文本挖掘与机器学习跟踪扫描动态快报(2020.08)
实时跟踪、关注文本挖掘与机器学习领域最新研究动态
深度观察
REALM:将检索集成到语言表示模型中
自然语言处理的最新进展很大程度上是建立在无监督的预训练能力之上的,这种训练使用大量文本来训练通用语言表示模型,而不需要人为的注释或标签。这些预先训练过的模型,如BERT和RoBERTa,已经被证明能记住海量的知识,例如“Francesco Bartolomeo Conti的出生地”,“JDK的开发者”和“Border TV的所有者”等等……虽然编码能力对于某些自然语言处理任务(如问答、信息检索和文本生成)特别重要,但这些模型隐式地存储知识,即世界知识在模型中以一种抽象的方式被捕捉,这使得很难确定在模型中存储了哪些知识以及这些知识保存在哪里。此外,存储空间以及模型的准确性会受网络规模的限制。为了获取更多的世界知识,标准做法是训练越来越大的网络,然而这可能导致速度太慢或成本太高。
相反,如果有一种预训练的方法可以显式地访问知识,例如通过引用额外的大型外部文本语料库,以便在不增加模型大小或复杂性的情况下获得准确的结果。例如,模型可以引用外部文档集“Francesco Bartolomeo Conti出生于佛罗伦萨”中的一句话来确定这位音乐家的出生地,而不是依靠模型的隐式能力来访问存储在其中的知识。检索包含此类明确知识的文本的能力将提高预训练的效率,同时使模型能够在不使用数十亿个参数的情况下很好地执行知识密集型任务。
在2020年国际机器学习大会上接收的论文REALM: Retrieval-Augmented Language Model Pre-Training中,我们分享了一种新的语言模型预训练范式,它通过一个知识检索器扩充语言表示模型,允许REALM模型从原始文本显式检索世界知识的文本文档,而不是将所有知识存储在模型参数中。我们还开放了REALM代码库来演示如何联合训练检索器和语言表示。
背景:训练前语言表示模型
要了解标准语言表示模型是如何记忆世界知识,首先应该回顾这些模型是如何预训练的。自BERT发明以来,被称为掩码语言建模的填空任务被广泛应用于预训练语言表示模型。如果文本中有某些单词被屏蔽了,那么任务就是补齐缺失的单词。此任务的示例如下:
在预训练过程中,模型会遍历大量的例子并调整参数以预测缺失的单词(answer:drink)在上面的示例中。有趣的是,填空任务会让模型记住关于世界的某些事实。例如,在下面的例子中,需要知道爱因斯坦的出生地来填补缺失的单词:
然而,由于模型所捕捉到的世界知识都存储在模型权重中,它是抽象的,因此很难理解存储了什么信息。
我们的建议:检索增强语言表示模型预训练
与标准的语言表示模型不同,REALM通过一个知识检索器对语言表示模型进行了扩充,该检索器首先从外部文档集合中检索另一段文本作为“支持知识”。(在我们的实验中,我们使用Wikipedia文本语料库)。然后将支持文本和原始文本一起输入语言表示模型。
REALM的关键直觉是,一个检索系统应该提高模型填充缺失单词的能力。因此,一个能够提供更多上下文来填充缺失单词的检索系统应该得到奖励。如果检索到的信息不能帮助模型做出预测,那么这样做就不得到奖励,以便为更好的检索腾出空间。
如果在预训练期间只有未标记的文本可用,那么如何训练知识检索器?结果表明,在不使用人工注释的情况下,可以利用填充词任务间接地训练知识检索器。假设查询的输入是:
补齐缺词(answer:pounds)。
在这句话中,不进行检索可能会很棘手,因为模型需要隐式存储白金汉宫所在国和相关货币的知识,并在两者之间建立联系。如果有一段文章明确地连接了从外部语料库中检索到的必备知识,那么模型就更容易填充缺失的单词。
在本例中,检索器将因检索以下句子而获得奖励。
由于检索步骤需要添加更多上下文,因此可能有多个检索目标可以帮助填充缺失的单词,例如,“The official currency of the United Kingdom is the Pound.”整个过程如下图所示:

REALM的计算挑战
扩展REALM预训练,使模型能够从数百万文档中检索知识是一项具有挑战性的任务。在REALM中,最佳文档的选择被定义为最大内部产品搜索(MIPS)。为了执行检索,MIPS模型需要首先对集合中的所有文档进行编码,这样每个文档都有相应的文档向量。当输入到达时,它被编码为查询向量。在MIPS中,给定一个查询,将检索集合中文档向量和查询向量之间内积值最大的文档,如下图所示:

在REALM中,我们使用ScaNN包高效地进行MIPS,这使得在预先计算文档向量的情况下,找到最大内积值相对容易。但是,如果在训练期间更新了模型参数,则通常需要为整个文档集合重新编码文档向量。为了解决计算难题,我们构造了检索器,以便可以缓存和异步更新为每个文档执行的计算。我们还发现,相较于每一步都更新一次文档向量,每500个训练步骤更新一次文档向量,可以获得良好的性能并使训练变得易于操作。
将REALM应用于开放域问答
我们通过将REALM应用于Open-QA(这是自然语言处理中知识量最大的任务之一)来评估其有效性。任务的目的是回答问题,例如“等边三角形的角度是多少?”
在标准问题解答任务(例如SQuAD或自然问题)中,支持文档作为输入的一部分提供,因此模型仅需要在给定文档中查找答案。在Open-QA中,没有给定的文档,因此Open-QA模型需要自己查找知识,这使Open-QA成为检查REALM有效性的出色任务。
下图显示了对自然问题的OpenQA版本的结果。我们将我们的结果与T5进行比较,T5是另一种在没有注释支持文档的情况下训练模型的方法。从图中可以清楚地看到REALM预训练生成了非常强大的Open-QA模型,甚至比大得多的T5(11B)模型高出近4个百分点,而只使用了一小部分参数(300M)。

结论
REALM的发布有助于激发开发端到端检索增强模型的兴趣,包括最新的检索增强生成模型。我们期待着以多种方式扩展这一领域的可能性,包括:
1)将领域式方法应用于需要知识密集型推理和可解释出处的新应用(超越Open-QA)。
2)探索其他形式的知识,如图像、知识图结构,甚至是其他语言的文本。
(张梦婷编译,李朝安校对)
研究动态
Google的“BigBird”在长文本NLP任务上获得SOTA性能
Google Bigbird Achieves Sota Performance On Long Context NLP Tasks
谷歌的BERT和其他基于transformers的自然语言处理(NLP)模型的巨大成功并非偶然。SOTA的所有性能背后都隐藏着transformer创新的自我关注机制,它使网络能够从整个文本序列中捕捉上下文信息。然而,自我关注的记忆和计算要求随序列长度呈二次方增长,这使得使用基于transformer的模型来处理长序列的成本很高。
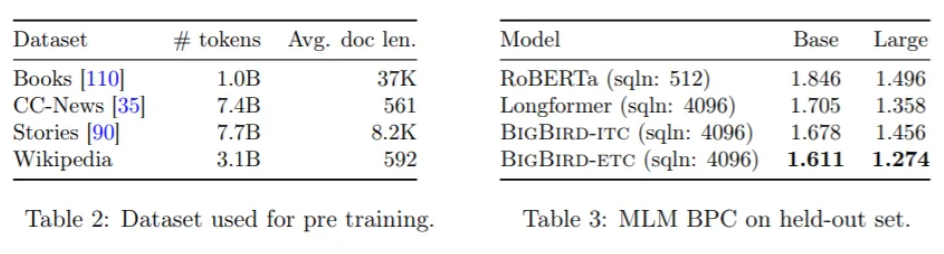
为了减少transformer的二次依赖,谷歌研究所的一个研究小组最近提出了一种新的稀疏注意机制,称为BigBird。在他们的论文BigBird:Transformers for Longer Sequences中,该团队证明了尽管BigBird是一种稀疏的注意机制,BigBird仍然保留了二次完整关注模型的所有已知理论特性。在实验中,BigBird可以显著提高长上下文NLP任务的性能,在问答和摘要中产生SOTA结果。
 研究人员设计BigBird以满足full transformer的所有已知理论特性,在模型中构建了三个主要组件:
研究人员设计BigBird以满足full transformer的所有已知理论特性,在模型中构建了三个主要组件:
一组全局token g,用于处理序列的所有部分。
对于每个查询qi,每个查询将处理的r个随机键的集合。
一组局部邻域w,使得每个节点都参与到它们的局部结构。
