文本挖掘与机器学习跟踪扫描动态快报(2021.04)
实时跟踪、关注文本挖掘与机器学习领域最新研究动态
深度观察
束搜索原理
Foundations of NLP Explained Visually: Beam Search, How It Works
机器翻译、聊天机器人、文本摘要和语言模型任务都会生成一些文本作为其输出。此外,还有图像字幕或自动语音识别(即语音到文本)任务也将文本作为输出,即使它们可能不被视为纯NLP任务。这些任务都使用了几种常用算法,作为它们产生最终输出的方法。
- 由于贪婪搜索既简单又快速,它常被用于上述NLP任务中。
- 另一种方法是使用束搜索。由于通常会产生更好的结果,它应用得更广泛,尽管它需要更多的计算。
在本文中,我将探索束搜索并解释为什么使用它以及它是如何工作的。我们将简要介绍一下贪心算法,并将其作为对照,以便我们了解束搜索是如何对其进行改进的。
文本生成
NLP模型如何产生输出
让我们以序列到序列模型为例。这些模型经常用于诸如机器翻译之类的任务中。
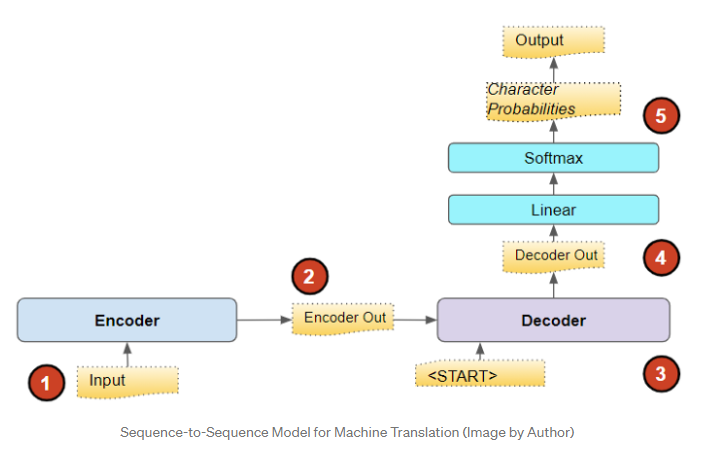
例如,如果使用此模型将英语翻译成西班牙语,则它将源语言中的一个句子(例如,英语中的“You are welcome”)作为输入,并输出目标语言中的等效句子(例如,西班牙语中的“De nada”)。
文本是单词(或字符)的序列,NLP模型构建一个词汇表,该词汇表包含源语言和目标语言中的整个单词集。该模型将源语句作为输入,并使其通过嵌入层,然后是编码器。然后,编码器输出一个已编码的表示形式,该表示形式可以紧凑地捕获输入的基本特征。
然后,将该表示形式与“
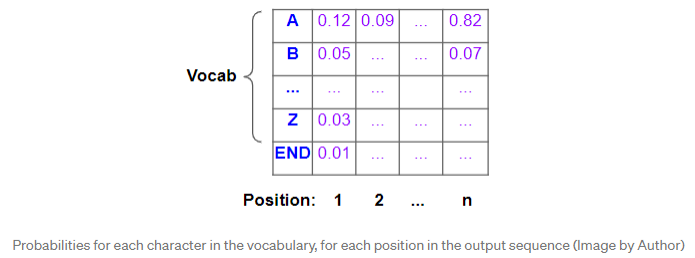
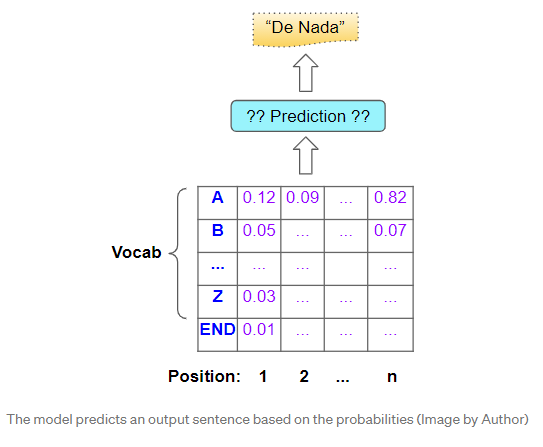
当然,我们最终的目标不是这些概率,而是最终的目标句子。为此,模型必须决定针对该目标序列中的每个位置应预测哪个词。
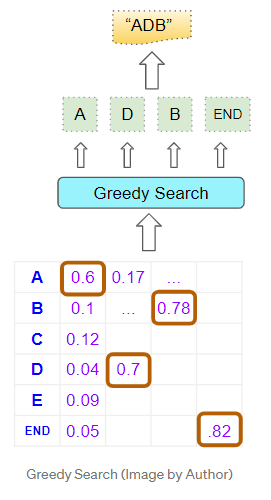
贪婪搜索
一个相当明显的方法是简单地选择每个位置上概率最高的单词并进行预测。 它计算迅速且易于理解,而且通常会产生正确的结果。
束搜索
束搜索在贪婪搜索的基础上从两个方面进行了改进。
- 通过贪婪搜索,我们仅在每个位置都选择了一个最佳单词。相比之下,束搜索会对此进行扩展,并采用最好的N个单词。
- 通过贪婪搜索,我们孤立地考虑了每个位置。一旦确定了该位置的最佳词汇,我们就不会检查它之前(即之前的位置)或之后的内容。而束搜索会选择到目前为止的N个词的最佳顺序,并考虑所有前面的单词与当前位置的单词组合在一起的概率。其中N称为波束宽度。
从直觉上讲,相比于贪婪搜索,束搜索具有更好的结果。因为,我们真正感兴趣的是最好的完整句子,如果我们在每个位置只选择最好的单个单词,我们可能会错过它。
束搜索的作用
让我们举一个波束宽度为2的简单示例,并使用字符使其保持简单。
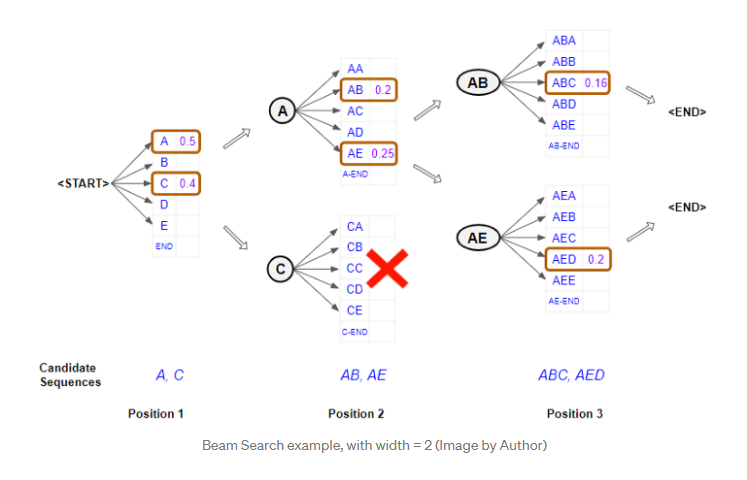
第一个位置
在第一个位置考虑模型的输出。它以“
第二个位置
- 当到达第二位置时,它将两次重新运行模型以通过将可能的字符固定在第一位置来生成概率。换句话说,它将第一个位置的字符约束为“A”或“C”,并生成具有两组概率的两个分支。具有第一组概率的分支对应于位置1中具有“A”,具有第二组概率的分支对应于位置1中具有“C”。
- 现在,它根据前两个字符的组合概率从两组概率中选择总体上最好的两个字符对。因此,它不会仅从第一组中选择一个最佳字符对,而从第二组中选择一个最佳字符对。例如“AB”和“AE”。
第三个位置
- 当到达第三位置时,它将重复该过程。通过将前两个位置约束为“AB”或“AE”,它将模型重新运行两次,并再次生成两组概率。
- 再一次,它基于两组概率中前三个字符的组合概率,从总体上选择了两个最佳字符三元组。因此,我们现在具有前三个位置的两个最佳字符组合。例如 “ABC”和“AED”。
重复直至<END>token
- 它将继续执行此操作,直到选择“
”标记作为某个位置的最佳字符为止,然后得出该序列的分支。
最后,它以两个最佳序列结束,并以较高的总概率预测一个序列。
束搜索的工作原理
现在,我们从概念上了解束搜索。让我们更深入一点,了解其工作原理的详细信息。我们将继续相同的示例,即波束宽度为2。
继续我们的序列到序列模型,编码器和解码器可能是由某些LSTM层组成的循环网络。另外,它也可以使Transformer而不是循环网络来构建。
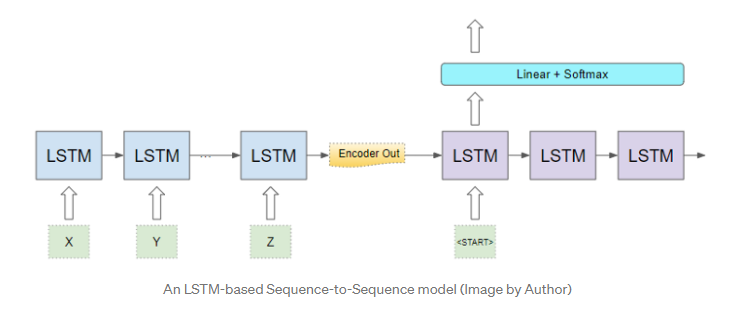
让我们集中讨论解码器组件和输出层。
第一个位置
在第一个时间步中,它使用编码器的输出和“
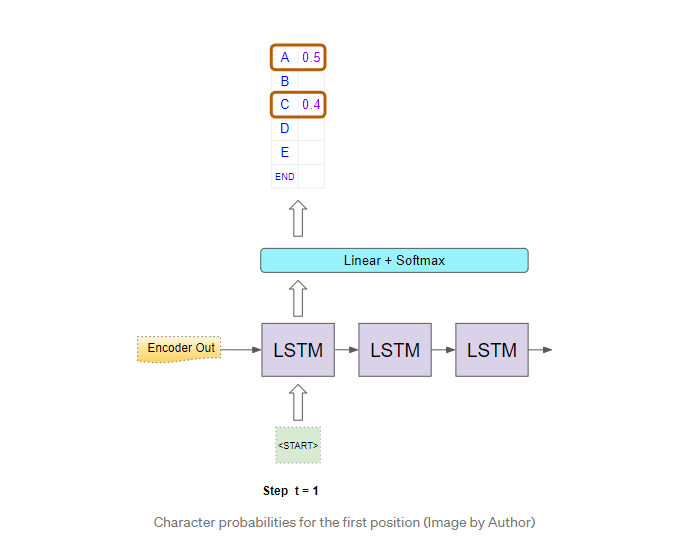
现在,它选择概率最高的两个字符,即“A”和“C”。
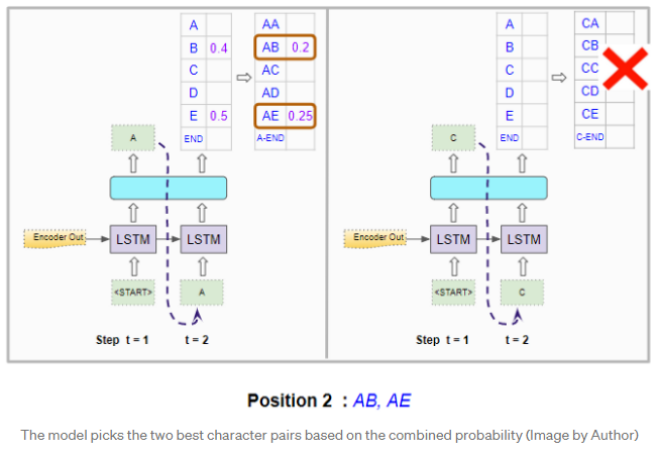
第二个位置
对于第二个时间步,它会像以前一样使用编码器的输出来运行解码器两次。 连同第一个位置中的“
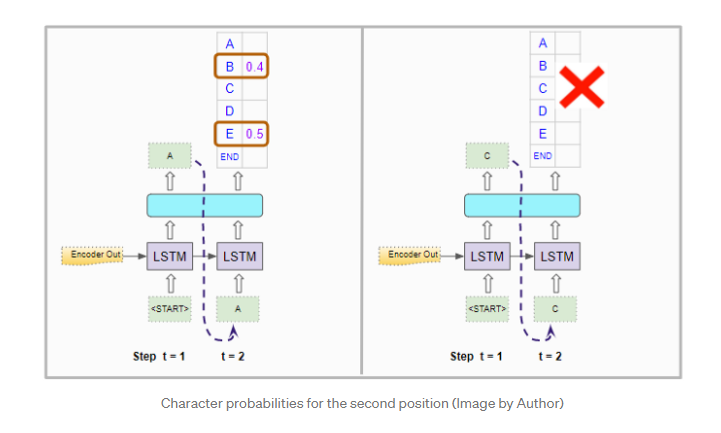
它为第二个位置的单词生成概率,但是这些单个单词的概率。它需要计算前两个位置中字符对的组合概率。假设“A”已经固定在第一位置,则“AB”对的概率是“A”出现在第一位置的概率乘以“B”出现在第二位置的概率。计算公式如下。
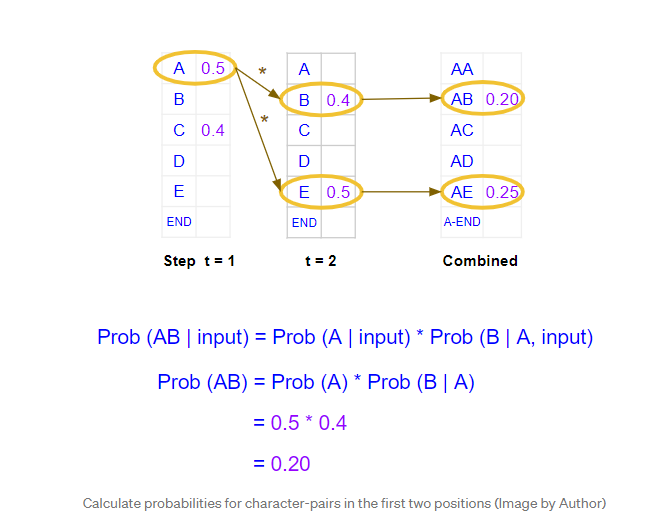
它对两个解码器运行都执行此操作,并选择两次运行中具有最高组合概率的字符对。因此,它选择“AB”和“AE”。
第三个位置
对于第三步,它再次像以前一样运行解码器两次。连同在第一位置的“
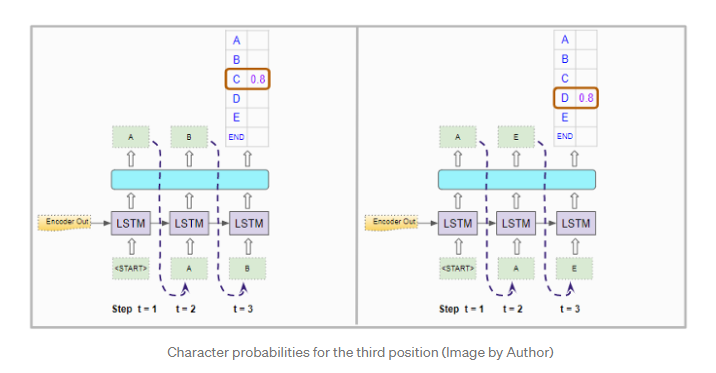
它计算前三个位置中字符三元组的联合概率。
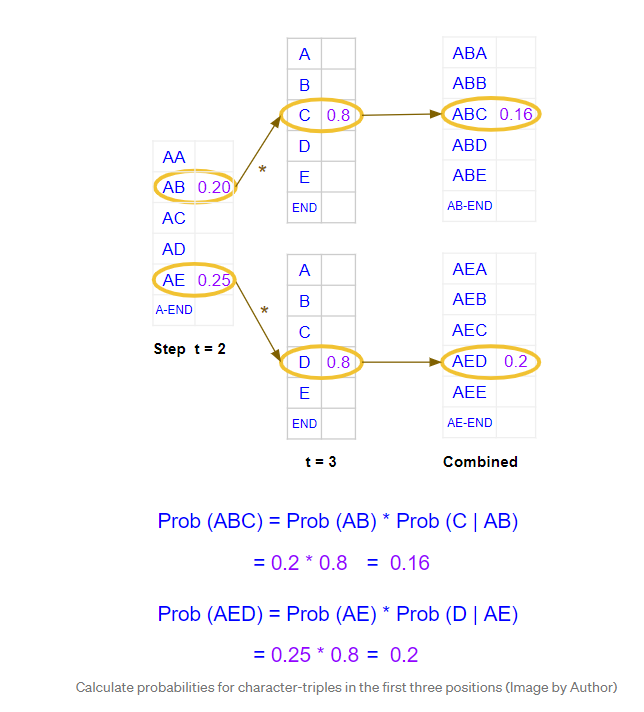
它在两次运行中都选择了两个最佳选择,因此选择了“ABC”和“AED”。
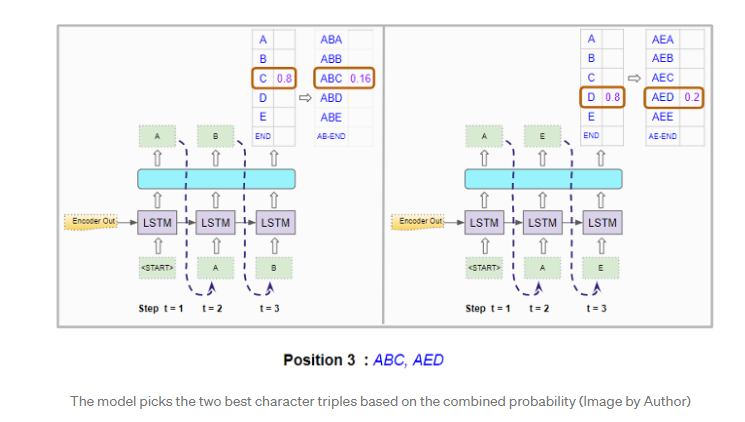
重复直至<END>token
它将继续执行此操作,直到选择“<END>”标记作为某个位置的最佳字符为止,然后得出该序列的分支。然后,它选择联合概率最高的序列进行最终预测。
(张梦婷编译,赵海喻校对)
研究动态
英伟达、斯坦福和微软提议在GPU集群上进行高效的万亿级语言模型训练
大规模的基于Transformer的语言模型在NLP领域产生了巨大的收益。然而,训练这种模型是具有挑战性的,原因有二。没有一个GPU有足够的内存来容纳近年来成倍增长的参数总数,即使有办法在单个GPU上训练这些参数,有限的计算能力也会在没有模型并行的情况下导致不现实的漫长训练时间。
在Efficient Large-Scale Language Model Training on GPU Clusters 一文中,来自英伟达公司、斯坦福大学和微软研究院的研究团队提出了一种新颖的并行化计划,在内存占用相当的情况下,将吞吐量提高了10%以上,表明这种策略可以在训练具有多达一万亿个参数的大型模型时组成实现高聚合吞吐量(502 petaFLOP/s)。

