文本挖掘与机器学习跟踪扫描动态快报(2020.09)
实时跟踪、关注文本挖掘与机器学习领域最新研究动态
深度观察
新的多任务基准测试表明,即使是最好的语言模型也不知道自己在做什么
New Multitask Benchmark Suggests the Best Language Models don't Have a Clue What they're Doing
基于Transformer的语言模型在自然语言处理(NLP)基准测试方面表现出色,这要归功于它们对大量文本语料库(包括所有Wikipedia、数千本书和无数网站)的预训练。尽管模型接触到海量的信息,研究人员仍然不确定他们学习和应用知识的能力如何,即这些语言模型实际上能理解多少?
事实证明不是很多。
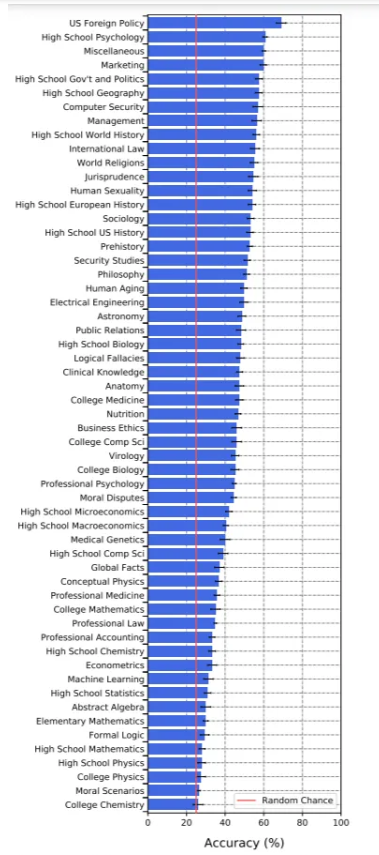
最近发表的论文Measuring Massive Multitask Language Understanding介绍了一项测试,涵盖诸如基础数学,美国历史,计算机科学,法律等主题,旨在测量语言模型的多任务准确性。来自加州大学伯克利分校、哥伦比亚大学、芝加哥分校和UIUC的作者总结说,即使是最顶级的1750亿参数的OpenAI GPT-3语言模型,在语言理解方面也有点愚蠢,尤其是在遇到比以前的基准更广和更深入的话题时。

为了评估语言模型从大量语料库中提取有用知识来解决问题的能力,研究人员编制了一套测试集,共有15908个问题,涉及STEM、人文科学和社会科学的57个不同主题。
与目前衡量语言模型背后的常识或狭义语言理解的基准不同,新测试旨在“测量任意的真实世界文本理解”和“全面评估模型的学术和专业理解的广度和深度”。
大规模的多任务测试包括来自不同知识分支的不同难度的多项选择题,分为少shot(few-shot)的开发集,验证集和测试集。 57个主题中的每个主题都包含至少100个测试示例,以检查零shot和少shot设置下的模型。


评估的语言模型是带有27亿,67亿,130亿和1750亿参数的变体形式的UnifiedQA(带有T5)和GPT-3。在实验中,所有模型在所有任务中的表现都低于专家水平。最大的GPT-3模型表现最好,平均准确率为43.9%,比随机概率提高了约20个百分点。该模型在美国外交政策类问题中的最高准确率为69%,而在大学化学中的得分最低,其26%的准确率与随机回答的结果基本相同。对于所有的模型,几乎随机准确率(25%)的任务包括与人类价值观相关的主题,例如法律和道德,以及物理和数学等计算量大的科目。

研究人员发现GPT-3在高度程序化的问题上表现不佳,他们怀疑这是因为模型比程序性知识更容易获得声明性知识。与口语科目相比,计算量大的STEM科目更容易打倒GPT-3。例如,虽然它知道PEMDAS代表圆括号、指数、乘法、除法、加减法(这是一种记忆方程式中数学运算顺序的常用技术),但它却未能应用这些知识来计算(1+1)×2=?
