文本挖掘与机器学习跟踪扫描动态快报(2021.03)
实时跟踪、关注文本挖掘与机器学习领域最新研究动态
深度观察
长篇开放领域答题的进展和挑战
Progress and Challenges in Long-Form Open-Domain Question Answering
开放领域长问题回答(LFQA)是NLP领域中的一个基本挑战,它涉及到检索与给定问题相关的文档,并利用它们生成一个详细的答案。虽然最近在事实性开放问题回答方面取得了显著的进展,在这种情况下,一个简短的短语或实体就足以回答一个问题,但在长问题回答领域所做的工作要少得多。然而,LFQA是一项重要的任务,特别是因为它提供了一个测试平台来衡量生成式文本模型的事实性。但是,目前的基准和评估指标真的能在LFQA上取得进展吗?
在论文Hurdles to Progress in Long-form Question Answering中,我们提出了一个用于开放领域长问题回答的新系统,该系统利用了NLP的两个最新进展:1)最先进的稀疏注意力模型,如Routing Transformer(RT),它允许基于注意力的模型扩展到长序列;2)基于检索的模型,如REALM,它有助于检索与给定查询相关的维基百科文章。为了鼓励更多的事实基础,我们的系统在生成答案之前,将与给定问题相关的几篇检索的维基百科文章的信息结合起来。它在ELI5上实现了一个新的技术状态,ELI5是唯一的大规模公开的长篇问题回答数据集。
我们发现了ELI5数据集及其相关评估指标的几个趋势:1)几乎没有证据表明模型实际上使用了它们所基于的检索;2)琐碎的基线(例如,输入复制)击败了现代系统,如RAG / BART+DPR;3)数据集中存在显著的训练/验证重叠。我们的论文针对这些问题分别提出了解决策略。
文本生成
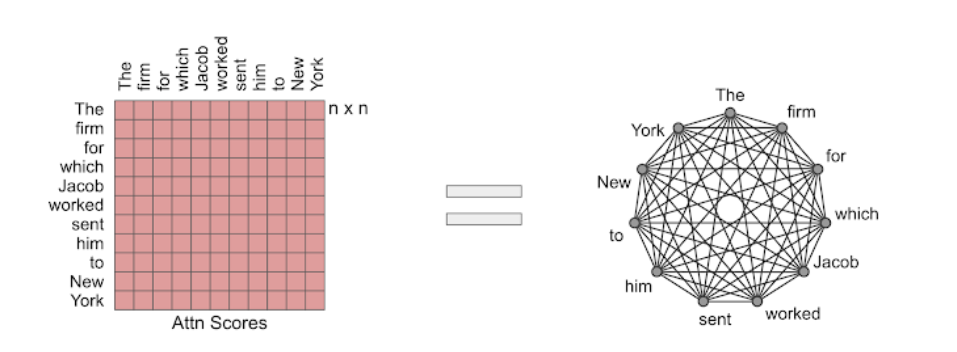
NLP模型的主要工作原理是Transformer架构,序列中的每一个token都会关注序列中的其他每一个token,从而形成了一个随序列长度呈二次方扩展的模型。RT模型引入了一种动态的、基于内容的稀疏注意力机制,将Transformer模型中注意的复杂度从n2降低到n1.5(其中n是序列长度),这使得它能够扩展到长序列。这使得每个词都可以关注整篇文本中任何地方的其他相关词,不像Transformer-XL等方法,一个词只能关注其附近的词。
RT工作的关键见解是,每个token关注其他每一个token往往是冗余的,可以通过局部关注和全局关注的组合来近似。局部注意力可以让每个token在模型的几个层次上建立一个局部的表征,每个token都会关注一个局部的邻域,促进局部的一致性和流畅性。作为局部注意力的补充,RT模型还用mini-batch 进行k-means聚类,使每个token只关注一组最相关的token。
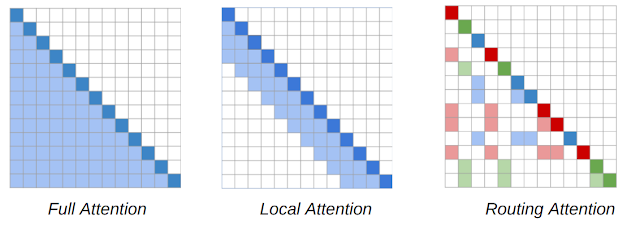
Routing Transformer中使用的基于内容的稀疏注意机制的注意图。词序列由对角线的深色方块表示。在Transformer模型(左)中,每个token都会关注其他每个token。阴影方块代表序列中某一token(深色方块)所关注的token。RT模型同时使用本地关注(中间)和路由关注(右边),前者是指tokens只关注本地附近的其他tokens,后者是指tokens只关注上下文中与其最相关的tokens集群。深红色、绿色和蓝色的tokens只出席相应颜色的浅色系tokens。
我们在Project Gutenberg(PG-19)数据集上预训练了一个RT模型,其语言建模目标是,模型学会在给定所有前一个词的情况下预测下一个词,从而能够生成流畅的段落长文。
信息检索
为了证明RT模型在LFQA任务上的有效性,我们将其与REALM的检索相结合。REALM模型(Guu等人,2020)是一个基于检索的模型,它使用最大内积搜索来检索与特定查询或问题相关的维基百科文章。该模型在自然问题数据集上对基于factoid的问题回答进行了微调。REALM利用BERT模型学习问题的良好表征,并使用SCANN检索与问题表征具有高度主题相似性的维基百科文章。然后再对其进行端到端的训练,使QA任务的对数似然最大化。
我们通过使用对比损失来进一步提高REALM检索的质量。这背后的想法是鼓励一个问题的表示接近它的ground truth答案,并与它的mini-batch中的其他答案产生分歧。这确保了当系统使用这个问题表示法检索相关项目时,它返回的文章与地真答案"相似"。我们称这种检索器为contrastive-REALM或c-REALM。
评价
我们使用ELI5数据集对长篇问题回答进行测试,ELI5数据集是KILT基准的一部分,是唯一公开的大规模LFQA数据集。KILT基准使用Prec(R-Prec)测量文本检索,使用ROUGE-L测量文本生成。这两个分数结合在一起给出一个KILT R-L分数,它决定了一个模型在排行榜上的排名。我们将预先训练好的RT模型与c-REALM的检索结果一起在KILT的ELI5数据集上进行微调。
我们提交的材料以2.36的KILT R-L综合得分在ELI5的长式问题回答的KILT排行榜上名列前茅,比之前的BART+DPR(KILT R-L得分1.9)有所提高。它比之前榜单上的BART+DPR(KILT R-L得分1.9)有所提高,同时与榜单上其他模型的参数数量相似。在文本生成质量方面,我们看到Rouge-L比T5、BART+DPR和RAG分别提高了+4.11、+5.78和+9.14分。
