文本挖掘与机器学习跟踪扫描动态快报(2021.06)
实时跟踪、关注文本挖掘与机器学习领域最新研究动态
深度观察
Transformer可视化解释
Transformers Explained Visually — Not Just Now,but Why They Work So Well
输入序列如何到达注意力模块
注意模块存在于编码器堆叠的每个编码器以及解码器堆叠的每个解码器中。我们先放大编码器注意力。
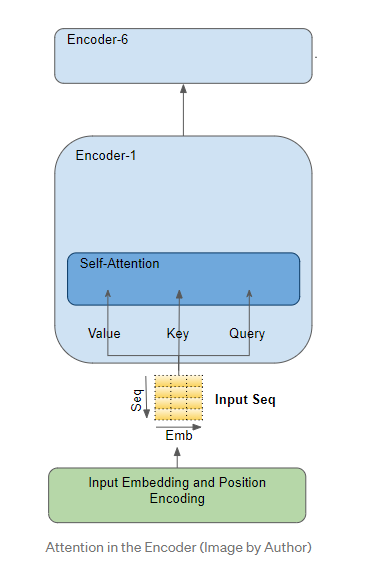
举个例子,假设我们正在解决一个英语到西班牙语的翻译问题,其中一个样本源序列是“The ball is blue”。 目标序列是“La bola es azul”。源序列首先通过嵌入和位置编码层,该层为序列中的每个字生成嵌入向量。嵌入被传递到编码器,它首先到达注意模块。在注意力机制中,嵌入的序列通过三个线性层传递,并生成三个独立的矩阵(Query、Key和Value)。这些是用来计算注意力权重的三个矩阵。
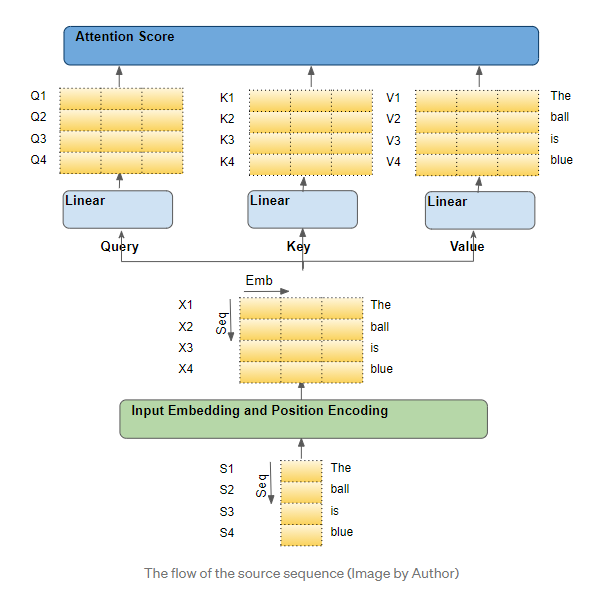
每个输入行是序列中的一个单词
从源代码序列中的单个单词开始,然后沿着它们通过Transformer的路径。特别是,我们要关注注意力模块内部发生的事情。这将帮助我们清楚地看到源序列和目标序列中的每个单词是如何与源序列和目标序列中的其他单词相互作用的。为了简化解释和可视化,让我们忽略嵌入维度,只跟踪每个单词的行。
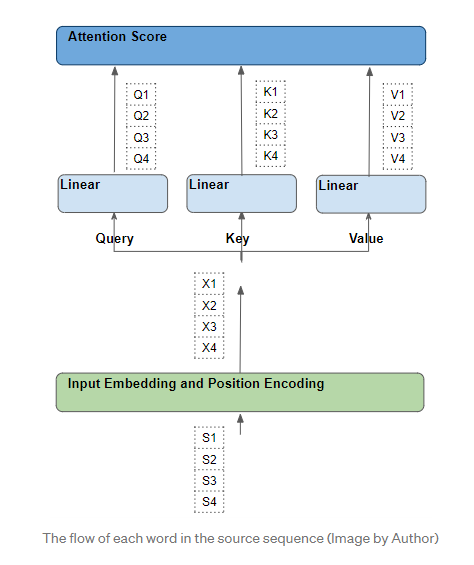
每个单词都经过一系列可学习的转换
每个这样的行都是通过一系列的转换(嵌入、位置编码和线性层)从其对应的源字生成的。所有这些转换都是可训练的,这意味着这些操作中使用的权重不是预先决定的,而是通过模型学习的,从而产生所需的输出预测。
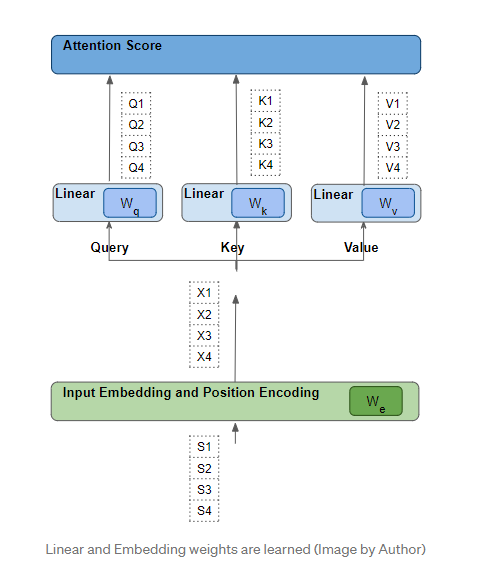
关键的问题是,Transformer如何计算出哪一组权重将给它带来最好的结果?