研究人员首先介绍了将数据并行化与张量模型并行化和流水线模型并行化相结合的技术,以促进大型模型的高效训练。
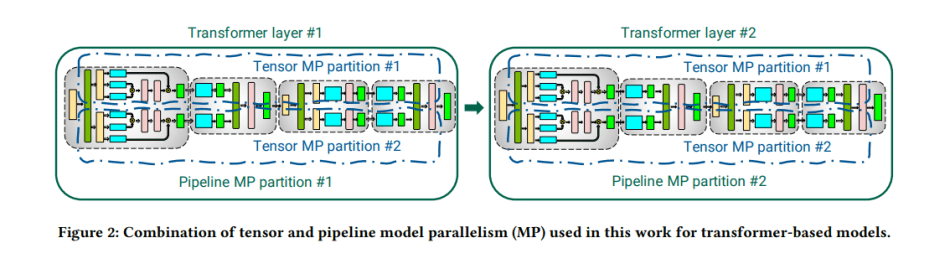
在数据并行的情况下,每个“工作者”都有一个完整模型的副本,而输入的数据集是分片的。工作者定期汇总他们的梯度,所以他们都保持一个一致的权重版本。在流水线并行中,一个模型的各层被分散在多个设备上。因为流水线方案必须确保输入在前向和后向中看到一致的权重版本,所以研究人员研究了两种调度方法:默认调度和交错阶段的调度。
该团队观察到,默认的训练计划有很高的内存占用率,因为它需要在内存中保留隐藏的中间激活。因此,他们选择了一个修改过的PipeDream-Flush计划,它的内存效率要高得多。虽然交错阶段的调度方法能够减少流水线气泡的大小,但它也有缺点,因为它需要额外的通信。
在张量模型并行化中,单个模型层被划分到多个设备上。所提出的方法对语言模型的基石——Transformer层采用了受Megatron项目启发的分区策略。
研究人员测试了他们的组合流水线、张量模型和数据并行的方法,以确定在训练10亿到1万亿个参数的GPT模型规模时,它是否能提高通信和计算性能。
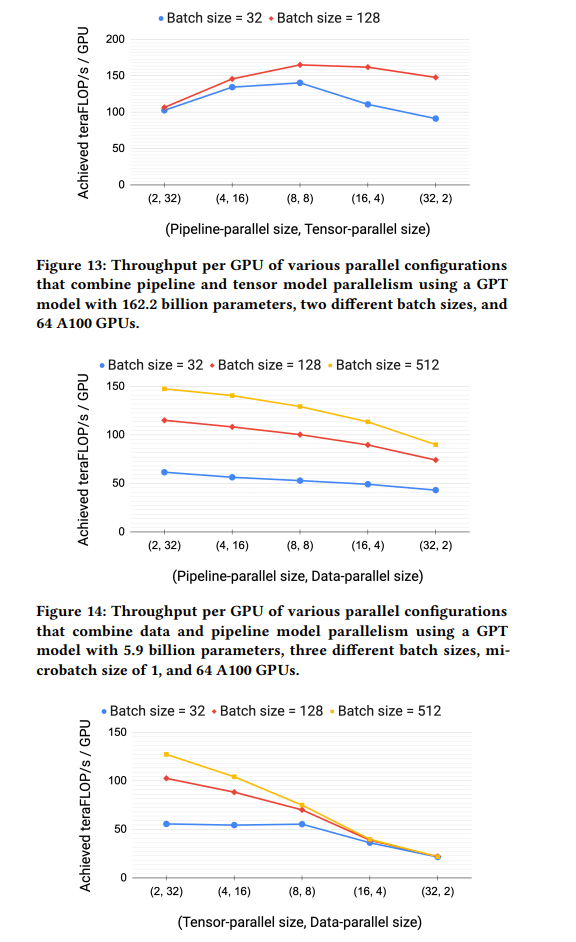
结果显示,所提出的张量、流水线和数据并行的组合能够在3072个GPU上以502 petaFLOP/s的速度对具有1万亿个参数的模型进行训练迭代,实现每GPU吞吐量为峰值的52%,优于以前的方法在类似大小的模型上获得的36%。该方法可以扩展到数以千计的GPU,并且在可以有效训练的模型规模上比现有系统实现了两个数量级的增长。
代码开放在 Github
(周子喻编译,张梦婷校对)
TUM、Google、Nvidia和LMU München的CodeTrans预训练模型破解源码任务
OpenAI强大的GPT-3大型语言模型是机器学习社区的一个游戏规则,自其2020年6月发布以来,出现了许多说明性的演示。Debuild创始人Sharif Shameem的演示展示了GPT-3如何让用户用普通语言描述所需的布局,然后在生成器产生适当的JSX代码。
基于Transformer的GPT-3也被证明是跨越各种自然语言处理(NLP)任务的强大解决方案,表明NLP应用在处理源代码和破解软件工程任务方面具有巨大潜力。然而,这一充满希望的方向仍未得到相对充分的探索。
在新论文 CodeTrans:Towards Cracking the Language of Silicone’s Code Through Self-Supervised Deep Learning and High Performance Computing中,来自慕尼黑工业大学、谷歌、Nvidia和慕尼黑大学的研究团队提出了CodeTrans,一个基于编码-解码的Transformer模型,在软件工程领域的任务中实现了最先进的性能。

