入单词的子集及其在输出文本中的顺序和插入输入中不存在的单词。标签模型采用了一种新的指针机制,支持结构转换,而插入模型则基于一种隐藏的语言模型。这两个模型都是非自回归的,保证了模型的快速性。FELIX的图示如下。
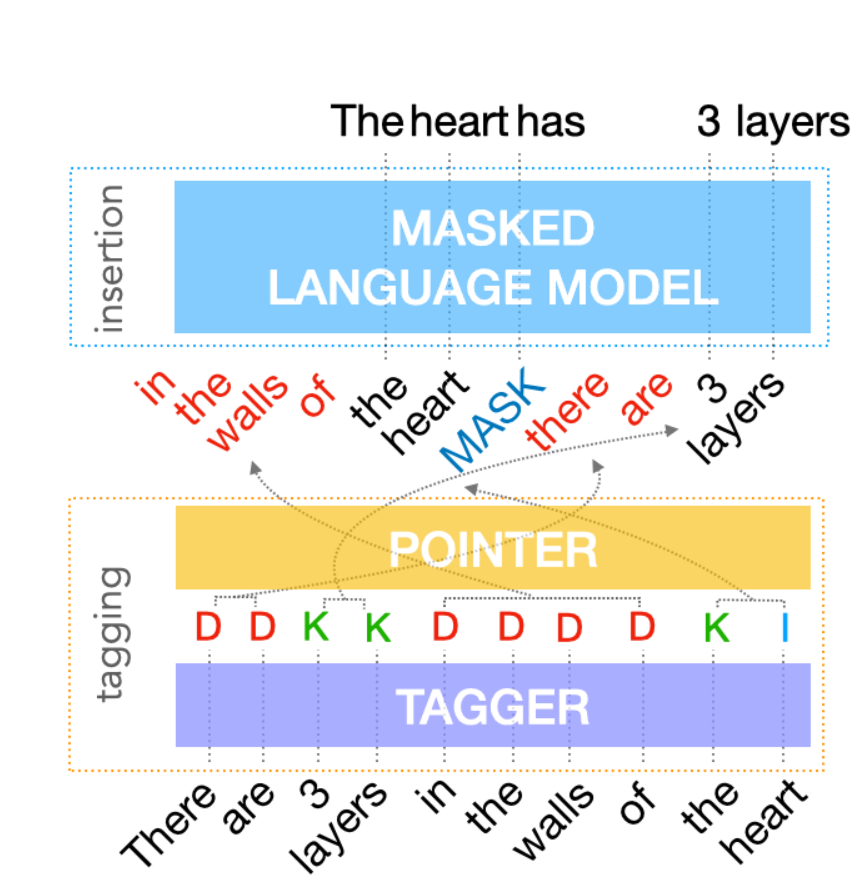
标签模型
FELIX的第一步是标记模型,它由两个组件组成。首先,标记者决定哪些单词应该保留或删除,以及在哪里插入新单词。当标记器预测插入时,一个特殊的掩码token被添加到输出中。在标记之后,有一个重新排序步骤,指针对输入重新排序以形成输出,通过该步骤,指针可以重用输入的部分内容,而不是插入新文本。重新排序步骤支持任意重写,从而可以对大型更改进行建模。指针网络经过训练,使得输入中的每个单词都指向下一个单词,因为它将出现在输出中,如下所示。
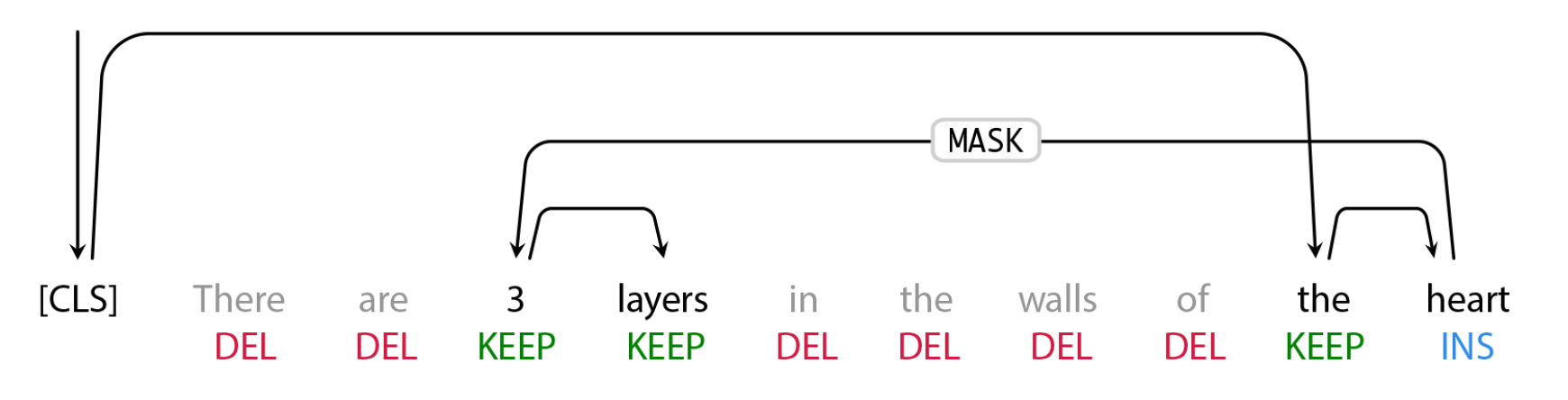
插入模型
标记模型的输出是经过重新排序的输入文本,其中包含已删除的单词和插入标记预测的掩码token。插入模型必须预测掩码token的内容。由于FELIX的插入模型与BERT的预训练目标非常相似,它可以直接利用预训练的优点,在数据有限的情况下,这一点尤为有利。

结果
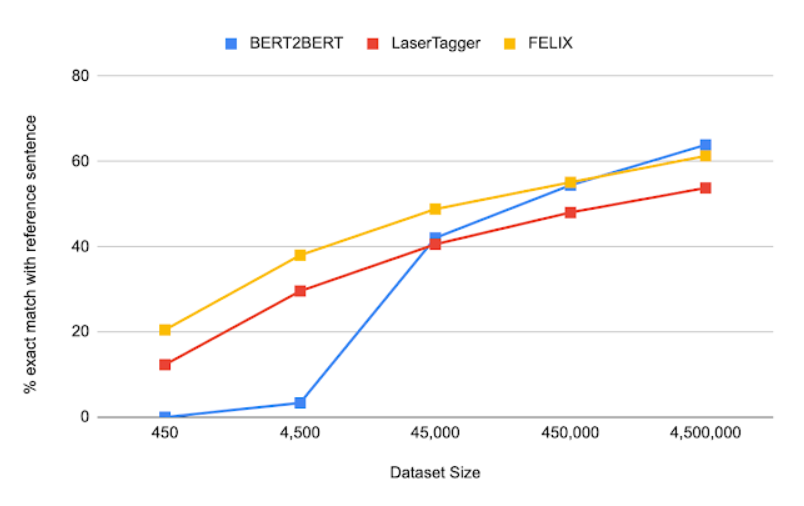
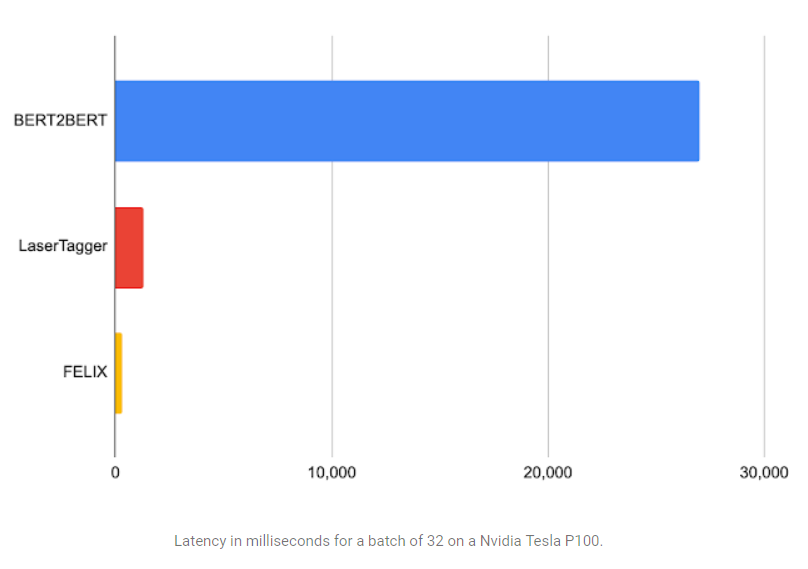
我们评估了FELIX在句子融合、文本简化、自动文摘和机器翻译后编辑方面的表现。这些任务在所需的编辑类型和操作时使用的数据集大小上有很大不同。下面是句子融合任务(即将两个句子合并为一个句子)的结果,在一系列数据集大小下,将FELIX与预训练的Seq2Seq模型(BERT2BERT)和文本编辑模型(LaserTager)进行了比较。我们看到,费FELIX的性能优于LaserTagger,并且仅需几百个训练样本就可以完成训练。对于完整的数据集,自回归BERT2BERT优于FELIX。然而,在推理过程中,这个模型需要花费更长的时间。
结论
我们介绍了FELIX,它是完全非自回归的,提供了更快的推理时间,同时实现了最先进的结果。FELIX还使用了三种技术来最小化所需的训练数据量:微调预训练的checkpoint、学习少量的编辑操作和一个插入任务,该任务模仿预训练的BERTde MLM任务。最后,FELIX在所学编辑操作的复杂性和它能处理的输入输出转换的百分比之间取得了平衡。我们已经为FELIX开源了代码,希望它能为研究人员提供一个更快、更高效、更灵活的文本编辑模型。
(张梦婷编译,周子喻校对)
研究动态
Google用Fourier变换代替BERT的自注意力:92%准确率,在GPU上快了7倍
Google Replaces BERT Self-Attention with Fourier Transform: 92% Accuracy, 7 Times Faster on GPUs
自2017年推出以来,Transformer架构在NLP领域占据主导地位。Transformer应用的唯一限制是其使用的自我注意机制需要巨大的计算成本,事实上它以二次复杂度来衡量序列长度。