注意力得分——Query和Key之间的点积
这里我们将只关注线性层和注意力得分。
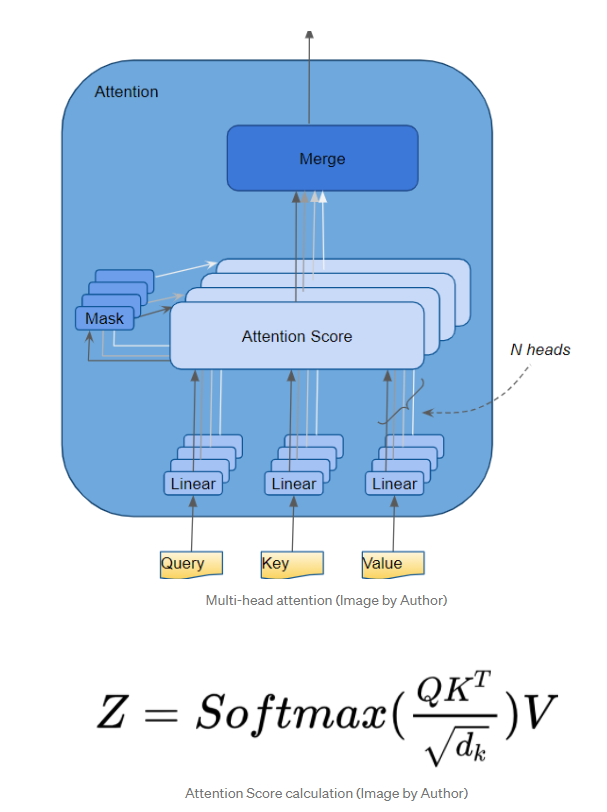
从公式中我们可以看出,注意力中的第一步是在Query矩阵和Key矩阵的转置之间进行矩阵乘法(即点积)。我们生成一个中间矩阵(我们称之为“因子”矩阵),其中每个单元格是两个单词之间的矩阵乘法。
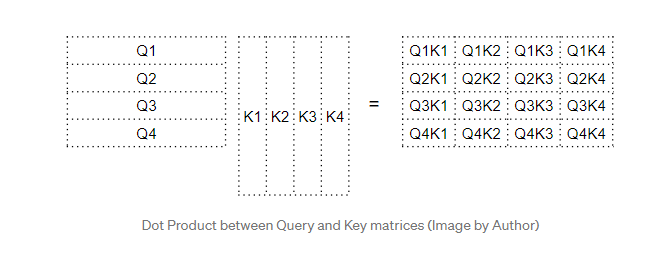
例如,第四行中的每一列对应于第四个Query与每个Key之间的点积。
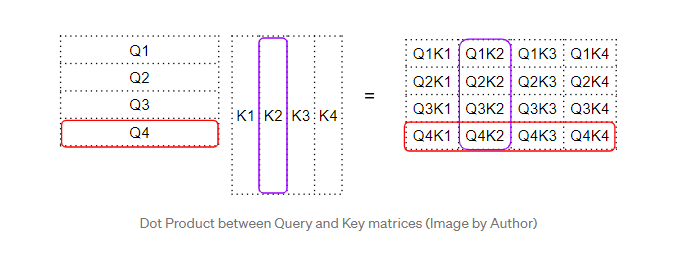
注意力得分——Query-Key 和 Value 之间的点积
下一步是这个中间“因子”矩阵和Value矩阵之间的矩阵相乘,以产生注意力模块输出的注意力得分。这里我们可以看到,第四行对应于第四个查询词矩阵乘以所有其他Key和Value。
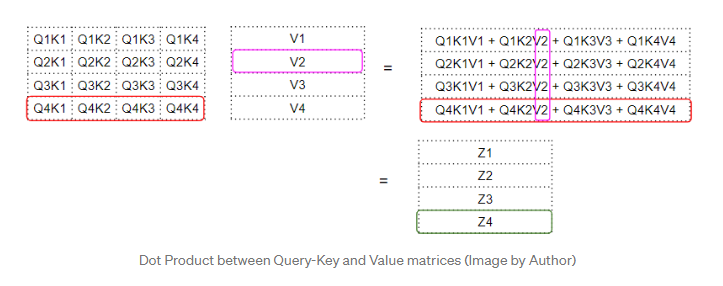
这产生由注意力模块输出的注意力得分向量(Z)。考虑输出分数的方法是,对于每个单词,它是来自Value矩阵的每个单词的编码值,由“因子”矩阵加权。因子矩阵是特定单词的Query值与所有单词的Key值的点积。

Query、Key和Value的作用是什么?