软件工程是设计、实施、测试和维护信息系统的高度复杂过程。编程语言——工程师与计算机交流的机器可理解语言——是软件工程过程的核心。研究人员提出,NLP技术也可以应用于解决编程语言任务,并协助软件工程过程。
拟议的CodeTrans适应了Vaswani等人(2017)提出的基于编码-解码的模型和Raffel等人(2020)实施的T5。与T5模型不同,提议的方法禁用了reduce_concat_tokens功能,这样每个样本就只有一个训练实例,而不是将不同的训练实例串联起来,达到最大的训练序列长度。该团队还借用了T5模型中的TaskRegistry和MixtureRegistry概念。每个任务可以作为一个TaskRegistry,而一个或多个TaskRegistry可以建立一个MixtureRegistry。研究人员总共建立了13个TaskRegistry,一个MixtureRegistry用于自监督学习,另一个MixtureRegistry用于多任务学习。
研究人员在一台英伟达GPU和谷歌云TPU上使用单任务学习、转移学习和多任务学习来训练CodeTrans,使用监督任务和自我监督任务来建立软件工程领域的语言模型。
他们将提议的CodeTrans应用于软件工程领域的六个监督任务。代码文档生成、源代码总结、代码注释生成、Git提交信息生成、API序列推荐和程序合成。
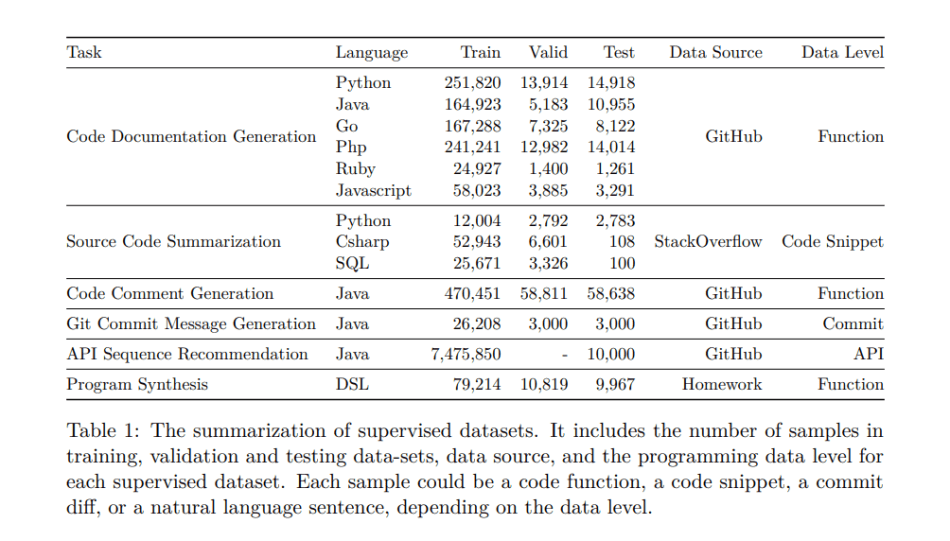
代码文档生成任务需要一个模型来生成给定的代码函数的文档。该任务包含六个编程语言功能,包括Python、Java、Go、Php、Ruby和Javascript。源代码总结任务旨在为一个简短的代码片段生成一个总结,涉及Python、SQL和CSharp语言。代码注释生成主要是为Java函数生成JavaDoc。Git提交信息生成任务旨在生成描述git提交变化的提交信息。API序列推荐用于生成API使用序列,如基于自然语言描述的类和函数名称。同时,程序合成是基于自然语言描述合成或生成编程代码的任务。
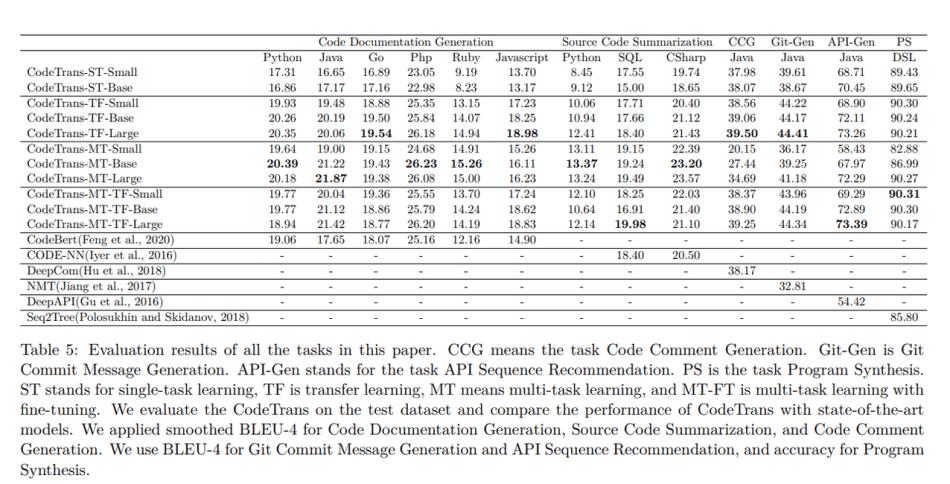
所有的任务都以平滑的BLEU-4评分标准进行评估。对于代码文档生成,CodeTrans在所有编程语言上的表现都优于CodeBert。在源代码总结任务中,它的表现也超过了Code-NN。在代码注释生成方面,CodeTrans在平滑的BLEU得分上超过DeepCom一个百分点。对于Git Commit Message Generation,CodeTrans的表现超过了NMT模型,而且CodeTrans多任务学习大模型的性能接近转移学习大模型。对于API序列推荐,具有多任务学习微调功能的CodeTrans大模型在所有模型中取得了最高分。而对于程序合成,10个CodeTrans模型中有9个模型的表现超过了Seq2Tree模型。
CodeTrans模型的表现优于所有基线模型,在所有任务中都取得了最先进的性能。
该团队表示,研究表明,更大的模型可以带来更好的模型性能,具有转移学习的模型与具有多任务学习微调的模型性能一样好,预训练模型可以在新的下游任务上有效地进行微调,同时节省大量的训练时间。这些结果表明,将Transformer编码器-解码器架构应用于软件工程领域具有广阔的潜力。
代码开放在 Github
(周子喻编译,张梦婷校对)
Yann团队利用字典学习来窥探Transformer
Yann LeCun Team Uses Dictionary Learning To Peek Into Transformers’ Black Boxes
Yann LeCun团队提出了字典学习,以提供Transformer表征的详细可视化,以及对语义结构的洞察力,如词级歧义、句级模式形成和Transformer捕获的长距离依赖。
Transformer架构已经成为许多最先进的NLP模型的构建块。虽然Transformer是强大的,但研究人员对其实际工作方式的理解仍然有限。这是有问题的,因为缺乏透明度,而且有可能通过训练数据和算法继承偏见,这可能导致模型产生不公平或不正确的预测。
在论文 Transformer visualization via dictionary learning:contextualized embedding as a linear superposition of transformer factors中,来自Facebook人工智能研究中心、加州大学伯克利分校和纽约大学的Yann LeCun团队利用字典学习技术,提供了Transformer表征的详细可视化以及对语义结构的洞察力--比如词级歧义、句级模式形成和长程依赖--这些都是Transformer所捕获的。