来自Google团队的最新研究建议用简单的线性变换来替换自我注意子层,这种线性变换可以“混合”输入token,从而能够以有限的精度成本显著加快Transformer编码器的速度。研究小组还发现用一个标准的、未经参数化的傅立叶变换替换自注意子层,在GLUE基准测试中达到了BERT准确率的92%,在GPU上训练时间快了7倍,在TPU上训练时间快了2倍。

Transformer的自注意力机制使输入能够用高阶单位来表示,从而灵活地捕捉自然语言中不同的句法和语义关系。长期以来,研究人员一直在权衡高复杂性、内存占用和Transformer的性能。但在论文FNet:Mixing Tokens with Fourier performance中,Google提出的FNet是一种在速度、内存占用和准确性之间达成完美平衡的模型。
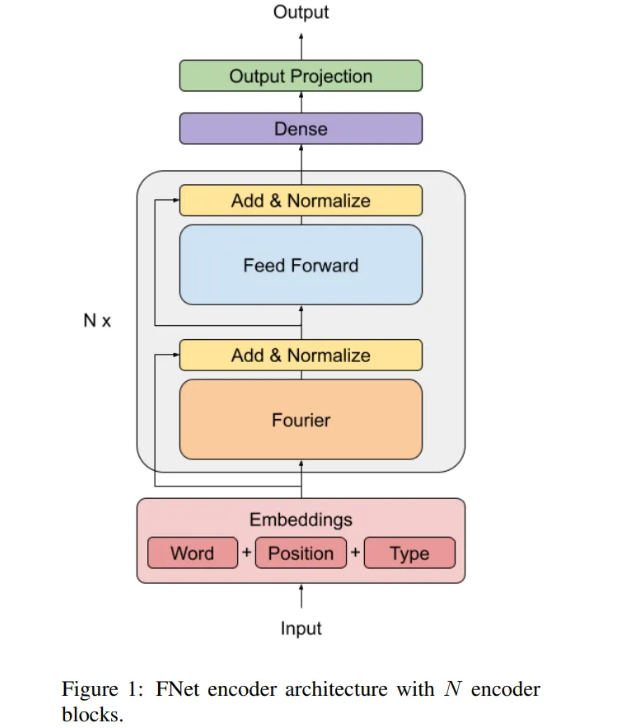
FNet是一个具有多层正则化ResNet的架构,每层由一个Fourier混合子层和一个前馈子层组成。该团队将每个Transformer编码器层的自注意力子层替换为傅里叶变换子层。它们沿着序列维和隐藏维应用一维傅里叶变换。若结果是一个复数,可以写成实数乘以虚数单位i。只保留实数的结果,而无需修改(非线性)前馈子层或输出层来处理叙述。
研究小组决定用傅立叶变换来代替自注意,傅立叶变换是基于19世纪法国数学家Joseph Fourier将时间函数转化为频率函数的技术,因为他们发现这是一种混合token的有效机制,使前馈子层有足够的权限访问所有的token。
在评估中,研究小组比较了多种模型,包括BERT基、FNet编码器(用Fourier子层替换每个自注意子层)、线性编码器(用线性子层替换每个自注意子层),一个随机编码器(用常数随机矩阵替换每个自注意子层)和一个前馈编码器(从变换器层移除自注意子层)。
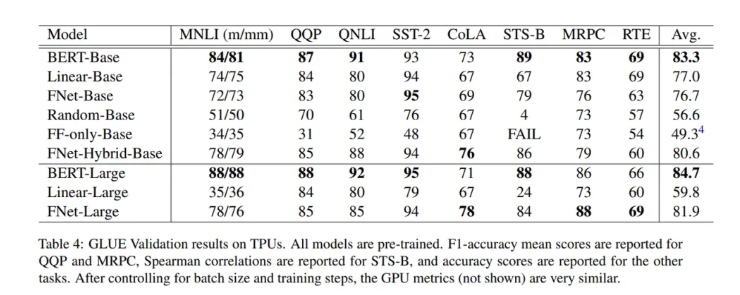
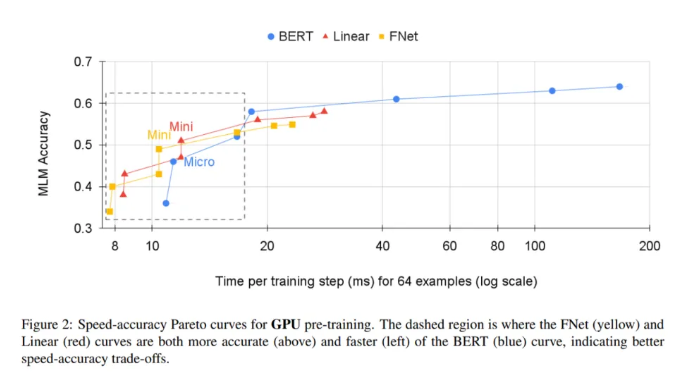
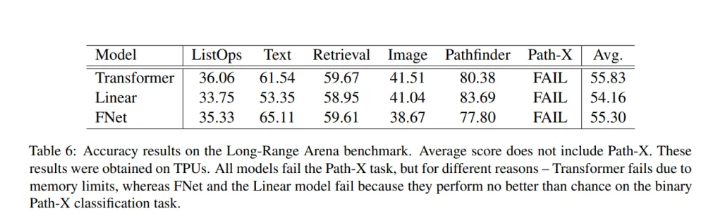
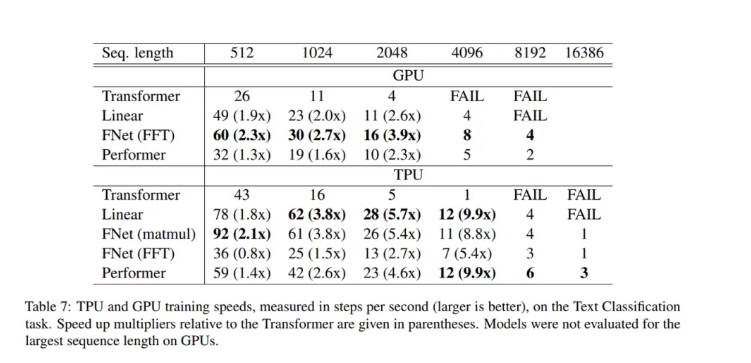
该小组将其结果和FNet表现总结如下:
1.通过用标准的、未参数的傅立叶变换替换注意子层,FNet在GLUE基准上实现了普通分类迁移学习设置中BERT的92%的准确率,但是在GPU上训练速度是普通分类迁移学习设置的7倍,在TPU上训练速度是普通分类迁移学习设置的2倍。
2.FNet混合模型只包含两个自注意子层,在GLUE基准上达到了BERT准确率的97%,但在GPU上的训练速度是在TPU上的近6倍。
3.FNet对于在Long Range Arena基准测试中评估的任何高效Transformer而言具有竞争力,同时在所有序列长度上具有较小的内存占用。
(张梦婷编译,周子喻校对)
华为和清华通过重用教师模型参数,提高了任务无偏BERT蒸馏效率
功能强大的大规模预训练语言模型(如Google的BERT)推动了NLP及其它领域的发展。然而,良好的性能伴随着巨大的计算和内存需求,这使得在资源受限的设备上部署此类模型变得困难。
以前的研究提出了任务无偏的BERT蒸馏方法,旨在获得一个可以像教师模型(如BERT-Base)那样直接进行微调的通用小型BERT。但是,即使是任务无偏的BERT蒸馏在计算上也很昂贵,这是因为涉及到大规模语料库以及需要执行教师模型的正向过程和学生模型的正向、反向过程。
