文本挖掘与机器学习跟踪扫描动态快报(2021.08)
实时跟踪、关注文本挖掘与机器学习领域最新研究动态
深度观察
会话 NLP 的两个新数据集:TimeDial和Disfl-QA
NLP中的一个关键挑战是构建能够理解和推力真实语音所特有的不同语言现象的会话代理。例如,因为人们并不总是准确地预谋他们要说什么,一次自然的谈话通常包括对讲话的中断,即不流利。这种不流畅可以是简单的(如感叹词、重复、重新开始或更正),这会破坏句子的连续性,也可以是更复杂的语义不流畅,其中短语的基本含义会发生变化。此外,理解一段对话通常还需要了解时间关系,比如一个事件是在另一个事件之前还是之后。然而,建立在当今NLP模型基础上的会话代理在遇到暂时关系或不流畅时往往会遇到困难,而且在改善其性能方面进展缓慢。这在一定程度上是由于缺乏涉及如此有趣的会话和言语现象的数据集。
为了激发研究界对这一方向的兴趣,我们很高兴推出TimeDial,用于对话中的时态常识推理,以及Disfl-QA,它专注于上下文不流畅。TimeDial提出了一个新的多项选择跨度填充任务,旨在用于时间理解,带有超过1.1k对话的带注释测试集。Disfl-QA是第一个在信息搜索环境中包含上下文不流畅的数据集,即通过维基百科段落回答问题,有约12k个人类注释的不流畅问题。这些基准数据集是同类数据集中的第一个,显示了人类绩效与当前最先进的NLP模型之间的巨大差距。
TimeDail
虽然人们可以毫不费力地对日常时间概念进行推理,如对话的持续时间、频率或事件的相对顺序,但这类任务对会话代理来说可能是一个挑战。例如,当前的NLP模型在填空(如下图所示)时往往选择不当,该空白假设推理具有基本的世界知识水平,或者需要理解跨会话回合的时间概念之间的显式和隐式相互依赖关系。
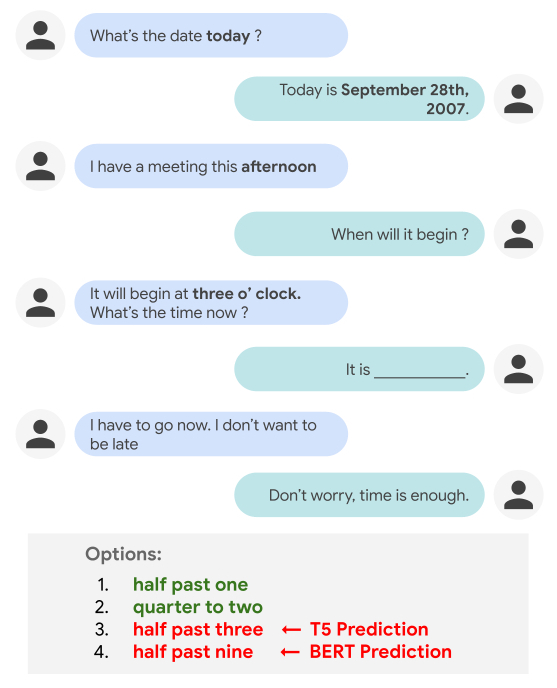
一个人很容易判断“一点半”和“两点”比“三点半”和“九点半”更像是填空的选项。然而,对于NLP模型来说,在对话的上下文中执行这种时间推理并非易事,因为它需要借助世界知识(即,知道参与者还没有迟到)并理解事件之间的时间关系(“一点半”在“三点”之前),而“三点半”在后面)。事实上,像T5和BERT这样的最新模型最终选择了错误的答案——“三点半”(T5)和“九点半”(BERT)。
TimeDial基准数据集测量模型在对话上下文中中的时态常识推理能力。数据集中约1.5 k个对话中的每一个都以多项选择设置呈现,其中一个时间跨度被屏蔽,并且该模型被要求从四个选项列表中找到所有正确答案来填空。
