文本挖掘与机器学习跟踪扫描动态快报(2019.11)
实时跟踪、关注文本挖掘与机器学习领域最新研究动态
深度观察
NLP中迁移学习的现状
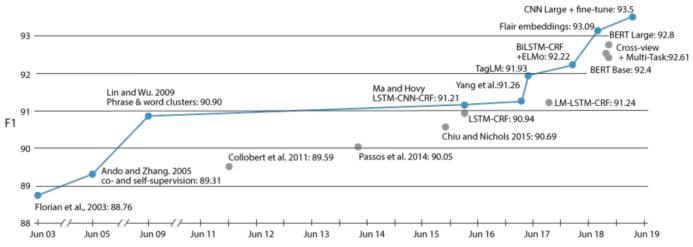
随着时间的推移,CoNLL-2003(English)上的命名实体识别的性能变化
当前的NLP中有很多不同类型的迁移学习,可以根据以下三个方面大致分类:a)源设置和目标设置是否处理同一任务;b)源域和目标域的性质;c)学习任务的顺序。突出上述三个方面差异的分类如下图所示:
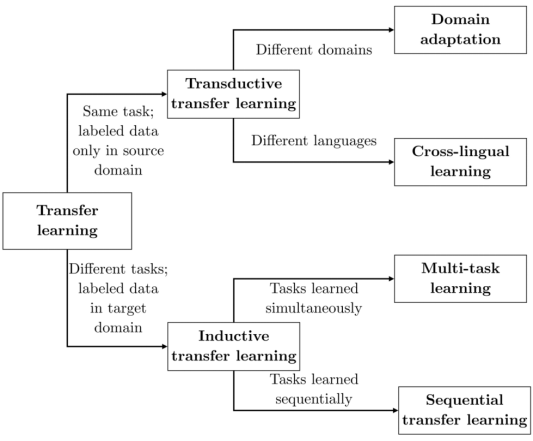
自然语言处理中迁移学习的分类法
顺序迁移学习是迄今为止改进最大的形式。通常的做法是,选择方法对大型未标记文本语料库中的表示(representations)进行预训练,然后使用标记数据使这些表示适应于受监督的目标任务。如下所示:
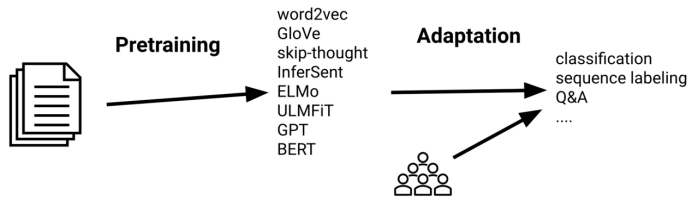
顺序迁移学习的一般过程
为什么预训练语言模型如此有效?
1.样本效率
预训练减少了对带标签数据的需求。在实现类似性能时,迁移学习所需的样本数要比未经过预训练的模型少10倍甚至更多。ULMFiT(Universal Language Model Fine-tuning)如下图所示:
检查BERT学习的原始词向量(大约30000个。其中78%是完整的“cell”、“protein”形式的单词,22%是不完整的单词像“##os”这种形式。例如,单词“icos”在BERT模型的输入时会表示为两个向量——“ic”和“##os”)显示:
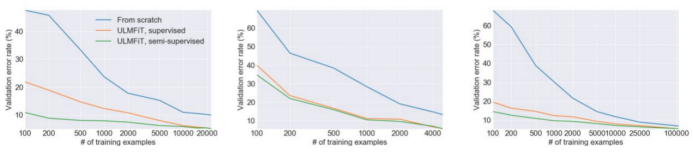
从零开始训练的模型(蓝色)与分别调整了标记目标数据(橙色)和未标记目标数据(绿色)的两个预训练模型的性能
2.扩大预训练
通常可以通过同时增加模型参数和预训练数据量的方式来改善预训练表征。但随着预训练数据量的增加,收益开始减少。然而,当前的性能曲线(例如下面的曲线)并不表示已经达到了平稳状态。因此,我们用更多数据可以训练出的更大的模型。
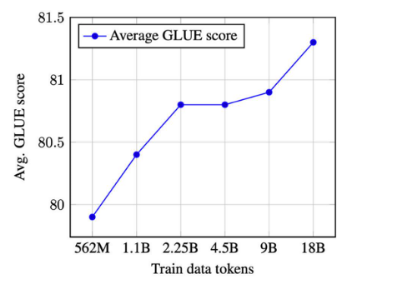
使用不同数量的常用爬网数据进行预训练的平均 GLUE分数
这种趋势的最新例子是 ERNIE 2.0, XLNet, GPT-2 8B和 RoBERTa。后者特别发现,简单地对BERT进行更长时间和更多数据的训练可以改善结果,而GPT-2 8B减少了语言建模数据集上的困惑(尽管只是相对较小的因素)。
3.跨语言预训练
预训练的一个主要承诺是,它可以帮助我们弥合数字语言鸿沟,并使我们能够学习全球6,000多种语言中的NLP模型。跨语言学习的许多工作都集中在训练不同语言中不同的单词嵌入,并学习如何使其对齐。同样,我们可以学习对齐上下文表示。另一种常见的方法是共享一个子词词汇表,并在多种语言上训练一个模型。虽然这很容易实现并且是强大的跨语言基线,但它会导致低资源语言的代表性不足,特别是最近备受关注的多语言BERT。尽管其有强大的零样本性能,但专用的单语语言模型往往更具有竞争力,同时效率更高。
为了使预训练的模型适应目标任务,我们可以在几个正交的方向上做出决策:架构修改,优化方案以及是否获得更多信号。
4.架构的修改
对于架构修改,我们有两个常规选项:
a)保持预训练模型的内部不变。这就像在预训练模型的顶部添加一个或多个线性层一样简单,通常是在BERT上完成的。相反,我们也可以使用一个模型的输出作为另一个不同的模型的输入,这在目标任务需要交互时通常是有益的,尽管这些交互在预训练嵌入中是不可用的。例如跨度表示或跨句关系建模( span representations or modelling cross-sentence relations)。
b)修改预训练模型的内部架构. 这样做的原因之一是适应结构上不同的目标任务,例如具有多个输入序列的任务。在这种情况下,我们可以使用预训练模型来尽可能多地初始化结构上不同的目标任务模型。还可以应用于特定任务的修改,例如添加跳过、剩余连接或注意(residual connections or attention)。最后,修改目标任务的参数可能会减少那些需要通过在预训练模型的各层之间添加瓶颈模块(“适配器”)来进行微调的参数的数量。
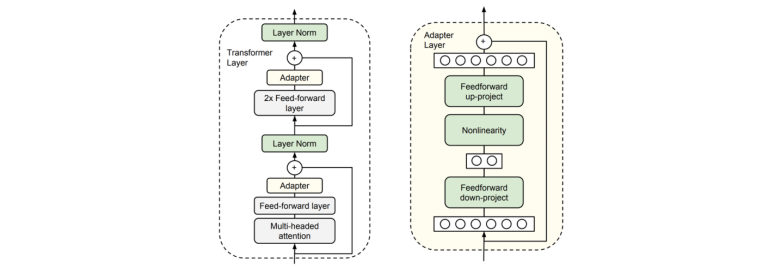
在Transformer块(左)中使用的适配层(右)
5.优化方案
在优化模型方面,我们可以决定应该更新的权重以及如何、何时更新这些权重。
a)哪些权重需要更新?至于权重更新,我们可以选择调整或不调整(预训练的权重):
不要更改预训练权重(特征提取)。在实践中,线性分类器在预训练表示的基础上进行训练。最佳性能往往是通过同时使用顶层的向量表示和学习层向量表示的线性组合。或者,可以将预训练表征用作下游模型中的特征。添加适配器时,仅训练适配器层。
更改预训练权重(微调)。将预训练后的权重用作下游模型参数的初始化。然后在适应阶段对整个预训练的架构进行训练。
时间上逐步进行(冻结)。对不同分布和任务的数据同时训练所有层可能会导致不稳定、不好的结果。所以,我们分别训练每一层,使它们有时间适应新的任务和数据。这可以追溯到早期深度神经网络的分层训练。最近的方法大多在一起训练的训练层的组合上有所不同,最后所有参数共同训练。对于Transformer模型,尚未对解冻(Unfreezing)进行详细研究。
强度逐步提高(较低的学习率) 。我们希望使用较低的学习率以避免覆盖有用的信息。较低的学习率在较低层(因为它们可以捕获更多的一般信息)、训练早期(因为模型仍需要适应目标分布)和训练后期(模型接近收敛时时)尤为重要。为此,我们可以使用区分性微调,这会降低每一层的学习率,如下所示。为了在训练初期保持较低的学习率,可以使用三角学习率计划表,在 Transformers中也称为学习率预热。Liu等人(2019)最近提出预热可以减少训练初期的差异。
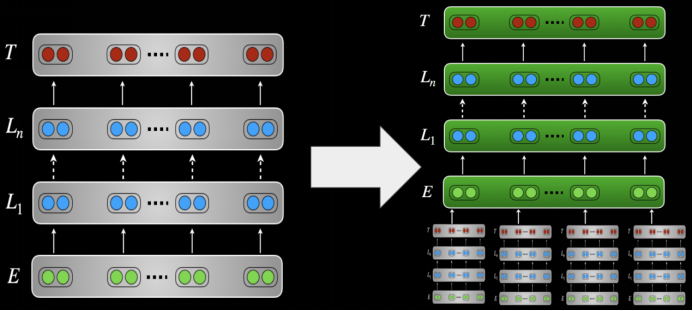
使用预训练模型作为单独的下游模型中的特征
b)如何以及何时更新权重?研究如何及何时更新权重主要是为了避免有用的预训练信息被覆盖,并最大限度地增加正向转移。与此相关的是灾难性遗忘的概念,如果模型忘记了最初训练的任务,就会发生这种情况。在大多数设置中,我们只关心目标任务的性能,但这也因应用程序而异。
更新我们的模型参数的指导原则是在时间上、强度上或与预先训练的模型相比,从上到下逐步更新它们。