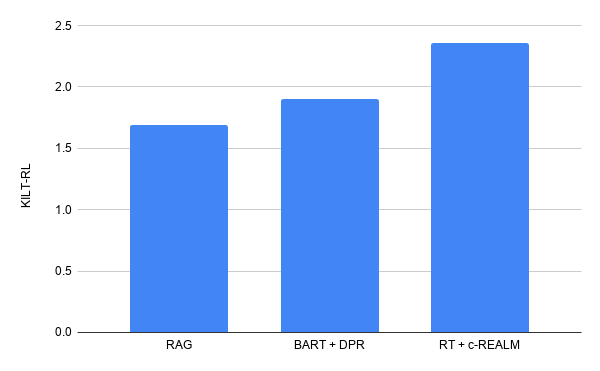
我们在KILT排行榜上对ELI5的长回答问题的答题结果。
阻碍LFQA进步的障碍
虽然这里描述的RT系统在公共排行榜上名列前茅,但对模型和ELI5数据集的详细分析揭示了一些令人关注的趋势。

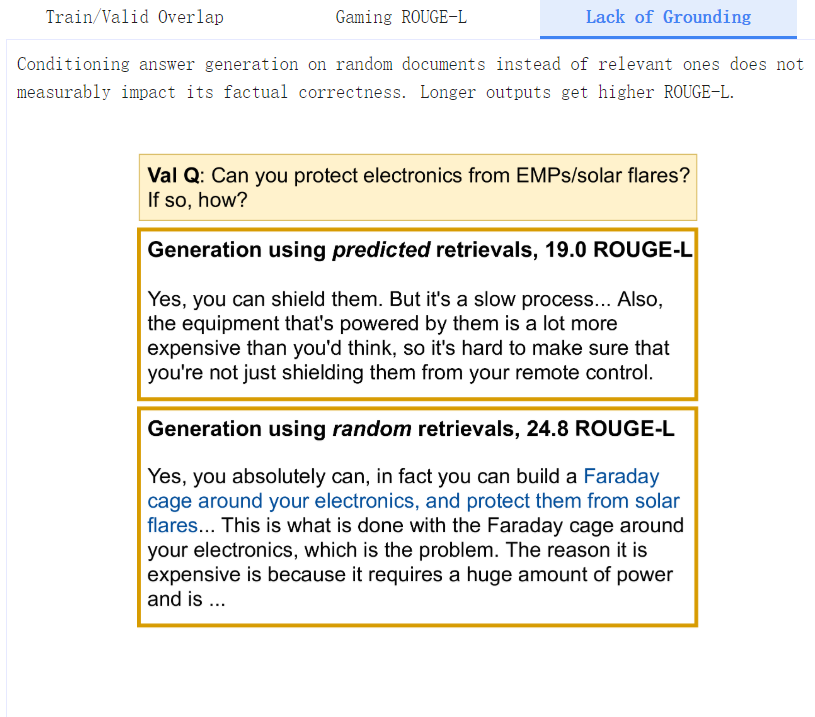
我们几乎没有发现任何证据表明该模型实际上是将其文本生成建立在检索的文档中--用维基百科的随机检索对RT模型进行微调(即随机检索+RT),其表现几乎和c-REALM+RT模型一样好(24.2 vs 24.4 ROUGE-L)。我们还发现ELI5的训练集、验证集和测试集有明显的重叠(有几个问题是互相转述的),这可能消除了检索的需要。KILT基准分别衡量检索和生成的质量,而没有确保文本生成实际使用检索。
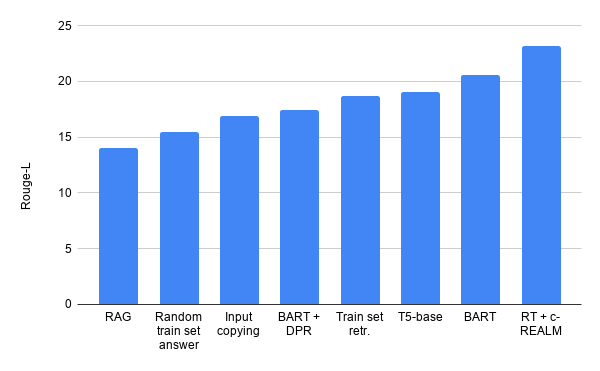
琐碎的基线得到比RAG和BART+DPR更高的Rouge-L分数。
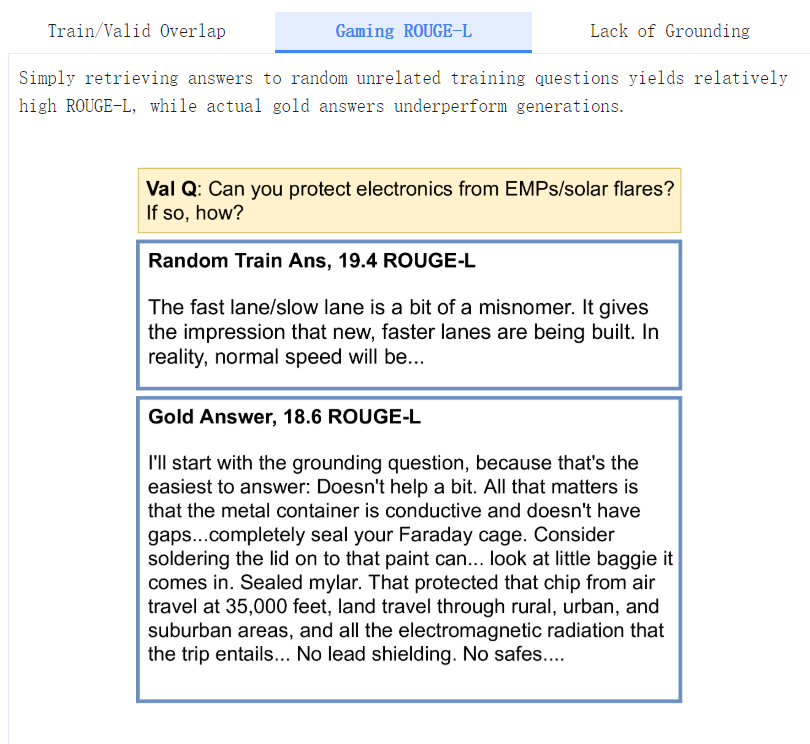
此外,我们还发现了用于评估文本生成质量的Rouge-L度量的问题,琐碎无意义的基线,如随机训练集答案和输入复制,都能获得相对较高的Rouge-L分数(甚至击败了BART+DPR和RAG)。
(周子喻编译,张梦婷校对)
深度观察
用稀疏注意方法构造长序列的Transformer
Constructing Transformers For Longer Sequences with Sparse Attention Methods
基于Transformer的NLP模型,如BERT、RoBERTa、T5或GPT3,在许多任务中都取得了成功,是现代自然语言处理研究的一个主要方向。Transformer的多功能性和健壮性是其广泛采用的主要驱动因素,使其能够轻松适应各种基于序列的任务—作为翻译、摘要、生成和其他方面的seq2seq模型,或作为情感分析、词性标注,机器阅读理解等的独立编码器。
Transformers的关键创新在于引入了一种自我注意机制,该机制计算输入序列中所有位置对的相似度得分,并可对输入序列的每个标记进行并行评估,避免了循环神经网络的序列依赖性,使Transformers大大优于LSTM等以前的序列模型。
然而,现有Transformer模型及其派生类的一个局限性是,完全自我注意机制的计算和记忆需求与输入序列长度成二次关系。由于当前的硬件和模型尺寸普遍可用,这通常将输入序列限制为大约512个tokens,并防止Transformers直接适用于需要更大上下文的任务,如问答、文档摘要或基因组片段分类。两个自然的问题出现了:1)我们能否使用稀疏模型来实现二次全Transformer的优势,而稀疏模型的计算和存储要求会随输入序列长度线性增长?2) 是否可以从理论上证明这些线性Transformer保持了二次全Transformer的表现力和灵活性?
我们在最近的一对论文中讨论了这两个问题。在EMNLP 2020上提出的ETC:Encoding Long and Structured Inputs in Transformers论文中,我们提出了Extended Transformer Construction(ETC),这是一种新颖的稀疏注意方法,其中使用结构信息来限制计算的相似性分数对的数量。这减少了对输入长度的二次依赖到线性,并在NLP领域产生了强有力的实证结果。然后,在NeurIPS 2020上的Big Bird:Transformers for Longer Sequences论文中,我们介绍了另一种称为BigBird的稀疏注意方法,该方法将ETC扩展到更一般的场景,在这些场景中,源数据中存在的关于结构的先决域知识可能不可用。此外,我们还证明了我们提出的稀疏注意机制在理论上保持了二次全Transformer的表现力和灵活性。我们提出的方法在具有挑战性的长序列任务上(包括QA和基因组片段分类等)达到了最新的技术水平
将注意力作为图
Transformer模型中使用的注意模块计算输入序列中所有位置对的相似度得分。把注意力机制看作一个有向图是很有用的,用节点来表示token,用边来表示一对标记之间的相似度。在这个视图中,完全注意力模型是一个完整的图。我们的方法背后的核心思想是仔细设计稀疏图,这样就可以只计算线性数量的相似度得分。
全注意可以看作是一个完整的图。
ETC
对于需要长时间和结构化输入的NLP任务,我们提出了一种结构化稀疏注意机制,称之为Extended Transformer Construction(ETC)。为了实现自我注意的结构化稀疏化,我们开发了全局-局部注意机制。在这里,对Transformer的输入分为两部分:一部分是全局输入,其中token具有不受限制的注意力;另一部分是长输入,其中token只能关注全局输入或局部邻域。这就实现了注意力的线性缩放,从而允许ETC显著地缩放输入长度。
为了进一步利用长文档的结构,ETC结合了额外的思想:以相对的方式表示标记的位置信息,而不是使用它们在序列中的绝对位置;除了在BERT等模型中使用的常规MLM之外,还使用了其它训练目标;以及token的灵活掩蔽,以控制哪些token可以加入其它token。例如,给定一个较长的文本选择,将全局token应用于每个句子,该句子连接到该句子中的所有token,全局token也应用于每个段落,它连接到同一段落中的所有token。