Query可以解释为我们计算注意力的词。Key和Value是我们正在关注的词,即该词与查询词的相关性如何。
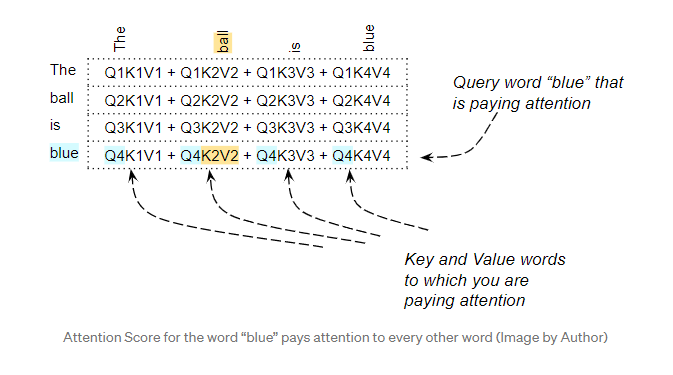
例如,对于句子“The ball is blue”,“blue”这个词的行将包含“blue”以及其它每个词的注意力权重。这里,“blue”是查询词(Query),其它词是“Key/Value”。
还有其它正在执行的操作,例如除法和softmax,但是在本文中我们可以忽略它们。它们只是改变矩阵中的数值,但不影响矩阵中每个单词行的位置。也不涉及任何词间的关系
点积表示了单词之间的相似性
所以我们已经看到,注意力得分是通过做点积,然后把它们相加,来捕捉一个特定单词和句子中其他每个单词之间的相互作用。但是矩阵乘法如何帮助Transformer确定两个单词之间的相关性呢?要理解这一点,请记住Query、Key和Value行实际上是具有嵌入维度的向量。让我们放大这些向量之间的矩阵乘法是如何计算的。
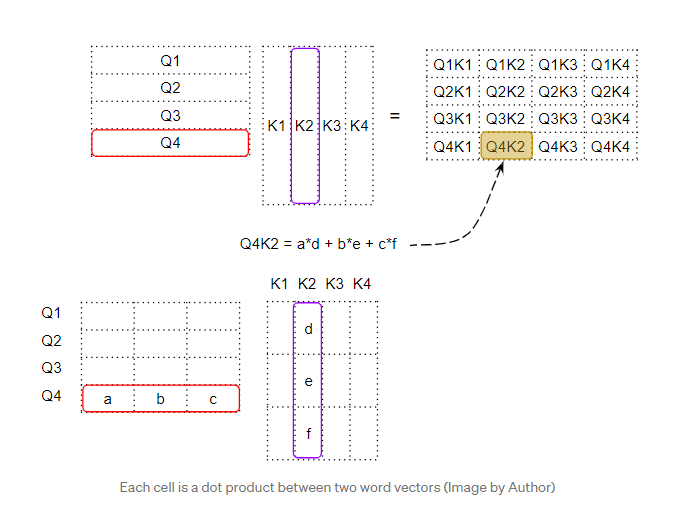
当我们在两个向量之间做点积时,我们将成对的数字相乘,然后求和。
- 如果两个成对的数字(如上面的“a”和“d”)都是正的或都是负的,那么乘积就是正的。乘积将增加最终总和。
- 如果一个数字是正数,另一个是负数,那么乘积就是负数。乘积将减少最终的总和。
- 如果乘积为正,则两个数越大,对最终求和的贡献就越大。
这意味着如果两个向量中对应数字的符号对齐,则最终的和将更大。
Transformer 如何学习单词之间的相关性?
点积的这个概念也适用于注意力得分。如果两个单词的向量更对齐,注意力得分会更高。那么我们想要Transformer的行为是什么呢?我们希望句子中两个相互关联的单词的注意力得分更高,而希望两个互不相关的词的得分更低。
例如,对于句子“The black cat drank the milk”,“milk”一词与“drank”非常相关,也许与“cat”的关系稍小,与“black”无关。我们希望“milk”和“drank”产生一个较高的注意力得分,“milk”和“cat”产生一个稍低的分数,“milk”和“black”产生一个可忽略不计的分数。这是我们希望模型学习产生的输出。为此,“milk”和“drank”的词向量必须对齐。“milk”和“cat”的向量会有些不同。而且“milk”和“black”的区别将很大。
那么Transformer是如何计算出哪一组权重会给它带来最好的结果的?词向量是基于词嵌入和线性层的权重生成的。 因此,Transformer 可以学习这些嵌入、线性权重等以生成上述要求的词向量。换句话说,它将学习这些嵌入和权重,如果一个句子中的两个词彼此相关,那么它们的词向量将对齐。从而产生更高的注意力得分。对于彼此不相关的单词,词向量将不会对齐,并且会产生较低的注意力得分。因此,“milk”和“drank”的嵌入将非常一致,并产生较高的注意力得分;“milk”和“cat”的得分稍低;而“milk”和“black”的嵌入将大不相同,并产生可以忽略不计的注意力得分。
Transformer编码器的自注意力
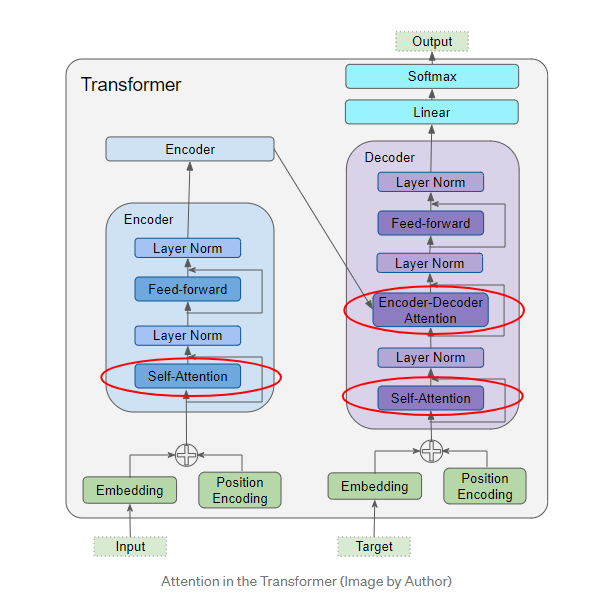
注意力在Transformer中使用的三个地方:
- 编码器中的自注意力
- 解码器中的自注意力
- 解码器中的编码-解码-注意力(Encoder-Decoder-attention)
在编码器的自注意力中,我们计算源序列中每个单词与源序列中其他单词的相关性。
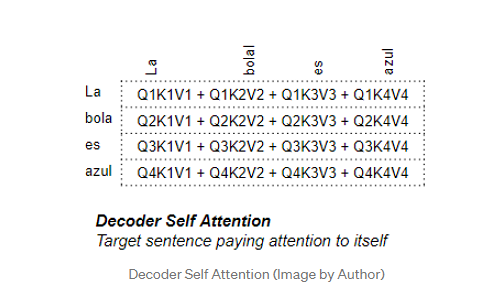
