文本挖掘与机器学习跟踪扫描动态快报(2020.01)
实时跟踪、关注文本挖掘与机器学习领域最新研究动态
深度观察
深度学习的十年回顾
随着21世纪第二个十年接近尾声,近十年来在深度学习领域取得的巨大进步值得我们回顾。在性能日益强大的计算机及大数据可用性的推动下,深度学习已成功解决了许多曾经棘手的问题,尤其是在计算机视觉和自然语言处理方面。 深度学习在现实世界中已经无处不在,从自动驾驶和医学影像分析到虚拟助理和深度伪装。
这篇文章概述了过去十年中一些最有影响力的深度学习论文。我的希望是通过提供简洁明了的摘要来提供进入深度学习不同领域的起点。摘要往往比表面层次的论述要略深,并参考了许多相关资源。
鉴于研究的性质,可以说是一千个人心中有一千个哈姆雷特。最有影响力的论文通常既不是第一篇也不是最好的那篇。我努力在它们之间找到平衡,将最有影响力的论文列为主要条目,将其他在该条目之前或在此基础上完善的相关论文列为荣誉奖予以列出。当然,由于这样的列表始终是主观的,因此这并不意味着最终的,详尽的或权威的。
2010
理解深度前馈神经网络训练的难点(7446次引用)
本文探讨了深度网络的一些问题,尤其是权重的随机初始化。 本文还注意到了S型曲线和双曲正切激活的问题,并提出了替代方案SoftSign,它是一种具有更平滑渐近线的S型激活函数。但是,本文的最主要的贡献在于初始化本身。当使用正态分布的权重进行初始化时,网络中的值很容易急剧增大或减小,从而无法进行训练。假设前一层的值是服从独立同分布的正态分布,将它们叠加会增加其方差,因此应按输入数量成比例地缩小方差,以保持输出为服从零均值和单位方差的标准正态分布。对于梯度问题,则将相同的逻辑反过来(即按输出数量进行处理)。本文介绍的Xavier初始化是两者之间的折衷,使用方差2/(Nin+Nout)为正态分布初始化权重,其中Nin和Nout分别是上前一层和后一层中神经元的数量。 2015年的一篇后续论文《深入研究整流函数:在ImageNet分类上超越人类水平》介绍了Kaiming初始化,它是Xavier初始化考虑了ReLU激活的影响的改进版本。
2011
深度稀疏整流神经网络(4071 次引用)
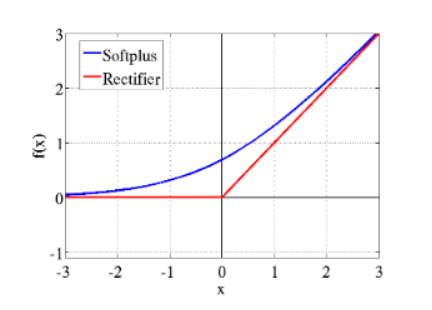
最早的MLP到2015年的各种神经网络大多数都是使用S型函数作为中间激活函数。S型函数(最常见的是logistic函数与双曲正切函数)具有处处可微和输出有界的优点。而且它与神经生物学中的全或无定律相吻合。
(注:全或无定律是神经传导的一项基本特性。即当刺激达到神经元的反应阈限时,它便以最大的脉冲振幅加以反应,但刺激强度达不到某种阈限时,神经元便不发生反应。)
然而,由于S型函数的导数从零开始迅速缩减,因此随着神经网络的层数的增加,梯度通常会迅速减小。这被称为梯度消失问题,这也是当时神经网络难以深度缩放的原因之一。本文发现,使用ReLU激活函数有助于解决梯度消失问题,从而为神经网络的深度发展奠定了基础。
(注:ReLU,Rectified Linear Unit,一种常用的激活函数,称为线性整流函数或修正线性单元)
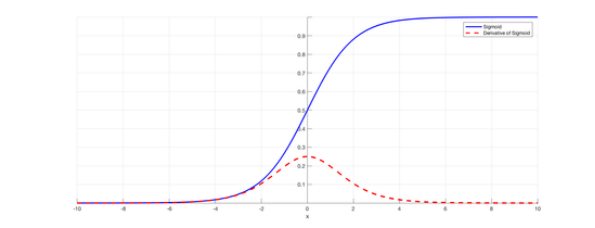
S型函数及其导数
尽管如此,ReLU激活函数仍然存在一些缺陷:它们在零时不可微,可以无限增长,并且当一半节点被激活并饱和时,剩下的节点可能“死亡”。2011年以来,已经提出了许多改进的激活方法来解决这个问题,但是由于其他的方法的有效性仍然有待考证,vanilla ReLU激活函数仍然极具竞争力。
《Digital selection and analogue amplification coexist in a cortex-inspired silicon circuit》(2000)一文被普遍认为是建立ReLU的生物学合理性的第一篇论文,而《What is the Best Multi-Stage Architecture for Object Recognition?》(2009)
是我能够找到的使用ReLU(对本文起到积极贡献)探索神经网络的最早论文。
荣誉提名:
整流非线性改进神经网络声学模型:
指数线性单元精准深度网络学习:
高斯误差线性单元:
此文介绍了带泄露修正线性单元(Leaky ReLU),由于在负半轴上存在较小的梯度“泄露”,因此输出不为零。这使其防止了ReLU激活函数中部分神经元死亡现象的出现。然而,泄露的ReLU在0处的导数不连续。
https://ai.stanford.edu/~amaas/papers/relu_hybrid_icml2013_final.pdf
指数线性单元(ELUs,Exponential Linear Units)和 Leaky ReLU相似,但在负半轴更平滑且饱和值为-1。
高斯误差线性单元(GELU,Gaussian Error Linear Units)作为一种常用的激活函数,其激活是基于高斯分布及对应的随机正则器dropout。具体来说,一个特定的值被保留的概率是标准正态分布的累积分布函数:。因此,这个变量的期望值在随机正则化后就变成了。GELU在许多SOTA模型中有所应用,如BERT和GPT/GPT2。
2012
深度卷积神经网络的ImageNet分类(52025次引用)
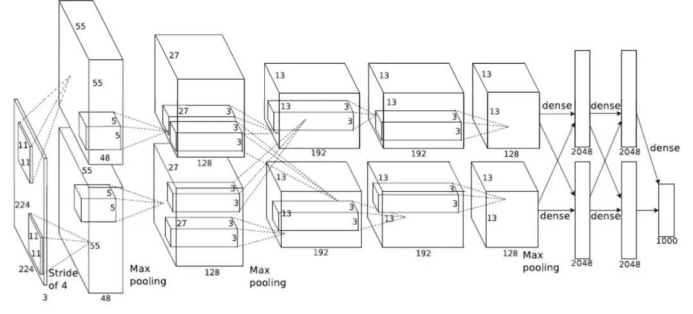
AlexNet是一个使用ReLU激活功能和6000万个参数的8层卷积神经网络。AlexNet的关键贡献在于展示了更深层网络的强大功能,因为其架构本质上是先前网络(即LeNet)的更深版本。
此篇关于AlexNet论文通常被认为是深度学习的发端。AlexNet也是最早利用GPU的大规模并行处理能力来训练比以前更深的卷积网络的网络之一。结果令人震惊,它将ImageNet的错误率从26.2%降低到15.3%,并在ILSVRC 2012中脱颖而出。其错误率的大大减少引起了深度学习领域的广泛关注,并使AlexNet论文成为深度学习中引用最多的论文。
荣誉提名:

ImageNet层次结构中的图像示例