通过这种方法,我们报告了五个具有挑战性的NLP数据集的最新结果,这些数据集需要长期或结构化的输入:TriviaQA、NQ、HotpotQA、WikiHop和OpenKP。
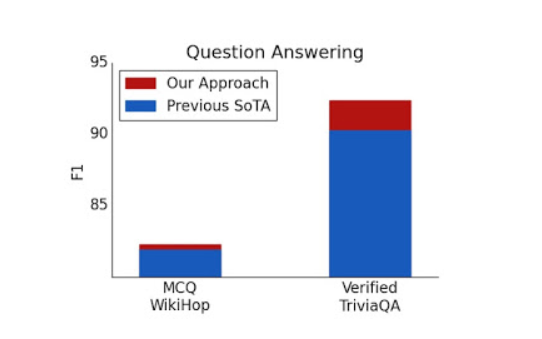
问答测试集结果。
BigBird
扩展了ETC的工作,我们提出了BigBird——一种稀疏的注意机制,它在token数量上也是线性的,并且是Transformer中使用的注意机制的一般替代品。与ETC相比,BigBird不需要任何关于源数据中存在的结构的必要知识。BigBird模型中的稀疏注意由三个主要部分组成:
- 处理输入序列的一组全局token
- 所有token都关注一组局部邻域token
- 所有token都关注一组随机token
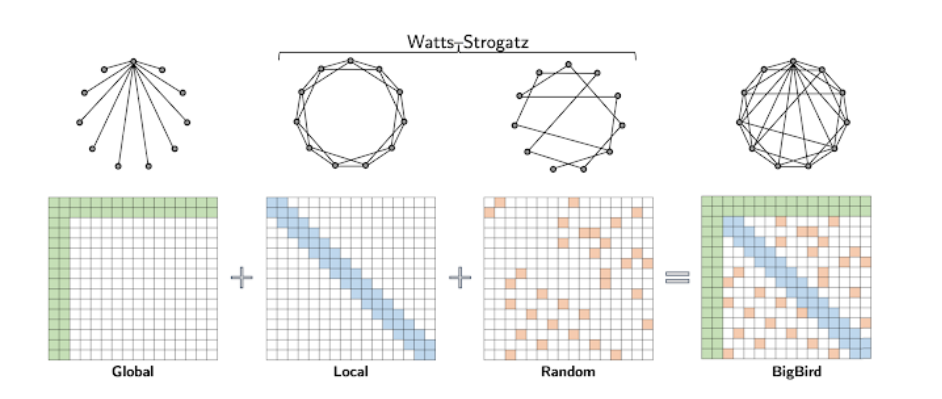
BigBird稀疏注意可以看作是在Watts-Strogatz图上添加了很少的全局token。
在BigBird的论文中,我们解释了为什么稀疏注意足以近似二次注意,部分解释了ETC成功的原因。一个关键的观察结果是,一个人计算的相似度分数与不同节点之间的信息流(即一个token相互影响的能力)之间存在内在的紧张关系。全局token充当信息流的管道,我们证明了具有全局token的稀疏注意机制可以和完全注意模型一样强大。特别地,我们证明了BigBird与原始Transformer一样具有表达能力,在计算上具有通用性(遵循Yun等人和Perez等人的工作),并且是连续函数的通用逼近器。
对于结构化和非结构化任务,这种设计可以扩展到更长的序列长度。通过使用梯度检查点,可以通过权衡训练时间以获得序列长度来实现进一步的缩放。这使我们能够扩展高效的稀疏Transformer,以包含需要编码器和解码器的生成任务,例如长文档摘要,在这方面我们实现了SOTA。
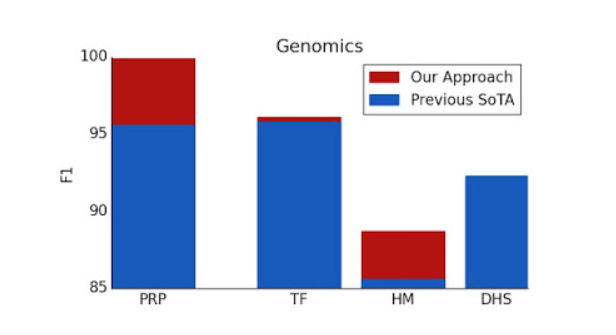
在多个基因组学任务上,例如启动子区域预测(PRP),染色质分布预测(包括转录因子(TF),组蛋白标记(HM)和DNase I超敏性(DHS)检测),我们的表现优于基线。 此外,我们的结果表明,可以将Transformer模型应用于目前尚未充分开发的多个基因组学任务。
主要实施思路
大规模采用稀疏注意的主要障碍之一是,在现代硬件中,稀疏操作的效率非常低。在ETC和BigBird背后,我们的一个关键创新是有效地实现稀疏注意机制。由于诸如GPU和TPU之类的现代硬件加速器使用合并内存操作,一次加载连续字节块,因此由滑动窗口(用于局部注意)或随机元素查询(随机注意)引起的小的零星查找是没有效率的。相反,我们将稀疏的局部和随机注意力转化为密集的张量运算,以充分利用现代单指令多数据(SIMD)硬件。
要做到这一点,我们首先“封锁”的注意机制,以更好地利用GPU/TPU,这是专为操作块。然后,我们通过一系列简单的矩阵操作(如重塑、滚动和聚集)将稀疏注意机制计算转化为密集张量积。
最近,Long Range Arena:A Benchmark for Efficient Transformer提供了六个需要更长背景的任务的基准,并进行了测试所有现有远程Transformer的实验。结果表明,BigBird模型与同类模型不同,它在不牺牲性能的情况下明显减少了内存消耗。
结论
我们证明了精心设计的稀疏注意可以像原始的完全注意模型一样具有表达能力和灵活性。除了理论上的保证,我们提供了一个非常有效的实现,它允许我们扩展到更长的输入。因此,我们在QA,自动文摘和基因组片段分类方面取得了最新的成果。鉴于我们注意力稀疏的一般性质,该方法应该适用于许多其他任务,如程序综合和长形式的开放域QA。我们已经为ETC和BigBird开源了代码,这两种代码在GPU和TPU上都能有效地运行长序列。
(张梦婷编译,周子喻校对)
研究动态
注意力并不是你所需要的全部:Google&EPFL的研究揭示了自我注意力结构中巨大的偏差
2017年的论文Attention is All You Need介绍了基于注意力机制的Transformer架构,标志着有史以来最大的机器学习(ML)突破之一。最近的一项研究提出了一种新的方法来研究自我注意,它的偏差和秩消失的问题。

基于注意的体系结构在NLP、语音识别以及最近的计算机视觉领域都被证明是有效的。然而,旨在了解Transformer内部工作原理和注意力的研究一直是有限的。
在论文Attention is Not All You Need:Pure Attention Loses Rank Doubly Exponentially with Depth中,来自Google和EPFL的一个研究小组提出了一种新的方法,揭示了自我注意网络(SANs)的操作和偏差,并发现纯粹的注意随着深度呈双倍指数衰减。
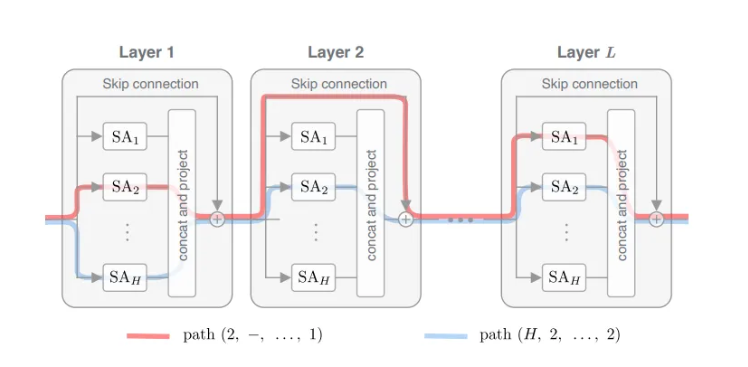
研究人员将他们的工作总结如下:
- 对Transformer的组成部分进行了系统的研究,揭示了自我注意和反作用力之间的对立影响:跳过连接和MLP,有助于防止Transformer的秩消失。
- 提出了一种通过路径分解分析SAN的新方法,揭示了SAN是浅层网络的集合。
- 通过对常用Transformer结构的实验验证了理论的正确性。