在我们的实验中,我们发现,虽然人们可以轻松地回答这些选择题(准确率为97.8%),但最先进的预先训练的语言模型仍然难以应对这一挑战。我们在三种不同的建模范式中进行了实验:(i)使用BERT对提供的4个选项进行分类;(ii)使用BERT-MLM对对话框中的掩码跨度进行掩码填充;(iii)使用T5的生成方法。我们观察到,所有模型都在这个挑战集上苦苦挣扎,最佳变体得分仅为73%。

定性错误分析表明,预训练的语言模型通常依赖于浅层、虚假的特征(尤其是文本匹配),而不是真正地根据上下文进行推理。很可能,构建能够执行TimeDial所需的时态常识推理的NLP模型需要重新思考时态对象在一般文本表示中的表示方式。
Disfl-QA
由于不流畅本质上是一种语音现象,它最常见于语音识别系统的文本输出中。理解这些不流畅的文本是构建理解人类语言会话代理的关键。不幸的是,NLP和语音社区的研究因缺乏包含此类不流畅的精选数据集而受到阻碍,并且可用的数据集(如Switchboard)在规模和复杂性方面都是受限的。因此,在不流畅的情况下,很难对NLP模型进行压力测试。

Disfl-QA是第一个包含信息搜索设置中上下文不流畅的数据集,即对来自SQuAD的维基百科段落的问答。Disfl-QA是一个针对不流畅的目标数据集,其中所有问题(~12k)都包含不流畅性,这使得不流畅性测试集比以前的数据集大得多。Disfl-QA中90%以上的不流畅是修正或重新开始,这使得不流畅修正的测试集更加困难。此外,与早期的不流畅数据集相比,它包含更广泛的语义干扰因素,即携带语义的干扰因素,而不是简单的言语不流畅。

这里,第一个问题(Q1)是寻找关于诺曼底位置的答案。在不流畅的版本(DQ1)中,在修正问题之前提到了挪威语。这种修正不流畅的存在使QA模型混乱,QA模型倾向于依赖问题中的浅层文本线索进行预测。
Disfl-QA还包括更新的现象,例如重新命名和修复之间的共同引用(表示同一实体)。

实验表明,在零样本设置中对Disfl-QA和启发式不流畅进行测试时,现有的基于最先进语言模型的问答系统的性能显著下降。
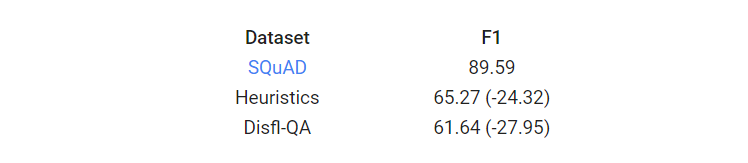
我们展示了数据增强方法部分地恢复了性能损失,并且还证明了使用人工注释训练数据进行微调的有效性。我们认为,研究人员需要大规模的不流畅数据集,以便NLP模型对不流畅具有鲁棒性。
结论
理解人类语言特有的语言现象,如不流畅和时间推理等,是在不久的将来实现更自然的人机交流的关键因素。通过TimeDial和Disfl-QA,我们的目标是通过提供这些数据集作为NLP模型的测试平台来填补主要的研究空白,以便评估它们对不同任务中普遍存在的现象的鲁棒性。我们希望,更广泛的NLP社区将设计出通用的少样本或零样本方法来有效处理这些现象,而不需要专门针对这些挑战构建的特定任务的人类注释训练数据集。
(张梦婷编译,赵海喻校对)
