文本挖掘与机器学习跟踪扫描动态快报(2020.07)
实时跟踪、关注文本挖掘与机器学习领域最新研究动态
深度观察
测试NLP中迁移学习的限制
通过预训练模型来开发通用的能力和知识,然后将其“转移”到下游的任务中,这种做法已经变得越来越普遍。在迁移学习于计算机视觉的应用中,通常通过对ImageNet这样的大型标记数据集进行监督学习来预训练。与之相反,用于NLP中的迁移学习通常在未标记的数据上使用无监督学习进行预训练。
尽管ML广泛流行,但仍然有几个紧迫的问题困扰着迁移学习:
该模型遗忘了多少原始任务?
为什么大型模型的变化不如小型模型大?
我们可以从预先训练的权重数据中获得更多输出吗?
结果是否与其他任务(例如分割)相似?
快速的进步和技术的多样性可能使比较不同算法和理解现有的迁移学习变得困难。Google的研究人员说,需要一种统一的方法来理解迁移学习的有效性。
为了制定一种独特的、统一的方法,研究人员将每个NLP问题都视为“文本到文本”问题,即以文本为输入,并产生新文本为输出。
文本到文本框架提供了灵活性,可以帮助评估各种基于英文文本的NLP问题表现的性能,包括问题解答、文档摘要和情感分类等。
使用这种统一的方法,我们可以比较不同的迁移学习目标,未标记的数据集和其他因素的有效性,同时通过扩大模型和数据集的范围以超越先前考虑的范围,探索NLP迁移学习的局限性。
测试迁移学习的有效性

在迁移学习中,对神经网络进行了两个阶段的训练:
预训练:通常在大规模基准数据集上训练网络。
微调:将预训练网络依据感兴趣的任务对特定目标进行进一步训练,与预先训练的数据集相比,可能没有标记的示例。
对于本研究,考虑到其广泛的适用性和采用性,完成的所有实验均基于Transformer架构。设计基准模型时,编码器和解码器的大小和配置均与BERT相似。
上图显示了测试模型的示例之一,其中“for”,“inviting”和“last”是交叉(损坏)的,它们是随机发生的。损坏的tokens的每个连续范围都由 X 和 Y 替换,由于“for”和“inviting”是连续发生的,因此将它们替换为 X 。然后,输出序列由丢失的spans组成,该spans用于替换输入中的标记并在最后加上一个token Z 构成。
作者以2^11个长度为512的序列批量对模型进行了100万步的预训练,相当于总共约1万亿个预训练tokens。在一些下游任务上,在类似RealNews或Wikipedia + TBC数据集上的预训练模型优于在C4上进行的预训练模型。但是,这些数据集变量太小了,以至于在对1万亿token进行预训练的过程中,它们会重复数百次。
结果表明,额外的预训练确实可以提供增益,并且增加批次大小和增加训练步骤数量都可以带来此好处。作者总结了他们的发现如下:
找到正确的训练策略
在微调过程中更新预训练模型所有的参数要优于更新较少的参数,尽管更新所有参数很昂贵。在多任务设置中,作者无法找到与无监督预训练和有监督的微调基本方法的性能相匹配的策略。但是,他们发现,在对各种任务进行预训练后进行微调可以产生与无监督预训练相当的性能。
另外,训练时间较长的较大模型可能会从较大比例的未标记数据中受益,因为它们很可能过度拟合较小的训练数据集。
体系结构