华为诺亚方舟实验室和清华大学的一个研究小组在论文Extract then Distll:Efficient and Effective Task-Agnostic BERT Distillation中提出了提取-再蒸馏(ETD),一种通用而灵活的策略,可重用教师模型参数进行高效和有效的任务无偏提取,可应用于任何规模的学生模型。

研究人员将他们的贡献总结为:
1.提出了一种有效的ETD方法,通过重用教师参数初始化学生模型,提高了任务无偏BERT提取的效率。
2.所提出的ETD方法是灵活的,适用于任何大小的学生模型。
3.证明ETD在GLEU和SQuAD基准上的有效性。
4.证明ETD是通用的,可以应用于现有最先进的蒸馏方法,如TinyBERT和MiniLM,以进一步提高其性能。
5.验证了ETD的提取过程是有效的,几乎不需要额外的计算。
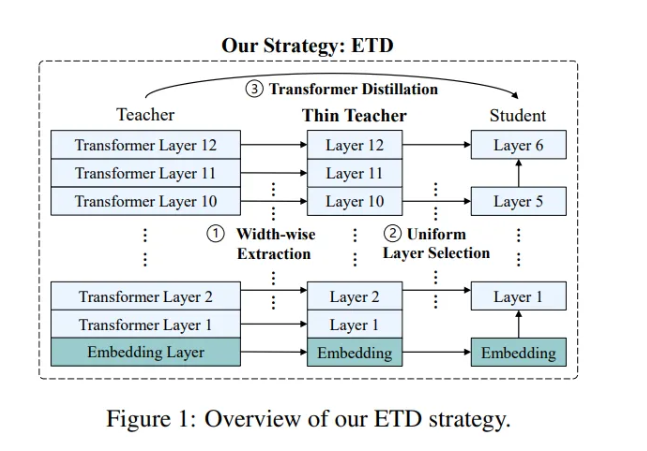
提出的ETD策略包括三个步骤:宽度提取、均匀层选择和Transformer蒸馏。
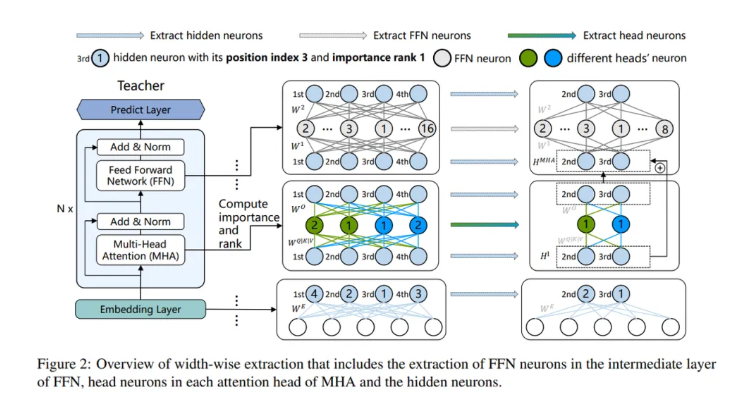
宽度提取将教师模型中的参数提取到更小型的教师模型中。该过程包括FFN神经元、头神经元和隐藏神经元的提取。隐藏神经元的提取遵循隐藏一致性原则,保证提取的不同模块的隐藏神经元具有相同的位置索引。研究人员提出了两种提取教师参数的方法:ETD-Rand随机提取教师参数的宽度,而ETD-Impt则根据重要性得分进行提取。这一步会产生一个与学生模型宽度相同的更小型教师模型。
经过宽度提取后,研究者可以采用均匀层选择策略进行深度提取。具体来说,给定一个具有N个Transformer层的更小教师模型和一个具有M个Transformer层的学生模型,他们将采用统一策略从更小型教师模型中选择M个层来初始化学生模型。
最后,利用提取的参数对学生进行初始化,并在ETD中采用最后一层蒸馏策略。
研究小组使用英文维基百科和多伦多图书语料库作为他们的数据集。他们采用了两个基线模型——BERT-Base(一个隐藏层大小为768的12层Transformer)和DistilBERT(一个宽度与教师模型相同的6层模型)——作为教师来测试ETD的蒸馏性能。他们还将ETD-Impt应用于流行的蒸馏方法(如TinyBERT和MiniLM),以评估ETD的通用性。
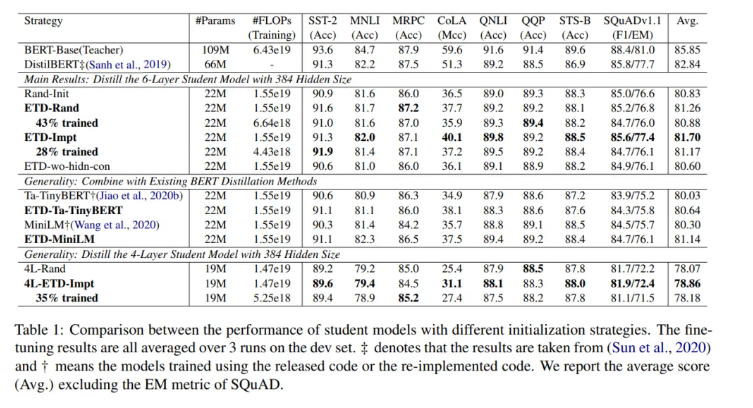
在实验中,ETD-Rand和ETD-Impt策略分别只使用了43%和28%的计算成本,取得了与Rand-Init相当的结果。与TinyBERT和MiniLM相比,ETD-Impt在计算成本低于28%的情况下取得了相似的性能,验证了所提出的ETD方法的效率和通用性。
(张梦婷编译,周子喻校对)
Facebook的动态基准测试Dynabench已发布
Facebook’s Dynabench now scores NLP models for metrics like ‘fairness’
去年9月,Facebook推出了Dynabench,这是一个用于人工智能数据收集和基准测试的平台。Dynabench利用一种被称为动态对抗性数据收集的技术,Facebook认为这是比当前基准所提供的更好的模型质量指标。
今天,Facebook用Dynaboard更新了Dynabench,一个评估即服务平台,用于按需对自然语言处理模型进行评估。该公司声称,Dynaboard不会出现测试代码中的错误、过滤测试数据时的不一致以及其他可重复性问题。
