相关项目
项目1:国家重点研发计划“基础科研条件与重大科学仪器设备研发”专项《科技文献内容深度挖掘及智能分析关键技术和软件》(2022YFF0711900)
项目网站:https://sciaiminer.las.ac.cn/
项目背景
科技文献蕴含人类知识、反映科研成果,是文献情报机构知识服务和情报分析的基础。项目针对文献情报机构迫切需要提升智能技术方法手段,将掩藏在海量科技文献中的深度知识内容有效挖掘出来并加以充分利用的重要问题,突破智能化关键技术,研发知识服务与情报分析自主软件。
总体目标
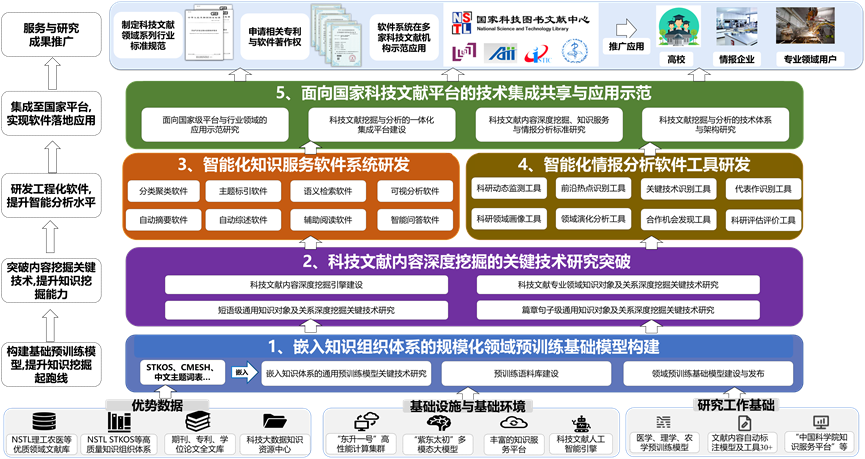
- 课题一:嵌入知识组织体系的规模化领域预训练基础模型构建
- 课题二:科技文献内容深度挖掘的关键技术研究突破
- 课题三:智能化知识服务软件系统研发
- 课题四:智能化情报分析软件工具研发
- 课题五:面向国家科技文献平台的技术集成共享与应用示范
主要研究内容
项目的研究重点是,突破科技文献内容深度挖掘和智能分析的关键技术,开发支撑科技文献知识服务和情报分析所需的自主软件系统,重点研究:嵌入知识组织体系的规模化领域预训练基础模型;科技文献内容深度挖掘的关键技术;智能化知识服务与情报分析软件研发;面向国家科技文献平台的技术集成共享与应用示范。
项目2:国家社会科学基金重大项目《大数据驱动的科技文献语义评价》(21&ZD329)
项目网站:https://scisemeval.las.ac.cn/
项目背景
当前科技评价体系尚无法深入到文献内容,无法对科技文献的众多细粒度指标进行评估,如尚无有效手段实现对研究过程的完善性、所做研究的价值大小、研究方法的合理性、取得成果的创新性等方面进行评估。
总体目标
- 课题一:大数据驱动的科技文献语义评价理论基础研究
- 课题二:大数据驱动的科技文献语义评价方法体系构建
- 课题三:大数据驱动的科技文献语义评价关键技术研究