该团队表达了他们的担忧:“GPT-3对于自己的所作所为没有一个准确的感觉,因为它的平均置信度可能会比它的实际准确率高出24%。”难怪纽约大学副教授兼AI研究员Julian Togelius之前在推特上说,“GPT-3通常表现得像一个聪明的学生,他还没读完书,就在考试中胡说八道。一些众所周知的事实,一些半真半假的事实,还有一些直截了当的谎言,交织在一起,乍一看似乎是一个流畅的叙述。”
(张梦婷编译,王宇飞校对)
研究动态
OpenAI的“GPT-f” 在数学定理自动证明中性能达到SOTA
OpenAI‘GPT-f’Delivers SOTA Performance in Automated Mathematical Theorem Proving
总部位于旧金山的AI研究实验室OpenAI,为其广泛使用的GPT家族添加了另一个成员。在一份新论文中,OpenAI研究人员介绍了GPT-f,它是Metamath形式化语言的自动证明助手。
虽然人工神经网络在计算机视觉,自然语言处理,机器人技术等方面取得了长足的进步,但OpenAI相信它们在推理任务的某些相对未开发的领域中也具有潜力。这项新研究通过将可迁移的语言模型应用于自动定理证明来探索这种潜力。

数学定理自动证明任务往往需要既通用又灵活的推理过程才能有效地检验证明的正确性。这使得它成为检查语言模型的推理能力和研究推理本身的一个十分吸引人的领域。验证证明的能力还可以自动生成可用作训练数据的新问题,这对研究人员来说十分有益。
研究人员发现,学习证明定理与学习玩古老的围棋游戏之间有相似之处,因为两者都提供了自动确定成功和通过自身尝试生成新数据的方法。因此,AlphaZero在围棋中的成功表明,自动定理证明可能是神经网络推理研究的一个具有广阔前景的领域。
Metamath是一种用于存档,验证和研究数学证明的语言和计算机程序。 研究人员使用Metamath(由基于单替换规则的简单元逻辑系统提供动力)作为正式环境,使用类似于GPT-2和GPT-3的仅编码器的transformer来创建具有各种预训练数据集和不同大小的模型。他们最大的模型具有36层和774M的可训练参数。
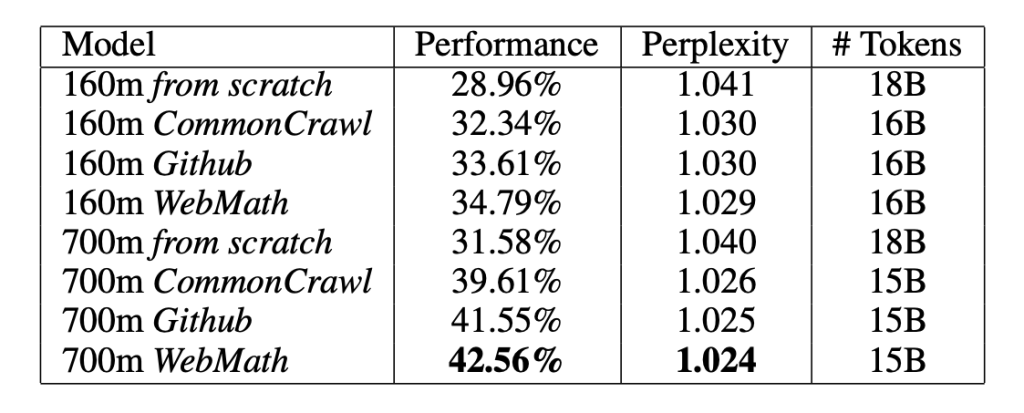
研究人员创建了GPT-f在线证明助手,以在其模型的帮助下进行交互式证明构造。 在实验中,GPT-f在Metamath库上获得了最新且最佳的(SOTA)结果,完成了来自留出测试集的56.22%的证明,而目前的SOTA模型MetaGen-IL则仅达到了21.16%,以证明迁移器体系结构在正式推理中的潜力。
GPT-f还发现了新的简洁证明,这些证明已被Metamath主库接受。 研究人员说,这可能是基于深度学习的系统首次为正规数学界所采用的证明提供帮助。
研究人员总结说:“我们的结果表明,将深度学习系统与正式系统紧密结合在一起,可以为进一步研究提供了有趣的可能,其目的是更好地利用前者的生成能力和提高后者的验证能力。”
(张梦婷编译,李朝安校对)
GreenKey发布针对对冲基金的NLP工具
自定义模型使交易者可以在几分钟内完成卖方研究。GreenKey的平台包括以“可信责任人”为基础的训练后模型,这种模型了解华尔街“行话”。交易者可以自动进行主题分类和情绪分析,从而不必阅读数千页的研究,新闻或收益记录。