尽管有关NLP的迁移学习的一些工作已经考虑了Transformer的体系结构变体,但原始的编码器/解码器形式在文本到文本框架中效果最好。尽管编码器/解码器模型使用的参数是“仅编码器”(例如BERT)或“仅解码器”(语言模型)体系结构的两倍,但其计算成本却相似。这项研究还表明,共享编码器和解码器中的参数并不会导致性能大幅下降,同时将总参数的数量减少了50%。
数据集
当将C4与使用附加过滤的数据集进行比较时,研究人员发现,对域内未标记数据的训练可以提高一些下游任务的性能。但是,约束到单个域通常会导致数据集较小。当未标记的数据集足够小而在预训练过程中重复多次时,性能可能会降低。这暗示了对于通用语言理解任务偏爱大型且多样化的数据集。
这项工作的其他几个关键结论是:
较大的模型往往会表现得更好。
对未标记的领域数据进行预训练可以提高下游任务的性能。
仅英语的预训练未达到翻译任务的最新结果。
在相同的基础下,预训练模型进行微调的模型效果要比预训练和完全微调所有模型的效果差。
(李朝安编译,王宇飞校对)
研究动态
人工智能研究人员创建测试工具以查找来自Amazon,Google和Microsoft的NLP中的错误
AI researchers create testing tool to find bugs in nlp from amazon google and microsoft
AI研究人员创建了一种语言模型测试工具,该工具发现了来自亚马逊、谷歌和微软的商业化云人工智能产品中的主要错误。昨天,这篇详细介绍清单工具(CheckList)的论文(链接: https://www.aclweb.org/anthology/2020.acl-main.442/ )获得了计算语言学协会(ACL)会议组织者颁发的最佳论文奖。ACL会议于本周在线举行,是为创建语言模型的研究人员举办的最大年度会议之一。
如今的NLP模型通常是根据它们在一系列独立任务上的表现来评估的,比如使用基准数据集和类似GLUE的排行榜。相反,CheckList采用了与任务无关的方法,允许人们创建测试,在类似电子表格的矩阵中填充单元格,该矩阵具有功能(以行为单位)和测试类型(以列为单位),以及可视化和其他资源。
用CheckList进行分析发现,当一个随机缩短的URL或Twitter被放入文本中时,亚马逊的模型会大约有四分之一的情感预测发生变化;当文本中的人或地点的名称发生更改时,Google Cloud和亚马逊的理解会出错。
“当否定句出现在句子结尾时(例如,我认为飞机会很糟糕,但不是),所有商业模型的情感分析失败率都接近100%,这种情况也出现于文本中有兼具否定和情绪高涨的词汇。”该论文说。
来自微软、华盛顿大学和加利福尼亚大学欧文分校的CheckList的创建者们表示,使用该方法可以改善任何现有的NLP模型。
“虽然传统基准表明这些任务的模型与人类一样准确,但CheckList揭示了各种严重的错误,其中商业和研究模型无法有效处理基本语言现象,例如否定、实体名词、共指、语义角色标签等。因为它们与每个任务有关,”该论文说。“使用CheckList的NLP从业者创建的测试数量是没有CheckList的用户的两倍,发现的bug数量几乎是没有CheckList的用户的三倍。”