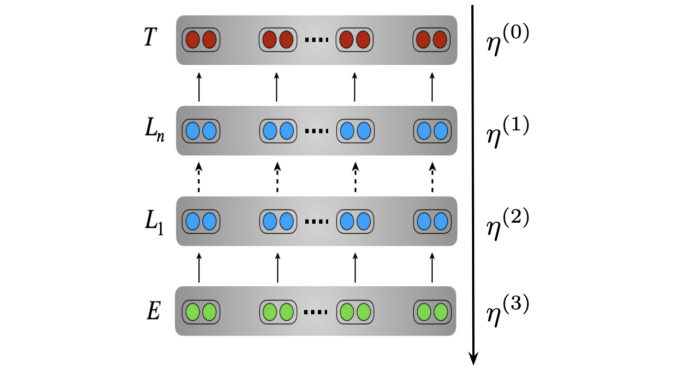
区分性微调
c)渐进式与预训练模型的比较(正则化)。最小化灾难性遗忘的一种方法是使用正则化术语鼓励目标模型参数保持与预训练模型的参数接近。
通常,需要从头开始训练的参数越多,训练的速度就越慢。特征提取需要添加比微调更多的参数,因此通常训练较慢。但是,当模型需要适应许多任务时,特征提取会更节省空间,因为它只需要在内存中存储一个预训练模型的副本即可。适配器通过为每个任务添加少量附加参数来达到平衡。
在性能方面,没有一种适应方法在每种情况下都明显优越。如果源任务和目标任务不同,则特征提取似乎更可取。否则,特征提取和微调通常会执行类似的操作,尽管这取决于可用于超参数优化的预算(微调通常需要更广泛的超参数搜索)。与LSTM相比,Transformers更易于微调(对超参数不太敏感),并且通过微调可以获得更好的性能。
但是,大型预训练模型(例如BERT-Large)在对具有小型训练集的任务进行微调时,容易降低性能。在实践中,观察到的行为通常是“开-关”:如下图所示,该模型要么运行良好,要么根本不运行。理解这种行为的条件和原因是一个开放的研究问题。
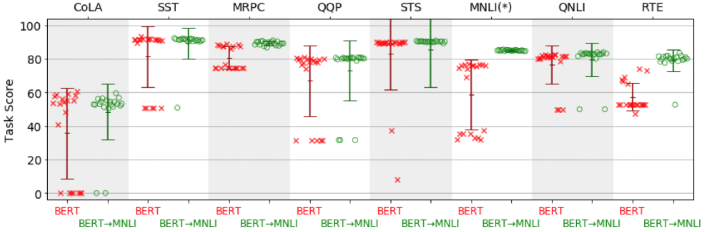
当对每个任务进行不超过5k个示例的微调时,BERT(红色)和BERT在MNLI(绿色)上进行微调的20个随机重启中的任务得分分布
6.获得更多信号
目标任务通常是低资源任务,我们往往可以通过组合一组不同的信号来提高迁移学习的性能:
a)顺序适应。如果有相关任务可用,我们可以先用更多数据微调相关任务的模型,然后再对目标任务进行微调。这有助于数据有限和任务类似的任务,且提高了目标任务的采样效率。
b)多任务微调。另外,我们还可以在相关任务和目标任务上共同微调模型。相关任务可以是无监督的辅助任务。语言建模是一个很好的选择,即使没有预训练也可以提供帮助。可以选择性的对任务比率进行退火,以在训练结束时降低辅助任务的重要性。语言模型微调在ULMFiT中用作单独的步骤,近来,即使有许多目标任务,多任务微调也带来了改进。
c)数据集切片。我们可以使用仅在数据的特定子集上受训的辅助磁头,而不是对辅助任务进行微调 。为此,我们将首先分析模型的误差,使用启发式算法自动识别训练数据的具有挑战性的子集,然后与主磁头一起训练辅助磁头。
d)半监督学习。我们还可以使用半监督学习方法,通过扰动未标记的示例来使模型的预测更加一致。扰动可以是噪声,掩蔽或数据扩充,例如反向翻译。
e)集成。为了提高性能,可以结合使用不同的超参数微调模型、使用不同的预训练模型或针对不同目标任务或数据集分割进行训练的模型的预测。
f)提炼。最后,可以将大型模型或模型集合提炼为单个较小的模型。该模型可以简单得多或具有不同的归纳偏差。多任务微调也可以与提炼结合使用。
未解决的问题和未来方向。
1. 预训练语言模型的缺点。预训练语言模型仍然不擅长细粒度的语言任务、层次句法推理和常识(当你把问题弄得复杂时)。它们仍然无法生成自然语言,特别是无法保持长期的依存性、关联性和连贯性。当进行微调时,它们也倾向于过渡到表层形式的信息,并且仍然可以被视为“快速表层学习者”。如上所述,特别是对少量数据进行微调的大型模型难以优化,而且存在高度的差异性。当前的预训练语言模型也非常庞大。提炼和修剪是处理此问题的两种方法。
2. 虽然语言建模目标已经证明在经验上是有效的,但它也有其缺点。最近,我们发现双向上下文和对连续单词序列进行建模特别重要。也许最重要的是,语言建模鼓励将重点放在语法和单词共现上,并且仅提供了一个微弱的信号来捕获语义和长期语境。我们可以从其他形式的自我监督中获得启发。此外,我们可以设计专门的预训练任务来明确学习某些关系。总体而言,从原始文本中学习某些类型的信息是困难的。最近的方法将结构化知识或利用多种模式作为缓解此问题的两种潜在方法。
(王宇飞编译,张梦婷校对)
DeepPavlov:一个端对端的对话系统和聊天机器人的开源库
这篇文章解释了如何利用DeepPavlov开源库开发聊天机器人,以及为什么在这个开发过程中TensorFlow 学习平台是一个不可或缺的工具。
DeepPavlov是由莫斯科物理技术学院MIPT(Moscow Institute of Physics and Technology)神经网络和深度学习实验室开发和维护。DeepPavlov是 TensorFlow 2.0挑战赛(#PoweredByTF 2.0 Challenge)的获奖作品。本文的代码可以在Google Colaboratory上访问。
在聊天机器人出现在几乎各行各业来简化人与电脑之间的交互的当下,对话系统已成为人机交互的标准,他们被整合到网站,信息平台和终端设备中。聊天机器人正在兴起,许多公司正在打算选择将日常的任务交给聊天机器人而不是人类,从而能够节省大量的劳动力成本。与人类不同的是,聊天机器人拥有能够二十四小时同时处理多个用户请求的能力。
尽管如此,许多公司在开展适合他们业务需求的机器人时都不知如何开始。从过去来看,聊天机器人可以分为两大类:规则导向型和数据驱动型。前者依赖于预先给定的命令与模板,每个命令都应该由聊天机器人的开发人员用正规的表达式和文本数据分析来编写。相反的,数据驱动型的聊天机器人依赖于预训练对话数据的机器学习模型。
1.对话系统的构建
简单起见,我们从对话系统最基本的元素开始。首先,一个聊天机器人需要在自然语言下理解语音。自然语言理解(Natural Language Understanding (NLU))组件把用户问询从自然语言翻译为带标记的语义表述。例如,“Please set an alarm for 8 am”,这句话会被翻译为像“set_alarm(8 am)”这样的机器理解的形式。之后机器人需要决定人类期望它做什么。对话管理器(Dialogue Manager (DM))将会跟踪对话的状态并且决定如何回应用户。在最后一个阶段,自然语言生成器(Natural Language Generator (NLG))将机器语义表述翻译回人类语言。例如:rent_price(Atlanta)=3000 USD翻译为“The rent price in Atlanta is around $3,000.”从下图看以看到一个典型的对话系统架构。
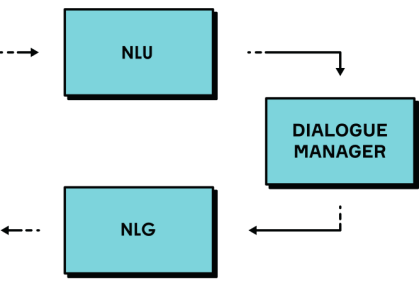
2.用DeepPavlov构建对话系统
开源对话式人工智能(AI)框架DeepPavlov为构建对话系统提供了一个免费好用的解决方案。DeepPavlov拥有几个预先定义的用于解决NLP相关问题的组件。这个框架允许您训练和测试模型,同时还能够微调超参数。