研究动态
Google的H-Transformer-1D:用于长序列处理的具有线性复杂度的快速一维层次注意
Transformer架构强大的注意力机制能够在各种NLP任务中提升SOTA性能。然而,这种注意机制的运行时间和内存使用的二次复杂性长期以来一直是处理长序列时的一个关键瓶颈。
在新论文H-Transformer-1D:Fast One-Dimensional Hierarchical Attention for Sequence中,Google的一个研究团队从两种数值分析方法——层次矩阵(H-Matrix)和多重网格——中获得灵感,以解决Transformer体系结构中注意机制的二次复杂性问题。研究人员提出了一种分层注意方案,该方案在运行时和内存方面具有线性复杂性,并在NLP基准上实现了SOTA性能。

在数值分析中,H矩阵被用作非稀疏矩阵的数据稀疏近似,通过矩阵块层次结构推广低秩近似,以显著提高压缩率。同时,多重网格法是一种求解大规模稀疏矩阵的算法,该矩阵由使用层次结构的离散偏微分方程生成。与其他方法相比,它的优势在于它可以随着使用的离散节点数线性扩展。

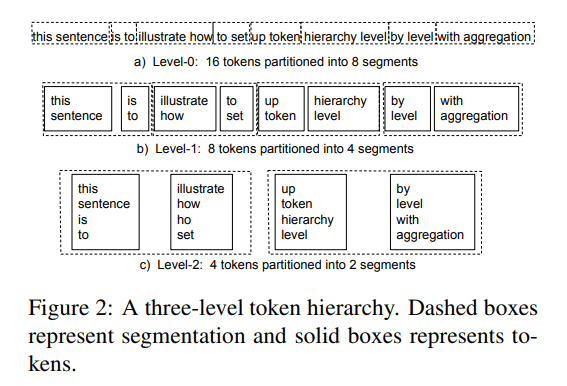
该团队将多层次方法的特点定义为对近距离的交互作用不进行近似,而对距离越来越远的交互作用应用精度越来越低的近似。这导致他们假设,注意矩阵的层次结构所体现的归纳偏见可以用来捕获NLP任务序列中的层次结构。他们确定了三个步骤来概括他们的分层注意机制:1)分离近距离、中距离和远距离注意的注意矩阵块,这是距离依赖性注意的第一步;2) 建立令牌层次结构;3) 构建了层次注意。

通常,所提出的分层矩阵结构建立了矩阵乘法和矩阵向量乘法的分层方法。该团队还表明,分层注意算法的总体运行时间和内存复杂度为O(dL),并且它仅使用针对GPU或TPU优化的密集线性代数运算。
该团队进行了广泛的实验,使用Long Range Arena(LRA)和10亿字的基准测试,评估所提出的分层注意方法在序列中捕获分层结构时所体现的诱导偏差的有效性。
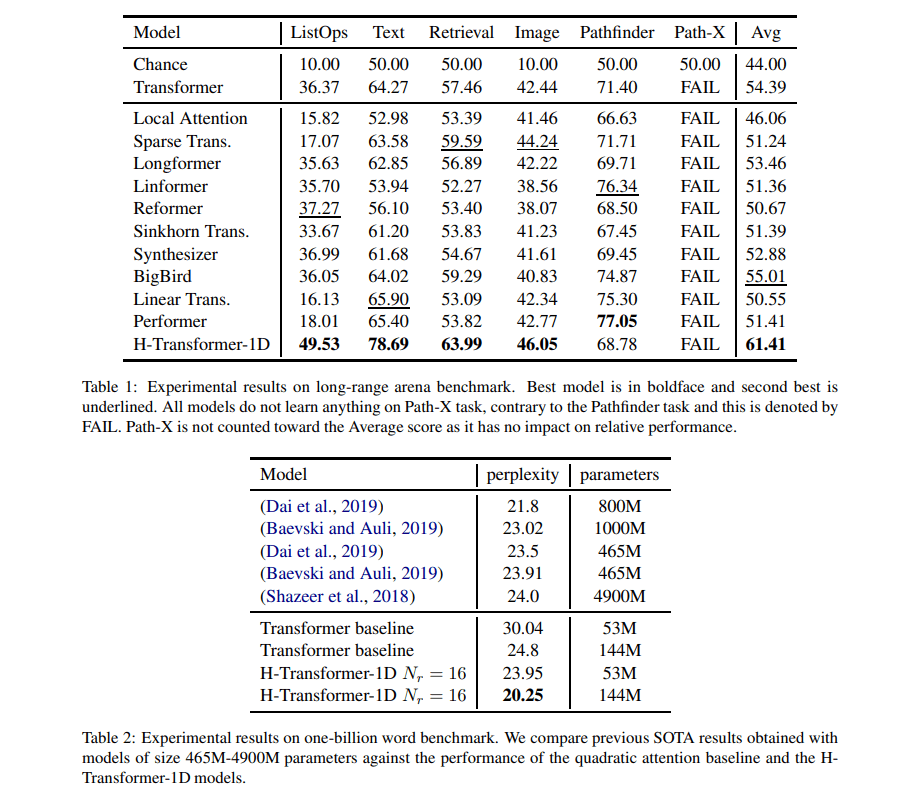
所提出的分层注意机制在LRA基准上取得了最佳性能,比以前的最佳Big Bird算法提高了6个百分点以上;并在10亿字基准上建立了一个新的SOTA,与之前的最好的Transformer-XL相比,测试困惑度降低了1.55个百分点。
总体而言,所提出的分层注意方法在运行时和内存使用方面表现出线性复杂性,并且与GPU和TPU上的密集线性代数库完全兼容。
(张梦婷编译,赵海喻校对)
Google研究人员使Transformers能够解决组合NLP任务