- 课题四:大数据驱动的科技文献语义评价方法实证分析
主要研究内容
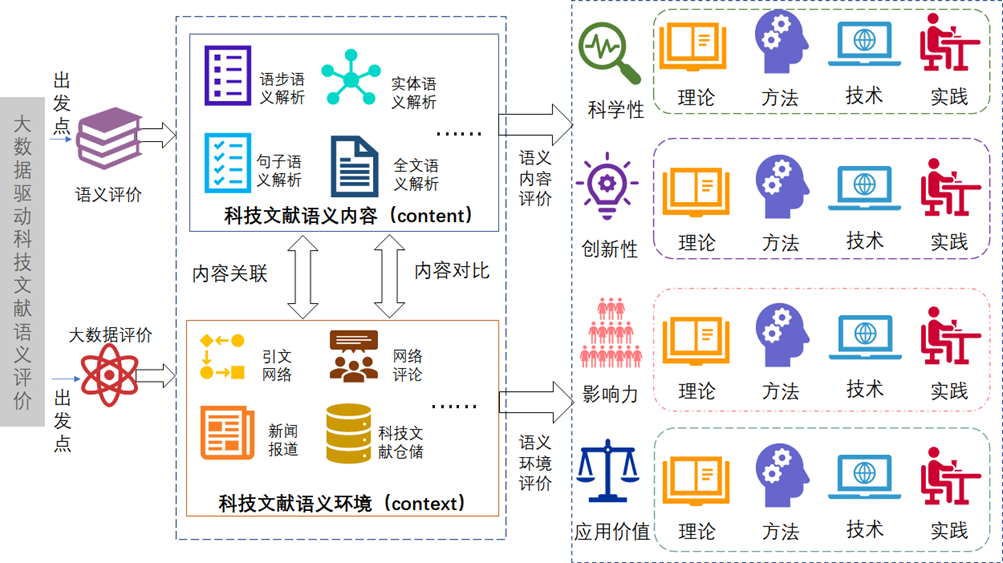
项目的总体思路是以科技文献为载体来评价科研成果或科研表现。具体而言,是以科技文献的语义内容和语义环境为基础,研究并突破基于语义要素的科技评价技术方法,研究构建“以科技创新质量、贡献、绩效为导向”的新型评价体系。

以大数据与语义两个关键要素为出发点,项目从待评价科技文献本身的语义内容与科技文献所处的外在语义环境层面,对科技文献内容从句子层面与短语层面进行解析。通过比较与对比,挖掘科技文献科学性、创新性、影响力和应用价值四个维度的特征,经过理论、方法、技术和实践四个步骤的研究,形成一套大数据驱动的科技文献语义评价体系。
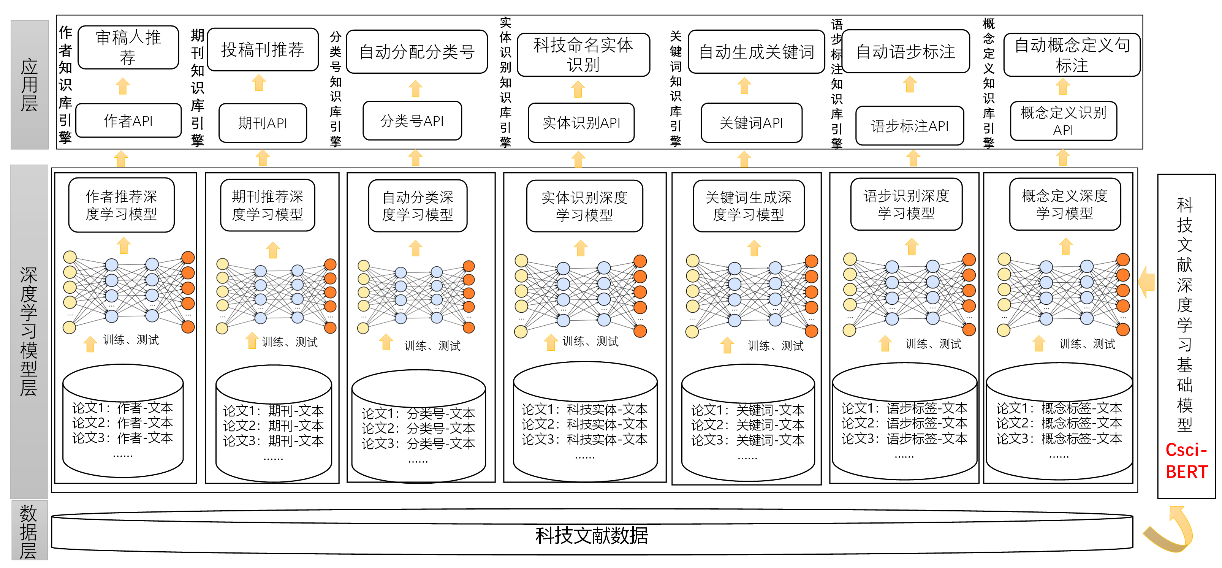
项目3:中国科学院文献情报能力建设专项《基于科技文献知识的人工智能(AI)引擎建设》
项目背景
隐藏于各类文献中的常识(或知识)是人工智能技术的重要基础,是人工智能飞速突破的本质所在。 数字图书馆中存在着丰富的科技文献资源,而这些科技文献资源是人类知识的最重要载体。 科技文献资源中蕴含着丰富的知识内容,如定义、概念,研究背景、研究问题、研究基础、研究思路、论文中应用到的理论工具和方法、论文所进行的科学试验、得到的实验结果、形成的研究结论等。对科技文献中的知识进行揭示是数字图书馆研究和建设人员的一项重要任务。
总体目标
- 建成并发布中国科技论文预训练基础语言模型(CsciBERT)
- 建成基于深度学习的科技文献知识引擎
主要研究内容
CsciBERT将利用大规模的科技文献文本内容,以自监督学习方式构建语言模型,建立起中文科技论文预训练语言模型。CsciBERT将作为面向全领域中文科技文献的通用预训练语言模型,针对不同学科领域的特定知识挖掘与分析需求,构建特定学科领域子语言模型。