以前试图对Transformer中的这个黑箱问题进行可视化分析的尝试包括直接可视化,以及最近旨在解释Transformer模型的“探测任务”。然而,诸如语篇(POS)标记、命名实体识别(NER)和句法依赖性等探测任务不够复杂,不能使研究人员相信其结果能准确反映所研究模型的真实特征和能力。这样的探测任务也未能揭示出Transformer的语义结构,超出了先前的知识,并且难以确定相关的语义表征是在Transformer中学习的。
研究人员提出使用字典学习,这是一种可以解释、改进和可视化非语境化词嵌入表征的方法,以减轻现有Transformer解释技术的局限。
该团队首先介绍了关于他们的方法的假设:上下文的词嵌入可以作为Transformer因子的稀疏线性叠加。以前的研究表明,词嵌入可以代表基本的语义。该团队将词的潜在表示方法作为语境化的词嵌入,并提出语境化的词嵌入向量也可以作为一组基本元素的稀疏线性叠加的因素,称之为Transformer因子。
然后,他们采用了使用输入样本的惯例,即触发一个特征的顶部激活,以在深度学习中可视化特征。因为一个上下文词向量一般会受到一个序列中许多标记的影响,所以给每个标记分配一个权重,以确定其对上下文词向量最大稀疏系数的相对重要性。
最后,他们为所有Transformer层建立了一个单一的字典,以确定具有重要性分数(IS)的低、中、高级转化因素,使用IS曲线来确定在哪些层出现Transformer因子。