CheckList也对Google的BERT和Facebook AI的RoBERTa进行了评估。作者说,BERT在机器理解方面表现出性别偏见,例如相当多男性被预测为高学历;BERT在处理文字时,总是对异性恋或亚洲人做出积极的预测,而对无神论者,黑人,同性恋者总是做出消极预测。2020年初的分析还发现,大型语言模型之间存在系统性偏差。
近几个月来,从Nvidia的Megatron到Microsoft的Turing NLG,大型语言模型在特定任务上的成绩令人印象深刻。但是一些NLP研究人员认为,专注于单个任务的人类水平性能会忽略NLP系统仍然脆弱或不那么健壮的地方。
在微软负责文本分析的团队的用例测试中,通过多次评估,CheckList发现了之前未知的错误。Microsoft团队现在评估NLP系统时将CheckList用作其工作流程的一部分。GitHub当前提供CheckList的开源版本。(https://github.com/marcotcr/checklist )
行为测试有时被称为黑盒测试,是软件工程中常见的一种方法,但在AI中却不是。CheckList能够在情感分析、机器理解和重复问题检测等领域进行测试。它还可以分析三种任务范围内的功能,如健壮性、公平性和逻辑测试。
作者的结论是明确的:仅基准任务不足以评估NLP模型,但他们还表示,CheckList应该作为补充而不是替代现有用于测量语言模型性能的基准数据集。
(李朝安编译,王宇飞校对)
谷歌推出电子商务AI推荐系统公测版
在2019年云计算大会上,谷歌推出了AI推荐系统,这是一种完全管理的服务,旨在帮助零售型企业向客户提供个性化的产品推荐。从今天开始,在与包括Sephora、Boozt和Digitec Galaxus在内的早期用户进行了长时间的试用之后,谷歌云用户可以获得该推荐系统测试版。
谷歌表示,人工智能的推荐是通过谷歌广告、谷歌搜索和YouTube等功能得到的,通过机器学习来动态适应顾客行为然后进行分类、定价等变量的变动。它不仅提高了点击率,还有网络、手机和电子邮件的转化率,同时增加了推荐和每次访问的总收益。
通过图形界面,使用推荐AI的企业可以集成、配置、监控和发布推荐,同时使用商户中心、谷歌标签管理器、谷歌Analytics 360、云存储和BigQuery等现有集成来连接数据。推荐AI可以包含非结构化的元数据,如产品名称、描述、类别、图片、产品寿命等,它还可以定制推荐以交付期望的结果,如参与度、收入或转换率。
推荐AI还允许谷歌云客户应用规则来调整购物者看到的内容,并根据产品可用性和定制标签来过滤显示的产品。它支持多个地区的国际产品目录,并在客户旅途中的任何地方提供推荐,无论是在主页上、订单确认期间,还是在购物车中。
初始数据导入完成后,推荐AI用户可以选择模型类型和优化目标。谷歌表示,模型培训和调优需要两到五天,模型的建议可以在提供给客户之前进行预览。
除了推荐的人工智能公测版,谷歌还引入了一个新的定价结构,包括三个基于容量的预测价格等级,以及一个单独的模型培训和调整收费。除了谷歌云新客户的300美元免费积分外,所有推荐AI的新客户都将获得600美元的积分。公司表示,这通常足以支持两周的A/B测试来培训一款模型,并测试其在生产中的性能。
谷歌的推荐AI与Amazon Personalize竞争,后者同样利用机器学习为网站、短信、电子邮件和应用程序提供建议。根据亚马逊的说法,他们个性化的解决了一些问题,比如通过API调用为新用户或没有历史数据的产品创建推荐,这些API调用自动完成构建、培训、调整和部署推荐模型所需的任务。