它支持Linux和Windows平台,Python 3.6, and Python 3.7。可以通过运行下代码安装DeepPavlov。
pip install -q deeppavlov
DeepPavlov模型在config文件夹中单独配置文件中定义。一个配置文件有五个主要部分构成:dataset_reader(数据集_读写器), dataset_iterator(数据集_迭代器), chainer(链接器), train(训练), metadata(元数据)。dataset_reader定义了数据集的位置和格式。加载之后,将会按照dataset_iterator的设定在训练集(train sets),验证集(validation sets)和测试集(test sets)之间分配数据。配置文件的链接器部分(chainer)由三个子部分组成,在输入部分(in)和输出部分(out)定义链接器的输入和输出,在管道部分(pipe)定义与模型交互所必要的组件的管道。元数据部分描述了随着模型变量变化的模型需求。
可以通过命令行界面(command-line interface (CLI))与在配置文件中定义的模型交互。但是,在使用任何模型之前,应该运行安装命令来安装它的所有必要组件。模型的依赖关系定义于配置文件中的这些必要组件部分。
代码中
代码中-d表示下载所需的数据,例如预训练的模型文件和嵌入。可以通过选取训练参数(train parameter)运行代码来训练模型。模型将会在配置文件里数据集_读写器定义的数据集下训练。python -m deeppavlov train
DeepPavlov框架允许测试你的数据上所有可用的模型,以确定性能最佳的那一个模型。要测试模型,请在测试文件的dataset_iterator(数据集_迭代器)部分具体指定数据集拆分方式以及拆分字段。
python -m deeppavlov test
另外你可以使用riseapi命令执行DeepPavlov来运行具有对模型具有对模型API访问权限的服务器
python -m deeppavlov riseapi
你可以在我们的帮助文档(https://github.com/deepmipt/DeepPavlov)中找到更多运行命令
3.一个不可或缺的工具
TensorFlow是用于机器学习的端到端开源平台,它是开发DeepPavlov时必不可少的工具。
从TensorFlow 1.4.0开始, Keras就是核心API的一部分
Keras是一个高级API,它降低了深度学习入门的门槛。Keras在TensorFlow上提供了一个高级抽象层,使我们可以把精力更多放在问题本身和超参数调整上。DeepPavlov的大多数文本分类模型都是通过Keras抽象实现的。Keras为我们提供了快速虚拟样机建模技术,可用于快速尝试各种神经网络架构和调整超参数。
此外,TensorFlow的灵活性使我们能够构建我们可以想到的任何神经网络架构,包括但不限于序列标记和问题解答。具体来说,我们使用TensorFlow与基于BERT的模型进行无缝集成。
我们已经实现了基于BERT的英语和多种语言模型的文本分类,命名实体识别(NER)和问题解答。另外,TensorFlow的灵活性使我们能够在我们的数据上构建BERT。这就是我们如何在对话数据中训练BERT来使它在社交网络的输出中有更好的表现的方式。
TensorFlow的另一个巨大优势是TensorBoard。您可以使用TensorBoard来可视化TensorFlow图,绘制指标并显示其他数据。TensorBoard允许我们检查模型并在调试它们时进行适当的更改。这有助于更好地理解机器学习模型。
4.DeepPavlov产生的成果
DeepPavlov带有由TensorFlow和Keras支持的几个预定义组件,用于解决与NLP相关的问题,包括文本分类,命名实体识别(NER),问题回答等。如今,通过应用BERT的模型,许多任务已经有了最新成果。BERT的发布使2018年成为自然语言处理的拐点。BERT是基于transformer的语言表示预训练技术。我们将BERT集成到三个下游任务中:文本分类,命名实体识别(和一般的序列标记)以及问题解答。结果,我们在这些任务中都实现了非常可观的改进。在接下来的小节中,我会详细描述如何使用DeepPavlov的基于BERT的模型。这些代码可以在Google Colab中访问。https://colab.research.google.com/github/deepmipt/dp_notebooks/blob/master/DP_tf.ipynb
BERT的文本分类模型
我们使用侮辱性词汇检测问题来演示DeepPavlov中基于BERT的文本分类模型。它涉及预先推断在公开讨论中发布的一条评论是否会被视作对其中一个参与者的侮辱。这是一个只有侮辱和非侮辱两类二元分类问题。
任何预训练的模型都可以通过命令行界面(CLI)或Python来进行推断。使用模型之前,请确保使用以下命令安装了所有必需的软件包:
python -m deeppavlov install insults_kaggle_bert
python -m deeppavlov interact insults_kaggle_bert -d
您可以通过Python代码与模型进行交互。
from deeppavlov import build_model, configs
model = build_model(configs.classifiers.insults_kaggle_bert, download=True)
model(['hey, how are you?', 'You are so dumb!'])
您可以根据自己的数据训练基于BERT的文本分类模型。为此,请在配置文件的dataset_reader(数据集_读写器)部分中修改data_path(数据集路径)参数。
然后在CLI中训练模型:
python -m deeppavlov train my_text_classification_config.json
或通过Python:
from deeppavlov import train_model, configs
model = train_model(configs.classifiers.my_text_classification_config)