ImageNet:大型分层图像数据库:
用于图像分类的灵活、高性能的卷积神经网络
梯度学习在文档识别中的应用:
ImageNet数据集也为深度学习的兴起做了相当大的贡献。它也是深度学习领域被引量最高的论文之一,有着大约15050次引用,也是所有深度学习中引用次数最多的论文之一。该数据集是使用Amazon Mechanical Turk将分类任务外包给工人来构建的,这也使得这个天文级别的数据集成为可能。ImageNet大型视觉识别挑战赛(ILSVRC,ImageNet Large Scale Visual Recognition Challenge)是以ImageNet数据库为对象的对像分类算法竞赛,同时它也推动了计算机视觉领域中许多其他创新的发展。
这篇论文早于AlexNet发表并与AlexNet有着许多共同点:这两篇论文都利用GPU加速训练神经网络,都利用ReLU激活函数来解决梯度消失问题。一些人认为这篇文章被冷落是很不公正的,它的被引量远少于AlexNet。
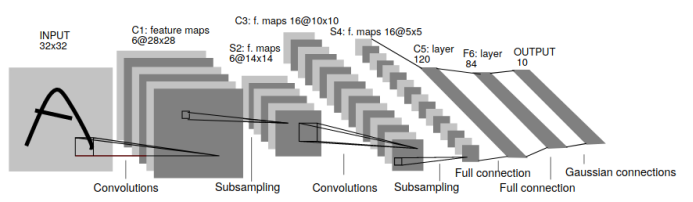
LeNet 结构
这篇1998年的论文被引用次数高达23110,是将卷积神经网络用于图像识别的先驱。实际上,目前的卷积神经网络几乎完全是此早期工作的放大版本! 更早些,LeCun在1989年的一篇被引用的很少的论文《Backpropagation Applied to Handwritten Zip Codes》,可以说是第一个梯度下降的卷积神经网络。
2013
单词和短语的分布式表示及其组合性(16923次引用)
本文(以及同一作者之前的论文《Efficient Estimation of Word Representations in Vector Space》)介绍了word2vec,它成为了深度学习的NLP模型中文本编码的主要方法。它基于这样的思想:出现在相似上下文中的单词可能具有相似的含义,因此可以将单词嵌入向量中,从而应用于其他模型。特别是Word2vec,它训练了一个可以用给定单词本身来预测单词的上下文,然后提取出网络中潜在的向量。
荣誉提名:
GloVe: 单词表示的全局向量
GloVe是基于word2vec相同核心思想的改进模型,但是实现方式略有不同。关于这两个模型哪一个更好,人们至今没有定论。
利用深度强化学习玩Atari(3251次引用)

DeepMind的Atari DQN的研究结果开启了深度强化学习领域的大门。强化学习之前主要用于在诸如网格世界之类的低维环境,很难在更复杂环境中有所应用。Atari是强化学习在高纬度环境下的第一例成功应用,将强化学习从无人问津的领域转到AI的重要子领域之一。
此文特别使用了深度Q学习,这是一种基于价值的强化学习方式。基于价值的意思是目标是通过遵循由Q值函数隐式定义的策略来了解在每种状态下获得的奖励的期望值(或者说在Q学习之下,每个“状态-行为”对)。本文所使用的是-贪婪策略,它采取概率为1-ε的Q函数估计下最贪婪(即得分最高)的行动以及概率为的完全随机行动。这是为了探索整个状态空间。训练Q值函数的目标是从Bellman方程,它将Q值函数分解为当前奖励值与下一期的最大Q值(或最大值的线性表示Q(s,a)=r+γ MAXa'Q(s',a'))之和,从而可以实现参数的自更新。这种基于当前奖励值和未来价值函数之和来更新价值函数的技术通常被称为时差学习(Temporal Difference Learning)。
荣誉提名:
从延迟奖励中学习:
Christopher Watkins发表于1989年的博士毕业论文介绍了Q学习。
2014
生成对抗网络(被引用13917次)

生成对抗网络的成功在很大程度上要归功于它们产生的惊人的视觉效果。依托于生成器(Generator)和鉴别器(Discriminator)之间的极大极小博弈,GANs能够对复杂、多维度分布进行建模,其对象通常是图片。生成器的目标就是最小化鉴别器正确甄别错误样本的对数概率,即log(1 - D(G(z)));而鉴别器的目标则是最小化对于正确和错误样本的分类误差,即logD(x) +log(1 - D(G(z))。
“极大极小博弈中用于生成器的努力对于理论研究十分有益,但在实际操作中用处不大。”
—Goodfellow, 2016
实际应用中,通常会训练生成器以使鉴别器的对数概率D(G(z))最大化, (相关阅读:NIPS2016指南:生成对抗网络,章节3.2.3)。这一微小变化减小了梯度饱和(gradient saturating)且提高了模型训练的稳定性。
荣誉提名:
Wasserstein GAN和改进Wasserstein GAN
StyleGAN:
原版生成对抗网络(Vanilla GANs)存在种种问题,尤其是在训练稳定性方面。即使进行了许多调整,Vanilla GANs也常常训练失败,或者出现模式崩溃(在这种情况下,生成器生成只生成少量清晰图片)。由于改进了训练的稳定性,能够调整梯度的Wassertein GAN成为当下默认使用的GAN。不同于原版GANs使用Jensen-Shannon距离法(当分布之间几乎没有重叠时会饱和并提供不可用的梯度),WGAN采用的是Earth Mover距离法。WGAN原稿论文通过限制权重的方式,实施了Lipschitz连续性约束(梯度小于所有位置的常数),从而通过调整梯度的方式改善了一些存在的问题。

StyleGAN图片
StyleGAN能够生成令人惊叹的高分辨率图像,与真实图像几乎无法区分。 生成如此高清图片的GANs之中所运用的最重要的技术就是渐进地增大图片大小,而StyleGAN内置了这项技术。StyleGAN还允许在每一个不同比例尺之上修改图片的潜在空间,从而只对生成图片的特定细节进行操作。
通过联合学习对齐和翻译的神经机器翻译(被引用9882次)

这篇文章引入了attention的概念——与其将压缩信息进一个RNN的隐空间里,不如在内存中保留全部的内容,通过O(mn)这一操作,使输出的所有要素处理输入的所有要素。即使attention的运算量二次递增,它依然比固定状态的RNNs表现更优秀,它不仅在类似于翻译和语言建模的文本处理领域不可或缺,其身影也穿梭在与之相去甚远的GANs领域的模型中。