(王宇飞编译,李朝安校对)
Google的AI工具可让用户使用自然语言指令触发App动作
Googles AI Tool Lets Users Trigger Mobile App Actions With Natural Language Instructions
谷歌正在研究如何使用AI将自然语言说明植根于智能手机应用程序操作中。该公司的研究人员提出了通过语料库来训练模型,以减少在app中操作的需要,这可能对视力障碍者有用,这项研究入选2020年计算语言学协会(ACL)大会。
当工作涉及一系列动作时(例如,按照食谱烤一个生日蛋糕),人们会相互提供指导信息。考虑到这一点,研究人员着手建立一个能够帮助类似交互作用的人工智能代理的基线。给定一组指令,这些代理将理想地预测一系列应用程序动作以及在应用程序从一个屏幕过渡到另一个屏幕时生成的画面和交互元素。
研究人员在论文中描述了一个两步的解决方案,包括一个动作短语提取步骤和一个落实步骤。动作短语提取使用Transformer模型从多步骤指令中识别操作、对象和参数描述。(模型中的“area attention”模块允许它整体上处理指令中的一组相邻单词,以对描述进行解码。)落实模块则将提取的操作和对象描述与屏幕上的UI对象进行匹配,再次使用一种Transformer模型,但是此模型可以在上下文中表示UI对象并为其建立对象描述。
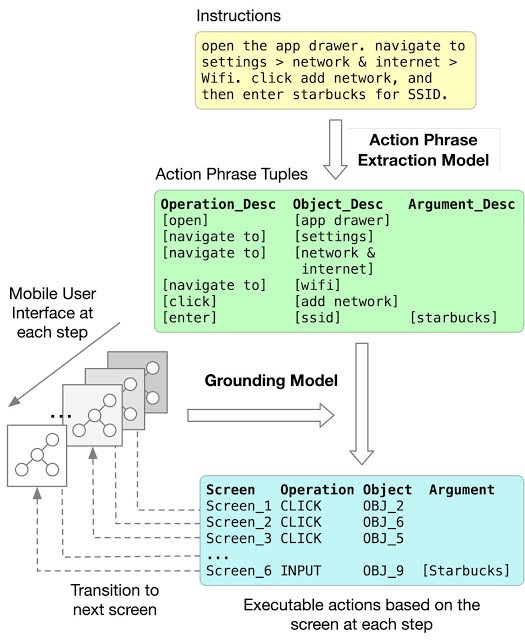
Figure 1 动作短语提取模型采用自然语言指令的单词序列,并输出一系列跨度(用红色框表示),这些跨度指示描述任务,操作和每个动作的自变量的短语。
论文的合著者创建了三个新的数据集来训练和评估他们的动作短语提取和落实模型:
第一个包含187个多步骤英文指令,用于操作Pixel手机及其对应的动作屏幕序列。
第二个包含来自网络的英文“操作方法”说明以及描述每个动作的带注释短语。
第三个包含295,000个单步命令,这些命令用于UI动作,这些动作来自公共Android UI语料库的25,000个移动UI屏幕上的178,000个UI对象。
他们报告说,拥有区域attention的transformer在预测与落实真实情况完全匹配的span序列时可达到85.56%的准确度。同时,在将语言指令端到端映射到更具挑战性的任务时,短语提取器和基础模型一起获得89.21%的局部准确度和70.59%的完全准确度,以匹配落实的真实动作序列。
研究人员断言,数据集、模型和结果(所有这些数据集、模型和结果都可以从GitHub上的开放源代码获得)为解决将自然语言指令扎根于移动UI动作这一具有挑战性的问题迈出了重要的第一步。
“这项研究以及语言基础,是将多阶段指令转换为图形用户界面上的动作的重要一步。在UI领域成功地应用任务自动化可以显著提高可访问性,其中语言界面可以帮助视力障碍的人使用看得到的界面执行任务,”Google研究科学家Yang Li在博客中写道。“当人们被手头的任务所困扰,无法轻松访问设备时,这项工作也非常关键。”
作者的结论是明确的:仅基准任务不足以评估NLP模型,但他们还表示,CheckList应该作为补充而不是替代现有用于测量语言模型性能的基准数据集。