您可以在the-bert-based-text-classification-models-of-deeppavlov阅读有关基于BERT的文本分类模型的更多信息,并可以在我们的演示demo.deeppavlov.ai中对其进行测试。
BERT的命名实体识别模型(NER)
除了文本分类模型外,DeepPavlov还包含基于BERT的命名实体识别(NER)模型。这是NLP中最常见的任务之一。具体来说是这样的过程:给定一系列tokens(单词,标点符号),为序列中的每个tokens提供来自预定义标签集的标签。NER有多种商业用途。例如,它可以从简历中提取重要信息,以方便人力资源专业人员对其进行评估。此外,NER可用于识别客户请求中的相关实体,例如产品规格,公司名称或公司分支机构的详细信息。
我们在OntoNotes英语语料库上训练了我们的NER模型,该语料库在标记模式中有19种类型,包括PER(人),LOC(位置),ORG(组织)以及许多其他类型。为了与模型进行交互,请首先安装其需求文件。
python -m deeppavlov install ner_ontonotes_bert_mult
python -m deeppavlov interact ner_ontonotes_bert_mult [-d]
然后,您可以通过Python代码与模型进行交互。
from deeppavlov import configs, build_model
ner_model = build_model(configs.ner.ner_ontonotes_bert_mult, download=True)
ner_model(['World Curling Championship will be held in Antananarivo'])
多语言BERT(M-BERT)模型可实现语言之间的零镜头传输,这意味着您可以在非英语句子上测试该模型,即使该模型是在英语OntoNotes上进行训练的,例如:
from deeppavlov import configs,build_model
ner_model = build_model(configs.ner.ner_ontonotes_bert_mult, download=True)
ner_model([
"Meteorologist Lachlan Stone said the snowfall in Queensland was an unusual occurrence in a state with a sub-tropical to tropical climate.",
"Церемония награждения пройдет 27 октября в развлекательном комплексе Hollywood and Highland Center в Лос-Анджелесе (штат Калифорния, США).",
"Das Orchester der Philharmonie Poznań widmet sich jetzt bereits zum zweiten Mal der Musik dieses aus Deutschland vertriebenen Komponisten. Waghalter stammte aus einer jüdischen Warschauer Familie."])
您可以在本文中阅读有关NER模型的更多信息。此外,您可以在我们的演示中查看NER模型。demo.deeppavlov.ai
BERT的问答模型
基于上下文的问题回答是在给定的上下文(例如,来自Wikipedia的段落)中找到问题答案的任务,其中,每个问题的答案都是上下文的一部分。例如,下面给出的【上下文,问题,答案】构成了基于上下文的问题回答任务的三元组。
内容:
在气象学中,降水是大气水蒸气在重力作用下凝结的任何产物。降水的主要形式包括毛毛雨,雨,雨夹雪,雪,霰和冰雹。降水在较小的水滴在云中的其他雨滴或冰晶碰撞而聚结的过程中形成。在分散的位置短暂而强烈的降雨被称为“阵雨”。
问题:
水滴在哪里与冰晶碰撞形成降水?
回答:
在云中
问答系统可以使商业活动中的许多流程自动化。例如,它可以帮助雇主基于公司内部的文件获得答案,它还可以帮助老师在教学过程中检查学生的阅读理解能力。近来,基于上下文的问答任务在学术界引起了很多关注。斯坦福问答数据集是该领域的主要里程碑之一((SQuAD))的发布。这是一个由大众工作者对一组维基百科文章提出的问题组成的全新的阅读理解数据集,SQuAD数据集催生了无穷无尽的方法来解决问答问题。最成功的方法之一便是基于BERT的问题回答模型。该模型优于其他所有模型,目前可提供与人类相差无异的回答结果。
为了在DeepPavlov中使用基于BERT的问答模型,请首先安装其需求文件。
python -m deeppavlov install squad_bert
然后,您可以按以下方式与模型进行交互:
python -m deeppavlov interact squad_bert -d
然后,您可以通过Python代码使用模型
多语言BERT模型使得我们只需在英语SQuAD数据集上进行训练就可以构建多语言问题回答系统。多语言QA支持用于训练M-BERT的所有104种语言。您可以按以下方式使用它:
from deeppavlov import build_model, configs
model_qa_ml = build_model(configs.squad.squad_bert_multilingual_freezed_emb, download=True)
context_en = "In meteorology, precipitation is any product of the condensation of atmospheric water vapor that falls under gravity. The main forms of precipitation include drizzle, rain, sleet, snow, graupel, and hail. Precipitation forms as smaller droplets coalesce via collision with other raindrops or ice crystals within a cloud. Short, intense periods of rain in scattered locations are called showers."