Adam:一个随机优化方法(被引用34082次)
Adam因其易于微调在自适应优化中被广泛运用,它基于为每个参数适配单独的学习率的思想诞生。虽然最新的一些文章对Adam的性能提出了质疑,但它依然是深度学习领域中最为流行的优化算法之一。
荣誉提名:
无耦合权重衰减正则化:
RMSProp:
这篇文章声称发现了在通常实施中使用带权重衰减的Adam运用的一个错误,并提出替代方案AdamW优化来缓解上述问题。
另一个流行的自适应优化方法(特别是RNNs领域,虽然这个方法与Adam相比究竟孰优孰劣还在争论中)。
2015
针对图像识别的深度残差学习(被引用34635次)
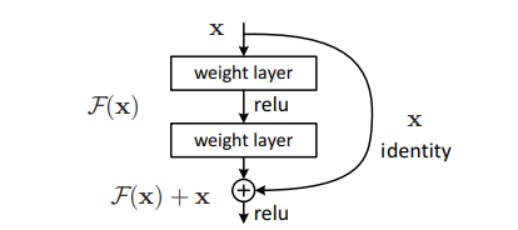
残差块(residual block)最初被设计用于解决深度CNNs中的坡度消失/爆炸问题,如今已成为几乎所有CNNs的构建基石。它的实现概念其实非常简单:将输入从每个卷积层块之前添加到输出中。残差网络的灵感源自于神经网络理论上不应以更多层来降维,因为最坏的情况下,多余的层会被粗暴地设为恒等映射(identity mapping)。在实际操作中,更深度网络训练中常遇到各种困难;残差网络使各层更容易学习恒等映射,同时减少了梯度消失的问题。虽然方法十分简单,但从效果上看,特别是在更深度网络中,残差网络比常规CNNs出色得多。
荣誉提名:
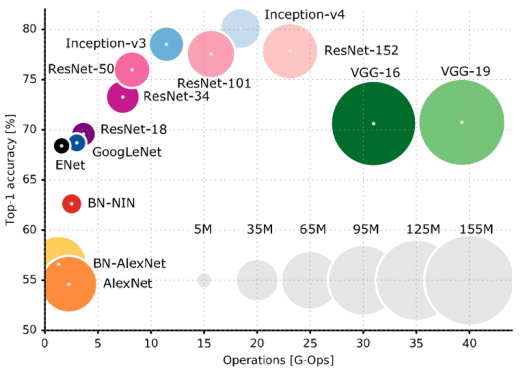
不同CNN的比较
许多其他更复杂的CNN基础理论也十分优秀。 以下是具有历史意义的网络理论的一小部分。
高速网络:
更深度的卷积:
针对大比例图像识别的超深度卷积网络:
神经常微分方程:
层正则化,实例正则化,以及群正则化:
不用人类经验而精通围棋:
深度语境化词语表征:
使用生成式预训练提高语言理解力:
语言模型是无监督多任务学习者:
Transformer-XL超出固定长度语境的注意力语言模型:
XLNet:用于语言理解的广义自回归预训练方法
具有子词单元的罕见词的神经机器翻译:
残差网络是早期高速网络的一个特例。早期的高速网络通过一个类似但更复杂的封闭式设计,来在更深度网络中处理梯度。
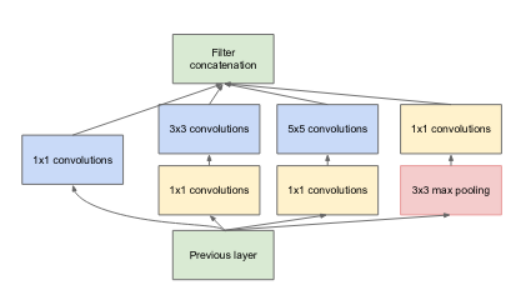
Inception-v1体系结构
Inception模块理论基于将卷积分解来减少参数数量和激活次数。这使它能容下更深度的层嵌套,对这篇文章中提到的GoogleNet十分有益;文中的GoogleNet后来改名为SOTA网络(ILSVRC2014)。之后Inception模块相继更新发布了许多版本,并最终在Inception-v4嵌入于ResNets中,详情参考:Inception-ResNet及残差关系在机器学习上的影响。
这是又一个在CNNs历史上非常重要的作品,这篇文章引入了VGG网络的概念。这篇文章的重要意义在于其探索只使用3*3卷积,而不是其它大部分网络中使用的更大的卷积。因而大幅降低了参数数量。
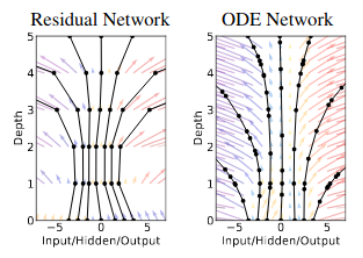
神经常微分方程图
神经常微分方程这篇文章曾获2018年NIPS最佳论文奖,区分开了残差和微分方程。其核心观点就是将残差网络视作连续转换的离散化,从而可定义残差网络为一个常微分方程的参数,也就可以用现成的求解器来对其进行求解。
Batch正则化:通过内部变量转化加速深度网络训练(被引用14384次)
不同正则化技术可视化
https://arxiv.org/abs/1607.06450
基于汇总统计数据的不同方法,出现了许多其他替代方法:分别是同批处理,批处理和通道,或者批处理和多通道。这些技术在不希望同批处理and/or通道中的不同样本互相干扰的时候十分有效,关于这点最好的例子就是GANs。
2016
用深度神经网络和树形搜索精通围棋(被引用6310次)
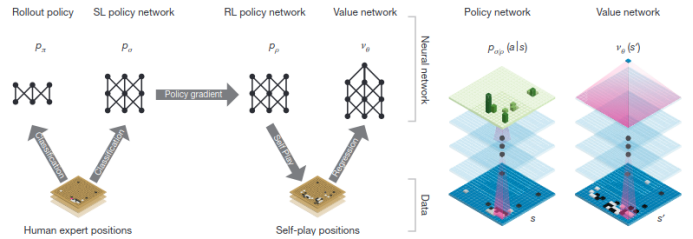
在深蓝打败Kasparov后,围棋成为AI社区的下一个目标。相对国际象棋,围棋有更大的状态空间,也更依赖于人类玩家的直觉。在AlphaGo之前的最优秀的围棋AI系统(例如Crazy Stone和Zen),基本都是由许多手工启发算法引导树形搜索的蒙特卡洛树形搜索组合。从这些AI系统的进展来看,打败最优秀的围棋选手还需要很多年。虽说之前已有将神经网络应用于围棋的尝试,还没有哪个AI系统达到了AlphaGo的成就,AlphaGo也在巨型算力的基础上集成了不少这些尝试中的技术成果。具体来说,AlphaGo包含一个策略网络和一个价值网络,分别可以缩小树形搜索并能够截断搜索树。这些网络首先由标准的监督学习训练,之后再接受强化机器学习进行进一步调整。
在以上列举的进展中,AlphaGo和Lee Sedol比赛,对公众思维影响最为深刻,受众约1亿人口,尤其是在围棋十分流行的中日韩三国。这场比赛和之后的AlphaGo Zero对战,已经对人类的围棋策略都产生了影响。例如,AlphaGo在第2场比赛第37手非常不常规,惊异到了许多分析者。这一手后来成为AlphaGo获胜的至关重要的一步。
荣誉提名:
这篇后续介绍AlphaGo Zero的文章,移除了监督学习过程,纯粹通过对战自己来训练策略网络和价值网络。虽然未受人类围棋策略的影响,AlphaGo Zero却能自己探索出许多人类围棋手的策略,此外还能独创自己更优的围棋策略。这些策略甚至与传统围棋思路中是相悖的。
2017
注意力机制即你所需(5059次引用)
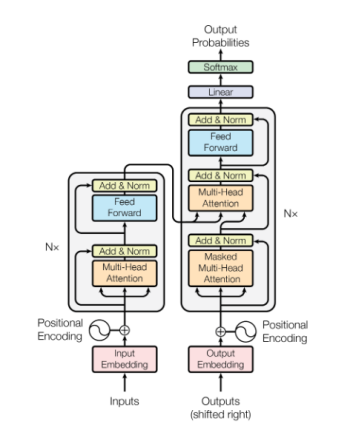