该团队首先研究了SAN的结构,其中包括跳转连接和禁用的多层感知器(MLP)。他们认为SAN是一个有向无环图,每个节点对应一个自关注头,有向边连接连续层的头。在此基础上,他们构建了一个路径分解,将多头SAN的行为描述为简单的单头网络的组合。通过路径相互作用,他们观察到偏差并不是特别有意义;而且每条路径都迅速收敛到一个具有相同行的秩1矩阵。有趣的是,当路径按指数增加时:每条路径然后按双指数退化,得到秩1的输出。
研究人员分别考虑了每一条路径的行为,研究了在向前传播过程中残余物是如何变化的。他们发现残差范数收敛到零的速度惊人地快(以三次方速率成倍指数)。由于注意矩阵的秩也取决于输入的秩,因此确定的立方收敛速度明显快于预期的速度。换句话说,更深层次的SAN将导致级联效应。
为了对SAN的结构有更深入地了解,团队通过合并SAN缺少的三个关键Transformer组件来扩展他们的分析:跳过连接、MLP和层规范化。这项检查显示,启用跳过连接的SAN严重依赖于短路径,表现为浅层单头自我注意网络的集合。研究小组还发现,MLP会抵消收敛,例如,当MLP变得更强大时,收敛会变得更慢;而层规范化并不能缓解秩消失。
研究小组进行了以下实验:
- 真实架构中的秩消失,检查流行的Transformer架构BERT、Albert和XLNet。
- 可视化不同结构的偏差,研究单层Transformer在重复应用时的行为,以预测简单的二维循环序列。
- 通过序列记忆、学习分类和凸包预测三个任务测试路径有效性。
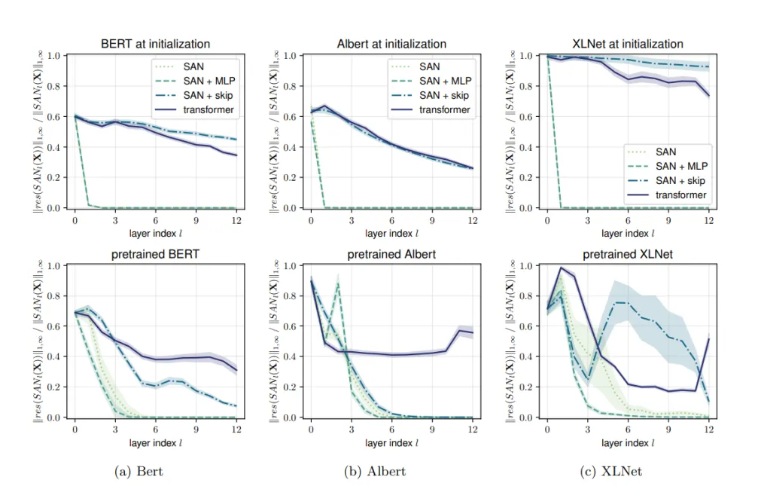
实验1的结果。三种模型训练前后沿深度残差的相对范数。纯注意(SAN)快速收敛到秩1矩阵。添加MLP块和跳过连接将生成一个Transformer。跳过连接在减轻秩消失(即零残差)方面起着关键作用。
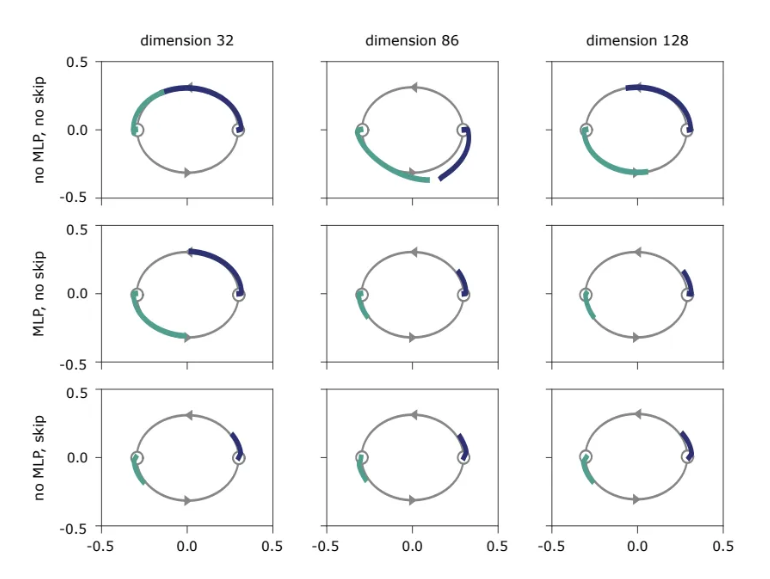
实验2的结果。将经过训练的单层Transformer模块反复应用于增加隐藏维度(水平方向)和跨架构变体(垂直方向)的模型。两条光背景路径说明了两条训练轨迹,其起点为(−0.3,0)和(0.3,0)。
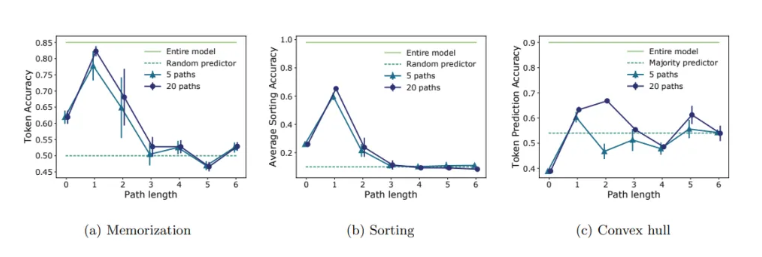
实验3的结果。将测试集每一个token的预测准确率作为评价指标。为了确定有多少表达能力可以归因于短路径和长路径,研究人员检查了不同长度路径子集(而不是整个SAN)的性能。
第一个实验证实,当跳过连接被移除时,所有网络都表现出快速的秩消失;第二个实验表明,添加MLP或skip连接可以停止或显著减缓秩消失。最后一个实验支持了研究人员的假设,即短路径是影响SAN表达能力的主要原因。
(张梦婷编译,周子喻校对)
CMU、Oxford和Facebook的跨语言视觉语言模型在Zero-Shot背景下实现了新的SOTA
CMU, Oxford & Facebook Cross-Lingual Vision-Language Model Achieves New SOTA in Zero-Shot Setting
建立不仅适用于单一语言,而且可以推广到全世界大约7000种语言的多功能视觉语言模型是困难的——如果模型在没有任何附加注释的训练数据的情况下进行传输,任务就变得更具挑战性。
为了解决这个问题,来自CMU、Oxford和Facebook人工智能的一个研究小组提出了一个基于Transformer的模型,即多语言多模态预训练(MMP),它可以在zero-shot背景下学习语境化的多语言多模态嵌入。

最近的跨语言迁移学习研究表明,仅使用英语注释的模式可以推广到非英语语言。这一成功归功于许多语言之间共同的基本词汇或结构。例如,许多英语和德语单词来自同一个来源,许多语言具有相同的递归结构。
研究人员指出,所有人类都有相似的视觉系统,因此许多共同的视觉概念可以被普遍理解。这使得利用语言和视觉特性将不同语言的句子与视觉概念相关联,从而在zero-shot(无标签)背景下实现视觉语言模型的跨语言传输。
团队总结了他们的主要贡献:
- 提出了一种基于Transformer的视频文本模型,该模型学习上下文化的多语言多模态表示。
- 实证研究表明,视觉语言模型不同于NLP模型,具有有限的zero-shot跨语言迁移能力。
- 提出了一种多语种多模态预训练策略,并构建了一个新的Multi-HowTo100M数据集进行预训练,以提高视觉语言模型的zero-shot跨语言能力。
- 通过在zero-shot和完全监督背景下实现最先进的多语种文本到视频搜索性能,证明了该方法的有效性。
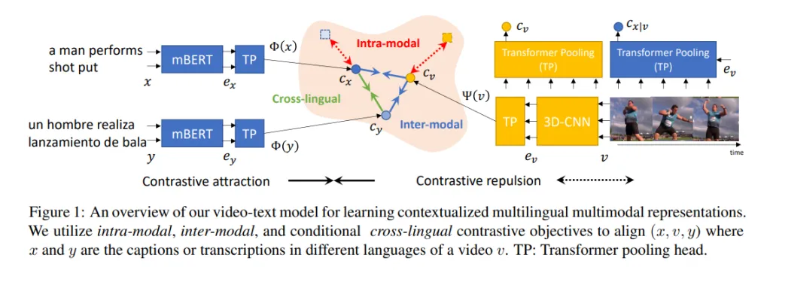
所提出的MMP的文本编码器由一个多语言Transformer和一个文本Transformer池化头组成,而视频编码器由一个3D-CNN和一个视频Transformer池化头组成。多语言Transformer生成上下文化的多语言表示来编码句子x;Transformer池化头用作池化函数来选择性地编码可变长度的句子并将其与相应的视觉内容对齐;3D-CNNs编码视频中的时空上下文;以及视频Transformer池化头将不同长度的视频编码为固定长度的表示。
在下一步中,研究人员需要通过最小化对比目标,将编码文本和视频对齐,以形成多模态表示,从而将相关(视频、文本)嵌入映射到共享嵌入空间中彼此接近的位置。受翻译语言模型(TLM)的启发,他们提出了类似TLM的对比目标来提高对齐质量。