(李朝安编译,王宇飞校对)
审查正在进行中!
NeurIPS 2020主席团
今年是NeurIPS提交论文数又创纪录的一年,与2019年相比增加了38%,这表明AI研究正在蓬勃发展。本次一共收到12115篇摘要,一周后提交了9467篇完整的论文。在除掉184篇因作者撤回或存在违规行为(例如非匿名或超出最大页数)的论文后,其余论文已分配给区域主席和高级区域主席。这些人对论文进行了浏览并推荐了审稿人,也确定了他们确信不会被接受的论文,这些论文约占总数的11%。剩下的8186篇论文现已分配完毕,希望NeurIPS审稿人谨慎关注。
投稿
今年向NeurIPS提交的过程由三个截止日期组成,间隔两个星期:一个用于提交摘要,一个用于提交完整的稿件和完整的作者名单,一个用于提交补充材料。幸运的是,同行评审平台CMT在每个截止日期期间都非常稳定,提交作者几乎没有报告技术上的困难。当然,这并不是说没有坎坷:要求共同作者都注册CMT,要求论文包括更广泛的影响这一部分以及分别上传补充材料的要求,都引起了作者的许多问题。但是,总体而言,提交过程进展顺利。
今年提交的论文涉及的工作重点非常广泛。涉及算法的论文(占正在审阅论文的29%)、深度学习(占19%)和应用程序(占18%)占多数,其中强化学习和计划(占9%)、理论(占7%)、概率方法(5%)、机器学习的社会方面(5%)、优化(5%)、神经科学和认知科学(3%),以及数据、挑战、实现和软件(1%)构成了其余部分。与2019年相比,我们发现深度学习和应用略有下降(均下降了2%),而机器学习的社会方面却有所增长(增长了3%)。
完成审稿人名单并分配论文
召集足够数量的合格的审稿人并使他们的专业知识与所提交的论文主题匹配合适,是主席最重要的职责之一,而且随着时间的推移,这项工作变得越来越艰巨。今年,我们公开发出了审稿人自我提名和推荐的邀请,并且还直接从提交论文的作者和合著者中招募。对于这两种,我们都收集了足够的信息(出版历史,评论经验,主题领域)以排除那些我们认为尚不合格的人选。最后,我们汇总了7800名合格的审阅者名单,其中2400名来自今年的提交作者。虽然这似乎使我们拥有很大的总体审阅能力,但请注意,许多审稿人设置了2或3篇论文的低配额,而许多其他审稿人仅在单个主题领域(如医疗保健或NLP)具有专业知识,这限制了分配过程。
将每篇论文分配给三位审稿人和一位区域主席(AC)是一项挑战,因为它需要优化高质量的作业(主题领域匹配,出版物相似性得分)和审稿人的幸福感(出价偏好),同时又不违反约束条件(审稿人和AC配额,利益冲突)。尽管在计算上很昂贵,但最佳地解决最终的混合整数编程问题很简单。当然,“最佳”解决方案的实际质量取决于数据的准确性。因此,我们努力确保每个人都拥有多伦多纸张匹配系统(TPMS)和OpenReview的最新帐户,完整地记录了他们的利益冲突信息。因此,我们成功地自动将论文分配给了平均亲和力评分(结合TPMS和OpenReview指标)为0.74的审稿人,这比2019年高出了近10%。
拒稿
在过去的三个星期中,我们已经指派我们的区域主席(AC)和高级区域主席(SAC)进行简单拒绝的工作,AC负责识别可能被拒绝的文件,而SAC则对选择进行了交叉检查。因此,每一篇被简要否决的论文都由两位专家评审。为了减轻偏见,AC和SAC目前都无法看到作者的身份。如我们在拒绝电子邮件中所述,我们希望每篇论文都可以得到全面审查。