context_fr = "Les précipitations désignent tous les météores qui tombent dans une atmosphère et il peut s'agir de solides ou de liquides selon la composition et la température de cette dernière. Ce terme météorologique est le plus souvent au pluriel et désigne sur la Terre les hydrométéores (cristaux de glace ou gouttelettes d'eau) qui, ayant été soumis à des processus de condensation et d'agrégation à l'intérieur des nuages, sont devenus trop lourds pour demeurer en suspension dans l'atmosphère et tombent au sol ou s'évaporent en virga avant de l'atteindre. Par extension,le terme peut également être utilisé pour des phénomènes similaires sur d'autres planètes ou lunes ayant une atmosphère."
model_qa_ml([context_en, context_fr, context_fr],["Where do water droplets collide with ice crystals to form precipitation?", "Sous quelle forme peut être précipitation?","Where the term precipitation can be used?"])
正如你看到的那样,我们通过提供批量的上下文和批量的问题来调用模型,作为输出,模型返回了批量的从上下文中提取的结果及其起始位置。这段摘录代码演示了在英语数据集上进行训练的多语言QA模型,一旦它在一个英语数据集上受过训练,即使以其他语言提出问题,也能够从法语内容中提取答案。
多语言QA模型的跨语言可传递性的详细比较可以在一篇专门文章中找到。
(李朝安编译,王宇飞校对)
研究动态
谷歌全新精简版模型ALBERT刷新三大NLP基准
谷歌的“ ALBERT”语言模型在GLUE,RACE和SQuAD 2.0三大自然语言理解(NLU)基准测试上都得到了最新的SOTA结果。ALBERT是谷歌2018年提出的NLU预训练方法BERT的“精简版”。研究人员在ALBERT中引入了两种参数缩减技术,以降低内存消耗和提高训练速度。
为什么这项研究很重要?Transformer架构和BERT的创建与开发证明了大规模预训练模型在处理NLP任务(例如机器翻译和问题解答)方面的功效。研究人员通常在预训练阶段训练一个完整的网络,然后为下游应用定制较小的特定任务模型。
然而,当前的SOTA语言模型包含了数亿甚至数十亿个参数,故而扩展此类模型会受到GPU或TPU等计算硬件内存的限制。此外,研究人员发现增加BERT-large模型中的隐藏层数会导致较差的性能。这些障碍促使谷歌深入研究能够减小模型规模而不影响性能的参数缩减技术。
核心创新:谷歌研究人员介绍了ALBERT的三项突出创新。
1.词嵌入向量参数的因式分解(Factorized embedding parameterization)
首先将独热向量(one-hot vector)映射到较低维的嵌入空间(embedding space),然后映射到高维的隐藏空间(hidden space),从而将隐藏层的规模与词汇嵌入的规模分离开来。这种分离使得在不显著增加词汇嵌入参数数量的情况下,更容易扩大隐藏层的规模。
2.跨层参数共享(Cross-layer parameter sharing)
跨层共享所有参数可以防止参数随网络深度的增大而增大,因此与BERT-large模型相比,大型ALBERT模型的参数要少18倍。
3.句间连贯性损失(Inter-sentence coherence loss)
谷歌在BERT论文中提出了next-sentence prediction技术来提高模型在下游任务中的性能,但后续的研究发现该技术效果并不理想。在ALBERT中,研究人员利用句子顺序预测(SOP,sentence-order prediction)的自监督损失对句间连贯性进行建模,这使新模型在多句子编码任务中能够更稳健地执行。
数据集:将BOOKCORPUS和English Wikipedia作为预训练基准模型,总共包含约16GB的未压缩文本。
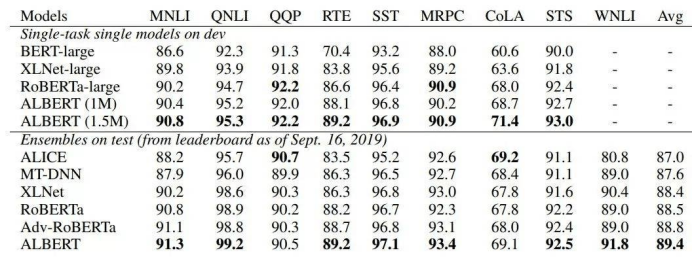
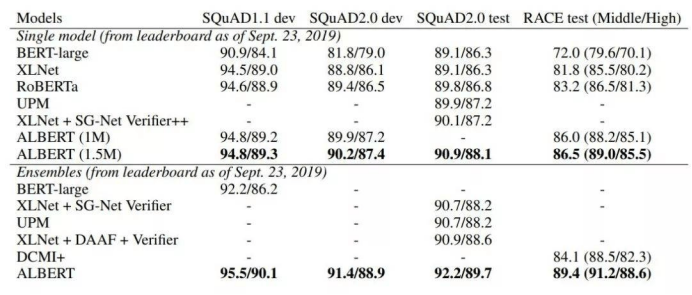
实验结果:在SQuAD1.1,SQuAD2.0,MNLI SST-2和RACE语言基准测试上,ALBERT模型明显优于BERT模型。
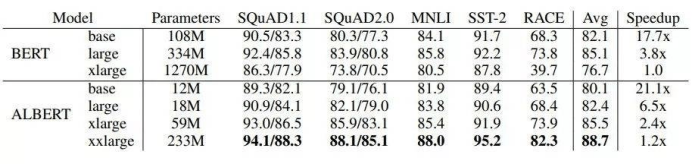
至于前文所述的三大自然语言基准测试的结果,ALBERT的单模型和集成模型都有所改进,其中GLUE得分为89.4,SQuAD 2.0测试F1得分为92.2,RACE测试的精度得分为89.4。
(张梦婷编译,王宇飞校对)
IBM的Lambada AI能为文本分类器生成训练数据
在缺乏足够的数据来训练机器学习模型的情况下,IBM的研究人员主张使用合成数据。他们使用了一个经过预训练的机器学习模型人工合成了新的标签数据,并将其用于文本分类任务。他们称之为基于语言模型的数据扩充(Language-model-based data augmentation)(简称Lambada),它可以提高分类器在各种数据集上的性能,并显著改善了最新的数据扩充技术。
该论文的合著者表明若想很好地适应分类器模型,可能需要大量的标记数据。然而许多情况下,尤其是在为特定应用开发AI系统时,标签数据稀缺且获取成本很高。研究者指出在文本域中生成合成训练数据比在视觉域更具挑战性,因为在更简单的方法中使用的转换通常会使文本失真,使其在语法和语义上不正确。因此,大多数文本数据扩充技术都存在涉及用同义词替换单个单词、删除单词或改变单词顺序的问题。