团队还构建了一个多语种多模式学习的Multi-HowTo100M数据集,以利用大规模多语种文本视频数据的弱监督。这个名为Multi-HowTo100M的数据集包含110万个视频,每个视频都有7到9种语言的字幕。
为了验证他们提出的多语种文本视频方法的有效性,研究人员进行了实验,使用mBERT作为模型,XLMRoberta large(XLM-R)作为文本主干,以及多语种多模式预训练(MMP)的Multi-HowTo100M。他们在VTT、VATEX和Multi30K数据集上对提出的模型进行了微调,以便在文本到视频搜索任务中对其进行评估。在zero-shot跨语言迁移实验中,他们只使用英语视频数据,并用非英语查询测试模型。

对于XLM-R,当使用更多多语言的文本-视频对进行预训练时,R@1会逐渐收敛。对于zero-shot德语到视频搜索,使用更多语言进行预训练可以提高搜索性能。
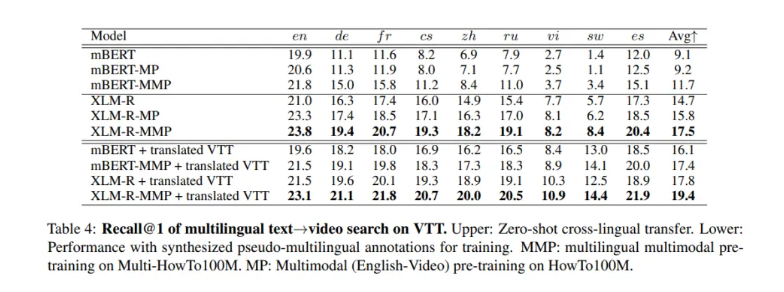
借助域内翻译的伪多语言注释,mBERT和XLM-R在非英语语言中表现出更好的性能。值得注意的是,mBERT的zero-shot和平移序列设置之间仍然存在性能差距,但XLM-R的差距要小得多。
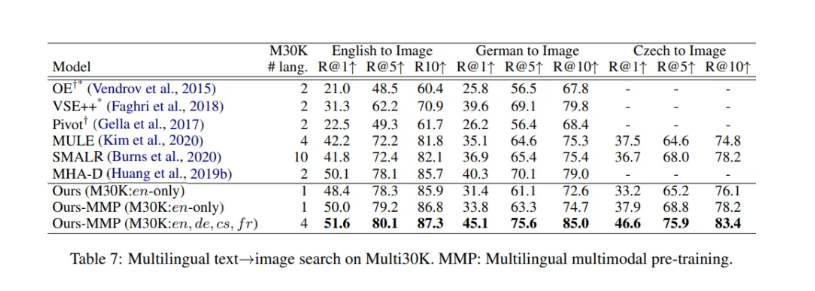
所提出的MMP改进了所有的召回指标,即使在模态缺口的情况下,其平均R@1级改进达到了3.2。此外,在不使用任何捷克语注释的情况下,带有MMP的zero-shot模型实现了与SMALR(Scalable Multilingual Aligned language Representation)相当的捷克图像搜索性能,SMALR使用10种语言作为注释。
结果表明,MMP对视觉语言模型的zero-shot跨语言迁移是有效的。
(张梦婷编译,周子喻校对)
GPT也能理解了!清华和麻省理工的P-Tuning提升了NLU基准的性能
GPT Understands, Too! Tsinghua & MIT’s P-Tuning Boosts Performance on NLU Benchmarks
GPT-3大型语言模型在生成类似人类的文本段落方面表现出了前所未有的能力,从创建历史人物之间的想象对话到总结电影和编写代码。然而,尽管它的输出在语法上是正确的,甚至在习惯用语上令人印象深刻,但GPT-3对世界的理解力往往严重不足。

来自清华与麻省理工学院的一个研究团队消除了GPT模型可以生成但不能理解语言的刻板印象,通过采用提出的P-tuning方法,证明GPT可以在NLU任务上与谷歌的BERT模型竞争。该团队表示,P-tuning还可以提高BERT在few-shot和监督环境下的性能。
GPT-3大型语言模型在生成类似人类的文本段落方面表现出了前所未有的能力,从创建历史人物之间的想象对话到总结电影和编写代码。然而,尽管它的输出在语法上是正确的,甚至在习惯用语上令人印象深刻,但GPT-3对世界的理解力往往严重不足。
研究人员将他们的贡献总结如下:
- 表明GPT在NLU中可以和BERT一样具有竞争力(有时甚至更好),通过P-tuning,可以提升预训练语言模型的性能。这揭示了GPT式架构在NLU中的潜力被低估了。
- 表明P-tuning是一种通用的方法,可以在few-shot和完全监督的环境下改善GPT和BERT。所提出的方法在LAMA知识探究和few-shot SuperGLUE上的表现优于最先进的方法,表明语言模型在预训练过程中掌握的世界知识和先前任务知识比之前人们以为的多。
像GPT-3这样的巨型模型往往存在可转移性差的问题,这意味着针对下游任务对这些万亿规模的模型进行微调是无效的。相反,GPT-3利用手工制作的提示来使模型适合下游应用。然而这种手工制作的提示搜索严重依赖于不切实际的大型验证集,提示的一个工作变化就会导致性能的急剧中断。

P-tuning方法解决了这些问题。它能在连续空间中自动搜索提示,弥补了GPT与下游NLBU任务之间的差距,给NLBU性能带来大幅提升。
P-tuning架构本身比较简单。给定一个预训练的语言模型,由预训练的嵌入层将离散的输入标记序列映射到输入嵌入中。提示符p的功能是将上下文x、目标y和自身组织到一个模板t上,通过这种方式,该方法可以找到更好的连续提示符,最后通过下行损失函数优化连续提示符。
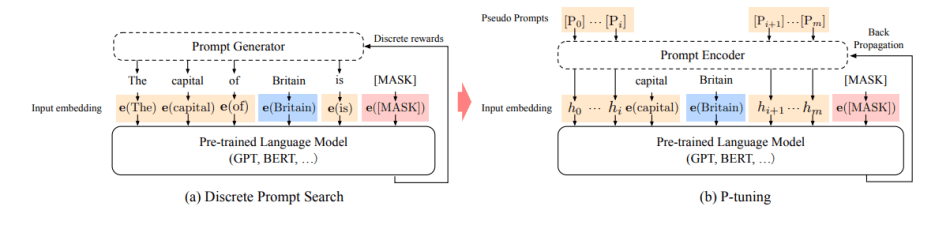
该团队在流行的LAMA知识探究和SuperGLUE NLU基准上进行了大量实验,以评估P-tuning性能。
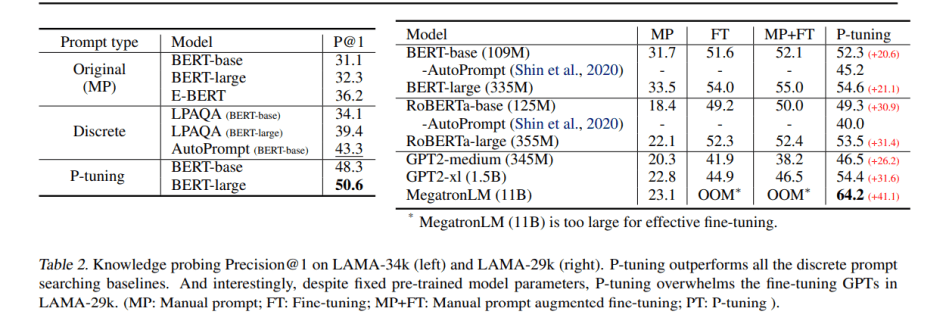
LAMA知识探究用于评估语言模型从预训练中获得了多少知识。结果显示,P-tuning显著提升了知识探究性能,在LAMA-34k上从43.3%提升到50.6%,在LAMA-29k上从45.2%提升到64.2%,这表明仅仅找到一个更好的提示,而不对语言模型进行微调,就能比研究人员之前认为的更多的知识。P-tuning的表现也优于之前的离散提示搜索方法,如AutoPrompt和LPAQA。
在SuperGLUE实验中,团队在NLU任务上考虑了完全监督设置和few-shot设置,这些任务包括问题回答(BoolQ和MultiRC)、文本牵连(CB和RTE)、共同参考解析(WiC)、因果推理(COPA)和词义歧义(WSC)。
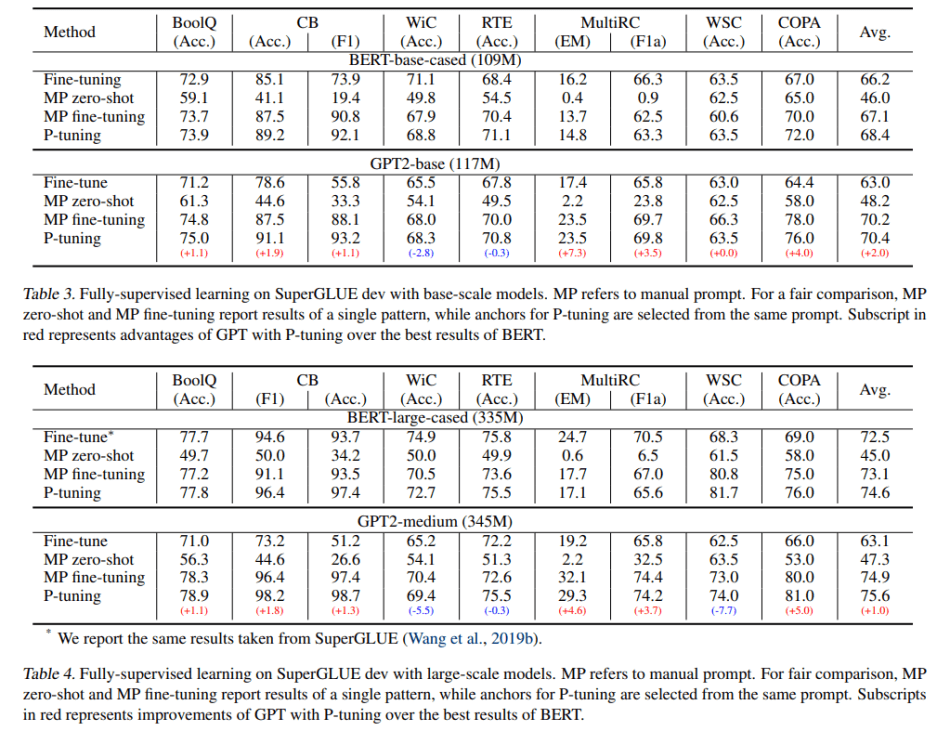