可销售的NLP工作流的创建者GreenKey(GK)已发布了其最新版本的“ Focus Studio”应用程序,该应用程序专门为对冲基金而设计。银行销售团队使用Focus Studio在其桌面上自定义NLP,以在电子邮件,即时消息和电话中查找客户见解(例如OTC报价和交易)以处理越来越多的会话数据。突出显示的见解以每日报告的形式提供,也可以用于支持实时自动化处理(例如聊天机器人)。 如今,最新版本的Focus Studio包括专门为对冲基金设计的NLP模型,以帮助他们应对阅读的大量非结构化文本以产生交易思路。
这些新的NLP模型在实际的卖方人员分析上进行了训练,以获取他们的见解,还能够通过快速注释过程自定义模型。交易者将从提供的“可信责任人”的基本模型中进行选择,甚至可以要求他们喜欢的卖方研究分析师为社区创建一个他自己的模型。然后,可以向自定义模型集合提供数千个文档,模型将识别主题,意图,实体,甚至可以提供原始情感评分,例如“言语不满”。 预先训练的模型还包括跨国固定收益,信贷,股票,外汇和商品市场的深入产品知识。
GK创始人兼首席执行官Anthony Tassone说:“ NLP已经改变了在卖方进行销售和交易的方式,从而在各种工作流程中产生了自动化和生成洞察力。” “现在,买方可以开始利用NLP来自动化和扩展其分析,同时保留卖方研究提供者和分析师的“受信任责任人”角色。” Focus Studio是一个全面、灵活的工具,模型,社区资源生态系统,可让用户在内部或云中构建和部署NLP支持的工作流。
(李朝安编译,王宇飞校对)
2021年十大自然语言处理趋势
2020年是基于深度学习的NLP研究的繁忙一年。最大的声响是由迄今为止发布的最大的NLP转换器GPT-3产生的。OpenAI的GPT-3(175B参数)比微软研究公司Turing NLG先前保持的17B参数记录高出了约10倍。
NLP的当代发展需要的训练数据量比以往任何时候都要少。除了将这些深度学习模型与传统的基于规则的算法一起用于更精确的文本分析、情感分析、会话式AI以及许多其他用例之外,这些其他案例可以解释该技术的强大优势。
为了简化NLP的复杂性,Analytics Insight为2021年带来了十大自然语言处理趋势:
1.有监督学习与无监督学习协作
有监督和无监督学习的应用为自然语言处理提供了巨大的支持。例如,文本分析利用无监督和有监督的学习来理解文档中的技术术语及其词类,而无监督学习可以确定它们之间的共生关系。
2.用强化学习训练NLP模型
虽然强化学习在样本效率、训练时间和总体最佳实践方面都有了很大的提高,但是从头开始训练RL模型仍然比较缓慢和不稳定。因此,与其从头开始训练一个模型,数据专家们希望首先训练基于NLP的监督模型,然后使用强化学习对其进行微调。
3.精确的深度学习分类
深度学习在自然语言处理中的应用是多方面的。像递归神经网络(RNN)这样的技术可以通过解析给数据科学家一个精确的文本分类。因此,RNN将成为某些文本分析平台中文档分类和实体标记的流行趋势。
4.市场情报监测
NLP将在跟踪和监测市场情报报告方面发挥关键作用,以便为企业未来战略制定提取智能信息。2021年及以后,NLP将在众多的商业领域找到它的应用。目前这项技术在金融营销中得到了广泛的应用。它分享对市场情绪、投标延期和交割的详尽见解,并从大型存储库中提取信息。