Google Researchers Enable Transformers to Solve Compositional NLP Tasks
合成泛化是理解和产生已知语言成分的新组合以“无限使用有限手段”的能力。虽然这是人类的第二天性,但经典人工智能技术,如语法或基于搜索的系统,也在NLP领域展示了这种能力。
然而,最先进的深度学习体系结构(如Transformer)难以捕捉自然语言中的组合结构,因此无法从组成上进行泛化。
在论文Making Transformers Solve Compositional Tasks中,Google的一个研究团队探索了Transformer模型的设计空间,以使深度学习体系结构能够解决自然语言组合任务。所提出的方法通过显著影响合成泛化的设计决策为模型提供归纳偏差,并在语义解析合成泛化和字符串编辑操作合成基准上实现最先进的结果。

该团队将其主要贡献总结如下:
- Transformer架构设计空间的研究,表明哪些设计选择会导致归纳学习偏差,从而导致在各种任务中的组合泛化。
- 在COGS等数据集上获得最先进的结果,我们使用基于序列标记的中间表示法的分类准确率为0.784(相比之下,之前报告的最佳模型为0.35(Kim和Linzen,2020))。
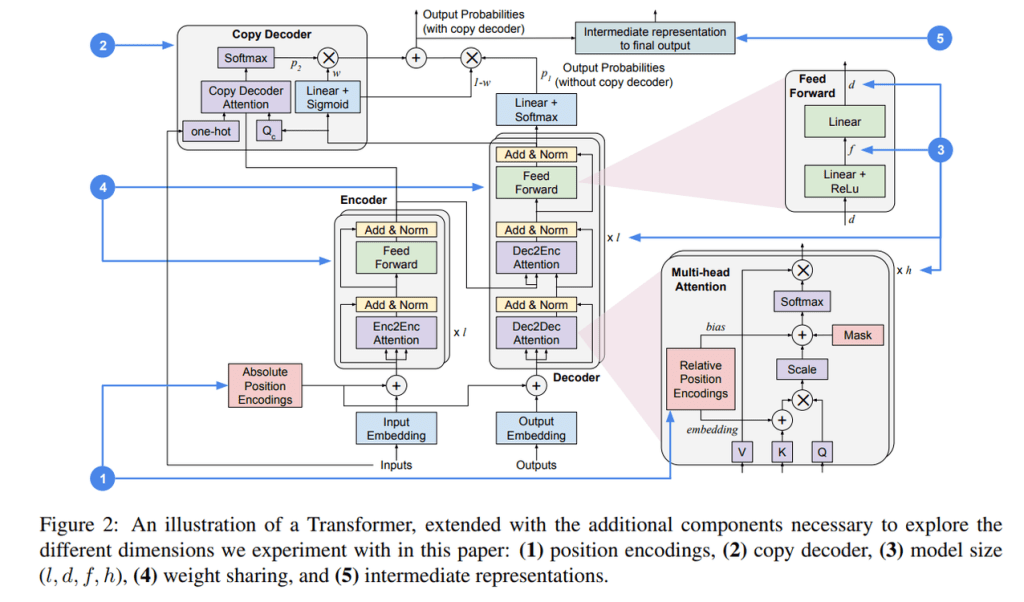
本研究侧重于标准Transformer模型,该模型包括编码器和解码器。给定token嵌入序列,Transformer网络将使用基于解码器生成的输出分布的预测,一次输出一个token序列。
尽管组合泛化似乎是一项艰巨的任务,但先前的研究表明,它可以被视为一个一般的分布外泛化问题。受这一想法的启发,研究人员假设,不同的Transformer架构选择将给模型带来不同的归纳偏差,从而使它们或多或少地发现对称性,从而更好地推广到分布外的样本。
研究人员评估了具有不同架构配置的Transformer的合成泛化能力,特别是:(1)位置编码类型,(2)复制解码器的使用,(3)模型大小,(4)权重共享,以及(5)使用中间表示进行预测。他们使用序列级精度作为评估指标。
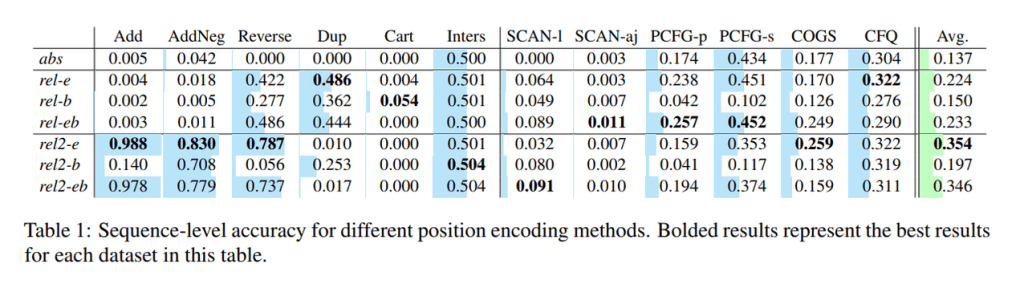
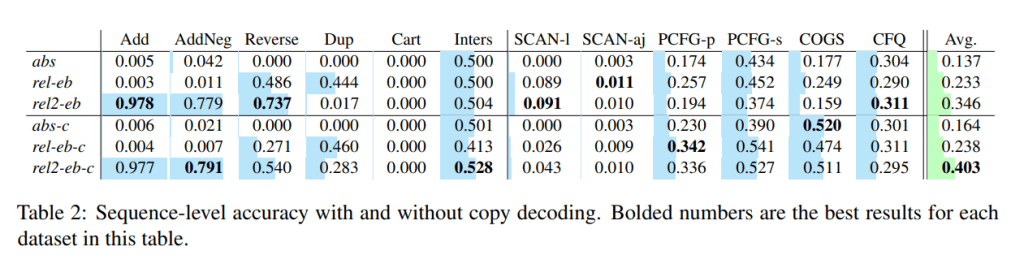
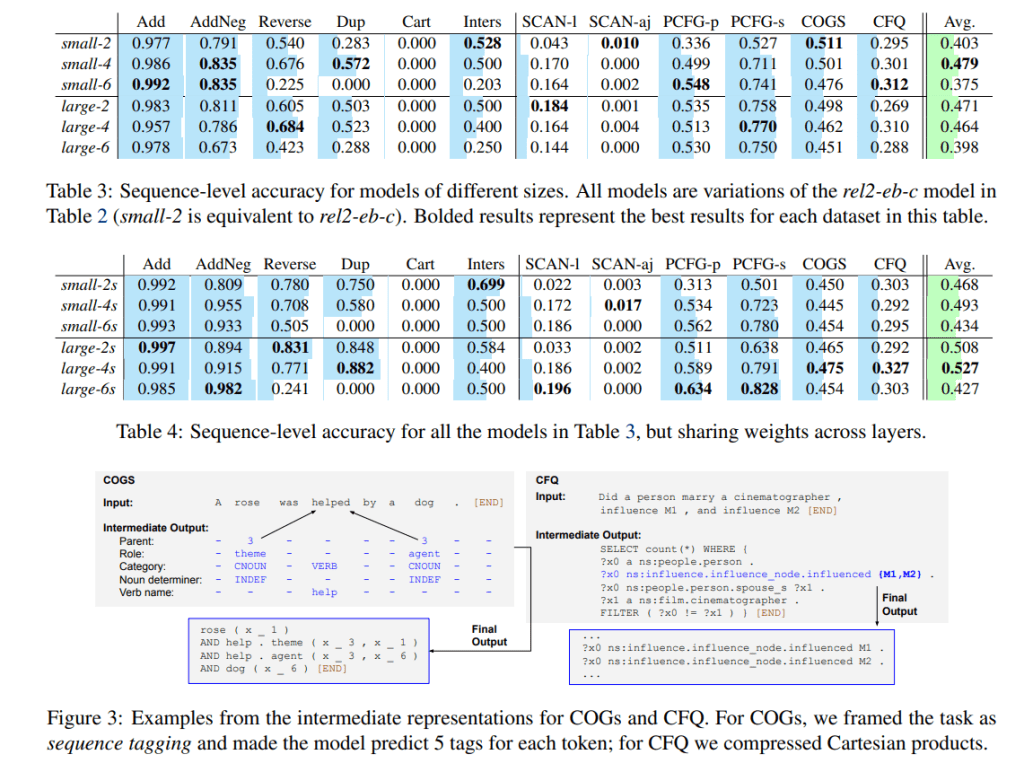
在实验中,基线Transformer的平均序列级精度仅为0.137。通过更改设计决策,其精度提高到0.527。此外,该方法在COGS数据集(0.784精度)和PCFG分割(分别为0.634和0.828)上获得了最新的结果。