转换器架构是利用前述attention机制的一个例子,今天已经发展成为几乎所有最先进的自然语言处理模型的基础。转换器模型击败RNNs,很大程度上是由于它在巨型网络中的计算优势。在RNNs中,梯度需要在整个“展开”的图形中传播, 这使得内存访问成为很大瓶颈。这也恶化了梯度消失的问题,从而需要更复杂(且计算成本更高)的LSTM和GRU模型。相反,转换器模型对高度平行处理进行了优化。计算成本最高的部分位于注意层之后的前馈网络,它能够平行使用。以及注意层本身,它是巨大的矩阵乘法,并且易于优化。
使用增强学习的神经架构搜索(引用1186次)
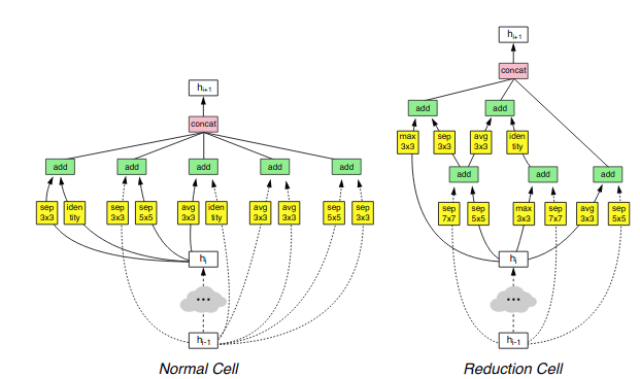
神经架构搜索(NAS)是网络性能压缩领域的普遍做法。NAS无需手动设计架构,将实现架构设计的过程自动化。在这篇论文中,利用RL训练一个控制器网络,从而产生高性能网络架构,从而创建许多SOTA网络。其他方法,例如Regularized Evolution for Image Classifier Architecture Search (AmoebaNet),使用了演化算法。
2018
BERT:语言理解的深度双向转换器的预训练
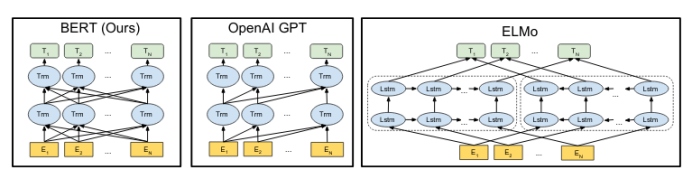
BERT是一种双向语境文本嵌入模型。与word2vec相似,它的基础是给每个单词(或子单词token)赋予一个向量。但BERT里的这些向量是语境化的,能正确区别同形异义词。另外,BERT是深度双向的,每层中的每个潜在向量依赖于前一层中的所有潜在向量,这是与GPT(仅包含前向)和ELMo(包括了独立的前向和后向语言模型,两者到最后才结合)等早期工作不同之处。在类似GPT的单向语言模型中,训练模型在每个time step,去预测下一个token,这种模型之所以可行的基础是每个时间步骤的状态仅依赖于上一个状态。(在ELMo中,前向和后向模型用这种方法独立训练,共同优化。)但在深度双向网络中,步骤t和层L的状态 必须依赖于所有的状态, 而这些状态中的任意一个反过来都依赖于St,从而使得网络能欺骗语言建模。为了解决这个问题,BERT运用重构任务去恢复网络从未见过的隐藏token。
荣誉提名:
自BERT发表以来,其他基于转换器的语言模型层出不穷。由于这些模型极为相似,我仅列举其中一些并不作为主要条目。当然,这个领域发展迅速,也不可能做到全面;此外,很多论文还有待时间验证,究竟谁影响最大尚难定论。
即前文提到的ELMo论文。ELMo可以说是首个语境文本嵌入模型(contextual text embedding model),但在实践中BERT变得越来越流行。

即前文OpenAI发表的GPT论文。这篇文章深入研究了在多个不同类型问题中,通过简单微调预训练参数,仅在相同的下游单向语言任务中进行训练的想法。考虑到从头开始训练现代语言模型的高昂代价,这个方法非常具有说服力。
GPT2,OpenAI的GPT模型的后继,在许多方面都只是GPT的扩展版本。它具有更多参数(高达15亿个),更多训练数据,更好的跨国测试困惑度。它的跨数据集泛化水平令人印象深刻,并为超大网络泛化能力提供了进一步实例。但是,它的声望来自于强大的文本生成能力。对文本生成更深入的讨论可查阅https://leogao.dev/2019/10/27/The-Difficulties-of-Text-Generation-with-Autoregressive-Language-Models/
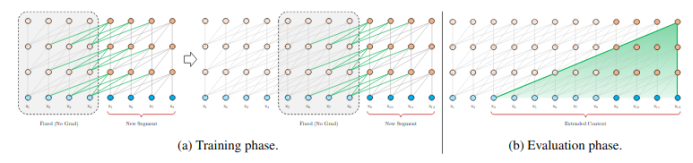
基于转换器的模型有固定的注意力长度,阻碍了对长文本语境的关注。,Transformer-XL试图通过关注来自于上一个注意力范围内的某些语境文本(为了计算可行性,它没有传播梯度)来实现更长的有效注意力范围,从而解决这些问题。
https://arxiv.org/abs/1901.02860
XLNet以多种方式解决了BERT面临的“欺骗”难题。XLNet是单向的,但是利用转换器对输入顺序的内在不变性,tokens能按任意顺序排列。这使得网络能有效地双向工作,同时保持单向性的计算优势。XLNet还成了Transformer-XL思想,能够提供更大的有效窗口。
https://arxiv.org/abs/1906.08237
更好的标记技术被认为是最近兴起的语言模型建模热潮的核心部分。通过分段标记所有单词,这些技术消除了出现未登录词tokens的可能性。
https://arxiv.org/abs/1508.07909
2019
深度双波谷:更大的模型和更多的数据伤害了谁
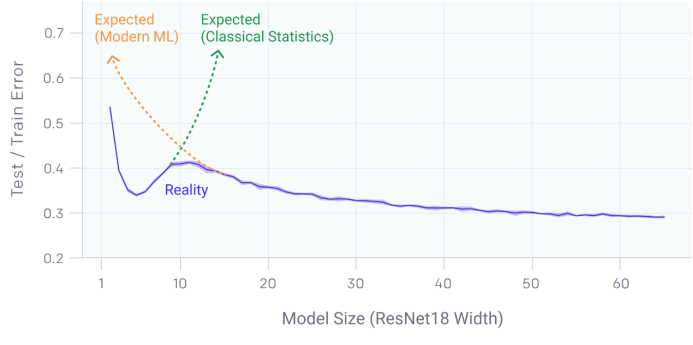
这篇文章所探讨的深度双波谷(Deep Double Descent)现象与经典机器学习和现代深度学习的流行观点背道而驰。在经典机器学习中,模型复杂性伴随着偏差-方差折衷。模型太弱,则不能充分捕捉数据结构,而模型太强,则会导致过拟合,涵盖了无法泛化的虚假模式。正因为如此,在经典机器学习理论中,随着模型变大,测试误差会下降,而一旦模型开始过拟合,测试误差又开始增加。但是在深度学习的实践中,模型通常过度参数化,看上去对较大模型的测试性能还是有所改进。这种冲突是深度双波谷背后的动机。深度双波谷扩展了Belkin 等人Double Descent论文,实证证明了Double Descent对更广泛类型的深度学习模型的效果,及其不仅适用于模型规模变化,还适用于训练时间和数据集规模变化。
“如果考虑了更多的函数类,这些函数类包含更多与数据适配的候选预测变量,我们可以发现具有更小范数因而也更简单的插值函数。因此,增加函数类容量可以改进分类器的性能。”
—Belkin. 2018
当模型容量接近于“插值阈值(interpolation threshold)”,即经典机器学习和深度学习的分界线,梯度下降法可能会发现接近于零误差的模型,很可能导致过拟合。但是,当模型容量进一步提高,可实现零训练误差的不同模型的数量会增加,一些模型平滑拟合数据(即不发生过拟合)的可能性也会增加。Double Descent认为,梯度下降法更可能找到这些更平滑的零训练误差网络,尽管过度参数化,但这些网络的泛化性很好。
彩票假说:发现稀疏可训练的神经网络