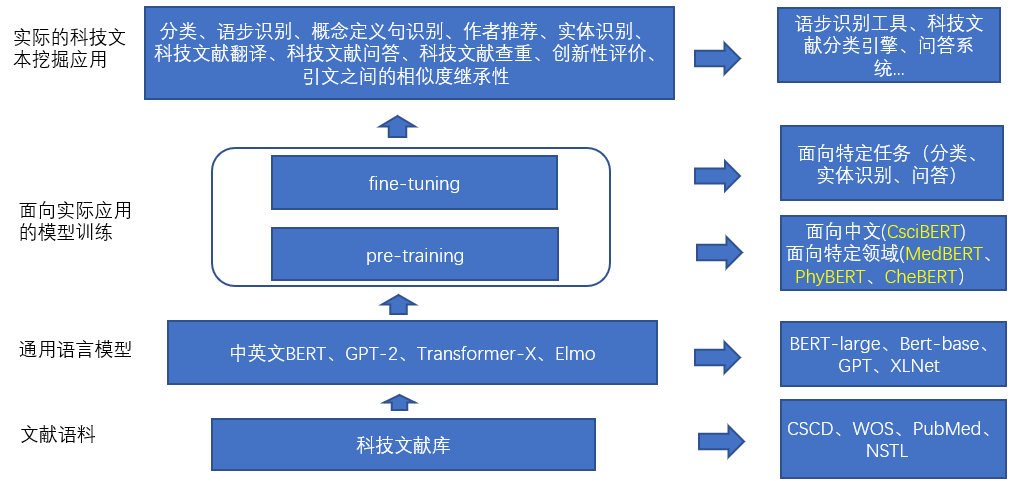
在完成构建中文科技论文预训练模型CsciBERT的基础上,项目将进一步针对文献情报工作的实际需求,充分挖掘科技文献资源,将科技文献库转化成为科技知识的引擎。
项目4:国家科技图书文献中心(NSTL)《下一代开放知识服务平台总体设计及关键技术研发专项--基于深度学习的科技论文语步标注技术工具研发》
项目背景
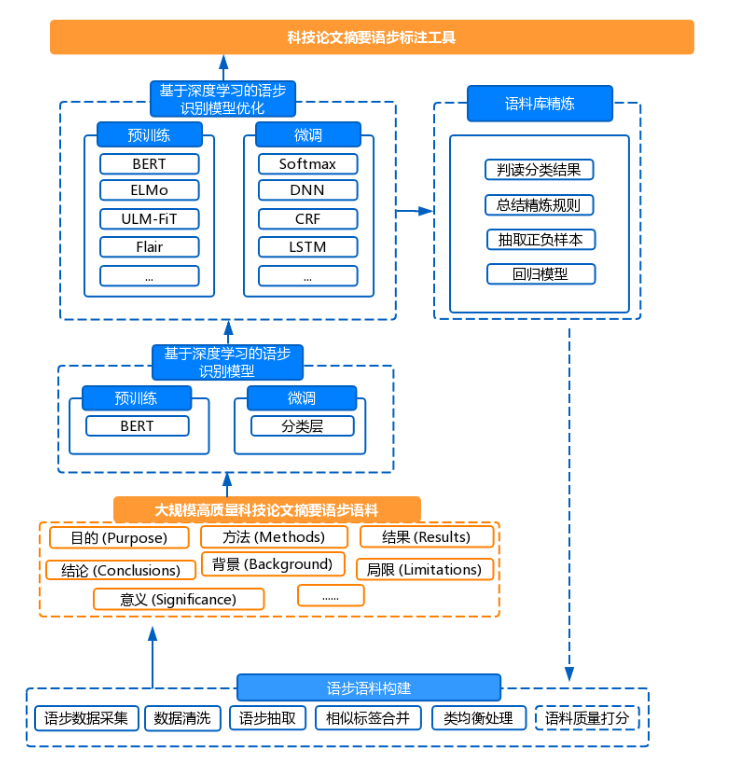
语步,也被称为修辞语步(Rhetorical Move),是文体学中的一个概念,最初由Swales提出,指实现完整交流功能的一个修辞单元(a rhetorical unit that performs a coherent communicative function)。 当前大多数期刊论文仍然在采用非结构化摘要,各个摘要的语步内容混杂在整个的摘要段落中,使读者不容易快速阅读和掌握这些非结构化摘要的相关语步内容。 自动识别科技论文非结构化摘要的语步,能够有效找出表达科技论文中研究目的、研究方法、研究结果以及研究结论的句子,使读者快速掌握科技论文的主要内容,对于揭示科技论文中的科学知识也具有重大意义。
总体目标
本课题承担下一代开放知识服务平台中的文本大数据分析子任务,通过实现语步自动标注,在句子层次上揭示海量科技文献中的知识内容,为下一代开放知识服务平台提供语步标注功能接口,从而有助于实现平台语义智能检索应用,有利于更加深层次地提供知识服务。
主要研究内容
为实现科技论文语步的自动识别,我们首先通过手机大规模的结构化摘要语料,构建了数据集。然后对比分析了各种深度学习方法在语步自动识别上的应用,针对当下效果最好的BERT模型,基于预训练+微调模型,完成模型优化改进,在语步识别上取得显著的效果提升。针对数据集质量问题,我们完成了语料库的精炼优化,进一步提升了语步识别的实际测试效果。针对实际应用场景,我们通过模型压缩和微服务的构建改善了深度学习模型的调用效率,形成了高效可用的语步识别工具。