总的来说,该研究表明,不同的设计决策如何提供归纳偏差,使模型能够推广到输入数据中的某些对称性,从而与先前报告的语言和算法任务中合成泛化的基线Transformer性能相比,显著改善合成泛化。
(张梦婷编译,周子喻校对)
LinkedIn研究应用深度NLP改进搜索系统
深度学习的快速发展在许多NLP任务中取得了令人印象深刻的成绩。由于当今无处不在的搜索系统处理用户查询和配置文件中的自然语言,以及他们在web上爬取的无数文档中的自然语言,搜索似乎是深层NLP的理想环境。然而,它在工业搜索引擎中的应用面临着许多独特的挑战,例如服务延迟、鲁棒性问题和有效性。
在论文Deep Natural Language Processing for LinkedIn Search Systems中,LinkedIn的一个研究团队研究了在各种有代表性的搜索引擎任务中使用深层自然语言处理,旨在为更好的行业搜索引擎的开发提供有用的见解。

该团队将其贡献总结如下:
- 据我们所知,这是首次将深度学习应用于搜索引擎产品中五个具有代表性的NLP任务的综合研究。对于每个任务,我们强调经典NLP任务和搜索任务之间的区别,提供实用的解决方案,并在LinkedIn的商业搜索引擎中部署模型。
- 虽然之前的工作侧重于离线相关性改进,但我们努力在延迟、鲁棒性和有效性之间取得平衡。我们将五项任务中的观察结果和最佳实践总结为经验教训,这些经验教训对于搜索引擎的开发和其他行业应用可能是一种宝贵的资源。
这篇论文提出了三个问题:(1)深度NLP在搜索系统中什么时候有用/没用?(2) 如何应对延迟挑战?(3) 如何确保模型的鲁棒性?为了找到答案,研究人员对深度学习在搜索引擎领域的五项具有代表性的NLP任务中的应用进行了全面研究。
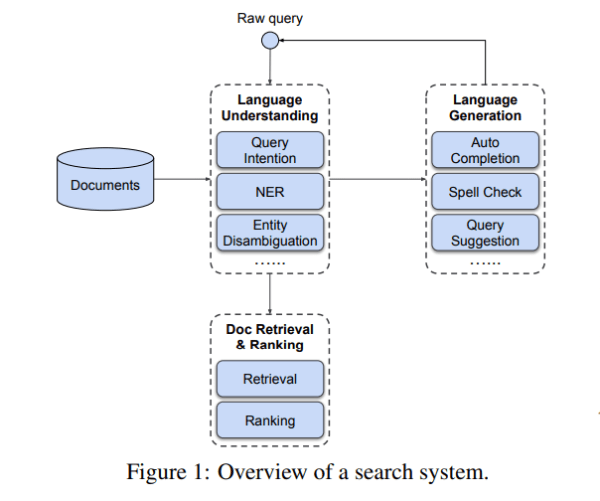
该团队首先概述了典型搜索系统的三个主要组成部分:语言理解,它从输入中提取重要特征;语言生成,这意味着查询更可能导致理想的搜索结果;以及文档检索和排序,从而生成最终结果。
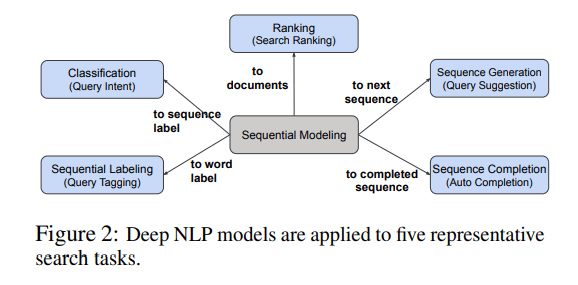
然后,他们在五个具有代表性的搜索任务上进行实验,这些任务涵盖了经典的NLP挑战:查询意图预测、查询标记、查询自动完成、查询建议和文档排序。
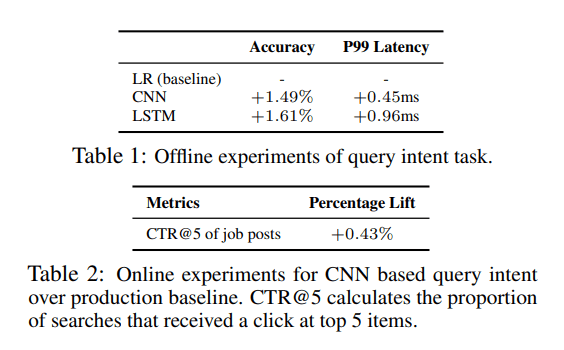
对于查询意图预测,LinkedIn系统预测用户对七个垂直搜索的意图概率:人员、工作、提要、公司、团体、学校、事件。对于这项任务,该研究比较了卷积神经网络(CNN)和长短记忆网络(LSTM)方法,并以它们的产生模型为基线。结果表明,CNN和LSTM模型都优于产生式模型,表明它们在捕获查询意图方面具有更高的有效性。