研究人员在评估实验中使用了一个12层的预训练BERT模型。他们将语义分为三类:词级歧义、句级模式形成和长程依赖,为每个语义类别生成了详细的可视化信息。

对于低级别的、词级的歧义,具有早期IS曲线峰值的Transformer因子往往对应于特定的词级含义。例如,在第0层,最高激活的词“left”有不同的词义,但这在第2层变得不那么含糊了。到了第4层,“left”的所有实例都被视为对应于同一意义。
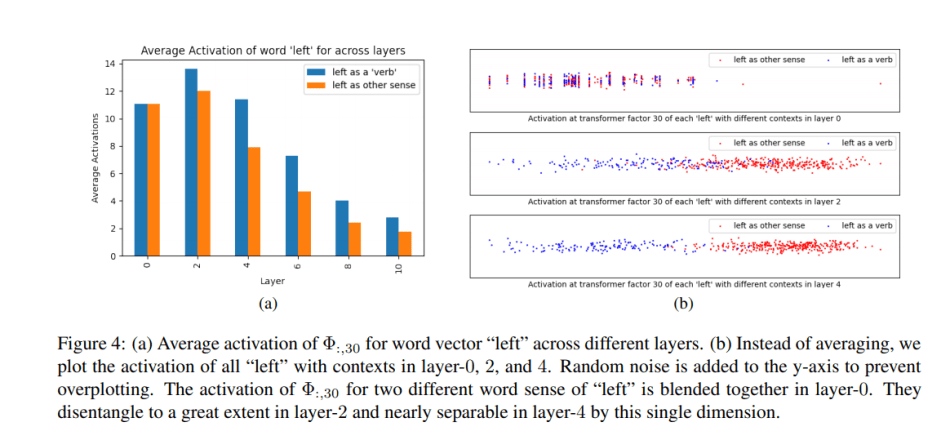
对于中层的、句子层面的模式形成,所提出的方法在形容词的连续使用中检测出模式。结果显示,例如,一个模式在第4层开始出现,在第6层继续发展,并在第8层变得相当可靠。研究小组得出结论,大多数具有在第6层之后达到峰值的IS曲线的Transformer因子都捕捉到了中层或高层的语义。