“重要的是,在人工智能研究中,没有单一的正确方法对模型进行排名,自从推出Dynabench以来,我们已经收集了超过40万个例子,并且我们已经发布了两个新的、具有挑战性的数据集。现在,我们在Dynabench内为所有四个最初的正式任务提供了对抗性基准,这些任务最初侧重于语言理解......尽管其他平台已经解决了当前问题的子集,如可重复性、可访问性和兼容性,[Dynabench]在一个单一的端到端解决方案中解决了所有这些问题。”
Dynabench
一些研究表明,常用的基准在估计现实世界的人工智能性能方面做得不好。最近的一份报告发现,自然语言处理模型给出的60-70%的答案被嵌入到基准训练集的某个地方,表明这些模型往往只是在记忆答案。另一项研究——对3000多篇人工智能论文的元分析——发现用于衡量人工智能和机器学习模型的指标往往是不一致的,不规则的跟踪,而且不是特别有参考价值。
Facebook对此的解决方案是Dynascore,一个旨在捕捉模型在准确性、计算、内存、鲁棒性和“公平性”等方面表现的指标。Dynascore允许人工智能研究人员通过对一系列测试给予更多或更少的重视(或权重)来定制评估。
当用户使用Dynascore来衡量模型的性能时,Dynabench会跟踪哪些例子愚弄了模型并导致对自然语言推理、问题回答、情感分析和仇恨言论等核心任务的错误预测。这些例子改善了系统,并成为训练下一代模型的更具挑战性的数据集的一部分,而这些模型又可以用Dynabench进行基准测试,以创造一个研究进展的“良性循环”。
众包注释者连接到Dynabench并收到关于模型反应的反馈。这使他们能够采用一些策略,如让模型关注错误的单词或尝试回答需要真实世界知识的问题。Dynabench上的所有例子都由其他注释者验证,如果注释者不同意原始标签,那么这个例子就会从测试集中丢弃。
评价指标
准确性是指模型做对的例子的百分比。计算,是Dynascore的另一个组成部分,衡量一个NLP模型的计算效率。为了说明计算情况,Dynascore衡量模型在Facebook的评估云中的实例上每秒可以处理的例子数量。
为了计算内存使用量,Dynascore以千兆字节的总内存使用量来衡量一个模型所需的内存量。模型运行期间的内存使用量是按时间平均的,在设定的秒内进行测量。
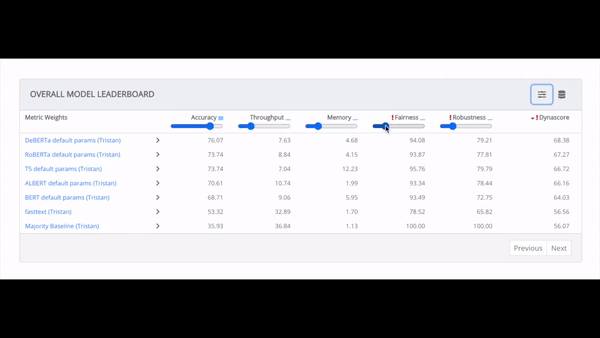
最后,Facebook声称Dynascore可以通过测试来评估一个模型的公平性,除其他外,该测试将数据集中的名词短语性别(例如,用 "兄弟"替换 "姐妹"或用“他们”替换“他”)与其他在统计学上能预测另一个种族或民族的名字替换。就Dynaboard评分的目的而言,如果一个模型在这些变化后其预测保持稳定,则被视为公平。
Facebook承认,这种公平性的衡量标准并不完美。例如,用“她的”或“她”替换“他的”在英语中可能有意义,但有时会导致语境错误。如果Dynaboard将“这只猫是他的”这句话中的“他的”替换成“她的”,结果将是“这只猫是她的”,这并没有保持原来的意思。
计算分数
为了将不同的指标合并成一个分数,用于在Dynabench中对模型进行排名,该平台采用加权平均值来计算Dynascore,因此,随着权重的调整,模型可以实时动态地重新排名。