在完全监督的环境下,对于BERT-base-case和BERT-large-case模型,P-tuning方法几乎在所有任务上都优于所有其他基于BERT的模型。P-tuning在GPT-2-base和GPT-2-medium模型上也取得了可喜的成绩。
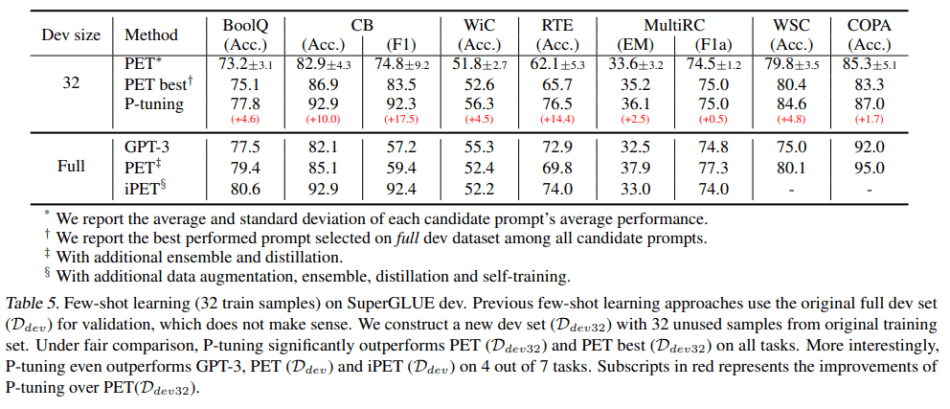
在few-shot学习设置下,P-tuning在所有任务上的表现始终优于PET(Ddev32)和PET-best(Ddev32)与人工提示;与GPT-3相比,P-tuning在7个任务中的6个任务上的表现有所提高,证明P-tuning可以搜索到远比人工方法更好的提示,并显著提高few-shot任务的表现。
总的来说,该研究证明了P-tuning在促使难以微调的较大规模预训练模型方面的竞争潜力。
(周子喻编译,赵海喻校对)
中国的GPT-3?BAAI推出超大规模智能模型“悟道1.0”
China’s GPT-3? BAAI Introduces Superscale Intelligence Model ‘Wu Dao 1.0’
自2020年5月发布OpenAI的GPT-3以来,AI研究人员已经接受了超大规模的预训练模型。包含了划时代的1750亿个参数的GPT-3在多个自然语言处理(NLP)任务中取得了优异的表现。然而,尽管规模庞大,功能强大,但这类模型仍然缺乏常识或认知能力,因此在处理复杂的推理任务时,如开放式对话、基于知识的问答、视觉推理等,都显得十分吃力。
为推动中国自主大规模预训练模型的研发,从更基础的角度进一步探索普适性智能,北京人工智能研究院近日发布了中国首个国产超大规模智能模型系统——悟道1.0。
该工作由北航研究学术副院长、清华大学教授唐杰领衔,来自北京大学、清华大学、中国人民大学、中科院等机构的百余名人工智能科学家组成的团队做出了贡献。
悟道1.0通过四种相关模式启动了大型科研项目。悟道-文源、悟道-文澜、悟道-文汇、悟道-文溯。
悟道-文源是中国有史以来最大的预训练语言模型,拥有包括中文和英文在内的主流语言的最佳处理能力,在文本分类、情感分析、自然语言推理、阅读理解等方面超越了人类平均性能基准。它在文本分类、情感分析、自然语言推理、阅读理解等方面都超越了人类平均性能基准。悟道-文源项目旨在探索通用NLU技术,研究大脑启发的语言模型。它拥有26亿个参数,能够进行记忆、理解、检索、数值计算、多语言等认知活动。悟道-文源在开域应答、语法纠正、情感分析等20个中文NLP任务上取得了GPT-3的可比性能。
同时,悟道-文澜是首个公开的中文通用图形多模态预训练模型。该超大规模多模态预训练模型旨在突破基于图形、文本和视频组合的多模态数据预训练的理论难题,最终生成超越SOTA性能的工业级中文图形预训练模型和应用。目前,该模型拥有10亿个参数,并对5000万个从公开源收集的图形对进行训练。悟道-文澜模型已达到SOTA性能,在中国公共多模态测试集AIC-ICC的图像标题任务中,比冠军团队的得分高出5%,在Visual Entailment任务中,比最受欢迎的UNITER模型高出20%。
悟道-文汇是一个面向认知的超大规模预训练模型,从认知角度出发,聚焦于一般人工智能的一系列本质问题,旨在发展和提升预训练模型基于逻辑、意识和推理的认知能力。悟道-文汇的参数已经达到113亿个,通过简单的微调就可以生成诗歌、制作视频、画图、检索文字、进行复杂推理等。BAAI表示,在图灵测试中,该模型在诗歌生成上实现了接近人类的性能。
悟道-文溯是一个大规模的生物分子结构预测训练模型。它可以处理超长的生物分子结构,其中它已经实现了SOTA性能、可解释性和鲁棒性。基于Google的BERT语言模型,"悟道-文溯"已经完成了100GB UNIPARC数据库的蛋白质训练,以及5-10万个人类外周血免疫细胞(25-30种细胞)和1万个耐药菌的基因训练。
BAAI研究团队总结了悟道1.0的一些主要贡献:
- 悟道-文源介绍了开源的中文预训练模型(CPM)。基于CPM,CPM-Distill模型可以减少38%的语言混淆,并在下游任务中取得更好的效果。
- 悟道-文澜是中国第一个通用的多模态预训练模型,可以基于图像和文字的弱关联性理解"内涵信息"。文澜采用先进的跨模态对比学习算法。给定一个图像-文本对,它可以放大每个模态的负样本数量,尤其是对于那些难以区分的模态,进一步提高神经网络的表达能力。它可以用最先进的单模态预训练模型轻松替代图像和文本编码器,实现比UNITER模型快20倍的性能。
- 悟道-文汇提出了一种新的预训练范式--生成式语言模型(GLM),突破了BERT和GPT的瓶颈。历史上第一次用单一模型在语言理解和生成任务中取得了最好的效果,并超越了BERT、RoBERTa和T5等在相同数据量下训练的常见预训练模型。文汇基于连续向量的微调方法P-tuning是第一个在NLU任务中超越AutoEncoder模型的自回归模型,在知识提取、Superglue Fewshot学习等10多个任务上取得了SOTA效果,性能提升超过20%。文汇的逆向提示算法在问答和诗词生成的任务上实现了接近人类的性能,是第一个可以生成基于现代题材的中国古典诗词的模型。
- 开源的悟道-文溯FastMoE是第一个支持PyTorch框架和多种硬件的高性能MoE(混合专家模型)系统。与传统的PyTorch实现相比,只需要一行代码就可以完成MoE的转换,模型训练速度提高了47倍。
BAAI Research目前正在与搜狗、360、阿里巴巴、新华社等讨论模型应用。团队还计划建立API接口,支持企业和个人用户的高并发和高速推理。