这些创新使得BigBird处理序列的时间比以前使用标准硬件所能处理的序列长8倍。
 此外,受BigBird处理长上下文能力的启发,该团队引入了一种基于注意力模型的新应用,用于提取DNA等基因组序列的上下文表示。实验证明BigBird在处理较长的输入序列方面是有益的,并且在诸如启动子区域和染色质分布预测等下游任务上也提供了超前的性能。
此外,受BigBird处理长上下文能力的启发,该团队引入了一种基于注意力模型的新应用,用于提取DNA等基因组序列的上下文表示。实验证明BigBird在处理较长的输入序列方面是有益的,并且在诸如启动子区域和染色质分布预测等下游任务上也提供了超前的性能。
 (张梦婷编译,李朝安校对)
(张梦婷编译,李朝安校对)
从数据集到NLP模型的语言表达不足的问题
The Problem of Underrepresented Languages Snowballs from Datasets to NLP Models
NLP pipeline如何全面支持广泛使用的语言?最近,克拉克森大学和爱荷华大学研究人员共同撰写了一项研究,旨在调查NLP工具对八种方言的理解程度:英语、汉语、乌尔都语、波斯语、阿拉伯语、法语、西班牙语和塞内加尔语沃洛夫语。他们的研究结果表明,即使在某种工具从技术上支持某种语言,也存在警告阻止其充分参与并导致某些表达不足。
一个典型的NLP pipeline包括收集语料库,将它们处理成文本,识别语言元素,训练模型,并使用这些模型来回答特定的问题六个步骤。研究人员说,人们已经很清楚地认识到某些语言在数据集中的缺乏表示的程度,但是在整个NLP工具链中扩大影响的方式却鲜有讨论。
合著者断言,绝大多数NLP工具都是用英语开发的,即使它们获得了对其他语言的支持,它们在鲁棒性、准确性和效率方面往往落后于英语。就BERT而言,开发人员发布了一个英语模型,随后发布了中文和多语言模型。但是单语言模型与多语言模型相比仍然保持了性能优势,英语和汉语单语模型的性能都比英汉组合模型好3%。如果范围缩小到24种计算资源有限的团队发布较小的BERT模型时,所有语言均为英语。
研究人员说,在pipeline的任何一个阶段缺乏表示,会加剧后期的表示不足。举例而言,BERT模型是使用最大的Wikipedia文章数据库在前100种语言上进行训练的,但是在调整发言人人数时,数据库的大小和质量有很大的差异。它们的变化不仅取决于语料库的文件大小和总页数,还包括没有内容的存根百分比、编辑次数、使用该语言工作的管理员数量、用户总数和活动用户总数。
具体情况如下:
全世界大约有11.9亿中国人说中文,其中有112万篇中文维基百科文章,每1000人中有0.94篇文章。
610万篇英文文章,即每1000人中有12.08篇文章(以全球5.05亿人为例)
160万西班牙语,即每1000人中有3.42篇文章(以全世界4.7亿人为例)
104万篇阿拉伯语文章,即每1000人中有3.33篇文章(以全世界3.15亿人为例)
222万篇法语文章,即每1000人中有29.70篇文章(以全世界7500万人为例)
波斯语732106篇,即每1000人中有10.17篇文章(以全世界7200万人为例)
乌尔都语155298篇,或每1000人2.43篇(全球6400万人)
沃洛夫语中有1393篇文章,或每1000位演讲者0.14篇文章(以全球1000万演讲者为例)
这些数据库甚至不如它们看上去那么有代表性,因为并非所有使用一种语言的人都能访问维基百科。就中文而言,它已被中国政府禁止,因此在Wikipedia中的中文文章更有可能来自台湾,香港,新加坡和海外的4000万华语使用者。
研究人员发现,某些语言的技术障碍往往比其他语言更高。例如,他们用来从维基百科下载中文、英文、西班牙文、阿拉伯文、法文和波斯语语料库的脚本,波斯语的错误率为0.13%,中文的错误率为0.02%,但在500万篇英文文章中没有错误。而对于乌尔都语和沃洛夫语语料库,这个脚本并不兼容,因为它不支持其格式。