为了计算调整的速度,Dynaboard使用了一个叫做"边际替代率"(MRS)的公式,在经济学中,边际替代率是指消费者在获得相同效用的情况下,愿意为另一种商品放弃的数量。要得出默认的Dynascore,需要估计用户愿意用每项指标换取1分的性能的平均比率,并使用该比率将所有指标转换成性能单位。
Dynaboard可供研究人员通过一个名为Dynalab的新命令行界面工具和库提交自己的模型进行评估。在未来,该公司计划将Dynabench开放,这样任何人都可以在循环中运行自己的任务或模型进行数据收集,同时托管自己的动态排行榜。
(周子喻编译,赵海喻校对)
研究显示Transformer拥有数学推理的构成能力
Study Shows Transformers Possess the Compositionality Power for Mathematical Reasoning
从哲学角度来看,还原论是世界上最自然的概念:通过理解其部分可以理解一个整体。当涉及到认知科学时,这个想法可以通过构成性原则来体现:人类根据感官观察推断结构和关系,并将这些信息与现有的知识结合起来,指导将较简单的意义构成复杂的整体。
在自然语言处理中使用强大的人工神经网络已经将构成性推进到用大量的语言数据进行训练可以揭示其表示中的语法结构。在一项新的研究中,来自加州大学戴维斯分校、微软研究院和约翰霍普金斯大学的一个研究小组将这种方法扩展到数学推理领域,表明标准Transformer架构和TP-Transformer都可以根据数学符号的结构关系来构成它们的含义。

最先进的Transformer架构在各种NLP任务上取得了令人印象深刻的结果。这些神经网络学习用高维向量对输入序列进行编码,该向量可以携带丰富的语义信息和关于输入的相关语言子成分的额外信息。一些研究表明,这类模型能够提取和组合各部分的含义,以提高其在任务中的表现。
在 Compositional Processing Emerges in Neural Networks Solving Math Problems 一文中,研究人员将Transformer应用于数学推理领域,以评估深度神经网络是否有能力通过获取和组合其子表达式的含义来得出整个算术表达式的含义。例如,1*9+2*3的值是通过对子表达式1*9和2*3的值进行合成得到的,最终结果为15。
该研究使用了标准Transformer和TP-Transformer,这些Transformer是在一个包含1.12亿个数学单词问题的数学数据集上训练出来的,涵盖了算术、代数、微积分、概率等。标准Transformer和TP-Transformer都有一个处理问题的编码器和一个产生输出的解码器。两者都包含六个Transformer层,其多头注意力模块包括八个。每层的每个头为每个输入生成一个Query、Key和Value向量。对Query和Key的按比例点积取一个softmax,产生注意力分布。最后的输出是加权注意力分布的值向量的平均值。TP-Transformer与标准Transformer不同,它有额外的角色向量,旨在明确地捕捉输入中的结构或关系信息。

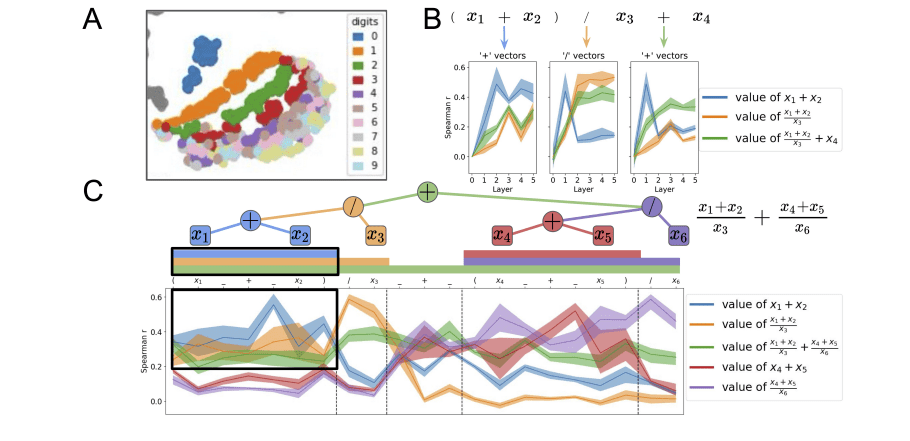
研究人员进行了实验来评估所提出的方法。结果证实,神经网络不仅能够推断出其训练数据中隐含的结构关系,而且还能利用这种知识来指导将单个意义组成复合整体。
(赵海喻编译,张梦婷校对)
项目工具