“任何密集、随机初始化的神经网络都包含一个子网络。这个子网络能通过初始化,使得隔离训练时,经过不多于原密集网络学习迭代次数的前提下达到与原网络相当的训练效果。”
另一篇关于深度神经网络训练特征的论文就是彩票假说论文。彩票假说认为,网络性能大部分来自于某些幸运初始化的特定子网络(也就是说,“彩票”,特指这些子网络),而且更大的网络彩票由于其机会更高,因而性能也更好。这不仅允许我们修剪不相关的权重(文献中已很好地论证),而且还允许我们仅使用“彩票权重”重新训练,令人惊讶的是,这种方式结果与原始结果较为接近。
结论与未来展望
过去的十年由深度学习革命与梯度网络的复兴的肇始而驱动,是人工智能历史上一个令人难以置信的快速发展和创新时期。很大程度上得益于可用算力的不断提高,神经网络规模变得越来越大,能力也越来越强,从计算机视觉到自然语言处理,全面代替了传统的人工智能技术。但神经网络也有缺点:他们需要海量数据进行训练、具有无法解释的故障模式、无法实现超越个体任务的泛化。由于人工智能领域的巨大进步,深度学习在提高人工智能方面的局限性已经开始显现,人们的注意力开始转向对深度学习的更深入理解之上。在未来十年里,人们可能会越来越了解今天所观察到的神经网络的许多经验特征。深度学习是人工智能工具箱中非常宝贵的工具,它让我们对智能的理解又近了一步。
向成果丰硕的21世纪20年代致敬!
(李朝安编译,张梦婷校对)
2020年面向开发人员的顶级NLP开源项目
2019年对开发者而言是丰收的一年,因为几乎所有行业领导者都将其机器学习工具包开源。开放源代码在帮助用户的同时还可以帮助工具本身,因为开发人员可以贡献并添加服务于少数复杂应用程序的定制。这样做的好处是可以实现交互并且有助于加快ML的民主化进程。在这里,我们编译了一些开源NLP项目,这些项目会让开发者和用户都感到兴奋。
LIGHT
LIGHT(Learning in Interactive Games with Humans and Text)——大型幻想文本冒险游戏和研究平台,用于训练可以对话和行动、与其他模型或人类互动的代理。游戏使用完全由玩家编写的自然语言。该平台使研究人员可以共同研究游戏世界中的语言和动作。完整的设置已开源,可供其他研究人员使用。
Dialogflow
Dialogflow建立在Google基础架构上,是一项可在Google Cloud Platform上运行的Google服务。在Google机器学习的支持下,Dialogflow整合了机器学习专业知识,这使得客户数量增加到数亿个。Dialogflow已针对Google Assistant进行了优化,是为超过4亿多种Google Assistant设备构建操作的最广泛使用的工具。
Microsoft Icecaps
Icecaps提供了一系列功能,这要归功于微软在个性化嵌入、最大程度的基于互信息(Mutual Information)的解码、知识基础以及共享特征表示方面的工作,这些功能使对话式AI(conversational AI)更加多样化并提供了相关的响应。 最重要的是,微软的库利用了TensorFlow,这使得用户可以轻松地使用多任务学习来构建复杂的培训配置。
AllenNLP
AllenNLP是一个基于PyTorch构建的开源NLP研究库。 AllenNLP使得针对任何NLP问题设计和评估新的深度学习模型变得容易。它也可以在云端或笔记本上高效运行。AllenNLP是由美国艾伦人工智能研究所(Allen Institute for AI)与华盛顿大学(University of Washington)的研究人员及其用户(包括Facebook research、Airbnb、Amazon Alexa和其他业内顶尖企业)密切合作建立和维护的。
Rasa Open Source
Rasa是一个开源框架,用于构建高性能、弹性、专有的上下文助理。它提供了必要的基础结构来创建可以理解消息并创建有意义对话的出色助手;运用机器学习来改善这些对话;并将其与现有系统和渠道无缝集成。
Apache OpenNLP
OpenNLP支持最常见的NLP任务,例如标记化、句子分段、词性标记、实体提取、分块、解析、语言检测和共指解析。Apache OpenNLP网站表示,他们一直在寻找新的贡献者来参与项目的各个部分,以使其变得更好。
BERT
BERT(Bidirectional Encoder Representations from Transformers)是Google于2018年下半年发布的一种预训练语言表示的新方法,可以在各种自然语言处理(NLP)任务中获得SOTA结果。
在2019年大部分时间中,BERT是最受关注的NLP项目,Google宣布将BERT用于其搜索引擎更增加了其关注度。 熟悉BERT是有益的,因为它带来了许多变体并且不断增长,尽管这些变体成为它的竞争对手,例如XLNet和ERNIE。
Hyperparameter Autotuning
此功能自动确定数据集的最佳超参数,以构建有效的文本分类器。使用自动调整功能,研究人员需要输入训练数据、验证集和时间约束。然后,FastText使用分配的时间搜索在验证集上提供最佳性能的超参数。研究人员还可以选择限制最终模型的大小。在这种情况下,fastText使用压缩技术来减小模型的大小。
此功能自动确定数据集的最佳超参数,以构建有效的文本分类器。使用自动调整功能,研究人员需要输入训练数据、验证集和时间约束。然后,FastText使用分配的时间搜索在验证集上提供最佳性能的超参数。研究人员还可以选择限制最终模型的大小。在这种情况下,fastText使用压缩技术来减小模型的大小。
研究人员可以在一个命令行中构建有效的文本分类器,因此现在可以为各种任务创建内存有效的分类器,包括情感分析、语言识别、垃圾邮件检测、标签预测和主题分类。
除了Spacy、Gensim和Hugging Face这样的项目外,这些都是目前广受欢迎的NLP项目。
(张梦婷编译,李朝安校对)
研究动态
Google发布ALBERT V2 &中文版