对于高层次、长距离的依赖关系,Transformer因子对应于文本中跨度较大的语言模式,结果显示了每个此类Transformer因子的前两个激活词及其语境。研究小组观察到,这种高层次的分析包含更抽象的重复结构,也可以使用中层次的信息片段,如出生日期、名字和姓氏、家庭关系、职业等。
研究人员认为这个简单的工具可以打开Transformer网络,显示从和不同阶段学到的分层语义表示。他们创建了一个 互动网站 ,用户可以通过可视化他们的潜在空间来获得对Transformer模型的额外见解。
(赵海喻编译,周子喻校对)
IBM的对抗性攻击策略使MBERT QA性能降低了85%
随着大型语言模型在QA任务上不断取得最新成果,研究者们对这些模型的鲁棒性提出了自己的一些问题。IBM的一个团队最近对英文QA进行了一项全面的分析,结果表明,SOTA模型在面对对手生成的数据时可能会非常脆弱。
以往对攻击策略的研究主要集中在单语QA的表现上,而对多语种QA的攻击则相对缺乏研究。IBM的研究人员瞄准了后者,在zero-shot情况下对七种语言应用了四种新颖的多语言对抗攻击策略。面对这样的攻击,大型多语种预训练语言模型(如MBERT)的性能平均下降了至少20.3%和85.6%。

研究人员总结了他们的主要贡献,揭示了多语言QA系统中的缺陷,并提供了在单一语言系统中不明显的见解,特别是:
- 与BERT相比,MBERT更容易受到攻击。
- MBERT优先考虑在某些语言中找到答案,即使对手的陈述使用的语言与问题和上下文不同,也会使得攻击成功。
- MBERT优先考虑的是问题的语言,而不是上下文的语言。
- 用机器翻译的数据扩充系统有助于构建更健壮的系统。
一种更流行的QA攻击策略是添加对抗性句子来分散阅读理解系统的注意力。这项新的研究建立在这种方法的基础上,将一个问题Q转化为一个陈述S,其目的是生成一个语义上与Q相似但可以被人类读者识别为不正确的对抗性陈述S。

提出的Q到S转换过程包括五个步骤。研究人员首先使用通用依存句法分析(UDP)和命名实体识别(NER)对英语问题输入进行预处理。他们对语法进行深度优先搜索,并标记所有词性(POS)标记以识别单词模式,模式“what nn”、“what vb”、“who vb”、“how many”和“what vb vb”占训练集的40%以上。基于这些模式,在第二步中,团队将问题转换为包含标记问题的语句。
在第三步中,研究人员运用四种不同的攻击策略来制造各种类型的对抗性陈述。这四种策略分别是随机回答随机问题(RARQ)、随机回答原始问题(RAOQ)、无回答随机问题(NARQ)和无回答原始问题(NAOQ)。在第四步,这些生成的对抗性陈述被翻译成其他语言,在第五步,这些翻译的对抗性陈述被插入到上下文中。
该团队使用MBERT预训练语言模型和SQuAD v1.1、MT SQuAD和MLQA数据集对多语言QA进行了实验。
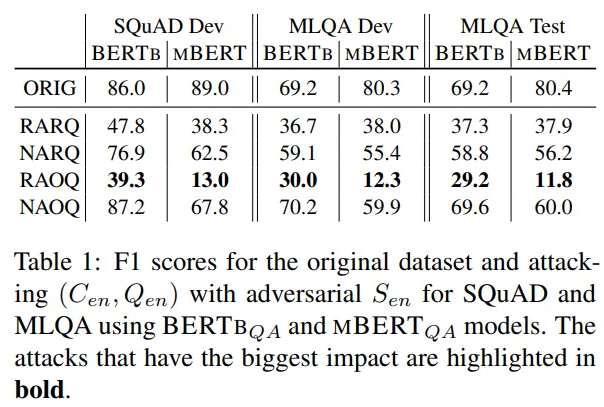

该团队攻击了仅用英语训练的多语言系统MBERTQA,以及用六种语言的数据训练的多语言系统MT-MBERTQA。结果表明,这两个系统都受到这四种攻击的影响。攻击力最强的是RAOQ,使用对抗性的中文陈述造成了F1得分平均降低30。
这项研究证明了所提出的攻击策略的有效性,该团队称这些策略可以用来帮助建立更强大的QA系统。
(论文链接: https://arxiv.org/pdf/2104.07646.pdf )
(张梦婷编译,赵海喻校对)
项目工具
用马尔科夫链生成文本——Markovify的介绍
Text Generation with Markov Chains: An Introduction to using Markovify
Markovify是一个Python库,它是一个简单的、可扩展的马尔科夫链生成器,使用起来非常简单和快速。马尔科夫链本身就是一个巧妙的创造,它为多状态过程提供“保持”和“改变”的概率。
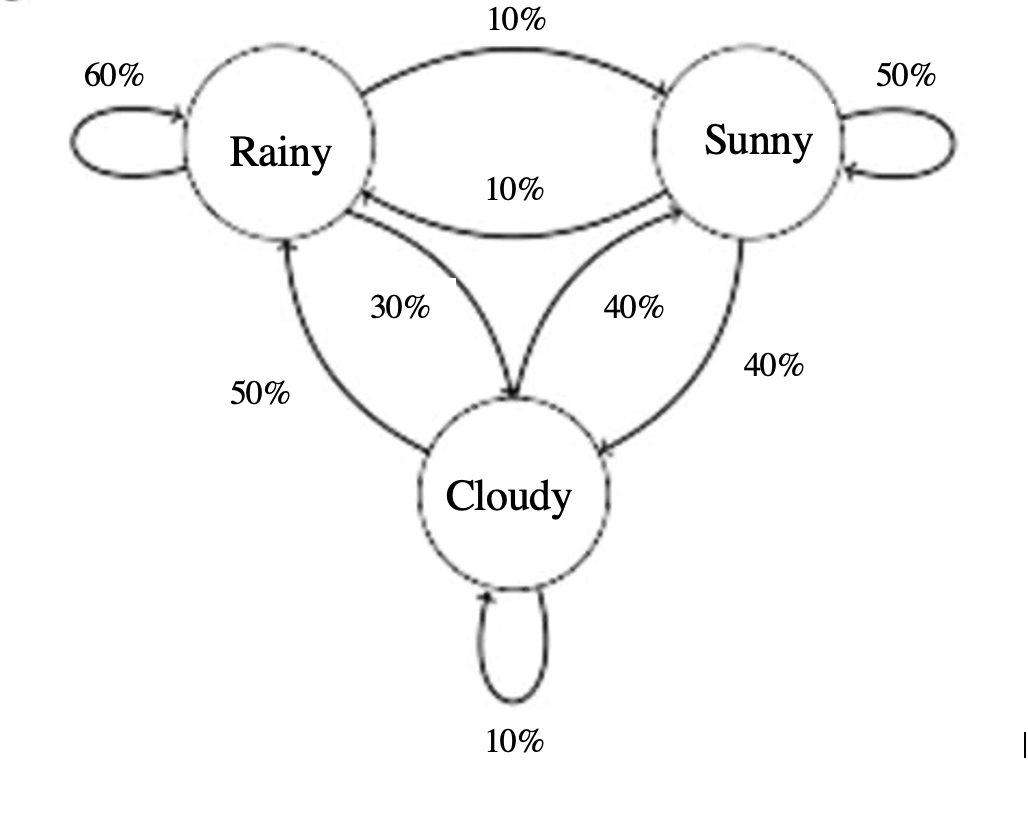
上图中有三种可能的状态:阴天、雨天和晴天。马尔科夫链依靠当前的状态来预测未来的结果。如果我们观察到今天是雨天,我们的概率如下:明天仍然下雨的可能性是60%,多云的可能性是30%,而晴天的可能性是10%。当我们从多云和晴天的状态开始时,也可以应用同样的逻辑。
那么,这到底是如何在文本中工作的呢?从本质上讲,我们的语料库中的每个词都是用马尔科夫链以不同的概率与其他每个词“连接”起来的。因此,如果我们的初始词(状态)是“Thou”,Markovify会给我们语料库中的每个其他词分配一个概率。它可能会将“Shall”的概率定为65%,“is”为20%,“may”为10%,以此类推,我们的整个语料库将构成最后的5%。请注意,“Thou”跟在自己后面的可能性应该接近0%,因为一个词像这样重复自己是没有什么意义的,而且几乎所有的词都是如此。
生成文本
首先,我们需要安装库和包:

我们将使用NLTK和spaCy进行文本预处理,因为它们是最常见的,而且如果我们先进行解析,我们的模型将更好地生成文本。现在我们可以导入我们的库。

在这个演示中,我们将使用古腾堡计划NLTK语料库中的三部莎士比亚悲剧。我们将首先打印古腾堡语料库中的所有文件,这样你就可以随心所欲地混合和匹配这些文件。

在这个演示中,我们将使用莎士比亚的三部悲剧《麦克白》、《凯撒大帝》和《哈姆雷特》。因此,我们接下来将导入它们并检查文本。

接下来我们将使用re库建立一个实用函数来清理我们的文本。这个函数将删除不需要的空格和缩进、标点符号等。

接下来我们将继续清理我们的文本,删除章节标题和指标,并应用我们的文本清理功能。

我们现在要使用spaCy来解析我们的文件。

现在,我们的文本已被清理和处理,我们可以创建句子并结合我们的文件。

我们的文本预处理已经完成,我们可以开始使用Markovify来生成句子。

现在我们只需要写一个循环来生成我们想要的句子就可以了。下面,我们将创建3个未定义长度的句子和3个长度小于100个字符的句子。

一些示例文本:
“He will stay till ye come K. Hamlet , this Pearle is thine , Here’s to thy health.”
“My Honourable Lord , I will speake to him.”
对莎士比亚英语来说还不错。但我认为我们可以做得更好。我们将使用SpaCy实现POSifiedText,尝试改善我们的文本预测。

最后,使用我们的新生成器打印更多的句子。

一些例子:
“He ha’s kill’d me Mother , Run away I pray you Oh this is Counter you false Danish Dogges.”
“Thy selfe do grace to them , we rest your Ermites King.”
(赵海喻编译,周子喻校对)
近期论文
Improving Faithfulness in Abstractive Summarization with Contrast Candidate Generation and Selection
摘要
尽管在神经生成式摘要方面取得了重大进展,但最近的研究表明,当前的模型容易产生不符合原始上下文的摘要。为了解决这个问题,我们研究了对比候选对象的产生并选择一种与模型无关的后处理技术,以纠正不忠于摘要中的外在幻觉(即源文本中不存在的信息)。我们通过生成替代候选摘要来学习区分性校正模型,其中生成摘要中的命名实体和数量被替换为源文档中具有兼容语义类型的实体和数量。然后使用此模型选择最佳候选作为最终输出摘要。我们在多个神经摘要系统上的实验和分析表明,我们提出的方法在识别和纠正外在幻觉方面是有效的。通过对不同类型的神经摘要系统中典型的幻觉现象进行分析,希望能够给今后的工作方向一点启发。
主要贡献
首先,我们的工作是第一次研究对比候选对象的产生,并选择与模型无关的有效技术来校正幻觉,在这种背景下,大量的ground truth摘要数据遭受幻觉。其次,我们在XSum训练的各种神经摘要系统上验证了我们的方法,并对每个系统中典型的幻觉类型进行了详细的分析。
实验
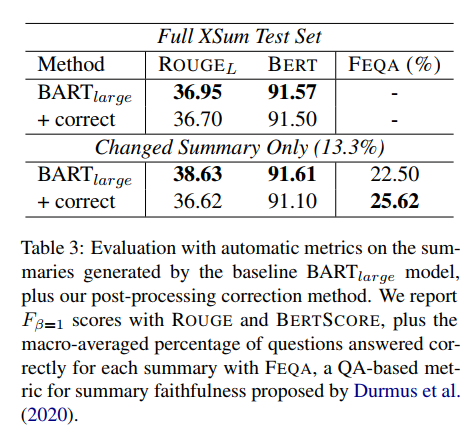


(张梦婷编译)
ProphetNet-X: Large-Scale Pre-training Models for English, Chinese, Multi-lingual, Dialog, and Code Generation
摘要
现在,预训练技术在自然语言处理领域无处不在。ProphetNet是一种基于预训练的自然语言生成方法,它在英文文本总结和问题生成任务上显示出强大的性能。在本文中,我们将ProphetNet扩展到其他领域和语言,并提出了ProphetNet家族的预训练模型,命名为ProphetNet-X,其中X可以是英文、中文、多语言等。我们预训练了一个跨语言生成模型ProphetNet-Multi,一个中文生成模型ProphetNet-Zh,两个开放域的对话生成模型ProphetNet-DialogEn和ProphetNet-Dialog-Zh。此外,我们还提供了一个PLG(编程语言生成)模型ProphetNet-Code,以展示除NLG(自然语言生成)任务外的生成性能。在我们的实验中,ProphetNet-X模型在10个基准测试中取得了新的最先进的性能。ProphetNet-X的所有模型都有相同的模型结构,这使得用户可以在不同的模型之间轻松切换。我们公开了代码和模型,并将持续更新更多预训练模型和微调脚本。
主要贡献
- 我们提供了一个名为ProphetNet-X的预训练模型系列,其中包括开放领域和对话中的英语和中文自然语言生成、多语言生成和代码生成等六个模型。
- 所有预训练的ProphetNet-X模型共享相同的模型结构。用户只需要简单地修改一个模型文件就可以在不同的语言或领域任务中使用它。
- 我们进行了广泛的实验,结果表明,ProphetNet-X模型在10个公开的基准上取得了新的最先进的性能。