用于测量文本相似性的BERT
BERT能够将单词的含义嵌入到密集向量中。称为密集向量的原因是向量中的每个值都有一个值,并且有成为该值的理由——这与稀疏向量形成对比,例如one-hot编码向量,其中大多数值为0。BERT很擅长创建密集向量,每个编码器层(有几个)都会输出一组密集向量。
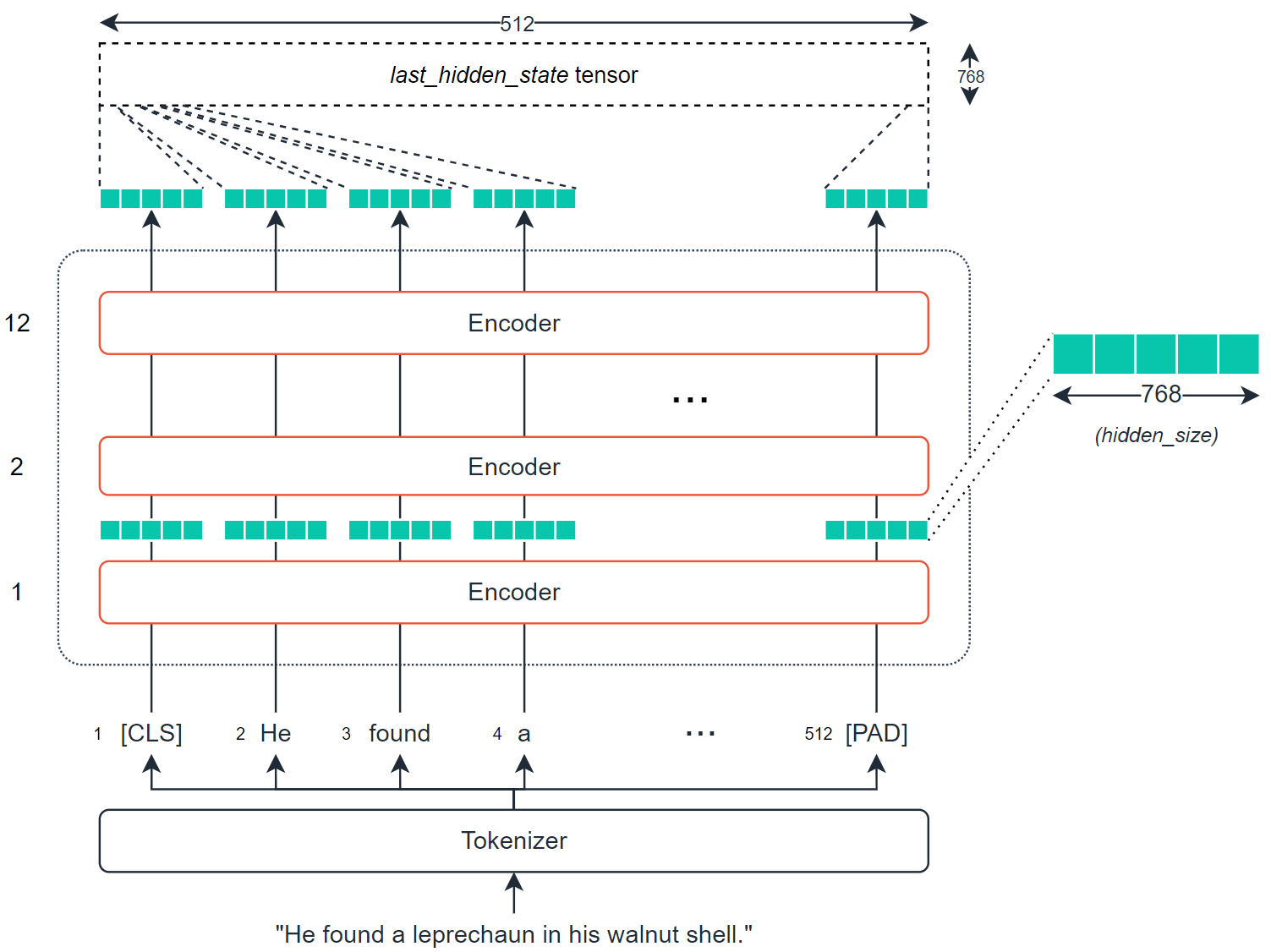
对于BERT-base来说,这将是一个包含768个值的向量。这768个值包含我们对单个标记的数字表示——我们可以将其作为上下文词嵌入。
因为每个符号都有一个这样的向量(由每个编码器输出),所以我们实际上是在看一个大小为768的张量,即符号的数量。我们可以对张量进行转换,以创建输入序列的语义表示。然后,我们可以计算不同序列之间各自的相似度。
最简单和最常用的提取张量是last_hidden_state张量,它由BERT模型方便地输出。张量的大小是512x768,我们想要一个矢量来应用我们的相似性度量。要做到这一点,我们需要将last_hidden_states张量转换为一个768维的向量。
创建矢量
我们使用平均值池化操作将last_hidden_states张量转换为向量。这512个token中的每一个都有768个值。这种集合操作将计算所有token嵌入的平均值,并将其压缩到一个768维矢量空间中,创建一个"句子矢量"。
代码
我们将概述两种方法:简单的方法和进阶的方法。
简单—— sentence-transformers
首先,使用 pip install sentence-transformers 安装 sentence-transformers。这个库在幕后使用HuggingFace的transformer - 所以我们实际上可以在这里找到sentence-transformer模型。
我们将利用bert-base-nli-mean-tokens模型来实现。它使用128个输入token,而不是512个。
让我们创建一些句子,初始化我们的模型,并对句子进行编码。
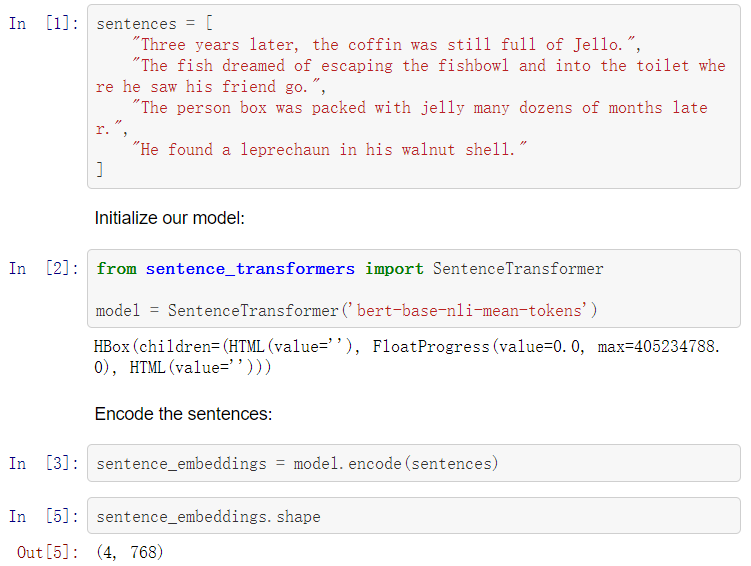
很我们现在有四个句子嵌入——每个都包含768个值。
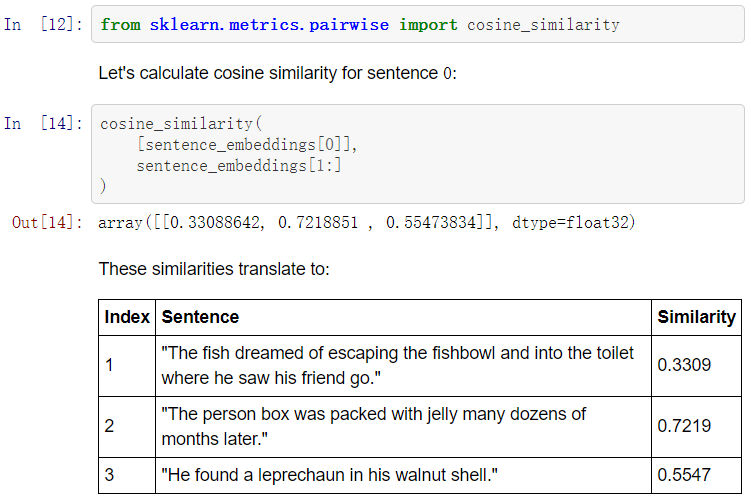
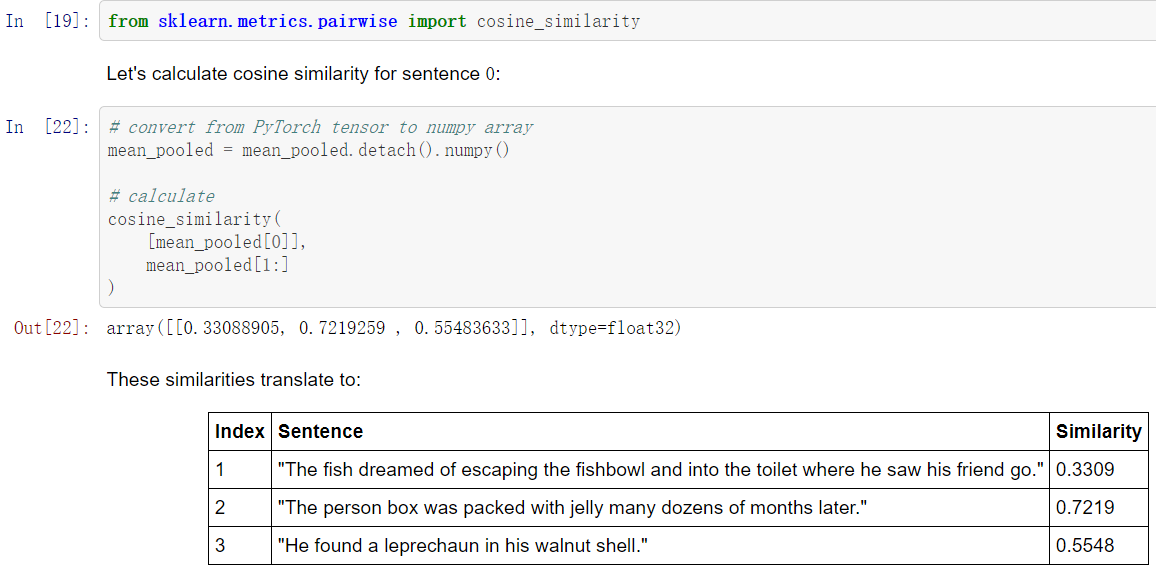
现在我们要做的是,利用这些嵌入,找到每个嵌入之间的余弦相似度。因此,对于0号句子:
Three years later, the coffin was still full of Jello.
我们可以用以下方法找到最相似的句子。
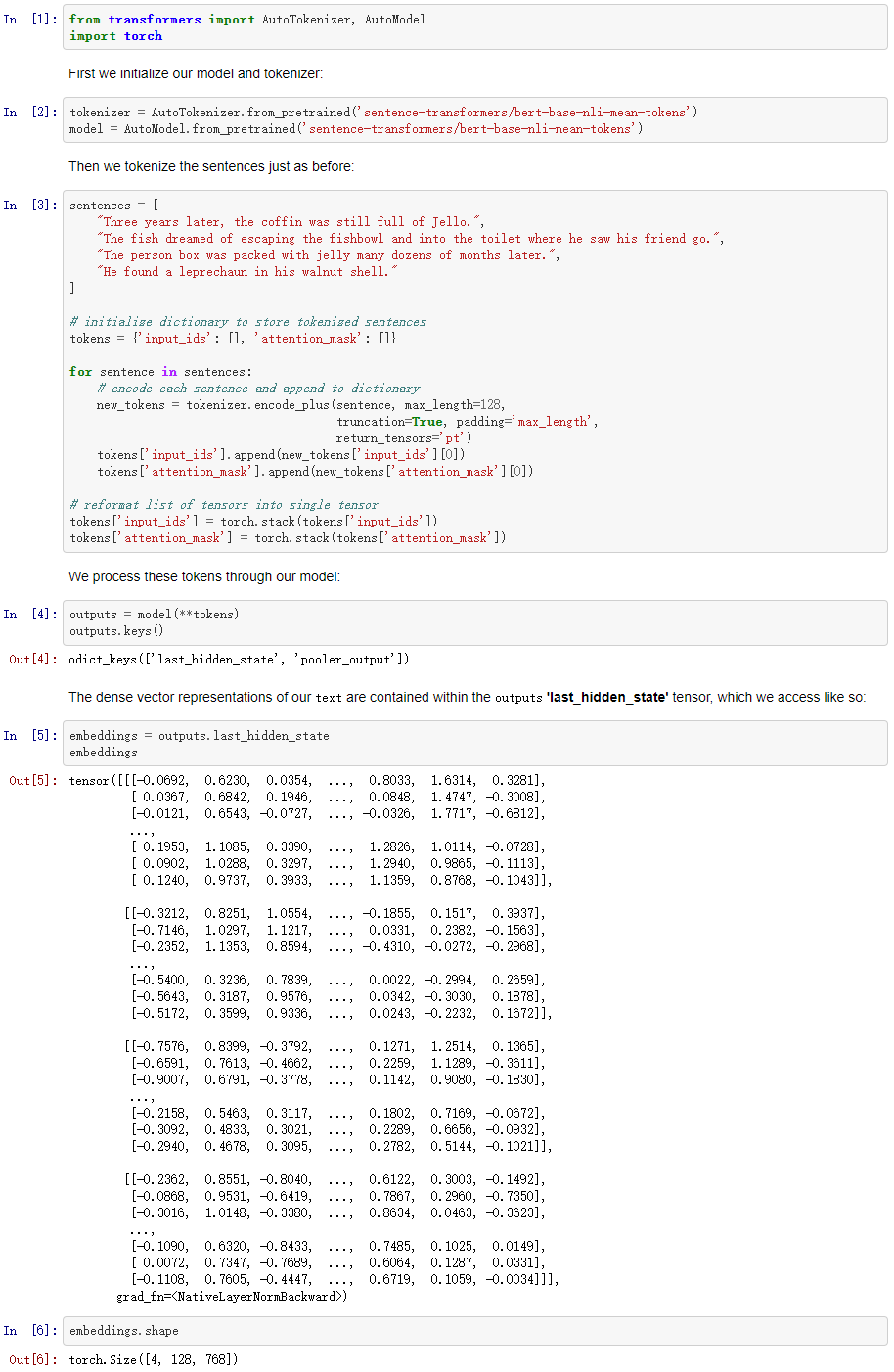
进阶—— transformers和PyTorch
创建last_hidden_state,然后对last_hidden_state进行进行了平均值池化操作,以创建句子嵌入。
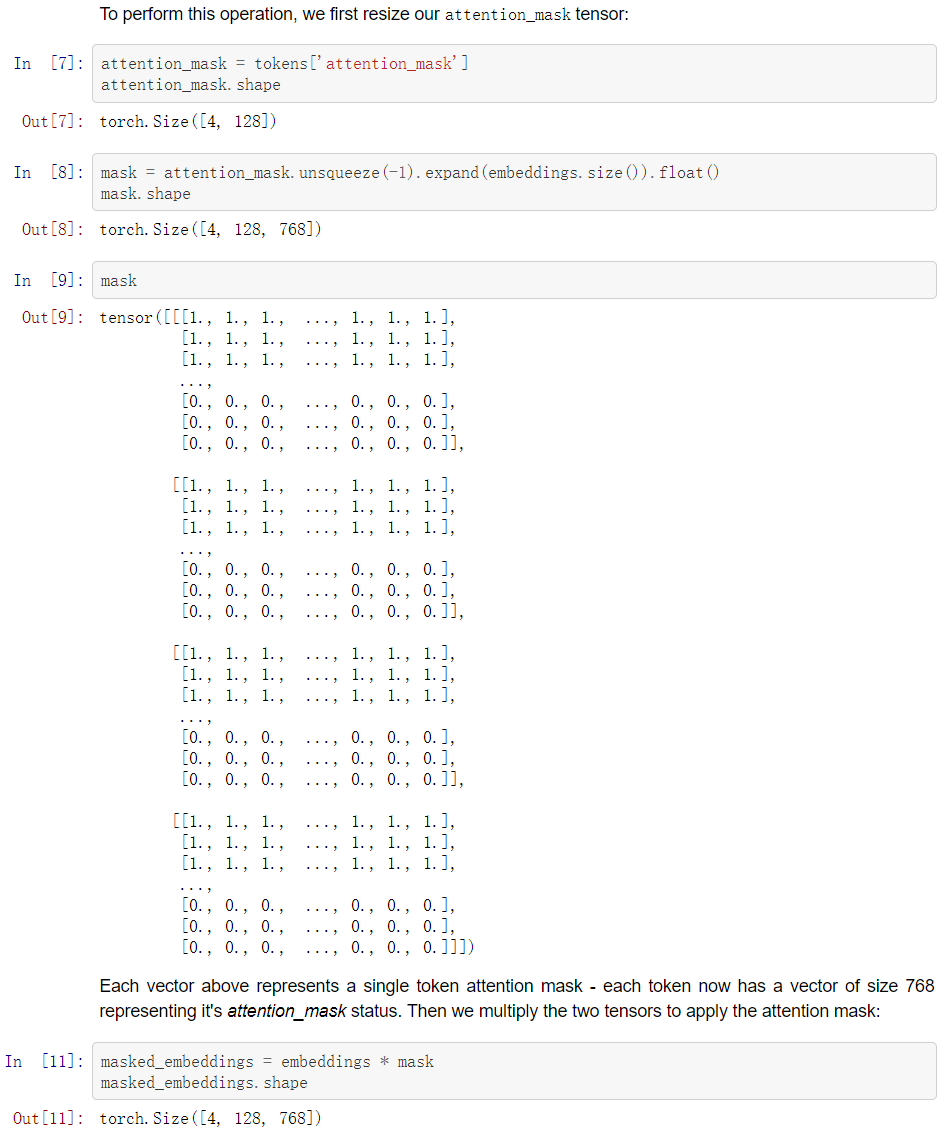
在我们产生了我们的密集向量嵌入后,我们需要进行平均值池化操作,以创建一个单一的向量编码(句子嵌入)。
为了进行这种平均值池化操作,我们将需要把我们的嵌入张量中的每个值都乘以其各自的attention_mask值,这样我们就可以忽略非真实的标记。
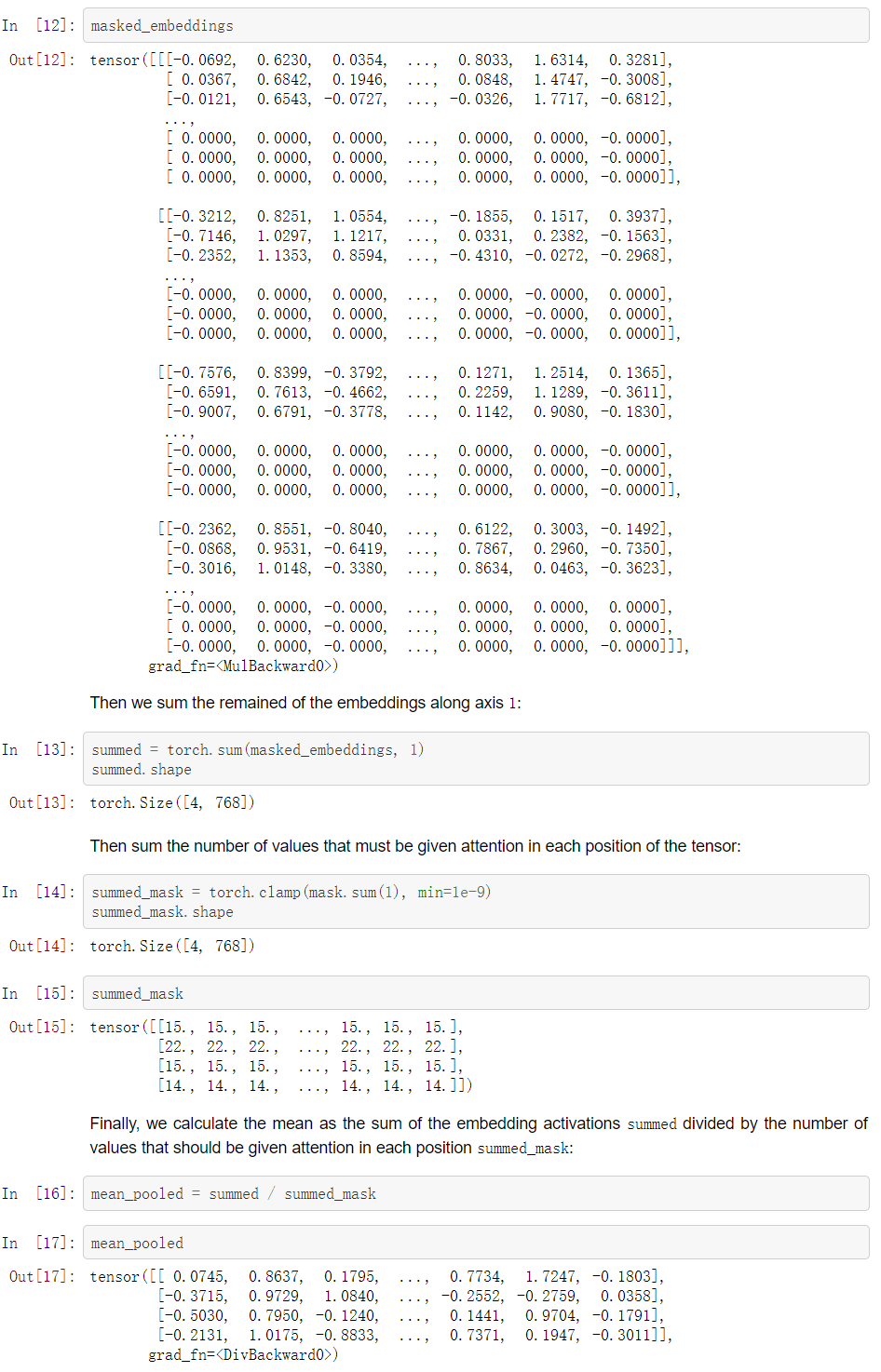