Google的ALBERT语言模型于2019年9月推出时,在GLUE,RACE和SQuAD 2.0等流行的自然语言理解(NLU)基准上获得了SOTA结果。Google现在已经发布了主要的V2 ALBERT更新和开源的中国ALBERT模型。
顾名思义,“A Lite BERT”表明ALBERT是该公司BERT(Bidirectional Encoder Representations from Transformers)语言表示模型的精简版本,该模型已成为NLU研究的主要内容。(论文:ALBERT: A Lite BERT for Self-supervised Learning of Language Representations)
正如同步报告中所述,Google的ALBERT是一个更精简的BERT;在3个NLP基准上实现SOTA,类似于BERT-large的ALBERT配置参数减少了18倍,并且训练速度提高了约1.7倍。
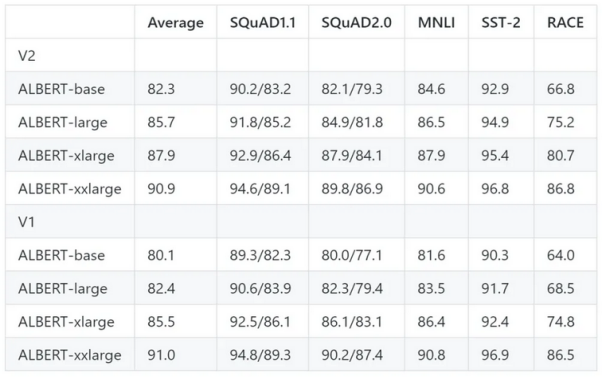
v2和v1模型的比较
ALBERT v2模型的主要变化涉及三种新的策略:无中途退出、额外的训练数据和较长的训练时间。研究人员对ALBERT-base进行了1000万步的训练,对其他模型进行了300万步的训练。结果表明,ALBERT v2的性能总体上比第一个版本有了显著的提高。
例外地,ALBERT-xxlarge v2的性能比第一个版本稍差。研究人员确定了两个可能的原因:1.额外训练150万步没有导致明显的性能改善; 2.对于v1,研究人员在参数集中进行了一些超参数搜索,而对于v2,他们采用了v1的参数,但对RACE测试超参数进行了微调。“考虑到下游任务对微调超参数敏感,因此需要谨慎对待所谓的细微改进。”
(张梦婷编译,李朝安校对)
项目工具
TensorFlow2.1正式版上线
去年 10 月,谷歌才发布了 TensorFlow 2.0 正式版。时隔三个月后,昨日官方发布了 TensorFlow 2.1,本次版本更新带了了多项新特性、功能改进和 bug 修复。
TensorFlow 2.1将是最后一个支持Python 2的TF版本。对Python 2的支持将于2020年1月1日正式终止。如前所述,TensorFlow也将从2020年1月1日开始停止支持Python 2,并且预计在2019年不会发布更多版本。
TensorFlow 2.1 最大的亮点在于进一步增加对 TPU 的支持。从 tf.keras、tf.data 等 API 的功能调整和更新来看,现在使用 TPU 加载数据集、训练和模型推理会更方便一些。
TensorFlow2.1正式版上线
在对操作系统的支持上,Windows 和 Linux 系统的 TensorFlow pip 版本默认支持 GPU。也就是说,如果使用 pip install tensorflow,则版本默认为是 gpu 版本(原始的 tensorflow-gpu 版本依然存在)。当然,不管有没有英伟达版本的 GPU,tensorflow 依然能够运行。如果需要使用 CPU 版本,用户的安装命令应该为:pip install tensorflow-cpu。
tensorflow pip软件包是使用CUDA 10.1和cuDNN 7.6构建的。
tf.keras:
增加了在 GPU 和 Cloud TPUs 上对混合精度(mix precision)的支持;参阅使用指南。(https://www.tensorflow.org/guide/keras/mixed_precision)
tf.Keras 中的 compile、fit、evaluate、predict 等 API 都支持 Cloud TPUs 了,而且支持所有的 Keras 模型(即以 sequential、functional 和子类方式构建的模型都支持);
现在为Cloud TPU启用了自动外部编译。 这使得tf.summary可以更方便地与Cloud TPU一起使用。
除了tf.data.Dataset之外,支持在 TPU 上使用 numpy 格式的数据上的.fit,.evaluate,.predict。
Cloud TPU支持带有分布式策略和Keras的动态批量大小控制。
引入了TextVectorization层,该层将原始字符串作为输入,并负责文本标准化,标记化,N 元语法生成和词汇索引。
只要在范围内构造模型,就可以将Keras .compile .fit .evaluate和.predict置于DistributionStrategy范围之外
诸多流行模型的 Keras 参考实现都可以在 TensorFlow Model Garden(https://github.com/tensorflow/models/tree/master/official)中获得;
tf.data:
tf.data.Dataset 现在支持在分布式环境下自动数据分发(automatic data distribution),包括在 TPU pods 上都可以。
tf.data datasets 和分布式策略都进行了改进以获得更好的性能。请注意,因为重新进行了分批的数据集会有多个副本, dataset 的行为会变得略有不同。
现在可以使用以下命令调整分布式策略: tf.data.experimental.AutoShardPolicy(OFF, AUTO, FILE, DATA) tf.data.experimental.ExternalStatePolicy(WARN, IGNORE, FAIL)
tf.distribute:
支持在 TPU 和 TPU pods 上自定义训练循环,通过以下 API 即可:
TensorRT:
现在默认情况下支持并启用TensorRT 6.0。 这增加了对更多TensorFlow操作的支持,包括Conv3D,Conv3DBackpropInputV2,AvgPool3D,MaxPool3D,ResizeBilinear和ResizeNearestNeighbor。