Transformer解码器的自注意力
我们刚才在编码器中看到的大部分自注意力也适用于解码器中的注意力,只有一些小的差异。
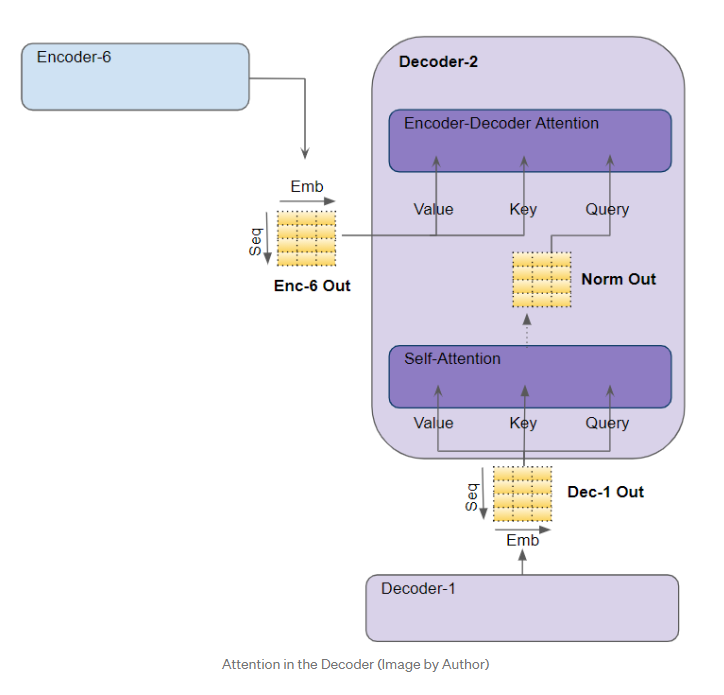
在解码器自注意力中,我们计算目标序列中每个单词与目标序列中其他单词的相关性。
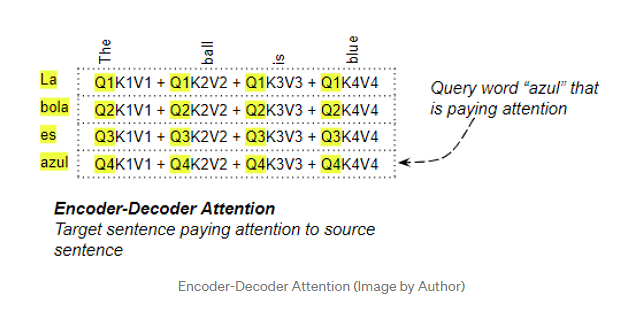
Transformer解码器的编码-解码注意力
在编码-解码注意力中,Query是从目标序列中获取的,Key/Value是从源序列中获取的。因此,它计算目标序列中每个单词与源序列中每个单词的相关性。
(张梦婷编译,周子喻校对)
研究动态
Google通过知识蒸馏将预训练的教师LM合并成单个多语言学生LM
现代预训练多语言模型旨在在单个模型中表示100多种语言。然而,尽管它们在跨语言迁移方面实现了SOTA性能,但由于容量有限、预训练数据倾斜和词汇欠佳等原因,它们往往无法公平地表示不同的语言。尽管在大型自定义词汇表上训练的特定语言模型可以避免这些问题,但它们缺乏多语LM强大的跨语言迁移能力。
为了解决上述问题,谷歌研究团队提出了MergeDistill框架,用于将多个单语和多语LM中的预训练教师LM合并成单个的多语言任务无关的学生LM。该方法旨在利用强大的语言特定LM的功能,同时仍然是多语言并实现积极的语言迁移性能。

为了实现他们的目标,该团队使用了Hinton等人在2015年提出的知识蒸馏(Knowledge Distillation,KD)技术。在大多数LM应用中,KD用于将大型教师模型压缩为较小的单任务学生模型。但KD也可以应用于任务无关的场景(如MLM),以获得任务无关的学生模型。
在MergeDistill: Merging Pre-trained Language Models using Distillation一文中,研究人员致力于在任务无关的场景中,将多个预训练好的LM合并成一个多语言的学生LM。他们的贡献总结如下:
- MergeDistill是一种任务无关的蒸馏方法,用于在预训练阶段合并多个教师LM,以训练强大的多语言学生LM,然后可以针对学生LM中所有语言的任何任务进行微调。这种方法更易于维护(模型更少)、计算效率更高且教师架构任务无关(因为我们获得了离线预测)。
- MergeDistill用于i)将单语教师LM组合成一个与单个教师竞争或优于单个教师的多语言学生LM;ii)组合多语言教师LM,使得重叠的语言可以从多个教师那里学习。
- 通过广泛的实验和分析,我们研究了类型相似性在构建多语言模型中的重要性,以及强大的教师LM词汇和预测对我们框架的影响。
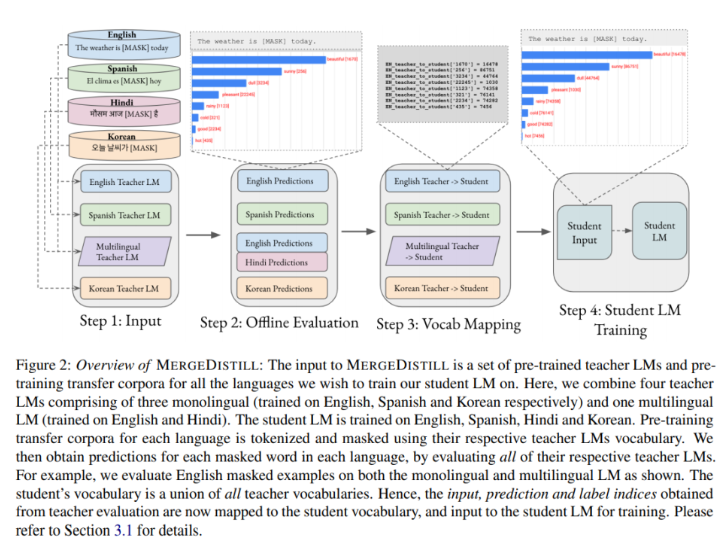
所提出的MergeDistill的输入是一组预训练的教师LM和用于训练学生LM的所有语言预训练迁移语料库。本研究所建立的一组预训练教师LM包含四个LM。三个单语LM分别接受英语、西班牙语和朝鲜语的训练,而多语LM则接受英语和印地语的训练。
从多个教师LM训练学生LM的第一步是使用各自教师LM的标记器标记每种语言的预训练迁移语料库和掩码。然后该方法通过评估各自的教师LM,获得每种语言中每个掩码、标记化示例的预测和logit。下一步是词汇映射,使用教师到学生词汇映射处理从每个教师LM评估后获得的输入索引。最后,研究者以教师预测为软标签和最小化师生分布的交叉熵为目标,利用处理后的输入索引、预测索引和gold标签索引,使用MLM训练他们的多语学生LM。
该团队对维基百科文本数据进行了大量的实验,以评估他们提出的MergeDistill方法的有效性。他们报告了结构化预测任务(NER,POS)的F1分数、准确率(Acc)、句子分类任务(XNLI,PAWS-X)的分数以及问答任务(XQuAD,MLQA,TyDiQA)的F1/精确匹配(F1/EM)分数。