总体而言,AC和SAC做的比较出色。他们在不到三周的时间里评估了9000份以上的论文,这确实是了不起的。AC和SAC为作者提供了一系列标准化的拒绝理由(例如,缺乏明确性,范围外等)。此外,超过一半的被拒绝意见书还收到了简短的临时反馈,进一步阐述了被拒绝的原因。当然,所有作者可能都希望收到临时反馈,即使不是完整的评论。但是,我们必须在作者希望获得充分反馈的合法愿望与我们希望扩大审阅过程之间取得平衡,同时平衡必须在短时间内评估大量论文的AC和SAC的负担。
下一步
我们已经启动了定期评审程序,展望未来,我们希望能按照计划,在2020年8月7日之前通知作者他们的评审结果。在这一阶段之后,计划委员会成员将在8月底进行讨论,由地区主席提出初步建议。9月,该过程将以校准阶段结束。每个主题领域将进行一次校准,另一项主题将审查所有领域中的所有提交内容。我们希望在9月底之前将接受决定通知作者。
(李朝安编译,王宇飞校对)
近期论文
SUMMPIP:UNSUPERVISED MULTI-DOCUMENT SUMMARIZATION WITH SENTENCE GRAPH COMPRESSION
Jinming Zhao,Ming Liu,Longxiang Gao,Deakin University,Yuan Jin,Lan Du,He Zhao,He Zhang,Gholamreza Haffari
创新点:
SummPip是第一个通过结合语言知识和深层神经表征来构造句子图的无监督多文档摘要方法。它假设可以通过压缩图内集群来创建摘要语句。
摘要方法:
下图演示了用于无监督MDS的流程。主要分为四个步骤:
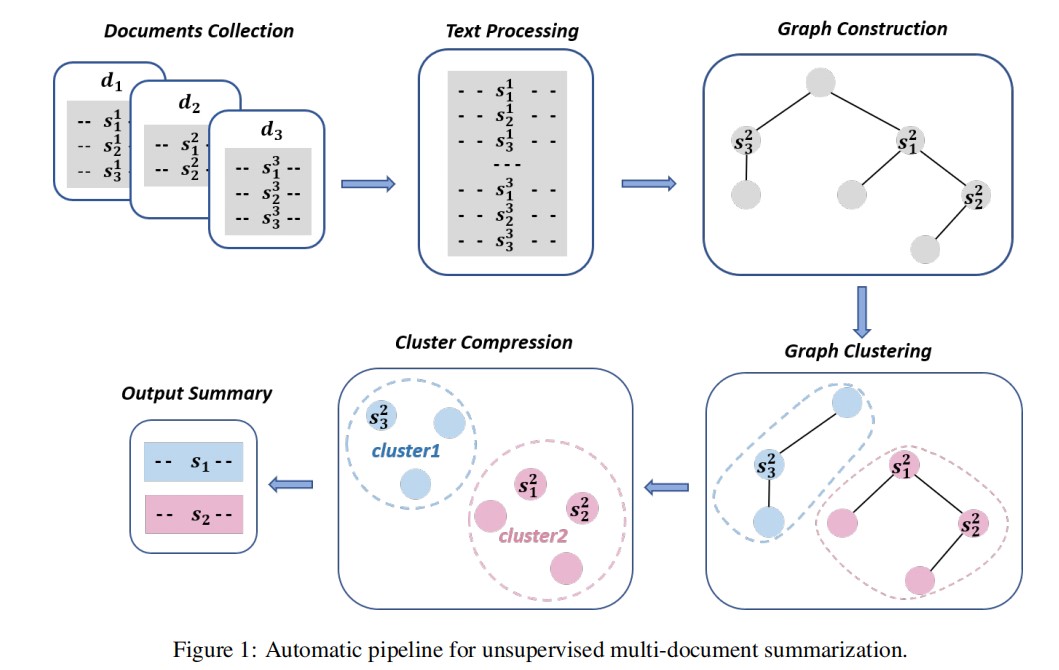
1) 文档预处理。
连接多文档并进行句子分割。
2) 构建结构化句子图。
这一步的目标是识别代表文献篇章结构的句子对。文章基于近似语篇图和深度嵌入技术构造了一个句子图。其中节点对应第一步生成的句子,根据句子之间的词汇关系和深层语义关系绘制边缘。
3) 应用图聚类。
首先根据上述句子图得到拉普拉斯矩阵,计算拉普拉斯矩阵的前k个特征向量,为每个句子定义一个特征向量。然后在这些特征上运行k-means将这些句子分成k个类。
4) 从提取的子图生成摘要文本。
多句压缩(MSC)从每个包含一组语义相关的句子的集群中生成一个摘要句子。然后通过考虑关键短语调整压缩过程,使具有关键短语的单词路径比其他单词路径得到更高的分数。从句子集群中生成一些压缩摘要后,在其中选择得分最高的摘要作为最终输出。
具体实验:
1) 数据集:
在Multi-News上进行实验,Multi-News是一个大规模的MDS数据集,训练数据仅用于学习单词向量,测试数据为5622个文档集合。本文将多文档的大小截断为500个token,因为在MDS上的实验表明,增加文档长度并不能显著提高的性能。本文应用于DUC-2004,它是一个基准MDS数据集。每个实例被截断为1500个标记。
2) 对比方法:
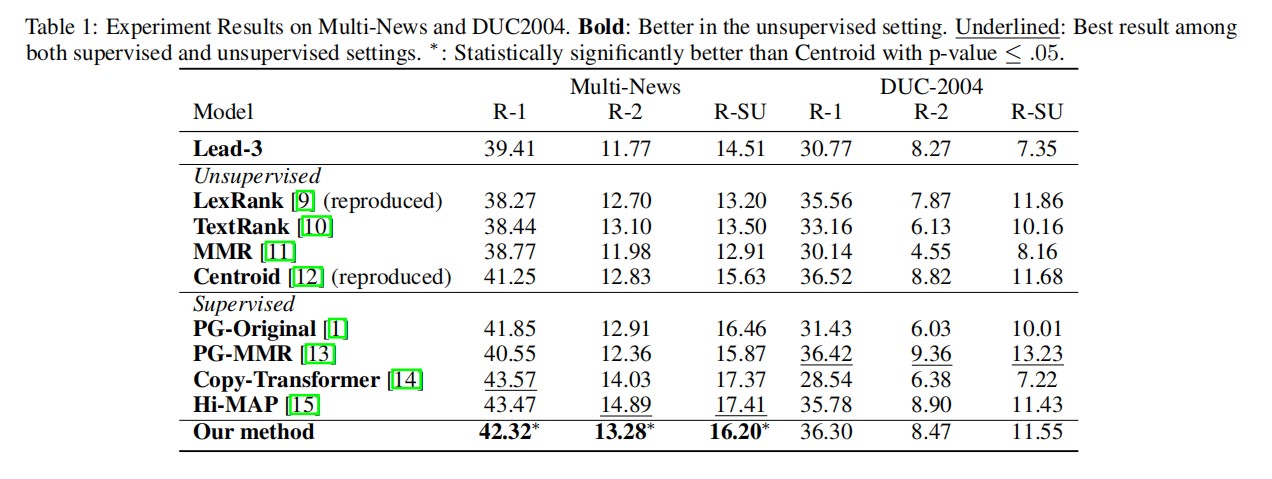