通过tf.experimental.tensorrt.Converter 实现TensorFlow 和 TensorRT 的 Python 交互。
strategy.experimental_distribute_dataset strategy.experimental_distribute_datasets_from_function strategy.experimental_run_v2 strategy.reduce
Bug 修复
tf.data
修复当 sloppy=True 时 tf.data.experimental.parallel_interleave 出现的并发问题;
增加 tf.data.experimental.dense_to_ragged_batch();
扩展 tf.data 语法解析选项以支持 RaggedTensors。
tf.distribute
修复使用 tf.distribute.Strategy 时 GRU 崩溃或输出错误结果的问题。
tf.keras
在tf.keras.backend导出depthwise_conv2d。
在Keras 图层和模型中,删除 trainable_weights、non_trainable_weights 和 weights 中变量的重复数据。
Kerasmodel.load_weights 现将 skip_mismatch 接受为参数。
修复 Keras 卷积层的输入形状缓存的行为。
现在Model.fit_generator、Model.evaluate_generator、Model.train_on_batch, Model.test_on_batch 和 Model.predict_on_batch 方法现遵循 run_eagerly 属性,并且默认情况下将使用tf.function正确运行。请注意,Model.fit_generator、Model.evaluate_generator 和 Model.predict_generator 是弃用的端点。这些端点现已被归入支持生成器和序列的 Model.fit、Model.evaluate 和 Model.predict 中。
(李朝安编译,张梦婷校对)
近期论文
Embedding Compression with Isotropic Iterative Quantization
SiyuLiao JieChen YanzhiWang QinruQiu BoYuan
主要贡献:
文章提出了一种各向同性的迭代量化(Isotropic Iterative Quantization, IIQ)方法。能够将嵌入矢量压缩为二进制矢量,实现超过30倍的压缩率,并且与原始的实值嵌入向量相比具有相近甚至有时更高的性能。从而解决了大量词汇的连续表示占用大量内存的问题。
研究动机:
在许多自然语言处理(NLP)应用中,单词是基本单位,一种困难在于应用程序中常见的大量词汇。此外,它们的语义排列可能很多,构成了句子和段落级别的丰富表达。在统计语言模型中,学习单词分布的单字组,双字母组和一般n元组。给定大量词汇,直方图已经足够复杂。然而,bigram分布的复杂度在词汇量上是平方的,而n-gram的复杂度则是指数的。
代替单词分布,具有浮点向量的连续表示更方便处理:它们是可区分的,并且它们的差异可用于绘制语义分类学。多年来,人们提出了各种算法来学习这些单词向量。两个代表性的向量表示是Word2Vec和GloVe。但是,代表大量词汇需要大量内存,这可能会引起问题,尤其是在资源受限的平台上。经过预训练的Word2Vec包含3M字向量,存储空间约为3GB。在资源受限的平台上部署时,此成本成为瓶颈。因此,研究单词嵌入的压缩至关重要。
模型思路:
鉴于NLP应用中各向同性的成功,本文旨在改善各向同性的同时最小化量化损失,而不是最大化位方差。此方法称为各向同性迭代量化IIQ。在IIQ方法中,我们表明正交变换保持了输入嵌入的各向同性,因此我们可以在ITQ中应用类似的替代过程来最小化量化损失。因此,该方法由三个步骤组成:最大化各向同性,降低维数和最小化量化损失。
- 最大化各项同性
- 降低维数
- 最小化量化损失
各向同性测度I(X)可以近似如下:
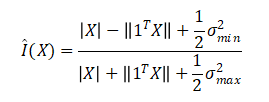
其中Qmin和Qmax分别为X最小和最大奇异值。通过给定嵌入的零中心,并通过删除大的奇异值以使其余的奇异值彼此接近来大致实现I(X)最大。将最大化结果表示为X^
为了方法更灵活,使用PCA进行降维。此步骤基本上删除了最小的奇异值,以便进一步加强奇异值的聚类。 请注意,PCA不会影响给定嵌入的最大化各向同性,因为它仅适用于在上一步之后彼此已经闭合的奇异值。可以对每个数据集量身定制的维数超参数。
给定最大化各项同性的解X^,将X^正交矩阵R相乘的结果会拥有相同的I(X)。因此可以使用正交矩阵R来减少量化损失。采用ITQ中的迭代优化策略,通过两个步骤实现局部最小值。
首先对一个给定的计算,然后,对于给定的更新值,该更新使量化损失最小
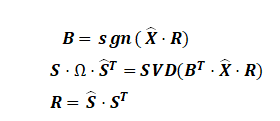
其中SVD(.)是奇异值分解数,是奇异值的对角矩阵。该迭代更新策略将一直运行,直到找到本地最佳解决方案为止。。
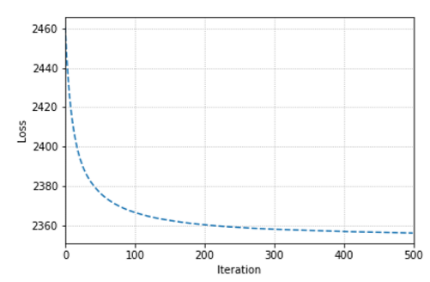
来自预训练的CNN模型的50000个嵌入向量的量化损失曲线。
实验结果:
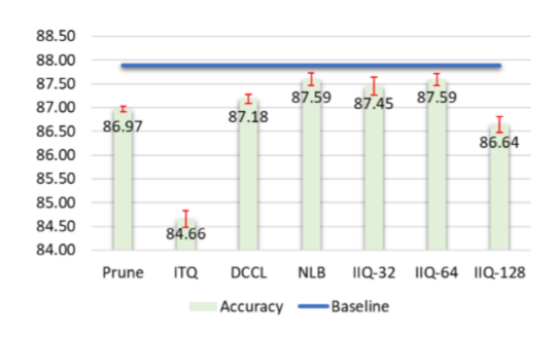
情绪分析任务IIQ与ITQ的比较
本文对于各种NLP任务(单词相似性分析、分类任务、主题聚类和情绪分析)的压缩嵌入进行了评估。并将实验结果可视化,得到IIQ方法对于单词相似性,分类和其他一些下游任务是有效的。由于各向同性的改善,IIQ的性能优于ITQ。这些发现基于32倍(和更高)的压缩比。结果表明,在现实生活中,在资源受限的平台上部署带有词嵌入功能的训练后的神经网络模型很有希望。
(李朝安编译,张梦婷校对)
LEARNING CROSS-CONTEXT ENTITY REPRESENTATIONS FROM TEXT