5.微调模型将是无缝的
迁移学习将为预训练的模型创造条件,从而为情感分析、文本分类等创建应用程序。在医疗使用案例中,迁移学习将使诸如患者满意度之类的情况得以准确衡量。这一点同样适用于任何服务业,其中满意度将是代表消费者满意与否的可能性的分数。
6.定制产品推荐
电子零售商将使用NLP和机器学习技术来提高客户参与度,分析其浏览模式和购物趋势。其他智能洞察还包括购买行为、自动生成的产品描述等。
7.智能语义搜索
语义搜索的需求是预计将在2021年影响NLP的另一趋势。这种搜索将涉及自然语言处理和自然语言理解,这需要对文本中包含的中心思想有详尽的理解。
8.智能认知通信
NLP在理解用户意图的用例中也会变得更加常见,比如智能聊天机器人和语义搜索。在深度学习、无监督和有监督机器学习的推动下,过多的自然语言技术将继续塑造认知计算的通信能力。
9.聊天机器人和虚拟助理的增长
在自然语言处理(NLP)发展的推动下,聊天机器人和虚拟助手市场的增长将是强劲的。聊天机器人市场在2019年价值26亿美元,预计到2024年将达到94亿美元。
10.社交媒体的情感分析
自然语言处理将是理解和分析受众对在社交媒体平台上发布的品牌传播的反应的一个很好的工具,也称为意见挖掘。它有助于分析通过社交媒体帖子与公司进行评论/互动的消费者的态度和情绪状态(快乐,悲伤,愤怒,恼火等)。
NLP的实际使用使拥有大量非结构化文本或语音数据的组织能够克服暗数据问题,并有效地挖掘这些问题以获取见识。然而,NLP真正值得注意的是它所涉及的AI的多个维度,暗示了这项技术在未来几年将产生的整体动态影响。
近期论文
Can Fine-tuning Pre-trained Models Lead to Perfect NLP? A Study of the Generalizability of Relation Extraction
Ningyu Zhang Luoqiu Li Shumin Deng Haiyang Yu Xu Cheng Wei Zhang HuajunChen
研究动机:
自我监督的预训练语言模型例如BERT和RoBERTa等,在标准的自然语言处理基准中取得了很好的成绩。但是,这些类型的模型的泛化行为仍然无法解释,即任务性能与对模型泛化性能的理解之间存在巨大差距。先前的方法表明,当遇到随机排列的上下文、对抗示例和对比集时,神经模型的鲁棒性较差且容易产生偏见,例如选择和语义偏见。
研究贡献:
该研究将关系提取(RE)作为研究案例,从鲁棒性和偏见方面诊断预训练模型的泛化能力。
研究内容:
1.泛化能力鲁棒性测试
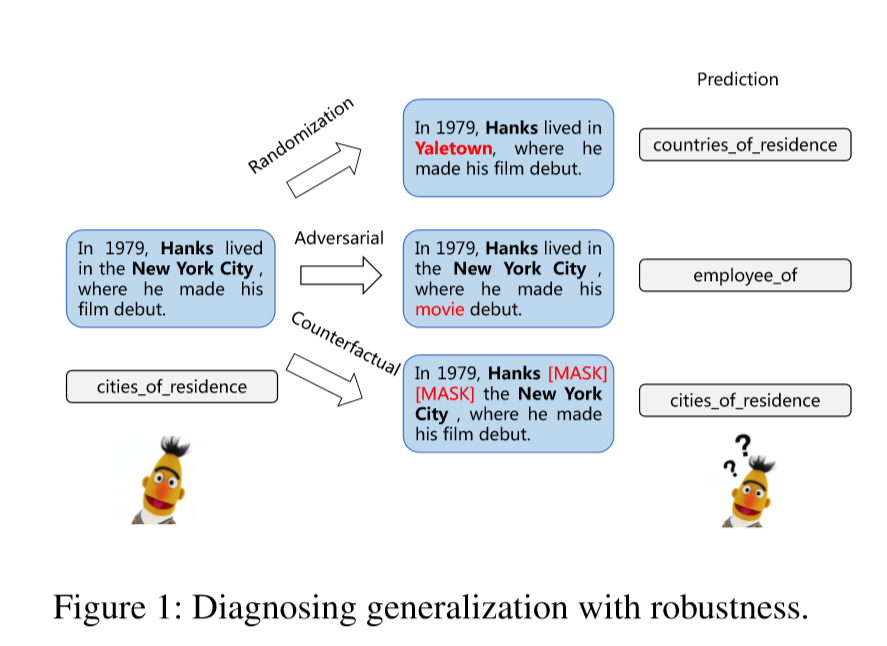
该研究从三个方面研究了关系提取的鲁棒性:随机化、对抗性、反事实,如下图所示。随机化测试旨在通过随机token排列来探究性能,对抗性分析用于研究其在遇到对抗排列时的稳定性,对比集用于分析模型是否捕获了相关现象。
2.诊断带偏见的泛化
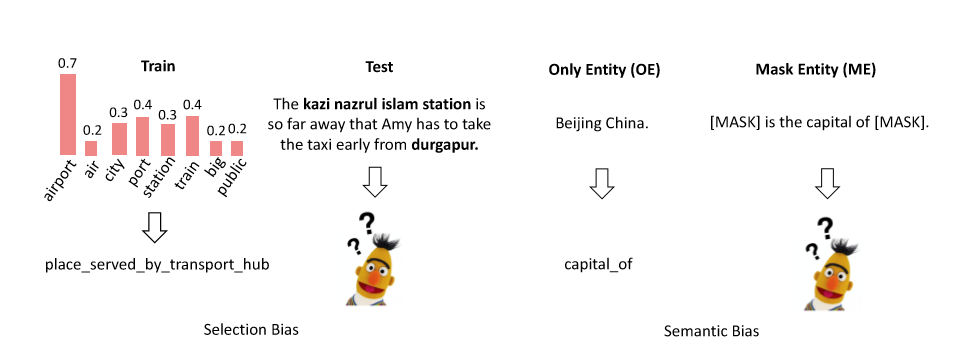
选择偏见一直是社会科学中的一个关注点,对这种偏见的考虑现在已被视为研究设计中的主要考虑因素。语义偏差的来源可能是嵌入模型的参数。 语义偏差会引起其他偏差。
实验结果