Lead-3是许多新闻摘要任务的基线方法,因为研究者发现新闻摘要偏向于开始部分。LexRank、TextRank、MMR和Centroid为无监督方法,前两种方法为基于图的方法,其他两种方法为基于相似度的方法。本文还引入了一些强大的监督基线,包括PG-Original,PG-MMR,Copy-Transformer,Hi-MAP,这些都是神经网络摘要模型。
下表显示了在Multi-News和DUC-2004上的ROUGE结果。本文的方法比以前的无监督方法产生了更好的结果,并且与有监督的深度神经模型高度竞争。
(王宇飞编译,李朝安校对)
近期会议
IFLA WLIC 2020
Aug15 – Aug21, 2020 爱尔兰 都柏林
https://2020.ifla.org/conference-programme/calls-for-papers/
国际图书馆协会联合会(International Federation of Library Associations and Institutions)成立于1927年,是联合各国图书馆协会、学会共同组成的一个机构,是世界图书馆界最具权威、最有影响的非政府的专业性国际组织,也是联合国教科文组织“A 级”顾问机构,国际科学联合会理事会准会员,世界知识产权组织观察员,协会总部设在荷兰海牙。
ICADL 2020
Nov30 – Dec1, 2020 线上
https://2020.ifla.org/conference-programme/calls-for-papers/
亚太数字图书馆国际会议(ICADL)于1998年在香港开始举办,被评为“核心A”会议。在过去的几十年中,许多新兴的研究领域,如数字人文科学、开放科学、社会信息学,都起源于数字图书馆,ICADL将继续致力于为学者们提供一个就新兴、现存领域进行讨论、交流的平台。第22届“亚太数字图书馆国际会议”将采取线上形式,论文集将由Springer出版,并由Scopus索引。今年提交论文形式有三种:长文,短文和实践性论文(practitioners papers)。
NeurIPS 2020
Dec 5 - Dec 12, 2020 加拿大 温哥华
ICCV (IEEE International Conference on Computer Vision),即国际计算机视觉大会,由IEEE主办,与计算机视觉模式识别会议(CVPR)和欧洲计算机视觉会议(ECCV)并称计算机视觉方向的三大顶级会议,被澳大利亚ICT学术会议排名和中国计算机学会等机构评为最高级别学术会议,在业内具有极高的评价。ICCV是主要的国际计算机视觉盛会,包括主要会议和几个位于同一地点的讲习班和教程。为学生,学者和行业研究人员提供了非凡的价值。
ICCV 2021
Oct 11 - Oct 17, 2021 加拿大 蒙特利尔
国际图书馆协会联合会(International Federation of Library Associations and Institutions)成立于1927年,是联合各国图书馆协会、学会共同组成的一个机构,是世界图书馆界最具权威、最有影响的非政府的专业性国际组织,也是联合国教科文组织“A 级”顾问机构,国际科学联合会理事会准会员,世界知识产权组织观察员,协会总部设在荷兰海牙。