Jeffery Ling Nicholas FitzGerald Zifei Shan Livio Baldini Soares Thibault Fevry David Weiss Tom Kwiatkowski
主要贡献:
提出了RELIC(Representations of Entities Learned in Context ),一个独立实体嵌入表经过训练,可以匹配已在其中看到这些文本上下文的固定长度矢量表示。并将RELIC应用于实体类型、实体链接和琐碎的问答,介绍了一种新颖的镜头分类重建任务,发现RELIC能够更好地捕获复杂的化合物类型,方法在实体链接方面也被证明是成功的,尽管没有使用链接的特定功能,但仍匹配CoNLL-Aida上的最新技术。证明了RELIC嵌入可直接用于回答琐事问题,而无需访问任何证据文件。
研究动机:
人工智能的长期目标是发展和普及以人为中心的人类知识,尽管我们已经能够创建知识表示,但这些方法在很大程度上依赖于人类对其本体论的定义,故而定义的范围有限且性质脆弱。相反,由于深度学习的最新进展,我们现在可以直接从大型文本语料库中学习单词和上下文化短语的强壮通用表示。特别是,我们观察到现有的建立上下文化短语表示的方法捕获了大量的局部语义上下文,故而认为通过学习一个聚合了实体所处的所有文本上下文的实体编码器,我们应该能够提取和浓缩关于该实体的通用知识。从而对于仅给定类别的几个示例性实体,我们可以使用RELIC来高精度地恢复该类别的其余实体。
模型思路:
从语境中学习
- RELIC训练输入
- 上下文编码器
- 实体嵌入
- RELIC训练损失

使用Transformer文本编码器将D中的每个上下文嵌入到固定长度的向量中,并使用BERT-based模型中的参数进行初始化。将与BERT序列表示中的初始[CLS]token相对应的Transformer输出作为上下文编码,并使用学习的权重矩阵W∈R(d*768)将其线性投影到R(d)中,得到与实体嵌入在同一空间中的上下文嵌入作为我们的实体嵌入。
每个实体e∈ε具有唯一的抽象Wikidata QID。RELIC通过|ε|*d维嵌入矩阵将这些唯一ID直接映射到R(d)中的专用向量上。
RELIC优化了上下文编码器和实体嵌入表的参数,以最大化观察到的(上下文,实体)对之间的兼容性。令g(x)→R(d)作为上下文编码器,再令f(e)→R(d)作为一个嵌入函数,其可通过查找操作将每个实体映射到其d维表示。将实体e和上下文x之间的兼容性得分定义为缩放余弦相似度(scaled cosine similarity)
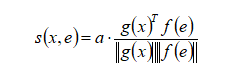
其中缩放因子(scaled factor)a是一个已学习的参数(learned parameter)。 下面给定一个上下文x,条件概率e定义为
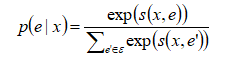
然后通过最大化平均对数概率来训练RELIC
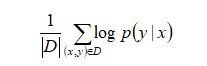
实验结果:
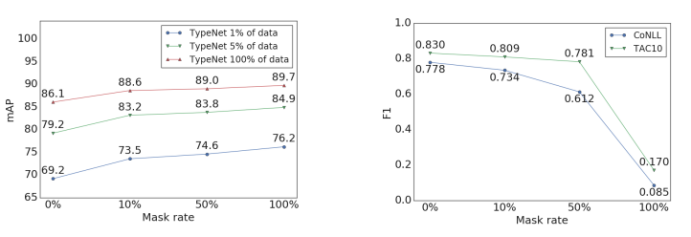
左图:开发集上的TypeNet实体级键入mAP,用于使用不同屏蔽率训练的RELIC模型。 在低数据和高数据情况下,较高的屏蔽率都会带来更好的性能。
右图:使用不同屏蔽率训练的RELIC模型的实体链接精度,未使用别名表或域内微调。 较高的屏蔽率会导致实体链接任务中的下游性能变差。
在训练过程中掩盖提及内容对实体键入任务很有帮助,但对实体链接有害。对提到的曲面形式进行建模对于链接至关重要,因为这些提及是在测试时给出的,并且名称具有极高的区分性。上图中的趋势之间的差异表明,可能没有一组实体嵌入对于所有的任务都是最佳的,但是RELIC的屏蔽率为10%,在大多数任务上接近最佳性能。RELIC的“填空”任务使我们能够学习具有潜伏本体的实体的上下文独立表示,能够更好地捕获复杂的化合物类型。并且RELIC嵌入可直接用于回答琐事问题,而无需访问任何证据文件。
(张梦婷编译,李朝安校对)
近期会议
ICAART 2020: International Conference on Agents and Artificial Intelligence
Feb 22 - Feb 24, 2020 马耳他 瓦莱塔
ICAART中有2条路线,一条与一般的Agent和Distributed AI相关,另一条与智能系统和计算智能相关。会议计划由几种不同类型的会议组成,例如技术会议,海报会议,主题演讲,教程,专题会议,博士联合会,小组和工业会议。会议上发表的论文可在SCITEPRESS数字图书馆中获得,并在会议记录中发表,并且一些最佳论文被邀请与Springer进行后期公开。
ICLR 2020:International Conference on Learning Representations
Apr 26 - Apr 30 ,2020 埃塞俄比亚 亚的斯亚贝巴
ICLR是每年春季举行的机器学习会议。自2013年成立以来,ICLR就采用了公开的同行评审程序来提交裁判论文(基于Yann LeCun提出的模型)。 2019年,有1591篇论文提交,其中500篇接受海报展示(31%),24篇接受口头演讲
JCDL 2020: Joint Conference on Digital Libraries
June 19 - June 23 ,2020 湖北 武汉
数字图书馆联合会议(JCDL)是一个重点讨论数字图书馆及其相关的技术实践以及社会问题的国际论坛。JCDL通过将ACM数字图书馆会议和IEEE-CS数字图书馆会议的进展结合起来,加强了ACM和IEEE-CS已经建立的会议卓越的传统。在本次会议上,JCDL向在该领域做出杰出贡献的人士颁发Vannevar Bush最佳论文奖、最佳学生论文奖、最佳国际论文奖、最佳海报奖。该会议邀请国家和国际社会就数字图书馆感兴趣的广泛主题发表论文。