项目5:中国科学院文献情报中心《科技文献丰富语义检索应用示范》
检索示范平台:物理领域科研论文自动语义标注检索系统
项目背景
丰富语义(Rich Semantics)相对于一般意义上的语义(Semantics)而言,是由多种类型的语义元素有机组合在一起的复合体,具有结构化、模型化的特征。丰富语义这一新概念的出现得到数字图书馆界的高度关注。本课题将建立面向高能物理领域的科技文献丰富语义检索应用示范系统。该系统将有助于实现科技文献中隐含知识的显性揭示,让科技文献的丰富语义能够被用户更方便地发现和使用,促进数字图书馆的知识抽取、文本挖掘、精准搜索、知识组织等技术能力的提高,项目成果将具有重要的学术价值和应用价值,产生一定规模的应用示范效果。
总体目标
本项目选择高能物理领域,整合优化各项已有的语义标注、语义组织、语义索引的关键技术,充分利用已有的语义资源建设一个高能物理领域科技文献的丰富语义检索的示范应用系统。该系统能够将科技文献中的丰富语义揭示挖掘出来,通过有效的语义组织、关联、索引、检索和展示,构建一个可交互的语义可视化检索应用示范,实现从文献的检索获取模式到知识的研究探索模式的转变,形成业界有影响的应用示范。
主要研究内容
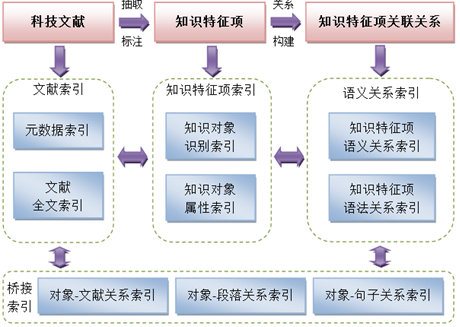
本课题提出提出科技论文的多层级语义标注模型,并形成各层级语义要素和相关关系进行自动标注和揭示的工具,从段落、语篇、句子、概念四个层级,对科技文章中具有重要语义内涵的各层级知识特征项进行自动标注。
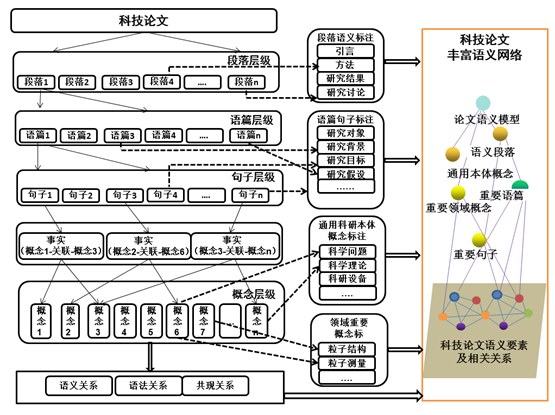
本课题从文献、知识特征项、知识特征项间的潜在语义/语法关系和桥结映射四个维度开展科技文献知识对象的索引构建,从而实现语义层面的分面索引和对丰富语义网络中知识节点的关系推理检索。