Lambada利用了生成模型(OpenAI的GPT)对大型文本进行了预训练,使其能够获取语言结构,从而产生连贯的句子。研究人员在现有的小型数据集上微调了他们的模型,并使用微调后的模型来合成新的带标签句子。他们在上述数据集上独立地训练分类器,并让它过滤合成语料库,在对现有和合成数据进行分类器重新训练之前,仅保留看起来“足够定性”的数据。
为了验证他们的方法,研究人员通过运行实验在三个数据集上测试了三种不同的分类器——BERT、支持向量机和长短期记忆网络(LSTM),对每个类别都改变训练样本。所涉及的语料库包含有关航班相关信息的查询、若干类别的开放域和基于事实的问题,以及来自电信客户支持系统的数据。
他们表明Lambada在小数据集上静态地提高了三个分类器的性能,这部分归功于其对每个类别的样本数量的控制。这些控制使他们能够投入更多的时间来为原始数据集中代表性不足的类生成样本。他们还表示他们的扩充框架不需要其他未标记的数据,并且对于大多数分类器而言,Lambada的准确性比简单的弱标记方法高。即相比于从原始数据集中获取的样本,生成的数据集更能提高分类器的准确性。
(张梦婷编译,王宇飞校对)
Facebook研究表明预训练AI模型可以轻松适应新语言
Multiligual masked language model是对多种语言文本进行训练的模型。语言建模领域的大多数前期工作都在研究单语数据集上共享词汇的跨语言迁移。Facebook的研究人员则是开始探索是否可以通过来自截然不同领域的文本来实现语言知识迁移。
在本周于Arxiv上发表的一篇论文中,Facebook AI和普金斯大学的科学家详细描述了不同masked language model的预训练方法对跨语言迁移的影响。他们发现即使只有一小部分参数(有助于控制整体模型性能的变量)是共享的,在没有任何共享词汇或领域相似性的预训练模型中也会出现通用表征,。他们声称仅通过共享参数,预训练就可以将相似的单词和句子映射到相似的隐藏表征(hidden representations)。
该团队认为参数共享是性能中最重要的因素,并且单词级别、上下文单词级别和句子级别的AI模型表征确实可以与简单的映射保持一致。最后一个发现则提供了关于为何仅参数共享就足以使多语言表征出现在multilingual masked language models中的见解。
该论文的合著者发现与同一语言上限相比,用不同语言训练的单语模型在没有相同参数的情况下,彼此之间的学习表征也对齐得很好。这表明在不增加额外训练的情况下使预训练模型适应新语言是有可能的,此外,未在所有可收集的无标记数据上进行联合训练,而能很好地对齐独立训练过的表征也是有可能的。
在一项相关的开发中,Facebook展示了一种机器学习系统(Polyglot),该系统可以在给定语音数据的情况下以多种语言生成新的语音样本。该工作建立在Facebook广泛的自然语言处理工作的基础上,其中word2vec模型使用原始音频来提高语音识别能力,而其自我监控模型ConvLM可以在其训练词典以外的地方高精度地识别单词。2018 年,谷歌发布了基于双向 Transformer 的大规模预训练语言模型 BERT,刷新了 11 项 NLP 任务的最优性能记录,为 NLP 领域带来了极大的惊喜。很快,BERT 就在圈内普及开来,也陆续出现了很多与它相关的新工作。
(张梦婷编译,王宇飞校对)
实现文本动画化的计算机模型
一种新的计算机模型能够直接将描述身体运动的文本编译为简单的计算机生成动画。科学家们在使计算机理解自然语言,以及利用一系列身体姿势来创建逼真动画的领域取得了巨大的进步,但是由于缺少自然语言和身体姿势之间的联系,有时这些功能看起来像是存在于不同的世界。
研究人员正致力于使用一种语言-姿势联合神经架构将自然语言和身体姿势这两个领域结合起来,他们称之为JL2P(Joint Language-to-Pose)。JL2P模型使研究人员能够同时嵌入语句和姿势,从而可以学习语言与动作、手势、运动之间的关系。
为了创建JL2P模型,LTI(Language Technologies Institute)博士生 Chaitanya Ahuja使用了一种“课程-学习”的方法,该方法将问题聚焦于先学习短而容易的序列(“向前走”),然后学习更长、更困难的序列(“向前走,然后转身再向前走”或者“跑步时跳过障碍”)。Ahuja用动词和副词描述动作及其速度/加速度,而用名词和形容词描述位置和方向,最终目标是让复杂的序列生成动画,使其同时或依次发生多个动作。但目前动画仅适用于简笔画。
卡耐基梅隆大学语言技术研究所副教授Louis-Philippe Morency认为更复杂的情况是大量事件的同时发生,即使它们是以简单的顺序发生的。并且身体各部分之间的同步非常重要,在每次移动腿部时,也移动了胳膊、躯干、可能还有头部。身体动画需要协调这些不同的部位,同时实现复杂的动作。在这种复杂的动画环境中引入语言叙述是通往更好地理解语音和手势的途径。
(张梦婷编译,李朝安校对)
GitHub启动安全实验室保护开放源代码
GitHub今天启动了GitHub安全实验室,旨在汇集来自Google、Microsoft、Mozilla、Oracle、Uber、HackerOne等合作组织的安全研究人员。许多开源项目形成了现代软件的底层基础设施,例如Ruby和Python之类编程语言,TensorFlow之类的机器学习框架,无容器应用程序的Kubernetes,以及Microsoft的Visual Studio Code(GitHub上最受欢迎的开源存储库)。
GitHub表示,它已使用CodeQL语义代码分析引擎在带有自定义查询的流行开源项目中发现了100多个漏洞,并且发布了安全公告(Security Advisories),为安全研究提供一种申请常见漏洞和暴露(Common Vulnerabilities and Exposures,CVE)的方法。完成后,咨询将发送到受影响的项目,并记录在GitHub咨询数据库和Security Advisory API中。GitHub还首次推出了北极代码库(Arctic Code Vault),这是一项在挪威永久冻土上保存开放源代码数千年的举措,使语义代码搜索可用于Python、Go和Ruby存储库。
(张梦婷编译,王宇飞校对)
项目工具
Google T5探索迁移学习的局限性
一个Google研究小组最近发表了一篇论文,探讨了使用统一的文本到文本转换器的迁移学习的局限性,并介绍了一种新颖的“文本到文本的迁移转换器”(T5)神经网络模型,该模型可以将任何语言问题转化为文本到文本格式。T5模型展示了GLUE,SQuAD和CNN / Daily Mail数据集的最新性能。并且在SuperGLUE语言基准测试中获得了令人印象深刻的88.9分,仅比人类89.8分的基线低了几个百分点。