(赵海喻编译,张梦婷校对)
项目工具
利用Neo4j图实现POS标签的隐藏马尔科夫模型
Implementing Hidden Markov Model for POS Tagging using Neo4j graph
POS标签的不同做法
简单来说,POS Tagging其实就是将一个词与它的Part of Speech进行标记。

现在有各种方法来做这个标签,下面介绍其中的几种方法。
基于词典的方法使用了以下简单的统计算法:对于每个词,它为该词分配一些训练语料库中出现频率最高的POS标签。这样的标签方法无法处理未知/模糊的单词。例如
I went for a run/NN
I run/VB in the morning
词典标签器会根据最高频率的标签来标记'run'。在大多数情况下,'run'很可能作为动词出现,这意味着'run'会在第一句话中被错误地标记。
但是,如果有一个规则应用于整个文本,例如,"如果之前的标签是DT,则用NN替换VB",或者"将所有以ing结尾的单词标记为VBG",则可以修正标签。基于规则的标签方法就采用了这样的方法。
概率标记器不会给每个词分配最高频率的标记,相反,他们会观察序列中稍长的部分,并经常使用标记和出现在目标词之前的词进行标记。
词典和基于规则的标签可以达到目的,但在扩展性和准确性方面还不够。我们的重点是使用HMM算法的概率标记器。
隐马尔科夫模型算法
马尔科夫模型是一种概率(或随机)模型,是为了模拟连续过程而开发的。在马尔科夫过程中,通常假设每个事件(或状态)的概率只取决于前一个事件的概率。这种简化假设是一种特殊情况,它被称为一阶马尔科夫假设。
马尔科夫链用来表示一个从一个状态到另一个状态的过渡过程。这个过渡做了一个假设,即过渡到下一个状态的概率完全取决于当前状态。
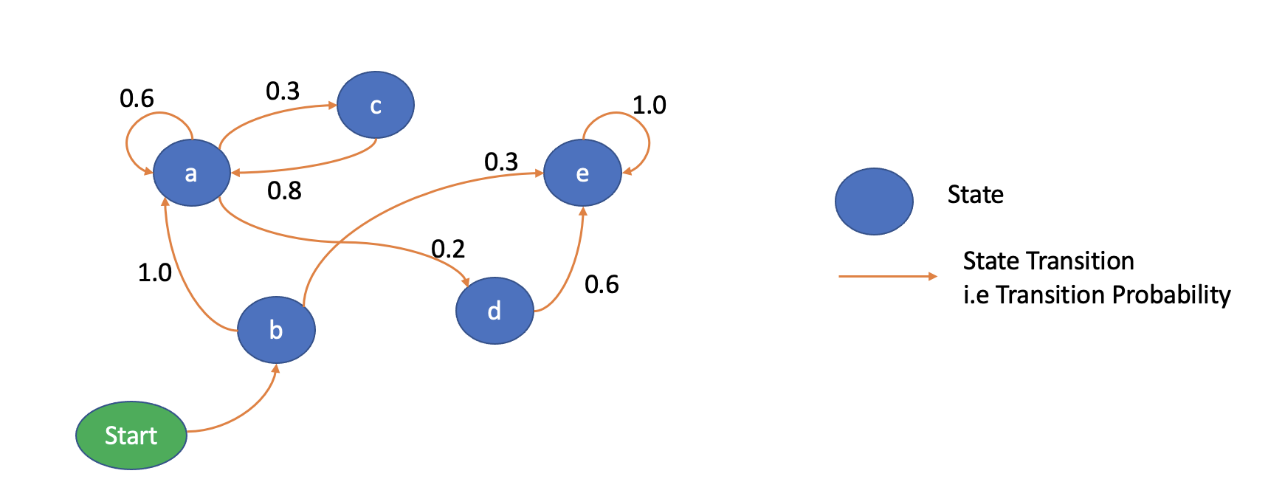
这里,'a','b','c','d','e',是状态,边上提到的数字是过渡概率。例如,从状态'a'过渡到状态'c'、'a'、'd'的概率分别为0.3、0.2。开始状态是一种特殊的状态,它代表了过程的初始状态。
马尔科夫过程通常用于模拟顺序数据,如文本和语音。例如,假设你想建立一个预测句子中下一个单词的应用程序。你可以将句子中的每个单词表示为一个状态。过渡概率将代表这个过程从当前单词到下一个单词的概率。例如,从状态"San"到"Franciso"的过渡概率会比到状态"Delhi"的概率高。
隐马尔科夫模型(HMM)是马尔科夫过程的一种扩展,它用于模拟状态是隐藏的(或潜伏的),它们发出观察结果的现象。例如,在语音识别系统(语音到文本的转换器)中,状态代表了你想要预测的实际文本词,但你并不直接观察它们(即状态是隐藏的)。相反,你只观察到每个词对应的语音(音频)信号,你需要利用观察结果推断出状态。
同样,在POS标签中,你观察到的是句子中的单词,而POS标签本身是隐藏的。因此,你可以将POS标签任务建模为一个HMM,隐藏状态代表POS标签,它发出的是观察结果——单词。
隐藏状态以一定的概率发出观测值。因此,除了过渡态和初始态概率,隐藏马尔科夫模型还有发射概率,它代表了某一观测值被某一状态发射的概率。下图说明了一个具有三个隐藏状态和三个观测值的隐藏马尔科夫过程的发射和转换概率。
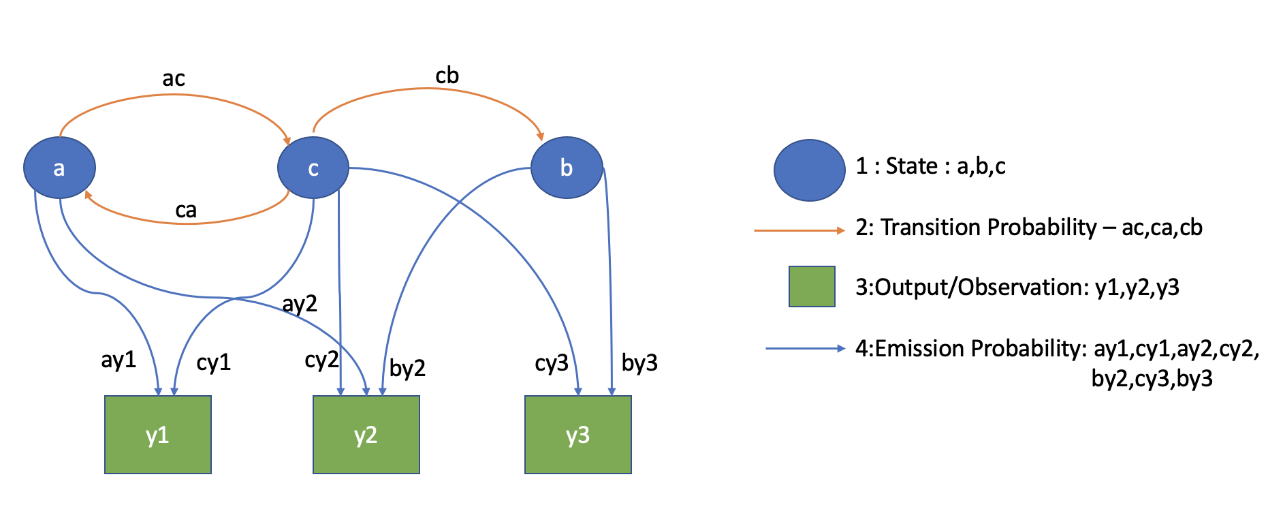
现在在我们下面的例子中,The,high,cost将是观察词,DT,JJ,NN将是过渡和观察概率的单词。
现在我们已经差不多理解了HMM,我们将使用HMM建模和Viterbi算法来解决解释问题,即"给定一个词/观测序列和一个HMM模型(即过渡、发射和开始状态的可能性),找到能使观测词的概率最大化的标签/状态序列。
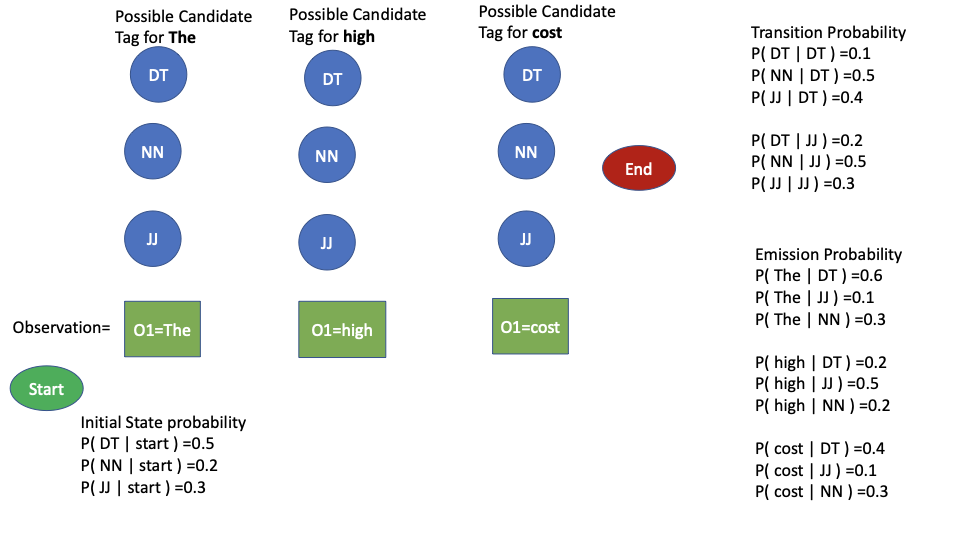
我们使用短语来标记'高成本',并假设我们只有三种可能的标记——DT、JJ、NN。我们还假设了一些发射(P('the'|DT)、P('the'|NN)、P('high'|JJ)等)和转换概率(P(NN|JJ)、P(JJ|DT)、P(DT|JJ)等)。给定一个由初始状态、发射和转换概率定义的隐藏马尔可夫模型,我们给观测值Oi分配一个标签Tj,使它的似然最大化。
HMM的图形建模



(周子喻编译,赵海喻校对)
近期论文
All NLP Tasks Are Generation Tasks: A General Pretraining Framework
摘要
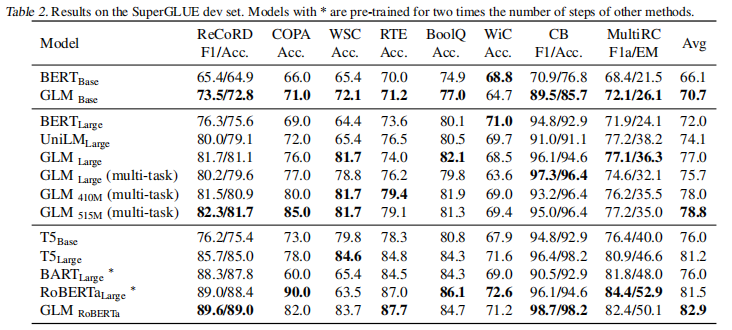
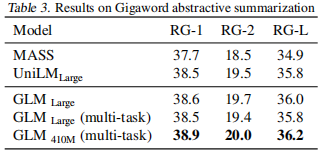
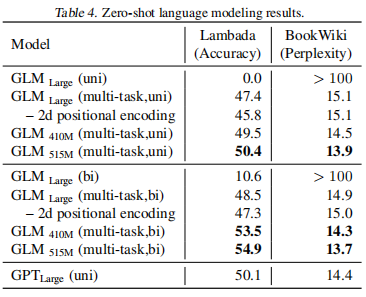
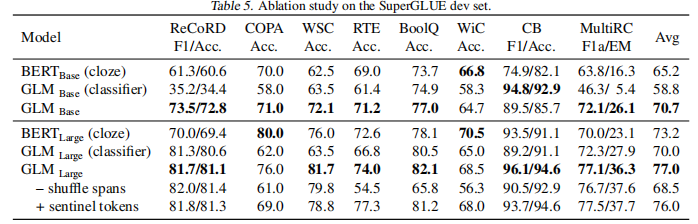
已经有各种类型的预训练架构,包括自回归模型(如GPT)、自动编码模型(如BERT)、编码器-解码器模型(如T5)。另一方面,NLP任务的性质不同,主要有分类、无条件生成和有条件生成三类。然而,没有一个预训练框架对所有任务的表现都是最好的,这给模型的开发和选择带来了不便。我们提出了一种新型的预训练框架GLM(General Language Model)来解决这一难题。与之前的工作相比,我们的架构有三大优势。(1)它在分类、无条件生成和条件生成任务上都有很好的表现,只需一个单一的预训练模型;(2)由于改进了预训练与微调的一致性,它在分类上的表现优于BERT类模型;(3)它能自然地处理可变长度的空白填充,这对许多下游任务来说至关重要。经验上,在相同数量的预训练数据下,GLM在SuperGLUE自然语言理解基准上的表现大幅优于BERT。此外,在BERTLarge的1.25倍参数下,GLM在自然语言理解、有条件和无条件生成方面同时达到了最好的性能,这证明了其对不同下游任务的可推广性。