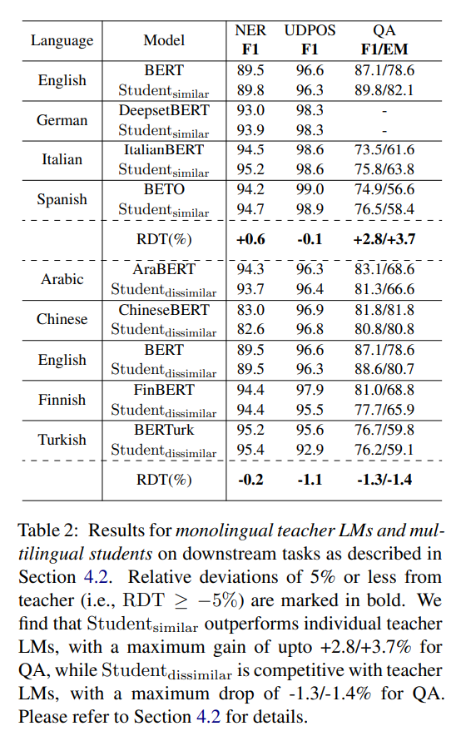
在他们的单语教师LM实验中,研究小组使用已有的单语教师LM来训练学生LM。结果表明在每种语言中,由此产生的学生LM要么具有竞争力,要么表现优于教师LM,从而验证了MergeDistill从单语教师LM有效训练多语言学生LM的能力。
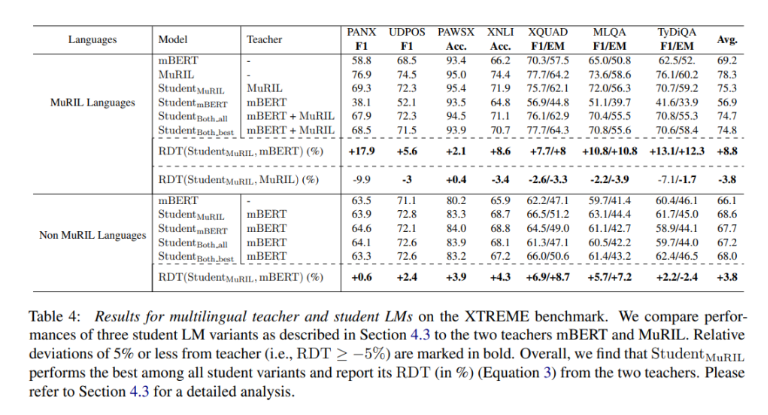
在多语种教师LM训练的案例中,团队使用多语言模型mBERT和MuRIL(印度语言的多语种表示,2020年)在XTREME基准上进行学生LM的训练。结果表明在Non-MuRIL语言中,学生LM以3.8%的平均相对分数击败教师(mBERT)。对于MuRIL语言,学生LM比教师(mBERT)高8.8%,但比教师(MuRIL)低3.8%。
总体而言,这项研究证明了所提出的MergeDistill方法的有效性和潜力,它弥合了不断扩大的强语言特定模型与大规模多语言LM跨语言性能之间的差距。
(张梦婷编译,周子喻校对)
迈向无Token的未来:Google提出了预训练的Byte-to-Byte Transformer
Towards a Token-Free Future:Google Proposes Pretrained Byte-to-Byte Transformers for NLP
Google的一项新研究建议修改标准Transformer架构,以便在NLP任务中处理字节(Byte)序列。研究人员表明,在参数计数、训练FLOP和推理速度方面,他们提出的字节级模型可以与当代大型语言模型通常采用的token级方法相匹敌。
Tokenization是将句子或文本分割成一系列token的过程。尽管Tokenization是NLP任务中常见的数据预处理过程,但它可能会遇到拼写错误、形态变化以及OOV(Out-of-vocabulary)问题。
解决这些问题的一种方法是创建直接对原始文本进行操作的无token模型,将文本数据存储为一个字节序列,模型使用该字节序列来处理任意文本序列。然而,由于字节序列比相应的词级token序列长得多,这种方法带来了很大的计算成本。
在ByT5: Towards a Token-Free Future With Pre-Trained Byte-to-Byte Models一文中,Google团队提出了ByT5。ByT5不像其他经过预训练的大型语言模型那样使用子词词汇表,而是直接在UTF-8字节上进行操作。新的架构消除了任何文本预处理的需要,并且可以轻松适应处理字节序列而不会增加过多的计算成本。

所提出的ByT5基于谷歌提出的mT5(大规模多语种文本到文本迁移Transformer),mT5是在大量未标记文本数据的语料库上进行训练的,在各种多语言NLP任务中取得了SOTA性能。研究人员通过执行一组不会显著增加计算成本的最小修改集,使mT5实现无token。
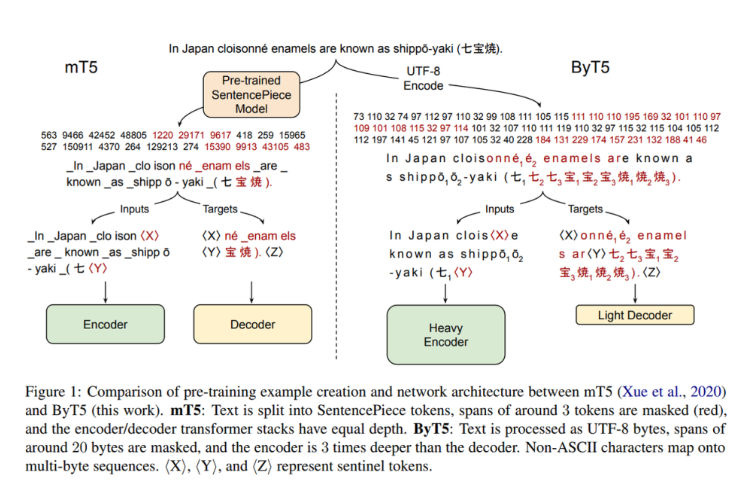
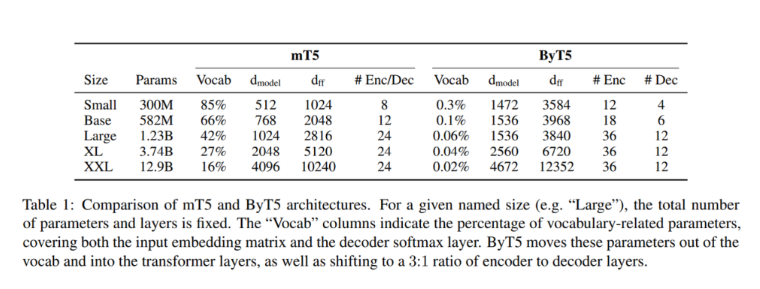
mT5设计的关键变化包括将SentencePiece(子词单元的重新实现)词汇表的UTF-8字节直接输入到模型中,而无需任何文本预处理,并将这些字节嵌入到模型的隐藏大小中。另外3个ID也被保留用于特殊标记:填充、句尾和未使用的标记。