实验
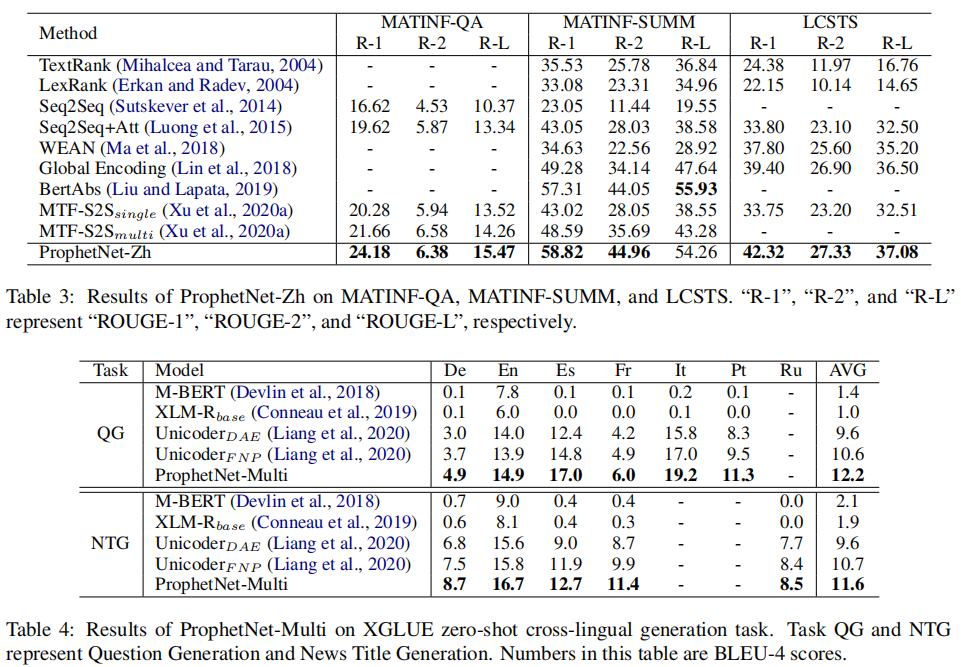
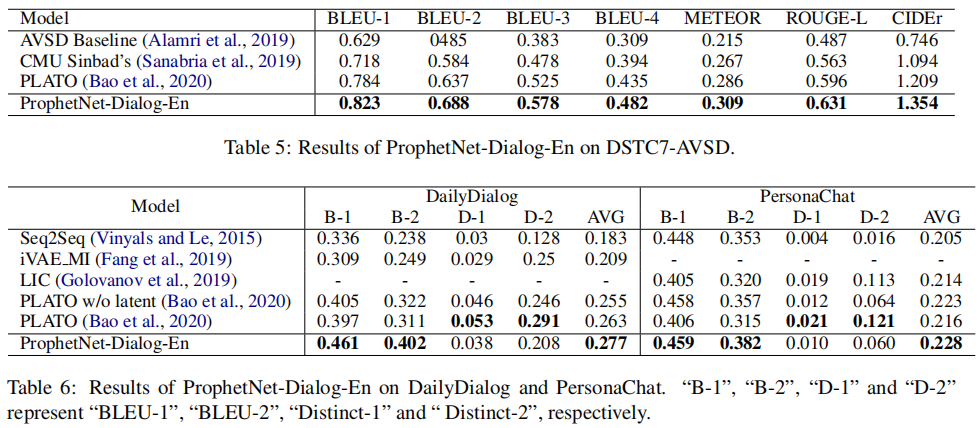
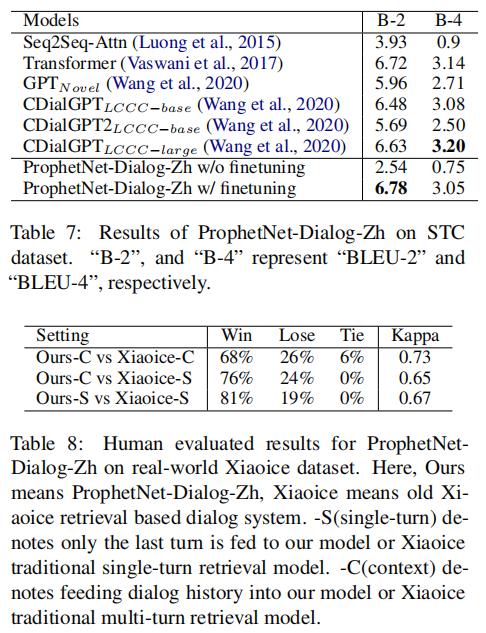
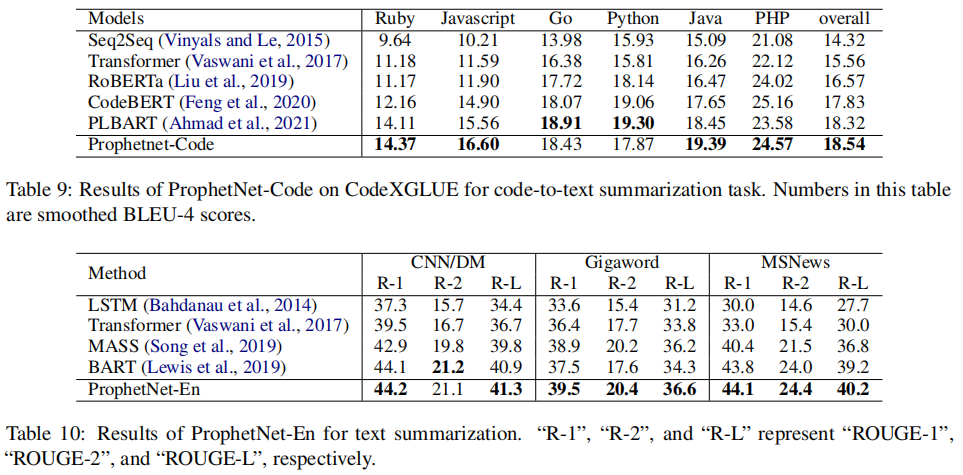

(张梦婷编译)
近期会议
International Conference on Learning Representations
Mar 26, 2021 线上
国际学习表征会议(ICLR)是致力于推进人工智能分支(称为表征学习,但通常称为深度学习)的专业人士的首要聚会。ICLR在全球范围内享有盛誉,它在人工智能、统计和数据科学等领域,以及机器视觉、计算生物学、语音识别、文本理解、游戏和机器人等重要应用领域,展示和发表深度学习的各个方面的最新研究成果。
(赵海喻)
DNLP 2021: International Conference on Data Mining and NLP
Aug 21 Chennai, India
DNLP 2021将提供一个极好的国际论坛,以分享数据挖掘和NLP的理论、方法和应用方面的知识和成果。 这次会议的目的是将学术界和工业界的研究人员和从业人员聚集在一起,集中精力于理解数据挖掘和NLP概念,并在这些领域建立新的合作关系。
(张梦婷)