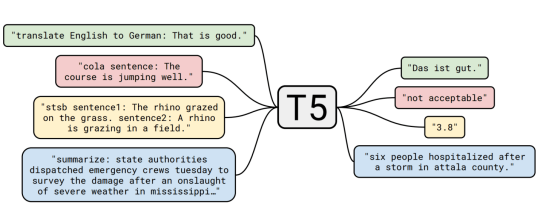
论文摘要:迁移学习是一种在自然语言处理(NLP)中强大的技术,在这种模型中,模型首先要针对数据丰富的任务进行预训练,然后再针对下游任务进行微调。迁移学习的有效性引起了方法,方法和实践的多样性。在本文中,我们通过引入一个统一的框架来探索NLP的转移学习技术的前景,该框架将每种语言问题都转换为文本到文本格式。我们的系统研究比较了数十种语言理解任务中的预训练目标,体系结构,未标记的数据集,传输方法和其他因素。通过将我们的探索性见解与规模相结合,以及我们新的“巨型清洁爬行语料库”,我们在许多基准上获得了最先进的结果,涵盖了总结,问题解答,文字分类等等。为了促进NLP迁移学习的未来工作,我们发布了数据集,预训练的模型和代码。(arXiv)
T5是一种非常庞大的新型神经网络模型,可对无标签文本(作者的大量新C4英语网络文本集合)和流行自然语言处理任务中的标签数据进行混合训练,然后针对每个他们旨在解决的任务。它是一个文本到文本模型:在训练过程中,该模型被要求生成新文本作为输出,即使对于通常被建模为分类和回归任务的训练任务,也是如此。输出要简单得多。
T5在20多个已建立的NLP任务上拥有最先进的技术。该列表包括GLUE和SuperGLUE基准测试中的大多数任务,这些任务已成为此类应用语言理解工作的主要进展指标之一。在许多这样的任务数据集上,T5的表现和人类工作人员的表现一样好,这表明T5可能达到了对指标进行处理的可能性的上限。
(李朝安编译,张梦婷校对)
百度发布带有联邦学习工具和更多功能的PaddlePaddle 1.6
百度的PaddlePaddle(PArallel分布式深度学习)是一个最初由百度的科学家们开发的,旨在将AI应用于内部产品,于2016年9月开源。从那时起,所提供的功能已经有了实质性的增长,到今天它已经获得了了21个旨在“改善可用性”和“加速广泛部署”人工智能的新功能。
增强功能中的主要功能可能是Paddle Lite 2.0,百度去年发布的Paddle Lite组件的第二代。它专为在移动设备,嵌入式设备和物联网设备上进行推断而设计,并且与PaddlePaddle模型和其他来源的预训练模型兼容。现在,Paddle Lite使开发人员可以使用大约七行代码来实现ResNet-50(一种流行的图像识别AI模型),并支持使用基于INT8数据类型的运算符下的矢量现场可编程门阵列(FPGA)和低精度推理。
在开发套件方面,PaddlePaddle现在总共包含四个工具:用于语义理解(NLP)的ERNIE,用于计算机视觉(CV)的PaddleDetection和PaddleSeg,以及用于推荐的Elastic CTR。作为一个迭代产品,ERNIE是一个通过多任务学习逐步获得知识的预训练语义理解框架,而PaddleSeg是一个支持从数据扩充到模块化设计的图像分割库。PaddleDetection是一个对象检测套件,已经升级增加了60多个模型。至于新发布的Elastic CTR,它提供参数部署预测并提供过程文档,以在Kubernetes(Google开源的一个容器编排引擎)上进行分布式培训。
PaddlePaddle 1.6还附带了一个新颖的框架-Paddle Graph Learning(PGL)-用于基于步行范式和基于消息传递范式的异构图学习,从而将PaddlePaddle支持的图学习模型的数量增加到13个。此外,还有PaddleFL联合学习框架,该框架利用开源FedAvg和基于隐私的差分SGD算法来实现分布式学习,使分布式学习能够在分散数据的语料库上进行模型训练。
新的PaddlePaddle包括EasyDL的升级版本,该平台已被65,000多家企业使用,通过交互界面在制造业、农业、服务业等行业构建169,000多种模型。EasyDL Pro(最新版本)是一站式开发平台,适合希望使用更少代码来部署算法的工程师。至于新的Master模式,它旨在帮助开发人员使用预训练的模型库和迁移学习的工具来更好地自定义任务模型。
(李朝安编译,张梦婷校对)
单芯片每秒1000万亿次运算:谷歌TPU原班团队全新AI架构,晶体管性能提升6倍
2016 年底,谷歌 TPU 团队的十位核心开发者中的八位悄悄离职,创办了一家名为 Groq 的机器学习系统公司。在此后的三年里,这家公司一直很低调。但最近,他们带着一款名为 TSP 的芯片架构出现在公众视野里。
TSP 的全称是 Tensor Streaming Processor,专为机器学习等 AI 相关需求打造。该架构在单块芯片上可以实现每秒 1000 万亿(10 的 15 次方)次运算,是全球首个实现该级别性能的架构,其浮点运算性能可达每秒 250 万亿次(TFLOPS)。在摩尔定律走向消亡的背景下,这一架构的问世标志着芯片之争从晶体管转向架构。
Groq 的 TSP 架构是专为计算机视觉、机器学习和其他 AI 相关工作负载的性能要求设计的。Groq 的架构还能用于广泛的工作负载。它的性能和简洁性使其成为所有高性能即数据和计算密集型工作复杂的理想平台。”
Groq 的这款架构受到软件优先(software first)理念的启发。它在 Groq 开发的 TSP 中实现,为实现计算灵活性和大规模并行计算提供了一种新的范式,但没有传统 GPU 和 CPU 架构的限制和沟通开销。
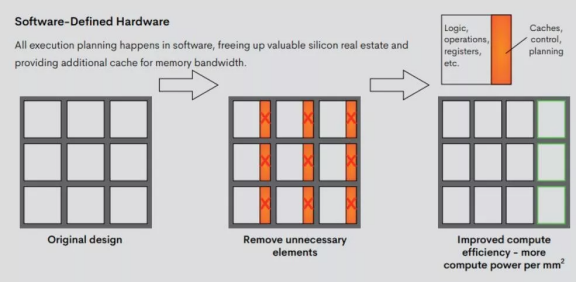
「软件优先」的硬件设计理念
在 Groq 的架构中,Groq 编译器负责编码所有内容:数据流入芯片,并在正确的时间和正确的地点插入,以确保计算实时进行,没有停顿。执行规划由软件负责,这样就可以释放出原本要用于动态指令执行的宝贵硬件资源。
这使得 Groq 的芯片性能具有确定性。编译器动态地重新配置硬件来执行每个计算,因此编译器和芯片之间没有抽象(abstraction)。由于编译器了解硬件和每条指令的速度,所以它可以准确地告诉硬件做什么,什么时候做。
开发人员可以在 Groq 芯片上运行相同的模型 100 次,每次得到的结果都完全相同。对于安全和准确性要求都非常高的应用来说(如自动驾驶汽车),这种计算上的准确性至关重要。
另外,使用 Groq 硬件设计的系统不会受到长尾延迟的影响,AI 系统可以在特定的功率或延迟预算内进行调整。
这种软件优先的设计(即编译器决定硬件架构)理念帮助 Groq 设计出了一款简单、高性能的架构,可以加速推理流程。
该架构既支持传统的机器学习模型,也支持新的计算学习模型,目前在 x86 和非 x86 系统的客户站点上运行。