然后团队修改预训练任务,这样就不用添加100个新token,而是重用最后的100个字节ID。此外,它们不使用3个子字标记的平均跨距长度,而是使用设置为20字节的平均掩码跨距长度来屏蔽更长的字节跨距。研究小组发现带有“更重”编码器的字节级模型在分类和生成任务上表现更好,因此将其编码器深度设置为解码器深度的三倍。最后,他们删除模型输出中的任何非法字节,以使所有字节序列在UTF-8标准下保持合法。
为了评估他们的Transformer架构修改在计算成本权衡方面的字节级处理性能,该团队将ByT5与mT5在标准英语和多语言NLP基准测试的广泛任务上进行了比较。
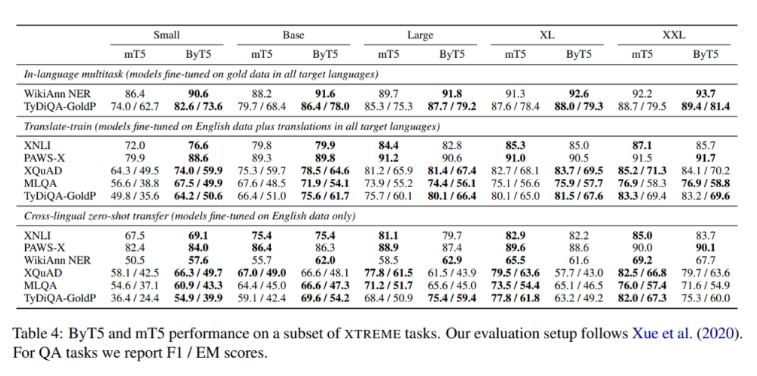
在XTREME基准的跨语言理解中,研究人员比较了问答任务的F1/EM分数。在最真实的语言环境中,ByT5在所有任务和模型尺寸上都优于mT5。ByT5在英语分类和生成等任务上也取得了优异的成绩。
结果表明,在10亿个参数下的模型尺寸、生成任务、带有语言标签的多语言任务以及存在各种类型噪声的情况下,所提出的ByT5性能均优于mT5。总的来说,结果表明ByT5是一个具有竞争力的字节级模型,可以有效地平衡计算成本。
(张梦婷编译,赵海喻校对)
Google研究了使DL模型“更小、更快、更好”的方法
Google Survey Explores Methods for Making DL Models "Smaller, Faster, and Better"
深度学习已经成为机器学习领域的主流方法。但DL不仅仅是性能方面的问题:随着当今复杂模型对参数和计算资源的需求越来越大,研究人员也在对这些重要的指标进行批判性研究。
谷歌的一个研究团队最近进行了一项关于如何使深度学习模型更小、更快、更好的研究,重点关注模型效率的核心领域,从建模技术到硬件支持。该团队还公开了一个基于实验的指南和代码,以帮助实践者优化他们的模型训练和部署。

研究人员首先确定了DL模型训练和部署中的挑战,包括可持续的服务器端扩展、支持设备部署、隐私和数据敏感性、新应用程序以及模型的爆炸性增长。这些挑战都基于模型效率,研究人员将模型效率进一步分解为推理效率和训练效率。
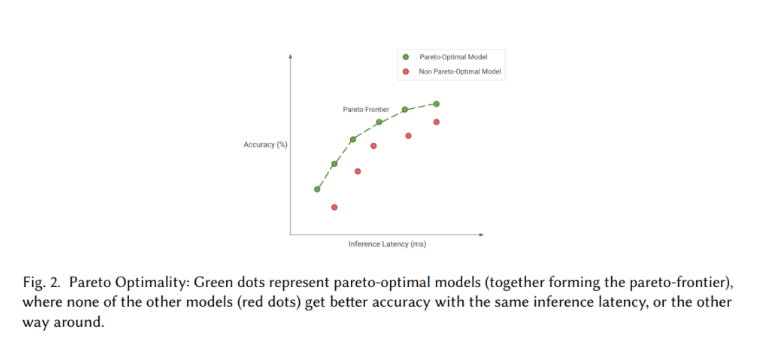
该团队将其目标定义为实现帕累托最优,即基于相关权衡选择最优模型。为此,他们探索了各种算法、技术、工具和基础设施如何协同工作,使用户能够更好地训练和部署模型质量和模型方面的帕累托最优模型。

该团队将帕累托最优模型分为五个主要领域:压缩技术、学习技术、自动化、高效架构和基础设施。压缩网络层是优化模型体系结构的经典技术。例如,量化是一种旨在通过在质量损失最小的情况下降低精度来压缩层的权重矩阵的方法。同时,学习技术侧重于使用不同的模型训练技术来产生更少的预测错误、需要更少的数据、更快的收敛速度等。自动化包括改进给定模型的核心度量的工具,例如优化超参数和架构搜索。模型架构也可以设计得更高效,比如注意层如何解决Seq2Seq模型中的信息瓶颈问题。最后,Tensorflow、PyTorch等模型训练框架也可以提高模型效率。
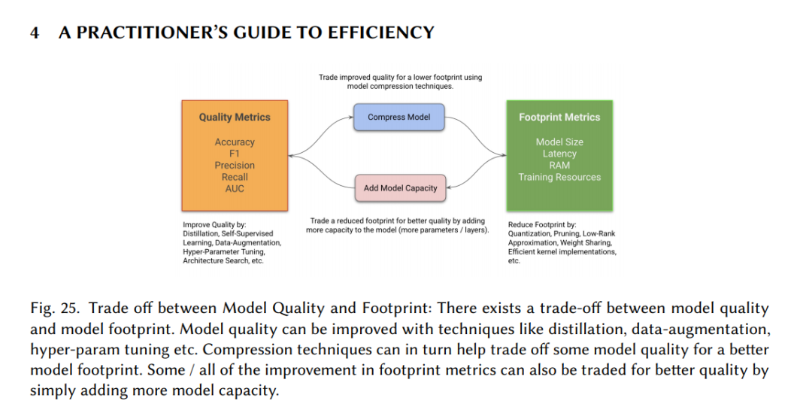
Google的研究人员在他们44页的论文中对这些领域进行了深入的调查,这篇论文为实践者提供了如何获得有效的DL模型的宝贵见解。团队提出并实证证明了实现帕累托最优模型的两种策略的合理性:
- 1.缩小和改进对占用空间敏感的模型:如果作为一个实践者,您希望在保持质量不变的同时减少占用空间,那么这对于设备部署和服务器端模型优化是一个有用的策略。理想情况下,收缩应该在质量方面损失最小(可以通过学习压缩技术、架构搜索等实现),但在某些情况下,即使是天真地减少容量也可以通过改进阶段进行补偿。也可以在收缩阶段之前进行改善阶段。