如下表所示,整体性能在强大的实体和上下文排列集合中急剧下降。 BERT随实体排列而具有更显着的性能衰减,这表明该模型对于不同的头和尾的实体是不稳定的。但BERT数据增强后在原始测试集和更强大的测试集上均取得了更好的性能。但是,鲁棒性的测试整体上能仍远远不能令人满意。
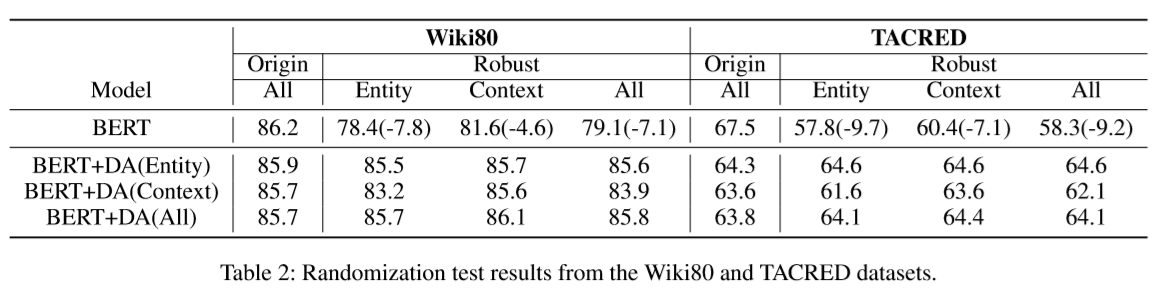
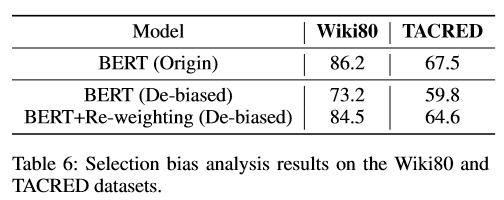
由下表可以注意到,BERT在去偏集上的性能很差,这表明在先前的基准测试中存在选择偏倚。与去偏集上的BERT相比,BERT重加权获得了相对更好的结果,这表明基于频繁的重采样是有益的。 <\p>
结论:
文章发现BERT对随机排列(即实体)敏感,这表明对预训练模型进行微调仍然会面临较差的鲁棒性。文章还观察到,数据增强可以使性能受益。BERT容易受到对抗性攻击,这些攻击包括合法的输入。 对抗训练可以帮助增强鲁棒性,但结果仍远远不能令人满意。在对比设置中,模型的性能会下降,但是反事实数据的增强会增强鲁棒性。BERT易于学习简单的提示,但是重新加权有助于减轻偏见。该模型中存在语义偏见,实体掩盖可以稍微缓解这种情况。
(王宇飞编译,张梦婷校对)
近期会议
ICADL 2020
Nov30 – Dec1, 2020 线上
https://2020.ifla.org/conference-programme/calls-for-papers/
亚太数字图书馆国际会议(ICADL)于1998年在香港开始举办,被评为“核心A”会议。在过去的几十年中,许多新兴的研究领域,如数字人文科学、开放科学、社会信息学,都起源于数字图书馆,ICADL将继续致力于为学者们提供一个就新兴、现存领域进行讨论、交流的平台。第22届“亚太数字图书馆国际会议”将采取线上形式,论文集将由Springer出版,并由Scopus索引。今年提交论文形式有三种:长文,短文和实践性论文(practitioners papers)。
NeurIPS 2020:Neural Information Processing Systems
Dec5 – Dec12, 2020 加拿大 温哥华
ICCV (IEEE International Conference on Computer Vision),即国际计算机视觉大会,由IEEE主办,与计算机视觉模式识别会议(CVPR)和欧洲计算机视觉会议(ECCV)并称计算机视觉方向的三大顶级会议,被澳大利亚ICT学术会议排名和中国计算机学会等机构评为最高级别学术会议,在业内具有极高的评价。ICCV是主要的国际计算机视觉盛会,包括主要会议和几个位于同一地点的讲习班和教程。为学生,学者和行业研究人员提供了非凡的价值。
•ICCV 2021: International Conference on Computer Vision
Oct11 – Oct17, 2021 加拿大 蒙特利尔
国际图书馆协会联合会(International Federation of Library Associations and Institutions)成立于1927年,是联合各国图书馆协会、学会共同组成的一个机构,是世界图书馆界最具权威、最有影响的非政府的专业性国际组织,也是联合国教科文组织“A 级”顾问机构,国际科学联合会理事会准会员,世界知识产权组织观察员,协会总部设在荷兰海牙。