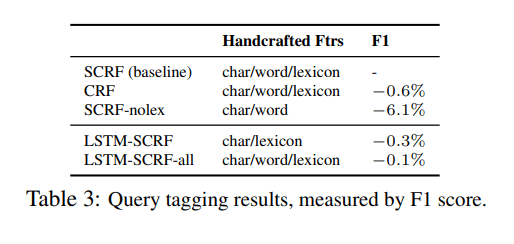
查询标记任务旨在识别查询中的命名实体。LinkedIn搜索系统识别了七种这样的条目类型:名字、姓氏、公司名称、学校名称、地理位置、头衔和技能。对于这项任务,团队选择了一个半马尔可夫条件随机场(SCRF)来训练生产模型,并将其与双向LSTM-CRF架构进行了比较。在这里,传统的SCRF方法取得了最好的结果,这表明LSTM提取长距离依赖关系的能力在这项任务中没有帮助。

对于查询自动完成,团队将非规范化语言模型应用于候选排名阶段,并将其与神经语言模型进行比较。结果表明,本文提出的非规范化语言模型可以在显著降低延迟的同时达到相同的关联性能水平。

对于查询建议,该团队在联邦搜索中测试了一个seq2seq模型,并将其与LinkedIn基于基线频率的方法进行了比较。结果表明,seq2seq模型可以找到更好的候选者,同时也为新手用户生成领域内术语。

最后,在文档排名上,团队将CNN排名与基线xgboost方法进行了比较。在这项任务中,提议的CNN排名大大超过了基线。
根据他们的实验,研究小组得出结论,深度NLP在与搜索相关的语言生成任务和处理具有丰富释义的数据时尤其有益。但是,深度NLP对查询标记任务没有帮助。研究人员还指出,延迟是这一领域的最大挑战,并表明鲁棒性和过度拟合问题通常可以通过仔细的数据分析来处理。
(张梦婷编译,赵海喻校对)
DeepMind:数据高效强化学习的新视角
DeepMind's Collect & Infer:A Fresh Look at Data Efficient Reinforcement Learning
近年来,人们对强化学习(RL)算法越来越感兴趣,这种算法可以完全从固定数据集中学习,而无需交互(离线RL)。在这一研究领域,还有一些相对未探索的挑战,例如如何最大限度地利用收集的数据,如何处理不断增长的数据集,以及如何组合最有效的数据集。
在论文Collect & Infer - a fresh look at data-efficient Reinforcement Learning中,DeepMind研究团队提出了一个清晰的概念,将RL过程分离为数据收集和知识推理,以提高RL数据效率。该团队引入了“收集和推断”(C&I)范式,并就如何从C&I角度解释RL算法提供了见解;同时也展示了它如何指导未来研究更高效的数据传输。

C&I范式的关键思想是将RL分离为两个不同但相互关联的过程:通过与环境交互将数据收集到过渡记忆中,并通过从所述记忆的数据中学习推断关于环境的知识。
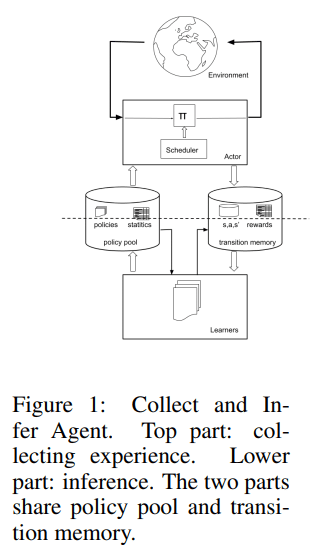