了维基百科之外,研究人员在组装每种语言的电子书时也遇到了一些问题,这些问题通常用于训练NLP模型。对于阿拉伯语和乌尔都语,许多标题都是扫描图像而不是文本格式,需要使用光学字符识别工具进行处理,准确率在70%到98%之间。在中国电子书中,研究人员使用的光学字符工具错误地在每一行间添加空格。由于沃洛夫语没有书面字符集,研究小组只能用英语、法语和阿拉伯语的文本。
研究人员写道:“尽管在维基百科和BERT等项目中投入了大量的多语种支持,但我们仍很难认为进行NLP指导下的决策,能够系统地代表了世界上大部分地区的声音。我们记录了整个NLP工具链如何进一步放大NLP流程早期缺乏表示(例如Wikipedia中的表示)的情况,最终导致依赖易于使用的预训练模型有效地阻止了除资源以外的所有团队包含各种表示。我们强调说多种语言的人在将其思想和表达方式充分纳入NLP得出的结论中所面临的困难,这些结论已被用来指导NLP的未来。”
(张梦婷编译,李朝安校对)
项目工具
微软研究院首次推出尖端生物医学NLP人工智能模型:PubMedBERT
Microsoft Research Debut Cutting Edge Biomedical NLP AI Model?
 微软研究院发表了一篇论文(链接:https://arxiv.org/pdf/2007.15779.pdf),重点研究了一种新的AI技术,它将有助于生物医学自然语言处理的发展。其为特定领域的语言模型预训练,创建了一个来自公共数据集的详细NLP基准,并产生了最佳结果。
微软研究院发表了一篇论文(链接:https://arxiv.org/pdf/2007.15779.pdf),重点研究了一种新的AI技术,它将有助于生物医学自然语言处理的发展。其为特定领域的语言模型预训练,创建了一个来自公共数据集的详细NLP基准,并产生了最佳结果。
微软研究公司表示,具体而言,结果要比以前更好。据研究小组称,该AI可以对文件进行分类,提取基于证据的医疗信息,识别命名实体等等。
研究表明,使用特定领域的数据来训练NLP模型将发挥特定的有效作用,例如在生物医学中。微软希望通过调整AI训练背后的概念来扩大这一潜力。
虽然特定领域的数据是准确的,但之前的测试是基于“域外”数据的假设进行的。微软研究院认为这是不正确的,因为混合域预训练数据不太准确。对于他们的新的预训练模型,该团队表明特定领域的预训练优于常规的混合领域预训练。
“为了促进这项研究,我们从公开的数据集汇编了一个全面的生物医学NLP基准,并了解预训练和特定任务的微调对特定领域应用的影响,进而对建模选择进行了深入比较。我们的实验表明,针对特定领域的预训练可以为生物医学NLP提供坚实的基础,从而在广泛的任务范围内产生新的最先进的性能。
训练
像任何AI训练一样,评估过程是很重要的。Microsoft Research使用最新PubMed文档数据集的词汇表生成训练模型。其中包括1400万篇摘要和32亿字内容,共21GB。使用一台带有16个V100 GPU的Nvidia DGX-2驱动机器,需要训练5天。
新模型建立在Google的BERT之上,称为PubMedBERT,在生物医学NLP学习方面一直优于同类的AI。
结果表明,从零开始特定领域的预训练大大优于泛型语言模型的连续预训练,从而证明了支持混合域预训练的主流假设并不总是适用的。
(张梦婷编译,李朝安校对)
近期论文
BERT有多智能? 评估语言模型的常识
How smart is BERT evaluating the language models commonsense knowledge
西湖大学、复旦大学和微软亚洲研究院的一个研究小组深入研究了BERT,以发现它是如何编码其用于下游常识任务的结构化常识知识的,发表论文Does BERT Solve Commonsense Task via Commonsense Knowledge?