- 2.对质量敏感的模型进行增长、改进和收缩:当您希望部署质量更好的模型,遵循此策略可能是有意义的。这里,容量首先是通过增加模型来增加的,如前所述。然后使用学习技术、自动化等改进模型,然后以学习的方式缩小模型。或者,模型也可以在增长模型后直接以学习的方式缩小。
研究人员认为,他们的研究是高效深度学习领域中第一次全面涵盖模型效率,从建模技术到硬件支持。他们希望这项工作可以作为实践指南,帮助开发人员训练和部署更有效的模型,并为DL社区在该领域的进一步研究提供启发。
(张梦婷编译,赵海喻校对)
EleutherAI声称新的NLP模型达到了接近GPT-3级别的性能
EleutherAI claims new NLP model approaches GPT-3-level performance
人工智能驱动的语言系统具有变革潜力,它们已经被用来驱动聊天机器人、将自然语言翻译成结构化查询语言、创建应用程序布局和电子表格,以及提高网络搜索产品的准确性。OpenAI的GPT-3可能是最著名的人工智能文本生成器,目前已有数万名开发者在300多个应用程序中使用,每天产生45亿个单词。
随着企业对人工智能的兴趣上升,咨询公司Mordor Intelligence预测,到2025年,NLP市场的收入将增加两倍以上。但非商业性的、开放源码的努力同时获得动力,EleutherAI取得的进展就是明证。一个草根的人工智能研究人员,本周EelurTai发布了GPT-J-6B(GPT-J),该模型声称,在各种任务上,该模型与同等大小的GPT-3模型几乎一致。
EleutherAI的创始成员之一Connor Leahy告诉VentureBeat:“我们认为,这可以说是目前最好的开源自回归语言模型。”
GPT-J是所谓的Transformer模型,这意味着它权衡了输入数据不同部分的影响,而不是对所有输入数据进行相同的处理。Transformer不需要在句子结束前处理句子开头。相反,它们识别赋予句子中单词意义的上下文,使它们能够并行处理输入数据。
Transformer架构构成了语言模型的主干,其中包括GPT-3和Google的BERT,但EleutherAI称与其它大规模模型开发相比,GPT-J的训练时间更短。研究人员将此归因于使用Jax,DeepMind的Python库设计用于机器学习研究,以及对Google的张量处理单元(Tensor Processing Units,TPU)的训练,后者是专门为加速人工智能而开发的专用集成电路(Application Specific Integrated circuits,ASICs)。

EleutherAI能够利用TPU研究云,这是一个支持项目的Google云计划,期望通过代码和模型共享研究结果。GPT-J的代码和经过训练的模型是在apache2.0许可下开源的,可以通过EleutherAI的网站免费使用。
GPT-J比之前发布的两款EleutherAI车型性能更强:GPT Neo 1.3B和GPT Neo 2.7B。例如,它可以执行加法和减法运算,并证明简单的数学定理,如“任何循环群都是阿贝尔群”,它还可以回答来自流行测试数据集(BoolQ)的定量推理问题并生成伪代码。

EleutherAI计划最终交付运行模型所需的代码和权重,该模型与完整的“DaVinci”GPT-3类似(虽然不完全相同)。(权重是神经网络中转换输入数据的参数。)与GPT-J相比,完整的GPT-3包含1750亿个参数,并使用45TB数据集中的4990亿个token进行训练。