一旦我们有了密集向量,我们就可以计算每个向量之间的余弦相似度。
(周子喻编译,赵海喻校对)
近期论文
True Few-Shot Learning with Language Models
摘要
预训练语言模型在许多任务中表现良好,即使是从少数样本中学习。但之前的工作用许多保留样本微调学习的各方面,如超参数、训练目标和自然语言模板。本文评估了保留样本不可用时,语言模型的少样本能力,并把这种设置称为真少样本学习。测试了两种模型选择标准,交叉验证和最小描述长度,用于在真少样本学习环境中选择语言模型的提示和超参数。平均来说,这两种方法都略优于随机选择,大大低于基于保留样本的选择。此外,选择标准往往倾向于选择那些表现明显比随机选择更差的模型。即使考虑到在选择过程中对模型真实性能的不确定性,以及改变用于选择的计算量和样本数量,也发现了类似的结果。研究结果表明,考虑到少样本模型选择的难度,之前的工作大大高估了语言模型的真少样本能力。
主要贡献
我们发现,真正的少样本模型选择产生的提示略微优于随机选择,而大大低于基于保留实例的选择。我们的结果表明,之前的工作可能大大高估了LM的few-shot能力。换句话说,提示如此有效的一个原因是,它们经常使用许多例子进行调整。此外,真正的几率模型选择在性能上有很高的差异;选择的模型往往比随机选择的模型差很多。我们发现,在改变所使用的例子数量、计算量和我们选择标准的保守性时,也有类似的结果。总的来说,我们的结果表明,模型选择是真少样本学习的一个基本障碍。
最近关于LM的工作是通过以自然语言 "提示 "的形式提供训练实例作为输入来进行few-shot学习。例如,对于一个回答问题的任务,在向GPT-3提供输入例子之前,先在输入例子中加上 "阅读理解答案提示"。然后,他们让LM按照LM的预训练目标(下一个单词的预测)完成提示中的剩余单词,对早期的单词(包括各种输入例子)进行调节。不涉及参数更新。
实验
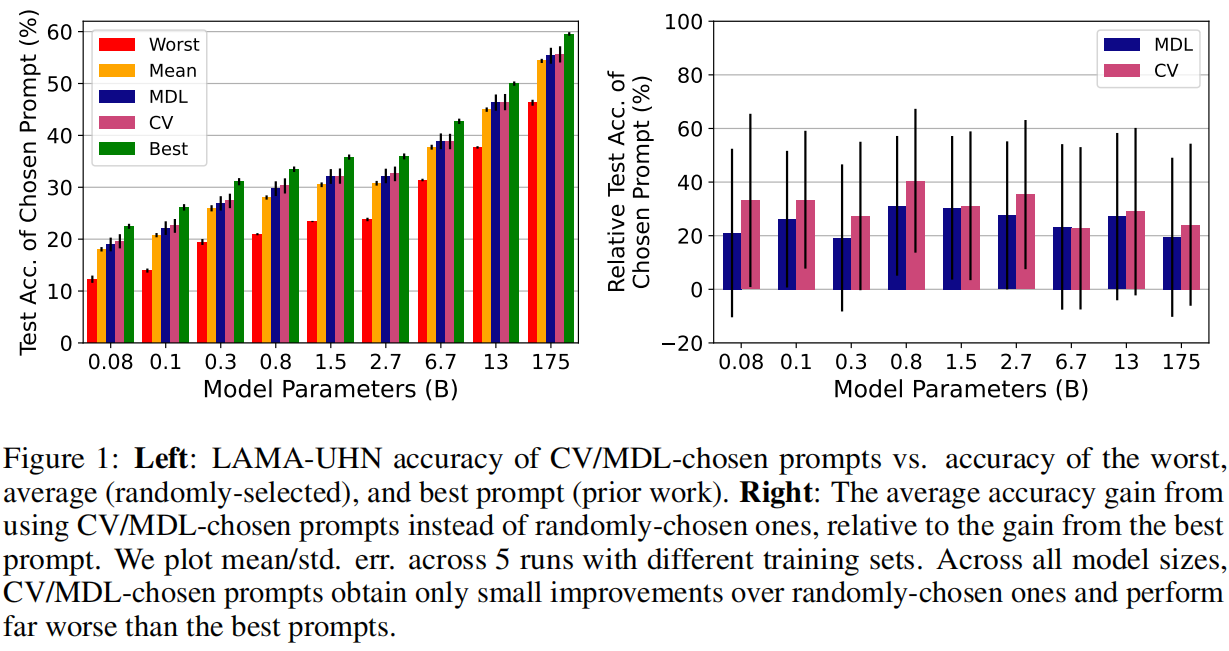
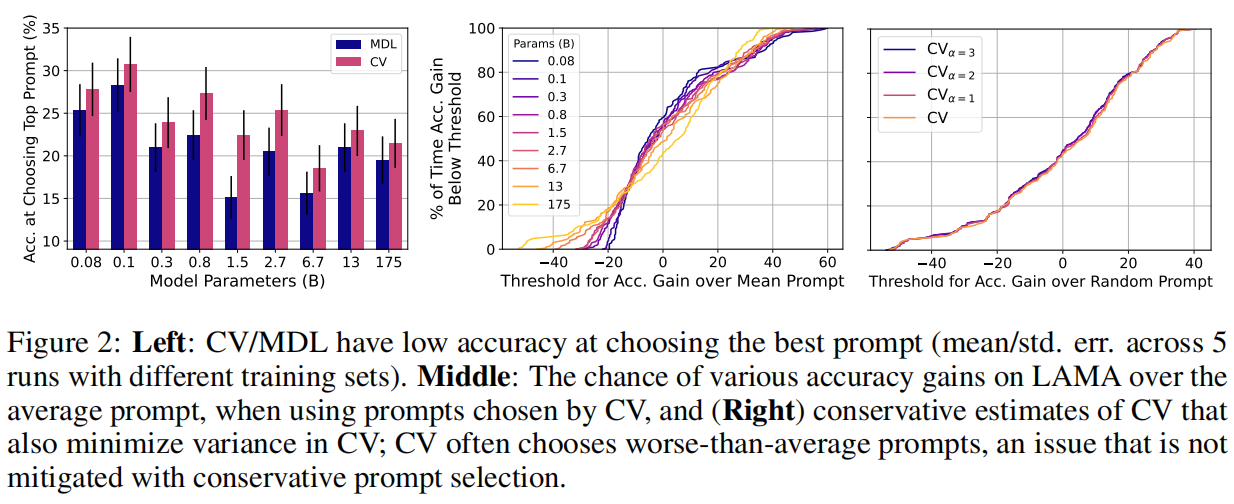
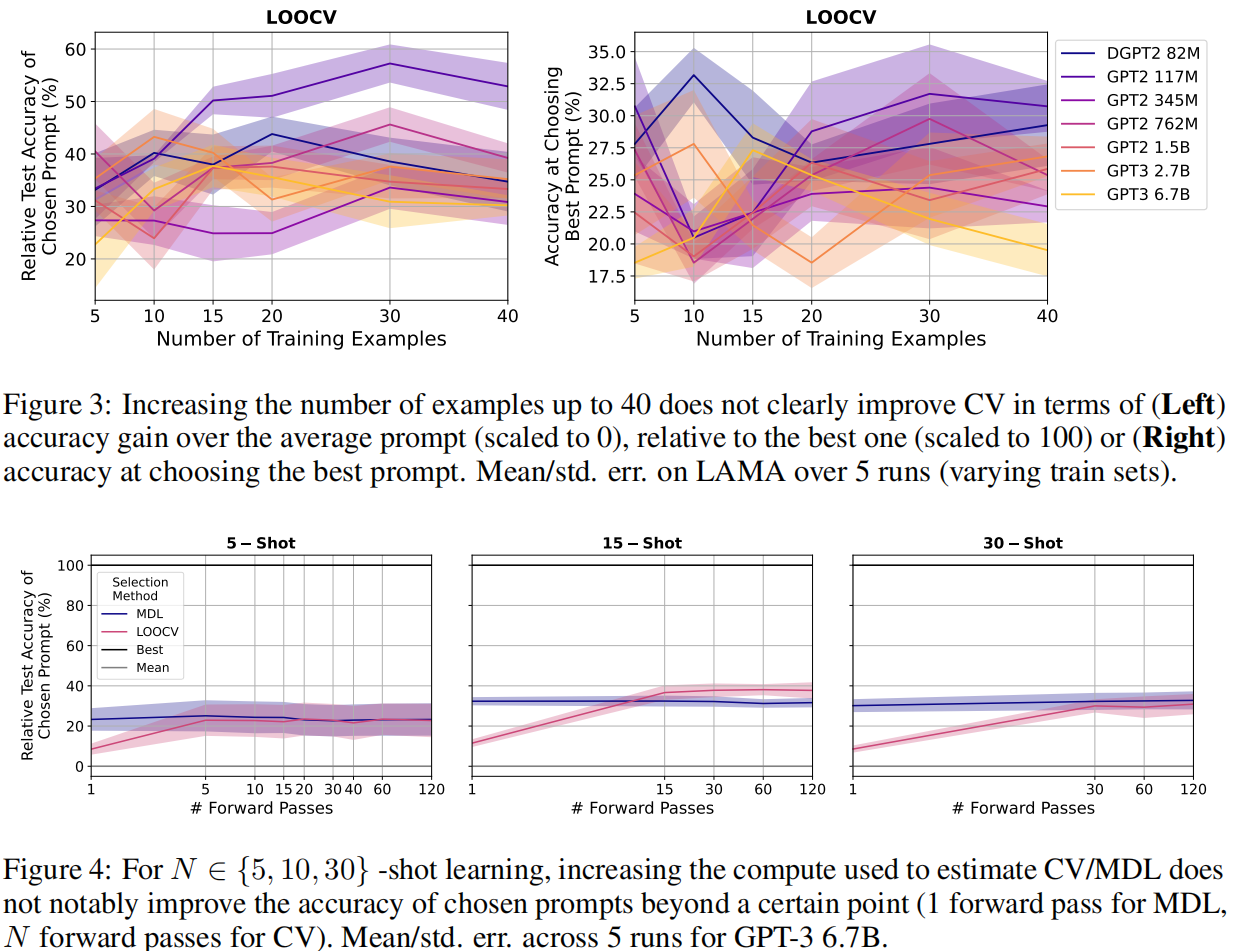
本文评估了两个标准的模型选择标准——交叉验证(CV)和最小描述长度(MDL)——发现这两个标准与随机选择相比只获得了有限的改进,而且比使用保留的例子进行选择要差很多。对于提示性选择,我们的观察结果在3个分类任务和LAMA基准的41个任务中对9个LM的规模超过3个数量级的情况下成立。对于选择超参数来说,真正的几率选择会使ADAPET(一种最先进的few-shot方法)在8个任务中的性能下降2-10%。
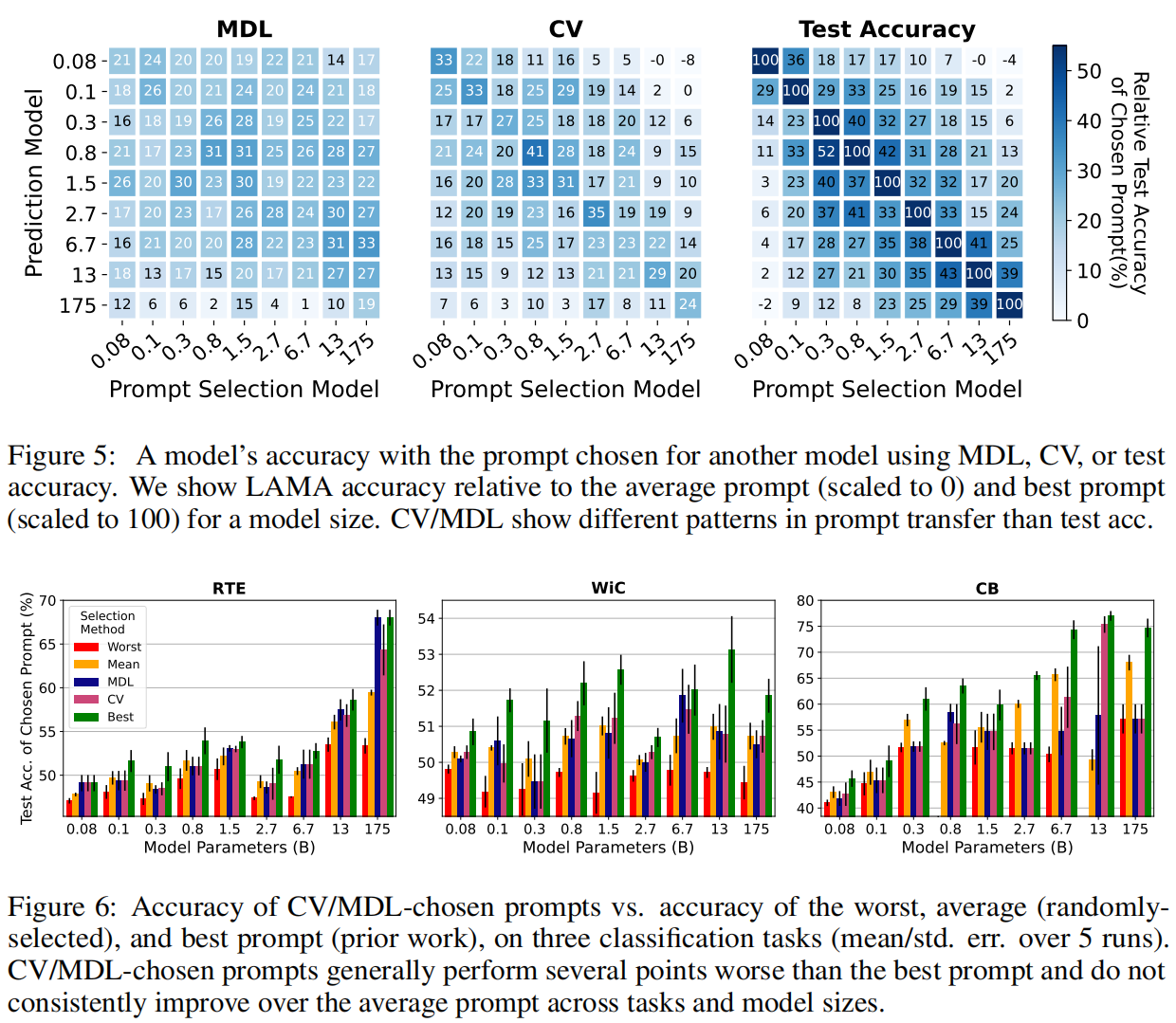
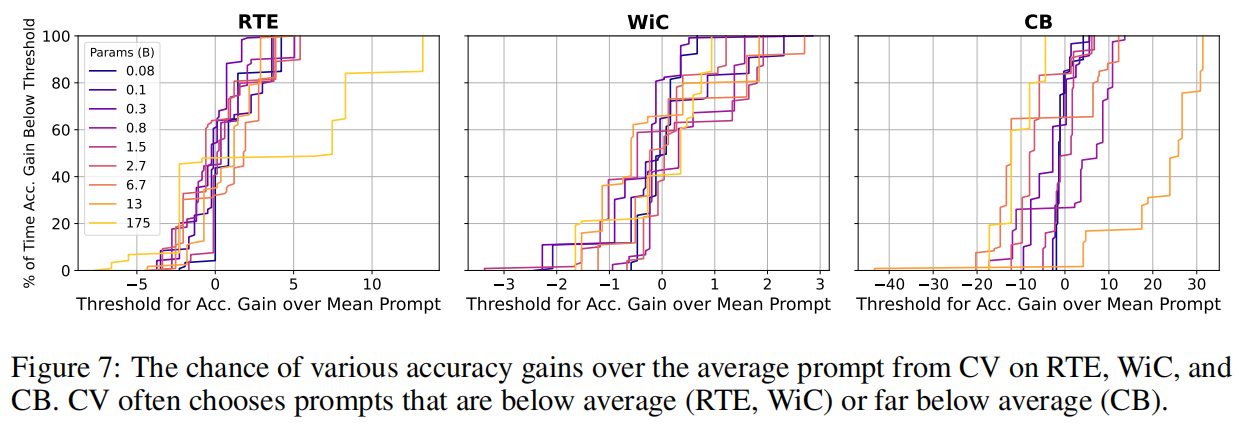
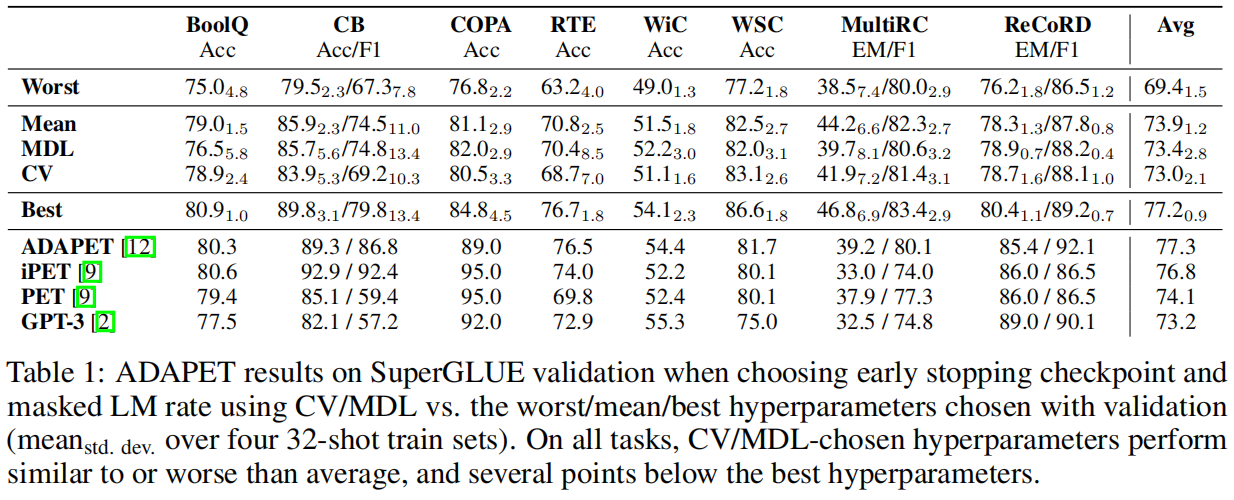
代码链接:https://github.com/ethanjperez/true_few_shot https://github.com/ethanjperez/true_few_shot
(周子喻编译,赵海喻校对)
Focus Attention:Promoting Faithfulness and Diversity in Summarization