 诸如BERT之类的预训练语言模型在各种下游任务上的成功实践,刺激了对模型内部语言知识的研究。以往的研究已经揭示了BERT中的浅层语法,语义和词义知识,然而BERT如何处理常识性任务的问题却尚未得到深入的研究。
诸如BERT之类的预训练语言模型在各种下游任务上的成功实践,刺激了对模型内部语言知识的研究。以往的研究已经揭示了BERT中的浅层语法,语义和词义知识,然而BERT如何处理常识性任务的问题却尚未得到深入的研究。
CommonsenseQA是建立在CONCEPTNET知识图上的一个多选问答数据集。研究人员从CONCEPTNET中提取出语义关系相同的多个目标概念,每个问题都有三个目标概念中的一个作为正确答案。例如,“鸟”是“野鸟通常生活在哪里”这个问题中的来源概念;“乡村”是从可能的目标概念“笼子”、“窗台”和“乡村”中得出的正确答案。
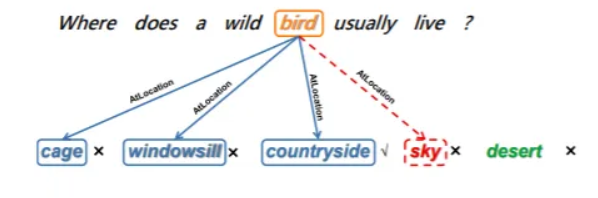 研究人员通过研究从答案概念到相关问题概念的联系,考察了常识知识在BERT句子表征中的存在,提出BERT表示中的这种关系反映了常识知识(即结构化常识)的使用。
研究人员通过研究从答案概念到相关问题概念的联系,考察了常识知识在BERT句子表征中的存在,提出BERT表示中的这种关系反映了常识知识(即结构化常识)的使用。

该团队设计了两组实验:一组测试常识链接在理解表示中的常识知识方面的优势,另一组评估常识链接与模型预测性能之间的相关性。他们的结论是,BERT确实从预训练中获得了常识性的知识,并通过微调,它在预测时将更多地依赖常识信息。强大的常识联系以及模型预测和常识联系强度之间的显著相关性证明了这一发现。研究小组还观察到,结构化常识知识越强时,模型精度会越高。
研究表明,使用特定领域的数据来训练NLP模型将发挥特定的有效作用,例如在生物医学中。微软希望通过调整AI训练背后的概念来扩大这一潜力。
研究人员说这是第一项研究表明BERT在解决CommonsenseQA问题时利用了常识性知识,而微调可以进一步使BERT学会在更高的层次上运用常识知识。他们希望他们的研究结果将鼓励进一步探索和利用BERT的潜在机制。
(张梦婷编译,李朝安校对)
近期会议
EMNLP 2020
Aug15 – Aug21, 2020 多米尼加共和国 蓬塔卡纳
EMNLP是计算机语言学和自然语言处理领域的顶级国际会议,由ACL旗下SIGDAT组织,每年举办一次,Google Scholar计算语言学刊物指标中排名第二,是CCF-B类推荐会议。通常,CoNLL会议也将于EMNLP会议共同召开。CoNLL是计算机语言学和自然语言处理领域的重要国际会议,由ACL旗下SIGNLL组织,每年举办一次,Google Scholar计算语言学刊物指标中排名第十,是CCF-C类推荐会议。
ICMLA 2020
Dec 14 - Dec 17, 2020 美国 迈阿密
ICMLA 2020旨在将研究人员和实践者聚集在一起,展示他们在机器学习(ML)领域的最新成就和创新。该会议为ML原创研究的传播提供了一个领先的国际论坛,重点放在应用以及新颖的算法和系统上。继前几届ICMLA会议取得成功后,此次会议旨在吸引来自广泛ML相关领域的研究人员和应用程序开发人员,而最近大数据处理的出现带来了对机器学习的迫切需求,以应对这些新的挑战。