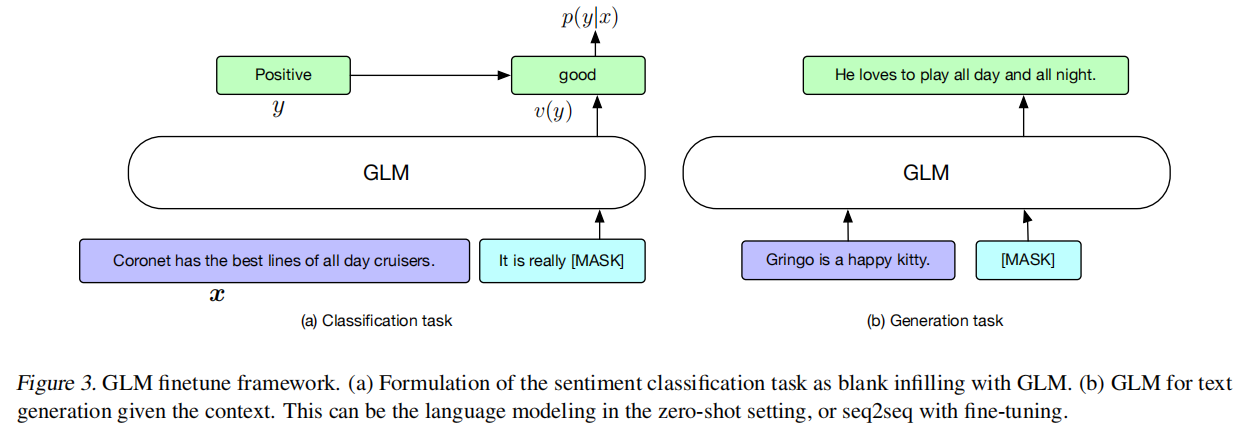
GLM-预训练模型架构
GLM使用类似BERT的Transformer结构,但做出了两个修正: (1)重新安排了层归一化和残差连接的顺序,这在扩展到大型BERT类型的模型时已被证明是至关重要的。(2)用线性层代替前馈网络进行token预测。
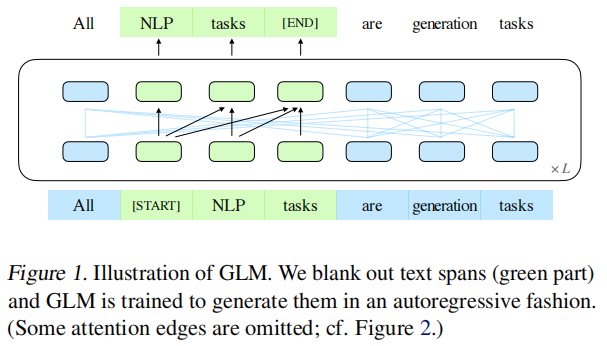
GLM是通过优化自回归空白填充任务来训练的。
位置编码方案: 每个token都用两个位置id进行编码。第一个位置id代表损坏文本x_corrupt中的位置。对于B中的token牌,它是对应的[MASK]的位置。第二个位置id代表跨度内的位置。对于A中的token,第二个位置id是0,对于B中的标记,它的范围是1到跨度的长度。两个位置id通过两个独立的嵌入表投射成两个位置向量,并添加到输入嵌入中。

(赵海喻编译)
Attention is not all you need: pure attention loses rank doubly exponentially with depth
摘要
基于注意力的架构在机器学习中已经变得无处不在。然而我们对其有效性的原因的理解仍然有限。这项工作提出了一种理解自注意力网络的新方法:我们表明,它们的输出可以被分解成一个个更小的项的总和,每个项都涉及跨层的注意力头序列的操作。利用这种分解,我们证明了自注意力具有强烈的 "token uniformity"的归纳偏置。具体来说,在没有skip connection或多层感知器(MLP)的情况下,输出会双倍指数地收敛到秩1矩阵。另一方面,skip connection和MLP阻止了输出的退化。我们的实验在标准Transformer架构的不同变体上验证了所确定的收敛现象。
主要贡献
- 系统研究了 Transformer 的构造块,揭示自注意力与其反作用力(跳过连接和 MLP)之间的对抗影响。这揭示了跳过连接在促进优化之外的重要作用。
- 提出一种通过路径分解来分析 SAN 的新方法,发现 SAN 是多个浅层网络的集成。
- 在多个常见 Transformer 架构上进行实验,从而验证其理论。
基于注意力的架构在机器学习领域已经非常普遍,但人们对其有效性原因的理解仍然有限。本文提出了一种理解自注意力网络的新方式:将网络输出分解为一组较小的项,每个项包括一系列注意力头的跨层操作。基于该分解,本文证明自注意力具备强大的token uniformity归纳偏置。也就是说,如果没有skip connection或MLP,其输出将双指数级收敛至秩 1 矩阵。另外,skip connection和 MLP 还可以阻止输出的衰退。该研究在不同 Transformer 变体上的实验证实了这一收敛现象。
本文利用随机矩阵的特性部分地推导出收敛界限,但其结果超出了想象。利用特殊堆叠自注意力模块的级联效应,发现这类网络的收敛速度比标准理论所描述的快指数级。该结果首次说明了整个网络收敛至秩 1 矩阵的条件。本文分析了三个重要组件:跳过连接、MLP 和层归一化,结果表明,跳过连接能够有效地缓解秩崩溃(rank collapse),MLP 则通过增加利普希茨常数来降低收敛速度。
(周子喻编译)
近期会议
AI Champions Online - Supply Chain
Mar 23 - Mar 25, 2021 线上
在线讨论业务、数据和人工智能、AI 冠军之间的重要联系,将无法在其他地方找到的内容直接带到您的家庭、通勤或办公室、桌面、手机或平板电脑上。致力于发现新的技术,见解和趋势,塑造美国领先的在线数据与模型分析活动。
EmTech Digital - 2021
Mar 23 - Mar 25 线上
麻省理工学院技术评论人工智能年度活动,今年内容包括:目前成功完成的重要挑战;优秀研究人员和工程师关于人工智能硬件和算法进一步发展的讨论;我们生活中的人工智能,包括如何解决不平等问题,以及确定未来利用人工智能的策略。
Big Data and Analytics Summit Canada
Mar 24 - Mar 25, 2021 线上
加拿大大数据与分析峰会旨在为数据主管提供技术、数据、人工智能、机器学习、风险管理和留住人才的当前趋势、战略见解和最佳实践趋势。今年的演讲者包括万事达卡、谷歌、Facebook、优步、LG、哈利伯顿、泰卢斯、阳光人寿、优步、肯德基等。利用这个机会,在这个互动环境中与同行建立联系,获得竞争优势。
Re•Work AI in Healthcare Summit - 20% Discount Code: UNITEAI
Mar 23 - Mar 25, 2021 线上
了解旨在彻底改变医疗保健、医学和诊断的人工智能方法和工具,以及在相关行业应用和关键见解。汇集了最新的技术进步以及应用人工智能解决商业和社会挑战的实际例子。通过独一无二的学术和行业组合能够与处于研究前沿的人工智能先驱们会面,并探索现实世界的案例研究,以发现人工智能的商业价值。
(赵海喻)