像GPT-3这样的语言模型通常会放大数据中编码的偏见。一部分训练数据并非罕见地来源于普遍存在性别、种族和宗教偏见的社区。OpenAI指出,这可能导致在女性代词附近放置“naughty”或“sucked”等词,在“恐terrorism”等词附近放置“Islam”等词。其他研究,如英特尔、麻省理工学院和加拿大高级研究所(CIFAR)研究人员4月份发表的一项研究,发现在一些最流行的模型中存在高度的陈规定型偏见。
虽然EleutherAI的模型在其能力方面可能不是最先进的,但它可以在很大程度上解决一个常见的技术问题:研究团队和工程团队之间的脱节。作为Hugging Face的首席执行官Clément Delangue在最近的一次采访中表示,科技巨头们在提供了黑盒NLP API的同时,还发布了难以使用或维护不好的开源存储库。EleutherAI的努力可以帮助企业实现NLP的商业价值,而无需自己做大量的法律工作。
(张梦婷编译,周子喻校对)
近期论文
FastSeq:Make Sequence Generation Faster
摘要
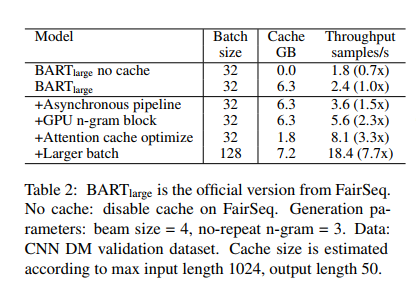
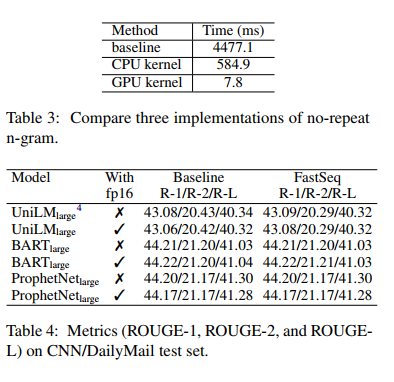
基于Transformer的模型对自然语言生成中产生了巨大的影响。然而,由于自回归解码过程涉及的模型规模大、计算量大,推理速度一直是一个瓶颈。我们开发了FastSeq框架来加速序列生成,而不会造成精度损失。所提出的优化技术包括注意缓存优化、检测重复n-gram的有效算法和具有并行I/O的异步生成pipline。这些优化足以适用于基于Transformer的模型(例如T5、GPT2和UniLM)。我们在一组广泛使用的不同模型上的基准测试结果表明,推理速度提高了4-9倍。此外,FastSeq很容易使用,只需简单的一行代码更改。源代码位于https://github.com/microsoft/fastseq
主要贡献
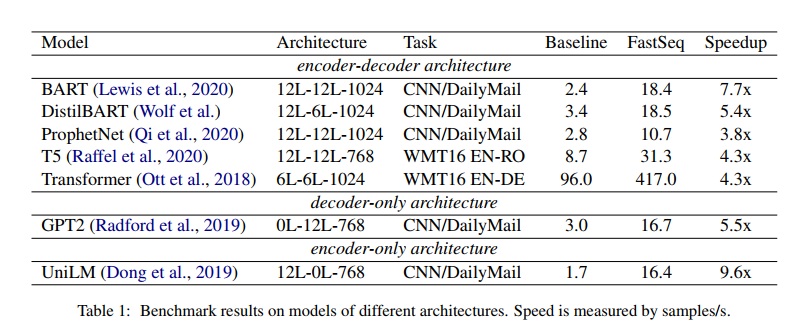
我们的优化方法包括注意缓存优化、检测重复n-gram的有效算法和具有并行I/O的异步生成pipline。这些优化对于广泛的基于Transformer模型的架构来说已经足够普遍,包括编码器-解码器架构(例如T5和BART),仅解码器架构(例如GPT2),以及仅编码器架构(例如UniLM )。FastSeq还可以灵活地扩展支持其他模型和框架。我们的技术部分被FairSeq2采用。
实验
在这项工作中,我们提出了FastSeq,它提供了在不损失精度的情况下加速序列生成的通用解决方案。提出的优化方案包括注意缓存优化、基于GPU的n-grams阻塞算法和异步生成pipline。在未来,我们将支持更多的模型和探索更多的技术,以加快生成速度。
(张梦婷编译,赵海喻校对)
近期会议
DNLP 2021: International Conference on Data Mining and NLP
Aug 21 Chennai, India
DNLP 2021将提供一个极好的国际论坛,以分享数据挖掘和NLP的理论、方法和应用方面的知识和成果。 这次会议的目的是将学术界和工业界的研究人员和从业人员聚集在一起,集中精力于理解数据挖掘和NLP概念,并在这些领域建立新的合作关系。
(张梦婷)
NLPCC 2021:Natural Language Processing and Chinese Computing
Oct 12 - Oct 17 Chennai, India
NLPCC是一个领先的国际会议,专门研究自然语言处理(NLP)和中文计算(CC)领域。NLPCC在CCF推荐的CS会议列表中。它是学术界、工业界和政府的研究人员和实践者分享他们的想法、研究成果和经验,并促进他们在该领域的研究和技术创新的主要论坛。
(张梦婷)