为了优化每个过程,团队设定了两个目标:(1)给定一个固定的数据批次,什么是获得最佳执行策略的正确学习设置(最优推理);和(2)给定一个推理过程,获得最大性能策略所需的最小数据集是什么(最佳收集)。
该团队将其算法开发需求描述为:
- 假设如(1)所建议的固定数据,学习是在“批量”设置中离线完成的。 数据可能是由与作为学习目标的行为策略不同的行为策略收集的。 这使得能够利用相同的数据同时针对多个目标进行优化,并且与离线 RL 的兴趣相吻合。
- 将数据收集视为一个单独的过程提供了一种新的方法,可以在不影响最终任务解决方案的情况下,将技能、基于模型的方法或创新探索方案等已知方法集成到学习过程中。
- 数据收集可以与推断同时进行(在这种情况下,两个过程相互影响,我们接近在线RL),也可以单独进行。
- C&I提出了一个不同的评估重点:与通常基于后悔的探索框架相比,C&I的目标并不是在收集过程中优化任务性能。相反,我们区分了学习阶段(在此期间收集一定数量的数据)和部署阶段(在此期间评估代理的性能)。
C&I范式提供了相当多的机会和灵活性。它在纯离线(批量)和更传统的在线学习场景之间的插值可以实现快速学习新行为,只需少量在线经验。通过解耦行动和学习,它可以优化无监督RL和无监督技能发现的数据收集策略和方案。通过将数据视为知识转移的载体,C&I可以为多任务和转移场景启用新算法。在考虑元学习或终身学习场景时,它也提供了不同的重点。
传统的贝叶斯方法试图在勘探和开发之间找到一个最佳的平衡点,但通常难以解决,因此提出的C&I方法将其优化重点放在数据收集上。
这篇论文的总体信息是通过明确分离数据收集和利用来重新思考数据高效的 RL,并利用离策略 RL 在代理设计中的灵活性。
该团队相信他们的工作可以鼓励进一步研究获取信息的策略; 同时提供一个灵活的框架,可以促进目标、表示和执行策略的概念解开。
(张梦婷编译,周子喻校对)
近期论文
Enhanced Seq2Seq Autoencoder via Contrastive Learning for Abstractive Text Summarization
摘要
在本文中,我们提出了一种基于对比学习的去噪序列到序列(seq2seq)自动编码器,用于生成式文本摘要。我们的模型采用基于标准Transformer的结构,带有多层双向编码器和自回归解码器。为了增强其去噪能力,我们将自监督对比学习与各种句子级文档增强相结合。seq2seq自动编码器和对比学习这两个组件通过微调进行联合训练,从而提高了文本摘要在ROUGE得分和人工评估方面的性能。我们在两个数据集上进行了实验,证明我们的模型优于许多现有的基准测试,甚至达到了与使用更复杂的体系结构和大量计算资源训练的最先进的生成式系统相当的性能。