更简单的架构设计
当前处理器架构的复杂性已经成为阻碍开发者生产和 AI 应用部署的主要障碍。当前处理器的复杂性降低了开发者工作效率,再加上摩尔定律逐渐变慢,实现更高的计算性能变得越来越困难。
Groq 的芯片设计降低了传统硬件开发的复杂度,因此开发者可以更加专注于算法(或解决其他问题),而不是为了硬件调整自己的解决方案。有了这种更加简单的硬件设计,开发者无需进行剖析研究(profiling),因此可以节省资源,更容易大规模部署 AI 应用。
与基于 CPU、GPU 和 FPGA 的传统复杂架构相比,Groq 的芯片还简化了认证和部署,使客户能够简单而快速地实现可扩展、单瓦高性能的系统。
让每个晶体管实现更高的性能
Groq 的张量流架构可以在任何需要的地方提供算力。与当前领先的 GPU、CPU 相比,Groq 处理器的每个晶体管可以实现 3-6 倍的性能提升。这一改进意味着交付性能的提升、延迟的下降以及成本的降低。使得Groq 的架构使用起来更加简单,而且性能高于传统计算平台。
(李朝安编译,张梦婷校对)
近期论文
ELECTRA: PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATORS
该论文目前在ICLR2020的双盲审阶段,尚不知道作者。
主要贡献:
1. ELECTRA提出了新的预训练任务和框架,把生成式的Masked language model(MLM)预训练任务改成了判别式的Replaced token detection(RTD)任务,判断当前token是否被语言模型替换过。
2. 解决了BERT中的不匹配问题,即网络在预训练用到了mask,但在对下游任务进行微调时却没有用到。
3. 模型从所有的输入tokens而不是仅仅被mask的小子集中学习,这使得它在计算上更有效率。
研究动机:
Masked language modeling (MLM)的预训练方法,如BERT,通过用mask替换一些tokens来破坏输入,然后通过训练一个模型来重建原来的tokens。虽然这在转移到下游NLP任务时有效,但它们通常需要大量的计算。(网络只从每个示例的15%的tokens进行学习,因此需要大量的计算成本)。
模型思路:
文章提出了一种更具样本效率的预训练任务,称为replaced token detection。文章使用的方法不是mask输入,而是用从小型生成器网络中取样的可信替代样本替换一些tokens,从而破坏了输入;然后训练一个判别模型来预测输入中的每个token是否被生成器样本替换,而不是训练一个模型来预测mask后的tokens。
模型架构:
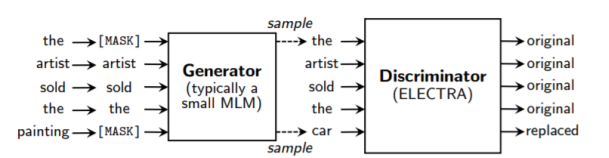
模型由生成器G 和判别器 D 组成。
输入的Tokens:
x=[x1,…,xn]
编码器对输入Token的上下文化的向量表示:
h(x)=[h1,…,hn]
生成器对位置 t 的 Token的Softmax层的表示:
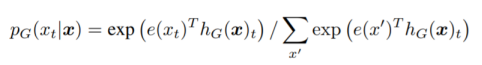
输入在模型中被mask替换的过程:
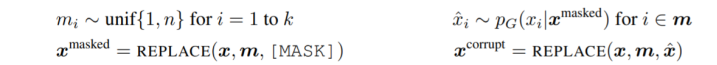
然后,判别器判断每个位置的Token是由生成器换过的还是原来的字:
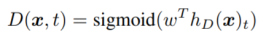
生成器及判别器的损失函数(极大似然估计和交叉熵):
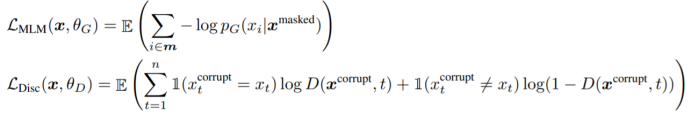
优化联合损失函数:
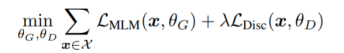
实验结果:
在相同的模型大小、数据和计算条件下,通过本文的方法学习的上下文表示大大优于通过BERT和XLNet等方法学习的上下文表示;小型模型的收益尤其强劲,例如,在一个GPU上训练一个模型4天,该模型在GLUE上的性能优于GPT(使用了30倍以上的计算进行训练)。该方法在大规模上也工作得很好,使用不到1/4的计算就可以达到RoBERTa的性能。
小细节:
Weight Sharing
作者认为在G模型生成任务中,G模型会对token的embedding层进行学习,从而得到更好的embedding,而D模型不会更新其embedding层,所以作者将两个模型的embedding层进行了共享。
Smaller Generators
生成器的大小在判别器的1/4到1/2之间效果是最好的,作者认为原因是过强的生成器会增大判别器的难度。
Training Algorithms
作者为ELECTRA提出了其他的训练算法,但这些算法并没有最终改善结果。
(王宇飞编译,李朝安校对)
近期会议
EMNLP 2019: Conference on Empirical Methods in Natural Language Processing
Dec 5 - Dec 7, 2019 中国 香港
EMNLP是自然语言处理领域的领先会议,由ACL语言数据特别兴趣小组(SIGDAT)组织。EMNLP于1996年成立,它是基于一个称为“大型语料库(WVLC)的研讨会”的较早的会议系列。根据Microsoft Academic Search的统计,截至2014年,EMNLP在计算机科学领域的现场评级为36,被引用计数为6937,均在CS领域排名前300。
ICAART 2020: International Conference on Agents and Artificial Intelligence
Feb 22 - Feb 24, 2020 马耳他 瓦莱塔
ICAART中有2条路线,一条与一般的Agent和Distributed AI相关,另一条与智能系统和计算智能相关。会议计划由几种不同类型的会议组成,例如技术会议,海报会议,主题演讲,教程,专题会议,博士联合会,小组和工业会议。会议上发表的论文可在SCITEPRESS数字图书馆中获得,并在会议记录中发表,并且一些最佳论文被邀请与Springer进行后期公开。
ICLR 2020: International Conference on Learning Representations
Apr 26 - Apr 30 ,2020 埃塞俄比亚 亚的斯亚贝巴
ICLR是每年春季举行的机器学习会议。自2013年成立以来,ICLR就采用了公开的同行评审程序来提交裁判论文(基于Yann LeCun提出的模型)。 2019年,有1591篇论文提交,其中500篇接受海报展示(31%),24篇接受口头演讲