摘要
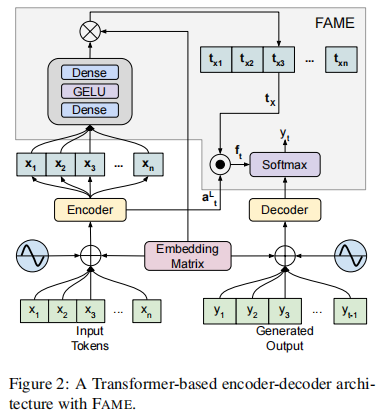
专业的摘要是以文件级别的信息来编写的,例如文件的主题。这与大多数Seq2Seq解码器形成鲜明对比,后者在每个解码步骤中同时学习关注突出的内容,同时决定生成什么。为了缩小这一差距,我们引入了焦点注意机制(Focus Attention MEchanism,FAME),这是一种简单而有效的方法,鼓励解码器主动生成与输入文档相似或有主题的标记。此外,我们还提出了焦点抽样的方法,以便能够生成多样化的摘要,目前在文本摘要方面这是一个研究不足的领域。
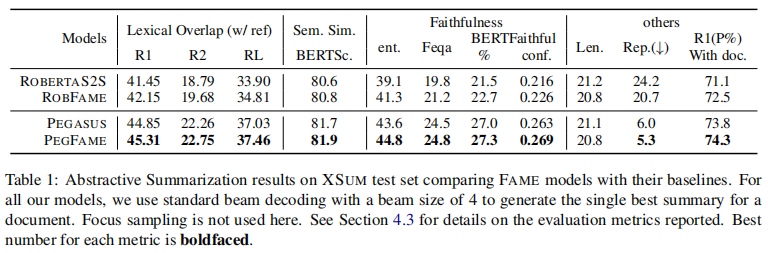
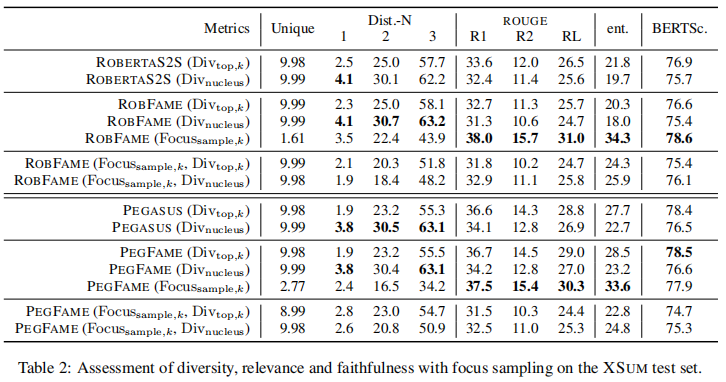
在对BBC的极端总结任务进行评估时,两个最先进的模型在焦点注意的增强下,生成的总结更接近目标,更忠实于其输入文档,在ROUGE和多种忠实度指标上都优于其普通模型。我们还从经验上证明,与基于top-k或核抽样的解码方法相比,焦点抽样在生成多样化和忠实的摘要方面更为有效。
模型架构
1.基于Transformer的 seq2seq模型
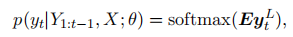
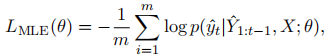
2.焦点注意机制
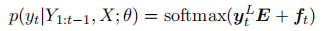
3.摘要诱导的主题集中分布
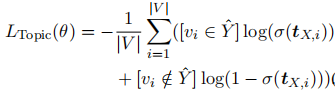
4.焦点抽样
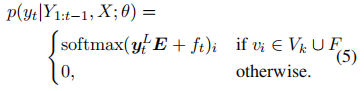
实验
(赵海喻编译,张梦婷校对)
近期会议
PAKDD 2021: Pacific-Asia Conference on Knowledge Discovery and Data Mining
May 11 - May 24 Delhi,India
PAKDD是在数据挖掘和知识发现领域中成立时间最长、领先的国际会议之一。它为研究人员和行业从业者提供了一个国际论坛,分享他们的新想法、原始研究成果和所有KDD相关领域的实际开发经验,包括数据挖掘、数据仓库、机器学习、人工智能、数据库、统计学、知识工程、可视化、决策系统和新兴应用。
(张梦婷)
DNLP 2021: International Conference on Data Mining and NLP
Aug 21 Chennai, India
DNLP 2021将提供一个极好的国际论坛,以分享数据挖掘和NLP的理论、方法和应用方面的知识和成果。 这次会议的目的是将学术界和工业界的研究人员和从业人员聚集在一起,集中精力于理解数据挖掘和NLP概念,并在这些领域建立新的合作关系。
(张梦婷)
NLPCC 2021:Natural Language Processing and Chinese Computing
Oct 12 - Oct 17 Chennai, India
NLPCC是一个领先的国际会议,专门研究自然语言处理(NLP)和中文计算(CC)领域。NLPCC在CCF推荐的CS会议列表中。它是学术界、工业界和政府的研究人员和实践者分享他们的想法、研究成果和经验,并促进他们在该领域的研究和技术创新的主要论坛。
(张梦婷)