主要贡献
在本研究中,我们提出了一个新的框架ESACL(Enhanced Seq2Seq Autoencoder via Contrastive Learning),通过微调来提高Seq2Seq模型的去噪能力和模型的灵活性。与大多数在预训练中设计去噪目标的现有方法不同,ESACL在微调阶段优化模型,这需要较少的计算资源,并显著节省训练时间。具体而言,ESACL利用了自我监督对比学习,并将其集成到标准的seq2seq自动编码器框架中。总的来说,它包括两个阶段:(1)句子级文档扩充,(2)seq2seq自动编码和对比学习的联合学习框架,总体目标是基于微调损失和自我监督对比损失。关于seq2seq自动编码器,ESACL使用与BART类似的体系结构,BART是一种基于Transformer的标准模型,具有多层双向编码器和从左到右的解码器。如图1所示,ESACL执行文档扩充以创建两个实例,并在seq2seq模型的基础上设计了一个独特的框架:它不仅使用来自解码器的输出进行微调,而且还尝试在两个扩充实例之间最大化编码器输出的一致性。
实验
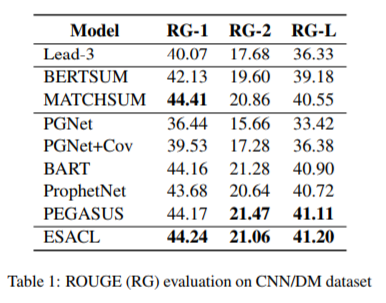
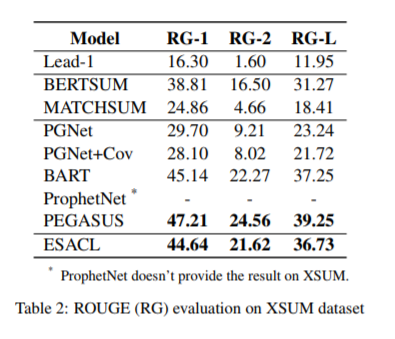
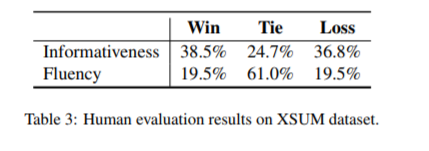
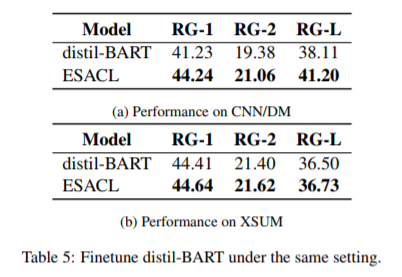
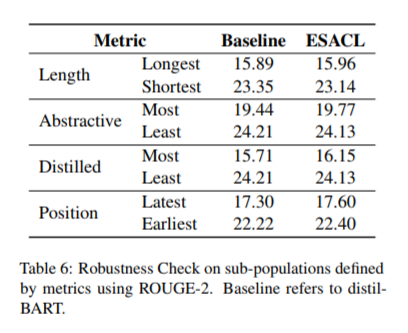
(张梦婷编译)
近期会议
MemSum : Extractive Summarization of Long Document Using Multi-Step Episodic Markov Decision Processes
Aug 21 Chennai, India
DNLP 2021将提供一个极好的国际论坛,以分享数据挖掘和NLP的理论、方法和应用方面的知识和成果。 这次会议的目的是将学术界和工业界的研究人员和从业人员聚集在一起,集中精力于理解数据挖掘和NLP概念,并在这些领域建立新的合作关系。
(张梦婷)
NLPCC 2021:Natural Language Processing and Chinese Computing
Oct 12 - Oct 17 Chennai, India
NLPCC是一个领先的国际会议,专门研究自然语言处理(NLP)和中文计算(CC)领域。NLPCC在CCF推荐的CS会议列表中。它是学术界、工业界和政府的研究人员和实践者分享他们的想法、研究成果和经验,并促进他们在该领域的研究和技术创新的主要论坛。
(张梦婷)